
Gaps and islands analysis identifies contiguous groups (islands) and breaks (gaps) in a sequence of data. The foundational patterns are covered in the Introduction to Gaps and Islands Analysis on Simple Talk. This article goes further – demonstrating efficient T-SQL solutions using window functions to solve advanced gaps and islands challenges: calculating winning and losing streaks, extending analysis across multiple entities with PARTITION BY, finding the longest streak across all entities, and filtering results to answer complex business questions. All examples use a baseball game dataset as a concrete, intuitive model for sequence analysis.
Gaps and islands analysis supplies a mechanism to group data organically in ways that a standard GROUP BY cannot provide. Once we know how to perform an analysis and group data into islands, we can extend this into the realm of real data.
For all code examples in this article, we will use a set of baseball data that I’ve created and maintained over the years. This data is ideal for analytics as it is large and contains data quality that varies between very accurate and very sloppy. As a result, we are forced to consider data quality in our work, as well as scrutinize boundary conditions for correctness. This data will be used without much introduction as we will only reference two tables, and each is relatively straightforward.
Once introduced, we can obtain metrics that may seem challenging to crunch normally, but by using a familiar and reusable gaps/islands algorithm, we can make it (almost) as easy as cut & paste.
Gaps and Islands: Definitions and Data Intro
Our first task is to define a programmatic way to locate gaps and islands within any set of data. To do so, consider what a boundary is within different data types:
- For a sequence of integers, a boundary can surround missing values.
- For dates/times, a boundary can represent the start or end of a sequence of frequent events that are chronologically close together.
- For decimals, boundaries may be defined by values that are within a small range of each other.
- For strings, missing letters or letter sequences may define a boundary.
These represent a starting point for considering ways to slice up data. A critical aspect of this work is that the result set of gaps/islands analysis will vary in size. For example, if we wanted to measure the number of winning streaks by a sports team as a data island, then there could be any number from zero to (N + 1) / 2 islands, given a set of N rows. This assumes a repeating sequence of winning and losing “streaks” of one game each.
The following diagram shows a set of 10 win/loss events and different ways that islands of data could look:

The image illustrates result sets of 0, 1, and 5 rows for island counts. Note that a single winning streak of 1 game and a single winning streak of 10 games each result in a single identifiable island of data. The key here is that if we are generating a dataset of winning streaks, the result set will vary in size based on the underlying data.
Let’s jump into baseball data and crunch winning streaks as islands of wins and losing streaks as islands of losses. Conceptually, islands are easier to manage and understand than gaps. This convention also allows us to write all our queries similarly, regardless of the results we are seeking.
Here is a sample of the data we will be working with:
|
1 2 3 |
SELECT TOP 10 * FROM dbo.GameLog; |

The results show a row per game with a sample of metrics, including team names (abbreviations), game date, score, and more. GameNumber indicates if a game was part of a double-header so that we know the order of games within a given day, when applicable. The details continue for many more columns and tell us who played each position, the umpires, and totals for many metrics within the game. For the sake of our work, the most basic high-level details are all we will need.
We will use an additional table that contains play-by-play details for each game. The following is a sample of that detail:
|
1 2 3 |
SELECT TOP 10 * FROM dbo.GameEvent; |
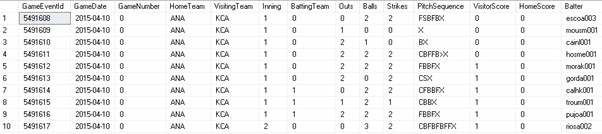
This table contains a row per play per game. A play is usually an at-bat, but may also consist of an error, stolen base, or other action that can be taken during a game. A single game could have over a hundred events associated with it. Like GameLog, the detail can get exhaustive, but we will focus on high-level, easy-to-understand metrics.
This data contains 219,832 games spanning from 1871 through 2018. There is a total of 12,507,920 events associated with those games. With the data introduced, let’s define a winning streak as a set of wins bounded by losses or ties. With that simple definition in mind, we can dive in and crunch our data.
Gaps and Islands: Calculating Streaks
The simplest analysis we can perform is to determine winning and losing streaks. From a data perspective, streaks can be described as islands of wins or losses. To code this, we need to formulate a reliable and repeatable process so that we are not writing new code over and over for each query. The following steps through what we need to accomplish to complete this analysis.
1. Gather a dataset
No metrics can be crunched without a candidate dataset that provides everything we want without noise or distractions. For baseball data, we will be creating a set of games. For example, if we wanted to find regular-season winning streaks for the New York Yankees, we would need to pull every regular-season game that they played in:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END AS result, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.HomeTeamName = 'NYA' OR GameLog.VisitingTeamName = 'NYA' AND GameLog.GameType = 'REG'; |
Here, we filter on any game where the home team or away team was the Yankees (NYA). We then filter to include only regular-season games (REG). GameLogId is an identity primary key and is used to ensure each row is unique and ordered chronologically.
Lastly, we compare the home and away scores to determine if the game was a win, loss or tie as follows:
- If the Yankees are the home team and the home score is greater than the visiting score, then it is a win.
- If the Yankees are the visiting team and the visiting score is greater than the home score, then it is a win.
- If the Yankees are the home team and the home score is less than the visiting score, then it is a loss.
- If the Yankees are the visiting team and the visiting score is less than the home score, then it is a loss.
- If the scores are the same, then it is a tie. This is uncommon but has happened enough times to be statistically significant.
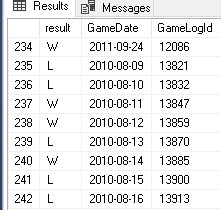
The results are a narrow dataset that lists every game the Yankees have ever played, as well as the result:
2. Determine the Start and End of Streaks
We now want to look at the data above and identify the dates that every winning streak began and ended. To do this, we need insight into the next and previous games. A winning streak begins when a win is preceded by a game that is not a win. A winning streak ends when a win is followed by a game that is not a win.
The easiest way to accomplish this is to use LEAD and LAG on each game to return whether the previous and next games were wins, losses, or ties:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
SELECT CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END AS result, LAG(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS previous_game_result, LEAD(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS next_game_result, ROW_NUMBER() OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS island_location, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.HomeTeamName = 'NYA' OR GameLog.VisitingTeamName = 'NYA' AND GameLog.GameType = 'REG'; |
Note that the contents of the result field are copied verbatim into a LEAD and LAG statement. Each are ordered by the game date and ID columns, ensuring chronological order and no chance of ties. Window functions operate over a window (set of rows) and here we are defining the window as the entire dataset with this particular ordering.
In addition, a column was added with a ROW_NUMBER, which numbers every game in order. This allows for some additional math later, such as streak length:
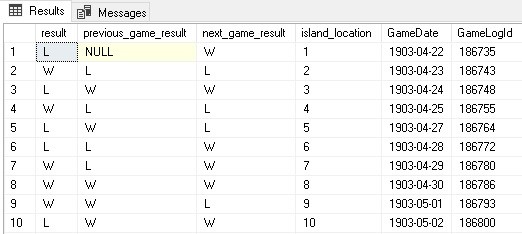
Note that the previous game result is NULL for the first row. Similarly, the next game result will be NULL for the last row in the dataset.
With this work out of the way, we can now identify the start and end of streaks. A critically important mathematical note on this data is that the number of starting and ending data points will always be equal. If we find 100 winning streaks, we know that there will be 100 starting points, 100 ending points, and all 100 of each can join together in order to provide a full dataset.
To find the beginning and end of each streak, we will encapsulate the code above in a CTE and query it accordingly:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
--CTE only, doesn’t run WITH GAME_LOG AS ( SELECT CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END AS result, LAG(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS previous_game_result, LEAD(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS next_game_result, ROW_NUMBER() OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS island_location, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.HomeTeamName = 'NYA' OR GameLog.VisitingTeamName = 'NYA' AND GameLog.GameType = 'REG'), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_number, GAME_LOG.GameDate AS island_start_time, GAME_LOG.island_location AS island_start_location FROM GAME_LOG WHERE GAME_LOG.result = 'W' AND (GAME_LOG.previous_game_result <> 'W' OR GAME_LOG.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_number, GAME_LOG.GameDate AS island_end_time, GAME_LOG.island_location AS island_end_location FROM GAME_LOG WHERE GAME_LOG.result = 'W' AND (GAME_LOG.next_game_result <> 'W' OR GAME_LOG.next_game_result IS NULL)) |
This code is starting to get lengthy, but it’s building on the TSQL we have already completed. CTE_ISLAND_START returns the date and location for the start of a winning streak, and CTE_ISLAND_END returns the date and location for the end of the winning streak. We add in a new ROW_NUMBER to ensure we have island numbers that fully describe the logic presented above. Note that we check for NULL to ensure that we identify the start and end of the dataset as legitimate boundaries.
3. Join Streak Start and End Dates and Return Results
Our final task is to join the beginning and end of each streak together to generate a dataset we can report from:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
WITH GAME_LOG AS ( SELECT CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END AS result, LAG(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS previous_game_result, LEAD(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS next_game_result, ROW_NUMBER() OVER (ORDER BY GameLog.GameDate, GameLog.GameLogId) AS island_location, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.HomeTeamName = 'NYA' OR GameLog.VisitingTeamName = 'NYA' AND GameLog.GameType = 'REG'), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_number, GAME_LOG.GameDate AS island_start_time, GAME_LOG.island_location AS island_start_location FROM GAME_LOG WHERE GAME_LOG.result = 'W' AND (GAME_LOG.previous_game_result <> 'W' OR GAME_LOG.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_number, GAME_LOG.GameDate AS island_end_time, GAME_LOG.island_location AS island_end_location FROM GAME_LOG WHERE GAME_LOG.result = 'W' AND (GAME_LOG.next_game_result <> 'W' OR GAME_LOG.next_game_result IS NULL)) SELECT CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time, CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location + 1 AS count_of_events, DATEDIFF(DAY, CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time) + 1 AS length_of_streak_in_days FROM CTE_ISLAND_START INNER JOIN CTE_ISLAND_END ON CTE_ISLAND_START.island_number = CTE_ISLAND_END.island_number ORDER BY CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location DESC; |
Note that all we have added here is a final select that joins together our CTEs on streak number (the island_number column). As a bonus, we can subtract island locations and find the difference between the start and end dates to determine how long a streak was, both in days and games. Ordering by streak length in games allows us to view the longest streaks first:
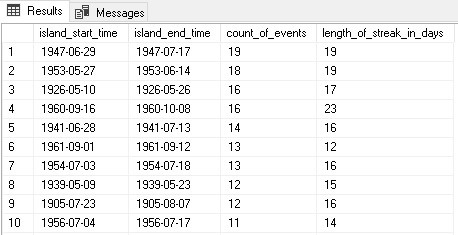
The results are straightforward and tell us the longest winning streaks of all time for a single team. Measuring losing streaks, tie streaks, or any other metric as a streak would only require changing the results that we define in the first CTE and then join on and filter in subsequent CTEs.
The syntax above seems lengthy, but now that it is defined, we can reuse it for all of our additional examples. We can customize and return a variety of more complicated insights without changing much about this code, making it a nice way to solve these analytic questions.
Using PARTITION BY to Calculate Streaks Across Multiple Entities
Analyzing winning streaks for a single team is useful, but what would be more interesting would be to look at a single team versus all other teams, or all teams versus all teams. This would provide an overall view of winning streaks, regardless of the opposition.
If we wanted to know the longest winning streaks by the Yankees versus other individual teams, we could accomplish that task by the use of PARTITION BY in all of our window functions. By partitioning by the opposing team, we can generate a list of winning streaks that are broken down into subsets for each team. With that single change, we can get a completely new set of results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
WITH GAME_LOG AS ( SELECT CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END AS result, LAG(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (PARTITION BY CASE WHEN VisitingTeamName = 'NYA' THEN HomeTeamName ELSE VisitingTeamName END ORDER BY GameLog.GameDate, GameLog.GameLogId) AS previous_game_result, LEAD(CASE WHEN (HomeScore > VisitingScore AND HomeTeamName = 'NYA') OR (VisitingScore > HomeScore AND VisitingTeamName = 'NYA') THEN 'W' WHEN (HomeScore > VisitingScore AND VisitingTeamName = 'NYA') OR (VisitingScore > HomeScore AND HomeTeamName = 'NYA') THEN 'L' WHEN VisitingScore = HomeScore THEN 'T' END) OVER (PARTITION BY CASE WHEN VisitingTeamName = 'NYA' THEN HomeTeamName ELSE VisitingTeamName END ORDER BY GameLog.GameDate, GameLog.GameLogId) AS next_game_result, ROW_NUMBER() OVER (PARTITION BY CASE WHEN VisitingTeamName = 'NYA' THEN HomeTeamName ELSE VisitingTeamName END ORDER BY GameLog.GameDate, GameLog.GameLogId) AS island_location, CASE WHEN VisitingTeamName = 'NYA' THEN HomeTeamName ELSE VisitingTeamName END AS opposing_team, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND GameLog.HomeTeamName = 'NYA' OR GameLog.VisitingTeamName = 'NYA'), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG.opposing_team ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_number, GAME_LOG.GameDate AS island_start_time, GAME_LOG.island_location AS island_start_location, GAME_LOG.opposing_team FROM GAME_LOG WHERE GAME_LOG.result = 'W' AND (GAME_LOG.previous_game_result <> 'W' OR GAME_LOG.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG.opposing_team ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_number, GAME_LOG.GameDate AS island_end_time, GAME_LOG.island_location AS island_end_location, GAME_LOG.opposing_team FROM GAME_LOG WHERE GAME_LOG.result = 'W' AND (GAME_LOG.next_game_result <> 'W' OR GAME_LOG.next_game_result IS NULL)) SELECT CTE_ISLAND_START.island_start_time, CTE_ISLAND_START.opposing_team, CTE_ISLAND_END.island_end_time, CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location + 1 AS count_of_events, DATEDIFF(DAY, CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time) + 1 AS length_of_streak_in_days FROM CTE_ISLAND_START INNER JOIN CTE_ISLAND_END ON CTE_ISLAND_START.island_number = CTE_ISLAND_END.island_number AND CTE_ISLAND_START.opposing_team = CTE_ISLAND_END.opposing_team ORDER BY CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location DESC; |
Note that all window functions now include a PARTITION BY that operates on the opposing team. Window functions operate over a window, and here we are defining the window as a dataset per team. This means that we will have a window per team, rather than a single window for all teams.
For the GAME_LOG CTE, this calculation requires partitioning by a CASE statement that is similar to how we determined if a game was a win or loss. In the remaining CTEs, we can use the opposing_team column to more quickly generate these results (and with less code). Also, note the following:
The final SELECT is nearly identical to all previous demos.
CTE_ISLAND_START and CTE_ISLAND_END are identical to previous demos except in the use of PARTITION BY to further subdivide the dataset.
These similarities allow us to reuse the same syntax repeatedly with a high level of confidence in the results:
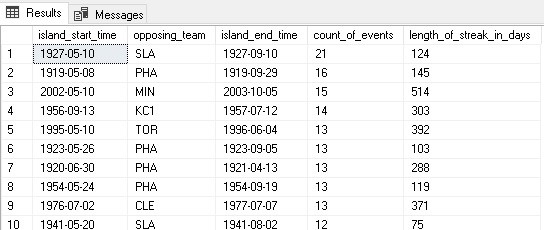
The results quickly tell us the longest winning streaks the Yankees have had versus all other teams in the regular season, with the St. Louis Browns being on the historical losing end of this dataset.
The dataset is interesting, but it begs the question: “How do we calculate winning streaks by all teams versus all teams?”. If we would like to see all winning streaks, regardless of team, then we will need to further customize our queries above as follows:
- Include both home and visiting teams in all queries.
The GAME_LOG CTE needs to be adjusted with a UNION ALL to ensure that we get all games from the perspective of the home and away teams. In other words, we need to double the size of this CTE to ensure that we have a row per team per game.
- This change will necessitate a separate CTE to appropriately order the dataset for further analysis.
- Instead of partitioning by the opposing team, we need to partition by both the team to trend and the opposing team. This will generate a much larger set of windows to analyze.
The following is the final result of the changes above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
WITH GAME_LOG AS ( SELECT CASE WHEN HomeScore > VisitingScore THEN 'W' WHEN VisitingScore > HomeScore THEN 'L' WHEN HomeScore = VisitingScore THEN 'T' END AS result, VisitingTeamName AS opposing_team, HomeTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' UNION ALL SELECT CASE WHEN VisitingScore > HomeScore THEN 'W' WHEN HomeScore > VisitingScore THEN 'L' END AS result, HomeTeamName AS opposing_team, VisitingTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND VisitingScore <> HomeScore), GAME_LOG_ORDERED AS ( SELECT GAME_LOG.GameLogId, GAME_LOG.GameDate, GAME_LOG.team_to_trend, GAME_LOG.opposing_team, GAME_LOG.result, LAG(GAME_LOG.result) OVER (PARTITION BY team_to_trend, opposing_team ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS previous_game_result, LEAD(GAME_LOG.result) OVER (PARTITION BY team_to_trend, opposing_team ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS next_game_result, ROW_NUMBER() OVER (PARTITION BY team_to_trend, opposing_team ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_location FROM GAME_LOG), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend, GAME_LOG_ORDERED.opposing_team ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_start_time, GAME_LOG_ORDERED.island_location AS island_start_location, GAME_LOG_ORDERED.opposing_team, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.previous_game_result <> 'W' OR GAME_LOG_ORDERED.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend, GAME_LOG_ORDERED.opposing_team ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_end_time, GAME_LOG_ORDERED.island_location AS island_end_location, GAME_LOG_ORDERED.opposing_team, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.next_game_result <> 'W' OR GAME_LOG_ORDERED.next_game_result IS NULL)) SELECT CTE_ISLAND_START.island_start_time, CTE_ISLAND_START.team_to_trend, CTE_ISLAND_START.opposing_team, CTE_ISLAND_END.island_end_time, CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location + 1 AS count_of_events, DATEDIFF(DAY, CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time) + 1 AS length_of_streak_in_days FROM CTE_ISLAND_START INNER JOIN CTE_ISLAND_END ON CTE_ISLAND_START.island_number = CTE_ISLAND_END.island_number AND CTE_ISLAND_START.opposing_team = CTE_ISLAND_END.opposing_team AND CTE_ISLAND_START.team_to_trend = CTE_ISLAND_END.team_to_trend ORDER BY CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location DESC; |
While the changes are readily apparent, the code overall is very similar to what we wrote earlier. Window functions operate over a window, and here we are defining the window as a dataset per each pair of teams. This means that we will have a window for every set of teams that have played each other. This is a far larger number of windows than earlier but is necessary to be able to calculate streaks in aggregate across all possible matchups. The results are as follows:
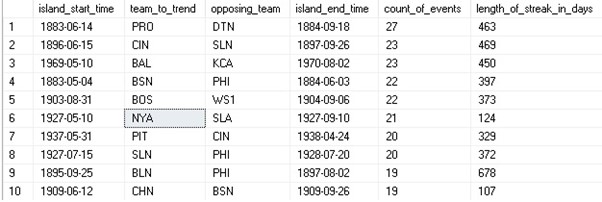
We can observe that the top winning streak for the Yankees is only number 6 on this list with the top 10 streaks ranging anywhere from 1883 to 1970. Streak lengths are often quite long as many spanned multiple seasons.
Longest Winning Streaks for Any Team
Another similar problem we may wish to solve is to determine the longest overall winning streaks for all teams in baseball. Earlier we calculated this metric for a single team, but there is value in being able to do so for all teams in a single query.
Fortunately, we have already done much of the work on this (and then some). To find the longest winning streaks for all teams in aggregate (not versus any specific team), all we need to do is remove the opposing team from all PARTITION BY clauses. The remaining TSQL remains nearly identical:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
WITH GAME_LOG AS ( SELECT CASE WHEN HomeScore > VisitingScore THEN 'W' WHEN VisitingScore > HomeScore THEN 'L' WHEN HomeScore = VisitingScore THEN 'T' END AS result, VisitingTeamName AS opposing_team, HomeTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' UNION ALL SELECT CASE WHEN VisitingScore > HomeScore THEN 'W' WHEN HomeScore > VisitingScore THEN 'L' END AS result, HomeTeamName AS opposing_team, VisitingTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND VisitingScore <> HomeScore), GAME_LOG_ORDERED AS ( SELECT GAME_LOG.GameLogId, GAME_LOG.GameDate, GAME_LOG.team_to_trend, GAME_LOG.result, LAG(GAME_LOG.result) OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS previous_game_result, LEAD(GAME_LOG.result) OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS next_game_result, ROW_NUMBER() OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_location FROM GAME_LOG), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_start_time, GAME_LOG_ORDERED.island_location AS island_start_location, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.previous_game_result <> 'W' OR GAME_LOG_ORDERED.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_end_time, GAME_LOG_ORDERED.island_location AS island_end_location, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.next_game_result <> 'W' OR GAME_LOG_ORDERED.next_game_result IS NULL)) SELECT CTE_ISLAND_START.island_start_time, CTE_ISLAND_START.team_to_trend, CTE_ISLAND_END.island_end_time, CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location + 1 AS count_of_events, DATEDIFF(DAY, CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time) + 1 AS length_of_streak_in_days FROM CTE_ISLAND_START INNER JOIN CTE_ISLAND_END ON CTE_ISLAND_START.island_number = CTE_ISLAND_END.island_number AND CTE_ISLAND_START.team_to_trend = CTE_ISLAND_END.team_to_trend ORDER BY CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location DESC; |
Window functions operate over a window and here we are defining the window as a dataset per team. This means that we will have a single window for every team that has ever won a game. This contrasts our previous query, which generated far more windows to perform analysis over.
The results are as follows:
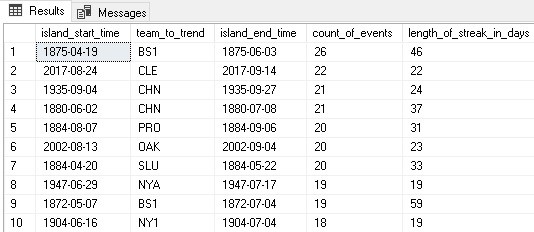
We can see that the longest winning streak of all time was accomplished by the Boston Red Stockings in 1875.
Note that the results do not include ties. Adjusting our work to include ties would require that we:
- Change CTE_ISLAND_START and CTE_ISLAND_END to consider a streak start/end bounded by a loss, and not a loss or tie.
- Adjust the count of events to exclude ties. This avoids reporting a streak that was more games won than were actually won.
Alternatively, we could count a tie as a win for record-keeping. This would simplify the T-SQL but report occasionally inaccurate data. For these metrics, adding a notes or has_ties column would better allow us to denote if a tie occurred.
The simplest approach would be to omit ties altogether and pretend they do not exist, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
WITH GAME_LOG AS ( SELECT CASE WHEN HomeScore > VisitingScore THEN 'W' ELSE 'L' END AS result, VisitingTeamName AS opposing_team, HomeTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND HomeScore <> VisitingScore UNION ALL SELECT CASE WHEN VisitingScore > HomeScore THEN 'W' ELSE 'L' END AS result, HomeTeamName AS opposing_team, VisitingTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND VisitingScore <> HomeScore), GAME_LOG_ORDERED AS ( SELECT GAME_LOG.GameLogId, GAME_LOG.GameDate, GAME_LOG.team_to_trend, GAME_LOG.result, LAG(GAME_LOG.result) OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS previous_game_result, LEAD(GAME_LOG.result) OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS next_game_result, ROW_NUMBER() OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_location FROM GAME_LOG), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_start_time, GAME_LOG_ORDERED.island_location AS island_start_location, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.previous_game_result = 'L' OR GAME_LOG_ORDERED.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_end_time, GAME_LOG_ORDERED.island_location AS island_end_location, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.next_game_result = 'L' OR GAME_LOG_ORDERED.next_game_result IS NULL)) SELECT CTE_ISLAND_START.island_start_time, CTE_ISLAND_START.team_to_trend, CTE_ISLAND_END.island_end_time, CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location + 1 AS count_of_events, DATEDIFF(DAY, CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time) + 1 AS length_of_streak_in_days FROM CTE_ISLAND_START INNER JOIN CTE_ISLAND_END ON CTE_ISLAND_START.island_number = CTE_ISLAND_END.island_number AND CTE_ISLAND_START.team_to_trend = CTE_ISLAND_END.team_to_trend ORDER BY CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location DESC; |
This code explicitly filters out ties, so the end results will completely ignore them. We get no insight into whether a streak included ties but could easily join our result set back into the underlying data to gather that information, if it were important.
Filtering Results to Answer Obscure Questions
When observing any data analysis long enough, we are eventually surprised by obscure data requests or facts that might not come naturally to us. In sports, like in business, people are looking for new knowledge that can provide any statistical benefit. Does a player perform better at night? How about in the cold? Does being right or left-handed matter?
Statistics across these metrics sound mind-bogglingly complex but are incredibly easy to crunch using code we have already written. The key is to alter the filter of our primary dataset. The remainder of the gaps/islands analysis can be left as-is and will perform exactly as we want.
For example, imagine we wanted to track winning streaks for all teams at night. The T-SQL to make this happen is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
WITH GAME_LOG AS ( SELECT CASE WHEN HomeScore > VisitingScore THEN 'W' WHEN VisitingScore > HomeScore THEN 'L' WHEN HomeScore = VisitingScore THEN 'T' END AS result, VisitingTeamName AS opposing_team, HomeTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND GameLog.DayorNight = 'N' AND GameLog.DayorNight IS NOT NULL UNION ALL SELECT CASE WHEN VisitingScore > HomeScore THEN 'W' WHEN HomeScore > VisitingScore THEN 'L' END AS result, HomeTeamName AS opposing_team, VisitingTeamName AS team_to_trend, GameLog.GameDate, GameLog.GameLogId FROM dbo.GameLog WHERE GameLog.GameType = 'REG' AND GameLog.DayorNight = 'N' AND GameLog.DayorNight IS NOT NULL AND VisitingScore <> HomeScore), GAME_LOG_ORDERED AS ( SELECT GAME_LOG.GameLogId, GAME_LOG.GameDate, GAME_LOG.team_to_trend, GAME_LOG.result, LAG(GAME_LOG.result) OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS previous_game_result, LEAD(GAME_LOG.result) OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS next_game_result, ROW_NUMBER() OVER (PARTITION BY team_to_trend ORDER BY GAME_LOG.GameDate, GAME_LOG.GameLogId) AS island_location FROM GAME_LOG), CTE_ISLAND_START AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_start_time, GAME_LOG_ORDERED.island_location AS island_start_location, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.previous_game_result <> 'W' OR GAME_LOG_ORDERED.previous_game_result IS NULL)), CTE_ISLAND_END AS ( SELECT ROW_NUMBER() OVER (PARTITION BY GAME_LOG_ORDERED.team_to_trend ORDER BY GAME_LOG_ORDERED.GameDate, GAME_LOG_ORDERED.GameLogId) AS island_number, GAME_LOG_ORDERED.GameDate AS island_end_time, GAME_LOG_ORDERED.island_location AS island_end_location, GAME_LOG_ORDERED.team_to_trend FROM GAME_LOG_ORDERED WHERE GAME_LOG_ORDERED.result = 'W' AND (GAME_LOG_ORDERED.next_game_result <> 'W' OR GAME_LOG_ORDERED.next_game_result IS NULL)) SELECT CTE_ISLAND_START.island_start_time, CTE_ISLAND_START.team_to_trend, CTE_ISLAND_END.island_end_time, CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location + 1 AS count_of_events, DATEDIFF(DAY, CTE_ISLAND_START.island_start_time, CTE_ISLAND_END.island_end_time) + 1 AS length_of_streak_in_days FROM CTE_ISLAND_START INNER JOIN CTE_ISLAND_END ON CTE_ISLAND_START.island_number = CTE_ISLAND_END.island_number AND CTE_ISLAND_START.team_to_trend = CTE_ISLAND_END.team_to_trend ORDER BY CTE_ISLAND_END.island_end_location - CTE_ISLAND_START.island_start_location DESC; |
The only change is that we added a filter to each part of the UNION dataset to filter out all games that are not night games. We check for NULL as some older games have no record of time of day. The results are as follows:
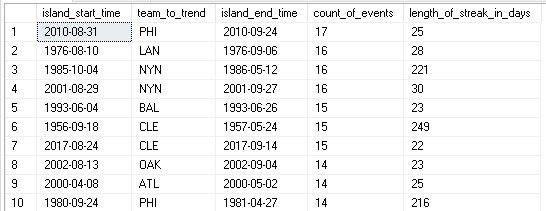
The results provide some obscure, but interesting data. Oftentimes, scenarios like these will seem nonsensical until a real-world scenario arises where they make perfect sense. For many statistical analyses, being able to improve predictions even by a small percentage can have a profound impact. For job functions such as sales or marketing, timing questions arise often and knowing the optimal ways in which to engage people can be the difference between success and failure.
Conclusion
The TSQL introduced in this article was not for the faint of heart. Breaking it into smaller pieces and viewing each chunk as a logical step towards getting our result set helped make it easier to read and understand. To summarize, the general process used in every islands/streaks analysis:
- Create a dataset with a definitive win/loss definition.
- Order the dataset so that each event can be numbered.
- Generate a list of island starting points
- Generate a list of island ending points
- Join the starting and ending points together and return results.
Once this syntax is established, every query will be similar to the rest of the queries we write. Copying, pasting, and modifying this TSQL to create new filters, partitions, or metrics is recommended as a far faster and reliable alternative than rewriting this code repeatedly.
Using this style of analysis, we can crunch vast amounts of data into meaningful groups that can measure success and report on how events relate to other nearby events. While other tools such as Python or R can be used to crunch this data in a similar fashion, being closer to the data allows for easier customization and more reliable control over performance.
FAQs: Efficient Solutions to Gaps and Islands Challenges
1. What are gaps and islands in SQL and why do they matter?
Gaps and islands analysis identifies contiguous sequences (islands) and breaks in those sequences (gaps) within ordered data. Common use cases include calculating streaks (consecutive wins or losses), finding date ranges where a value was continuously active, identifying missing values in a sequence, and grouping consecutive events by category. SQL Server’s window functions – particularly ROW_NUMBER(), LAG(), LEAD(), and SUM() OVER – provide efficient T-SQL solutions that outperform cursor-based approaches.
2. What is the most efficient T-SQL approach for gaps and islands analysis?
The most efficient approach uses the difference between two ROW_NUMBER() calculations to assign a group identifier to each contiguous sequence. For a sequence of wins and losses, compute ROW_NUMBER() OVER (ORDER BY date) – ROW_NUMBER() OVER (PARTITION BY result ORDER BY date). Rows with the same result in the same contiguous run produce the same difference value, identifying them as an island. This avoids recursion and cursor iteration, running in a single scan of the data.
3. How do I calculate the longest streak in SQL Server?
Calculate streaks using the ROW_NUMBER difference method to identify each streak and its start/end dates. Then aggregate by group identifier to get the streak length (COUNT of rows per group). Use RANK() or DENSE_RANK() over the streak lengths to identify the longest. With PARTITION BY you can calculate the longest streak for each entity (team, player, or category) simultaneously in a single query.
4. What is the difference between gaps analysis and islands analysis in SQL?
Gaps analysis identifies the missing values or breaks between sequences – for example, finding which dates are missing from a series of daily records, or which integers are absent from a numbered sequence. Islands analysis identifies the contiguous groups themselves – the runs of consecutive matching values. In practice, both analyses use the same underlying ROW_NUMBER difference technique and are typically performed together in the same query.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments