
The gaps and islands problem is the task of detecting unbroken runs of sequential values (islands) and the missing values between them (gaps) in a column – typically an IDENTITY column, a date column, or a sequence number.
This article presents an alternative set-based solution to both gaps and islands, compares it against the four solutions documented in Itzik Ben-Gan’s chapter of SQL Server MVP Deep Dives, and includes a scalable test harness that benchmarks all approaches from 200,000 to 2,000,000 rows.
The alternative solution uses a self-join with row numbering and turns out to be competitive with, and in some cases faster than, the established approaches. All solutions are set-based T-SQL – no cursors or loops.
What are Gaps and Islands in SQL Server?
The word ‘Gaps’ in the title refers to gaps in sequences of values. Islands are unbroken sequences delimited by gaps. The ‘Gaps and Islands’ problem is that of using SQL to rapidly detect the unbroken sequences, and the extent of the gaps between them in a column.
Islands and gaps appear in all sorts of sequences, be they IDENTITY columns where some rows have been removed or dates that occur in sequence (but some are missing). In all cases, the sequences do not contain duplicates. The ‘Gaps and Islands’ problem isn’t entirely an academic game, since a number of business processes demand some way of detecting gaps and islands in sequences.
A typical example might occur in the express distribution business where a consignment has many packages numbered sequentially. Typically you scan all packages when a consignment reaches the depot. If packages are missing those represent the gaps. So if you want to represent the event “consignment arrived at the depot” and list the package numbers that did arrive, you’d want to group them like 1-10, 15-18, etc. where those are the islands.
It is complex and interesting task to come up with a solution that performs and scales well. Chapter 5 of SQL Server MVP Deep Dives, Gaps and Islands by Itzik Ben-Gan, is probably the best and most thorough explanation of the main solutions. My interest was piqued by that article and I played about with the examples to try to gain a little better insight.
While doing so, I happened upon a rather different solution to the problem, and was sufficiently intrigued to develop a test harness to evaluate the way that the various algorithms performed and scaled. Let’s dip our toe in the pond by looking at some sample data.
The sample data
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE GapsIslands (ID INT NOT NULL, SeqNo INT NOT NULL); ALTER TABLE dbo.GapsIslands ADD CONSTRAINT pk_GapsIslands PRIMARY KEY (ID, SeqNo); INSERT INTO dbo.GapsIslands SELECT 1, 1 UNION ALL SELECT 1, 2 UNION ALL SELECT 1, 5 UNION ALL SELECT 1, 6 UNION ALL SELECT 1, 8 UNION ALL SELECT 1, 9 UNION ALL SELECT 1, 10 UNION ALL SELECT 1, 12 UNION ALL SELECT 1, 20 UNION ALL SELECT 1, 21 UNION ALL SELECT 1, 25 UNION ALL SELECT 1, 26; SELECT * FROM dbo.GapsIslands; |
We’ve thrown in an ID column because you may need to retrieve islands and/or gaps across more than one record grouping. However, this value is not used in the basic examples, but will be used in the later performance test harnesses. This produces a table of sample data (on the left) and I’ve added the results we should expect for islands (in the middle) and gaps (on the right):
|
Results |
Islands |
Gaps |
|
ID SeqNo 1 1 1 2 1 5 1 6 1 8 1 9 1 10 1 12 1 20 1 21 1 25 1 26 |
ID StartSeqNo EndSeqNo 1 1 2 1 5 6 1 8 10 1 12 12 1 20 21 1 25 26 |
ID StartSeqNo EndSeqNo 1 3 4 1 7 7 1 11 11 1 13 19 1 22 24 |
In our example, islands are contiguous groups of integers. In a way, gaps are the inverse of islands, as they are the endpoints between the islands.
It is interesting to note that there will always be one less row of gaps than islands.
Some Islands Solutions
In the SQL MVP Deep Dives book, the author provides four solutions to the islands problem. From his timing results, it seems that two of these seem to be much better than the others, based on the measure of elapsed time only. Let’s take a look at these two.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
INSERT INTO dbo.GapsIslands SELECT 1, 1 UNION ALL SELECT 1, 2 UNION ALL SELECT 1, 5 UNION ALL SELECT 1, 6 UNION ALL SELECT 1, 8 UNION ALL SELECT 1, 9 UNION ALL SELECT 1, 10 UNION ALL SELECT 1, 12 UNION ALL SELECT 1, 20 UNION ALL SELECT 1, 21 UNION ALL SELECT 1, 25 UNION ALL SELECT 1, 26 PRINT 'Islands Solution #1 from SQL MVP Deep Dives'; WITH StartingPoints AS ( SELECT ID, SeqNo, ROW_NUMBER() OVER(ORDER BY SeqNo) AS rownum FROM dbo.GapsIslands AS A WHERE NOT EXISTS ( SELECT * FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo = A.SeqNo - 1) ), EndingPoints AS ( SELECT ID, SeqNo, ROW_NUMBER() OVER(ORDER BY SeqNo) AS rownum FROM dbo.GapsIslands AS A WHERE NOT EXISTS ( SELECT * FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo = A.SeqNo + 1) ) SELECT S.ID, S.SeqNo AS start_range, E.SeqNo AS end_range FROM StartingPoints AS S JOIN EndingPoints AS E ON E.ID = S.ID AND E.rownum = S.rownum; PRINT 'Islands Solution #3 from SQL MVP Deep Dives'; SELECT ID, StartSeqNo=MIN(SeqNo), EndSeqNo=MAX(SeqNo) FROM ( SELECT ID, SeqNo ,rn=SeqNo-ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo) FROM dbo.GapsIslands) a GROUP BY ID, rn; |
We have modified the code provided to support the ID column, which may reflect different user IDs, machine IDs, or whatever for your particular case. When you run this code, you’ll find that the results precisely match the expected results for islands shown in the table above. It is important to note that in at least the second case, the sequence numbers must be unique within an ID in order for the solution to work.
The following performance was achieved by these two solutions across 1,000,000 rows, with the index being essential to achieving these results. This basically confirms the findings in the book: solution #3 is faster.
|
Islands |
Test Harness – 1,000,000 Rows |
||
|
Solution |
CPU (ms) |
Elapsed Time (ms) |
Logical IOs |
|
Islands #1 |
1545 |
1611 |
10568 |
|
Islands #3 |
733 |
807 |
2642 |
In the resources file, you may run the script: Islands Test Harness #1.sql to confirm these results for yourself and see how they may vary based on your machine’s configuration.
The Traditional Gaps Solutions
The gaps problem, in my mind at least, is intrinsically a bit more challenging than islands because, in effect you need to “make up” the data points that are the endpoints of each gap; meaning that by definition for the gaps, the endpoints of the gap do not already exist in the data.
As I thumb through my extensively dog-eared copy of the SQL MVP Deep Dives book, I find there are four solutions proposed for gaps. Of these, there are 3 which seem to perform to relatively the same order of magnitude when it comes to elapsed time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
PRINT 'Gaps Solution #1 from SQL MVP Deep Dives'; SELECT ID, StartSeqNo=SeqNo + 1, EndSeqNo=( SELECT MIN(B.SeqNo) FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo > A.SeqNo) - 1 FROM dbo.GapsIslands AS A WHERE NOT EXISTS ( SELECT * FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo = A.SeqNo + 1) AND SeqNo < (SELECT MAX(SeqNo) FROM dbo.GapsIslands B WHERE B.ID = A.ID); PRINT 'Gaps Solution #2 from SQL MVP Deep Dives'; SELECT ID, StartSeqNo=cur + 1, EndSeqNo=nxt - 1 FROM ( SELECT ID, cur=SeqNo, nxt=( SELECT MIN(B.SeqNo) FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo > A.SeqNo) FROM dbo.GapsIslands AS A) AS D WHERE nxt - cur > 1; PRINT 'Gaps Solution #3 from SQL MVP Deep Dives'; WITH C AS ( SELECT ID, SeqNo, ROW_NUMBER() OVER(PARTITION BY ID ORDER BY SeqNo) AS rownum FROM dbo.GapsIslands ) SELECT Cur.ID, StartSeqNo=Cur.SeqNo + 1, EndSeqNo=Nxt.SeqNo - 1 FROM C AS Cur JOIN C AS Nxt ON Cur.ID = Nxt.ID AND Nxt.rownum = Cur.rownum + 1 WHERE Nxt.SeqNo - Cur.SeqNo > 1; |
Once again a check of the results confirms that they are identical to those shown in the preceding table for gaps. Test harness Gaps Test Harness #1.sql confirms that solution #1 from SQL MVP Deep Dives is the fastest.
|
Gaps |
Test Harness – 1,000,000 Rows |
||
|
Solution |
CPU (ms) |
Elapsed Time (ms) |
Logical IOs |
|
Gaps #1 |
903 |
810 |
23012 |
|
Gaps #2 |
5056 |
1522 |
3192926 |
|
Gaps #3 |
1591 |
1593 |
5278 |
An Alternative Gaps Solution
Since we have relatively a fast method of determining islands, perhaps it’s possible to convert that solution into one that will identify our gaps. Let’s take a look at the islands results to see how it might be converted into gaps.

If we first insert two columns and fill the first with one less than the StartSeqNo and the second with one greater than the EndSeqNo, we can circle the numbers that represent the gaps. Each pair of colored, circled numbers in the rightmost table perfectly represents our gaps.
This suggests to us that UNPIVOTing the islands might give us something to work with to arrive at the gaps. There are at least three methods to un-pivot two columns: 1) using the SQL UNPIVOT keyword, 2) doing a UNION ALL between each of the columns and 3) using the CROSS APPLY VALUES (CAV) approach to UNPIVOT. We’ll choose the latter because as this article: An Alternative (Better?) Method to UNPIVOT seems to demonstrate, that approach may be the swiftest. We’ll also move the fastest islands bit of code magic into a Common Table Expression (CTE) so we can focus on our gaps solution.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
WITH Islands AS ( SELECT ID, StartSeqNo=MIN(SeqNo) - 1, EndSeqNo=MAX(SeqNo) + 1 FROM ( SELECT ID, SeqNo ,rn=SeqNo-ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo) FROM dbo.GapsIslands) a GROUP BY ID, rn ) SELECT ID, SeqNo ,n=ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo) ,m=ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo)/2 FROM Islands CROSS APPLY (VALUES (StartSeqNo),(EndSeqNo)) a(SeqNo) ORDER BY ID, StartSeqNo; |
We’ve thrown in a couple of row numbers to see if they might help us with the grouping we need. These results are:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ID SeqNo n m 1 0 1 0 1 3 2 1 1 4 3 1 1 7 4 2 1 7 5 2 1 11 6 3 1 11 7 3 1 13 8 4 1 19 9 4 1 22 10 5 1 24 11 5 1 27 12 6 |
We certainly have the numbers in SeqNo that represent the endpoints of our gap and we even have a grouping column (m) that will allow us to group our gap start/end points, which we arrived at by the totally simplistic method of dividing by two. Now all we have to do is figure out a way to remove the first and last row from the result set!
Since all the gap endpoints of interest are in groups of two, this brings to mind the HAVING clause. Let’s give that a try.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
WITH Islands AS ( SELECT ID, StartSeqNo=MIN(SeqNo) - 1, EndSeqNo=MAX(SeqNo) + 1 FROM ( SELECT ID, SeqNo ,rn=SeqNo-ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo) FROM dbo.GapsIslands) a GROUP BY ID, rn ) SELECT ID, StartSeqNo=MIN(SeqNo), EndSeqNo=MAX(SeqNo) FROM ( SELECT ID, SeqNo ,m=ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo)/2 FROM Islands CROSS APPLY (VALUES (StartSeqNo),(EndSeqNo)) a(SeqNo)) a GROUP BY ID, m HAVING COUNT(*) = 2 ORDER BY ID, StartSeqNo; |
Inspection of the results set clearly shows we’ve achieved our expected results – the gaps!
Performance Comparison of Gaps Solutions
Performance always counts so let’s see how well this solution performs in a sufficiently large test harness versus the solutions proposed in the MVP Deep Dives book.
In the two test harness scripts we mentioned previously, the code to generate a large test data set looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
SET NOCOUNT ON SET STATISTICS TIME, IO OFF CREATE TABLE GapsIslands (ID INT NOT NULL, SeqNo BIGINT NOT NULL); ALTER TABLE GapsIslands ADD CONSTRAINT pk_GapsIslands PRIMARY KEY (ID, SeqNo); DECLARE @Records INT = 1000000; -- Generate a sequence numbers table with 10 unique IDs for a total -- of @Records rows, with small gaps around every 500 or so. WITH Tally (n) AS ( SELECT TOP (1+CAST(FLOOR((@Records/10)/500.+@Records/10) AS INT)) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM sys.all_columns a CROSS JOIN sys.all_columns b ) INSERT INTO dbo.GapsIslands SELECT m, n FROM (SELECT TOP 10 n FROM Tally) a(m) CROSS APPLY Tally b WHERE n % 500 <> m; PRINT 'Rows in test harness: ' + CAST(@@ROWCOUNT AS VARCHAR(12)); -- Make the gaps wider towards the end DECLARE @Gaps INT = 1 WHILE @Gaps <= 3 BEGIN WITH Gaps AS (SELECT TOP (@Gaps * 1000) ID, SeqNo FROM GapsIslands ORDER BY SeqNo DESC) UPDATE Gaps SET SeqNo = SeqNo * POWER(10, @Gaps) * (ID + 1); SELECT @Gaps = @Gaps + 1; END |
While reviewing this article, Peter Larsson (alias PESO) suggested an alternative using CROSS APPLY VALUES that may improve the speed. So let’s take a look at that method also.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
WITH cteSource(ID, Seq, Num) AS ( SELECT d.ID, f.Seq, f.Num FROM ( SELECT ID, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY MIN(SeqNo)) AS Grp, MIN(SeqNo) AS StartSeqNo, MAX(SeqNo) AS EndSeqNo FROM ( SELECT ID, SeqNo, SeqNo - ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo) AS rn FROM dbo.GapsIslands ) AS a GROUP BY ID,rn ) d CROSS APPLY ( VALUES (d.Grp, d.EndSeqNo + 1),(d.Grp - 1, d.StartSeqNo - 1) ) AS f(Seq, Num) ) SELECT ID, MIN(Num) AS StartSeqNo, MAX(Num) AS EndSeqNo FROM cteSource GROUP BY ID, Seq HAVING COUNT(*) = 2; |
Using the gaps solutions identified previously, a quick check of the results at 1,000,000 rows delivers these results (run Gaps Test Harness #2.sql).
|
Gaps |
Test Harness – 1,000,000 Rows |
||
|
Solution |
CPU (ms) |
Elapsed Time (ms) |
Logical IOs |
|
SQL MVP Deep Dives Gaps #1 |
967 |
827 |
22997 |
|
SQL MVP Deep Dives Gaps #2 |
5258 |
1653 |
3192923 |
|
SQL MVP Deep Dives Gaps #3 |
1840 |
1834 |
5278 |
|
CROSS APPLY VALUES – Islands to Gaps |
718 |
933 |
2639 |
|
CAV – Islands to Gaps (by PESO) |
640 |
711 |
2639 |
Elapsed times for the new CAV (Cross Apply Values) methods appear quite competitive, and both logical IOs and CPU time appear improved. In a moment we’ll see if these results can be reproduced and how they scale.
An Alternative Islands Solution
If it is possible to convert Islands to Gaps, perhaps it is also possible to convert Gaps to Islands. Let’s consider a data transformation as follows:
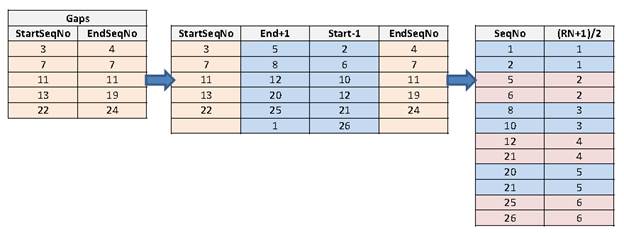
For this solution, we’ll take the end point and add one, while we subtract one from the start point. We need to add a row, and that row will be the first and last sequence number in our series. Finally, we’ll un-pivot and add a row number that groups each resulting sequence number in pairs (note that you could either add 1 to or subtract 1 from the row number before dividing by 2).
So now, skipping the intermediate explanatory step as it is quite similar to what we did before, we can arrive at the following code to calculate islands from gaps:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
WITH Gaps AS ( SELECT ID, StartSeqNo=SeqNo + 1, EndSeqNo=( SELECT MIN(B.SeqNo) FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo > A.SeqNo) - 1 FROM dbo.GapsIslands AS A WHERE NOT EXISTS ( SELECT * FROM dbo.GapsIslands AS B WHERE B.ID = A.ID AND B.SeqNo = A.SeqNo + 1) AND SeqNo < (SELECT MAX(SeqNo) FROM dbo.GapsIslands B WHERE B.ID = A.ID) ) ,MinMax AS ( SELECT ID, MinSeqNo=MIN(SeqNo), MaxSeqNo=MAX(SeqNo) FROM dbo.GapsIslands GROUP BY ID ) SELECT ID, MinSeqNo=MIN(SeqNo), MaxSeqNo=MAX(SeqNo) FROM ( SELECT ID, SeqNo, m=(ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SeqNo)-1)/2 FROM ( SELECT ID, MinSeqNo=EndSeqNo+1, MaxSeqNo=StartSeqNo-1 FROM Gaps UNION ALL SELECT ID, MinSeqNo, MaxSeqNo FROM MinMax) a CROSS APPLY (VALUES (MinSeqNo),(MaxSeqNo)) b (SeqNo)) b GROUP BY ID, m; |
The Gaps CTE above is the SQL MVP Deep Dives fastest (elapsed time) approach to gaps and the MinMax CTE is used to compute the additional row we’ll need to go from gaps to islands.
So how do these results compare to our fastest islands solutions at 1,000,000 rows?
|
Islands |
Test Harness – 1,000,000 Rows |
||
|
Solution |
CPU (ms) |
Elapsed Time (ms) |
Logical IOs |
|
SQL MVP Deep Dives Islands #1 |
1217 |
1256 |
10568 |
|
SQL MVP Deep Dives Islands #3 |
593 |
727 |
2641 |
|
CROSS APPLY VALUES – Gaps to Islands |
1358 |
890 |
25690 |
The SQL MVP Deep Dives Islands solution #3 still wins the elapsed time race but our approach is a respectable showing, being solidly in second place in terms of elapsed time. It appears that parallelism accounts for this positioning, as CPU for the CAV – Gaps to Islands solution exceeds the elapsed time. These results may be reproduced by running Islands Test Harness #2.sql.
Scalability
Using each #2 test harness, we’ll generate test data from 200,000 to 2,000,000 rows and chart the results for comparison. You’ll see that the final results appear to be a bit mixed.
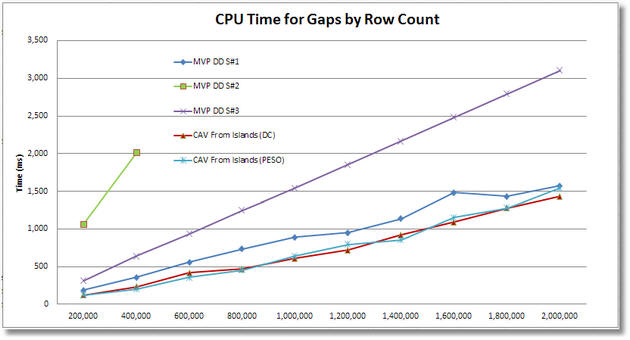
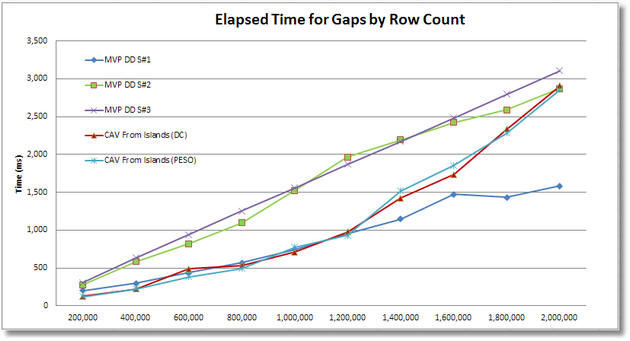
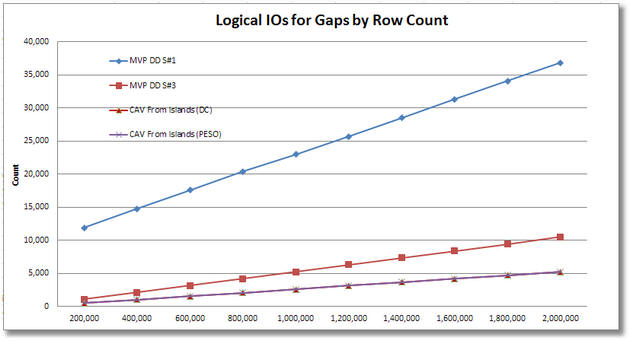
For the CAV (Cross Apply Values) solutions for islands to gaps, their ranking appears as #1 for CPU across the board, although it is a slim lead and the convergence at 2M rows suggests that it may start lagging behind above that. For elapsed time, the CAV solutions appear to be basically tied with MVP DD S#1 up to about 1.2M rows, but then they fall to second place ranking above that row count. In logical IOs they are the clear winner across the board (the SQL MVP Deep Dive solution #2 was omitted due to scaling of the chart). MVP DD S#3 does get good marks for logical IOs.
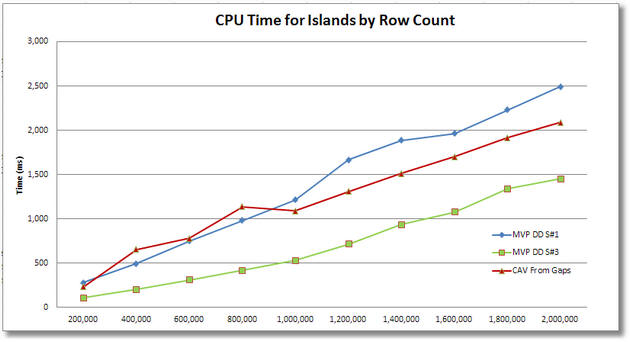
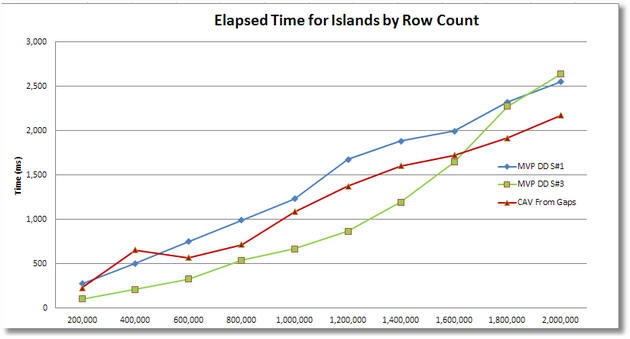
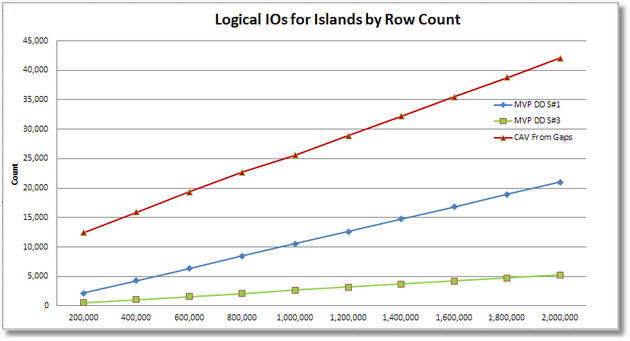
For the CAV (Cross Apply Values) solution of gaps to islands, it manages to achieve a #2 ranking for CPU above 1M rows but lagged slightly behind prior to that. For elapsed time, above 1.8M rows it seems to have achieved the #1 ranking of the 3 solutions (below 1.8M it is #2), but our scaling tests don’t go above 2M rows so we’re not sure how long it would maintain that lead. However on logical IOs, it is a clear #3 (and would probably remain so) regardless of the number of rows in the test harness.
It also appears that for the CAV gaps to islands solution, we lost the parallelism that resulted in the highly favorable elapsed time result, possibly because SQL had cached a non-parallelized execution plan at the lower row counts.
Ultimately the CAV (Cross Apply Values) approaches may offer benefits under some conditions but your choice should be made based on a careful analysis of which solution works best for your constraints of data rows, parallelism and the specific resource that you most wish to conserve (CPU, elapsed time or logical IOs).
Gaps and Islands
A Google search for anything similar to an approach like this for calculating islands and gaps came up empty, but we’d love to hear if anyone has published anything on it before or has other improvements to suggest. And we’d most certainly be thrilled to hear from our valued readers if this solution has been of benefit to them. Perhaps in SQL 2012 someone can come up with something faster utilizing a window frame. We look forward to hearing about that too.
Timing tests run for this article were done in SQL Server 2008 R2 on a Dell Inspiron Core i5 2.4 GHz with 8GB of memory.
Until next time
The Excel file with the results of the test, and the graphs, is attached, as are the four SQL source files for the tests. Links to them can be found at the head of this article
If you liked this article, you might also like Introduction to Gaps and Islands Analysis
FAQs
1. What is the gaps and islands problem in SQL?
The gaps and islands problem is the task of identifying unbroken runs of sequential values in a column (islands) and the missing values between those runs (gaps). It appears in any situation where you have a sequence that may have breaks – an IDENTITY column where rows have been deleted, a date column where some dates are missing, or a package-scan sequence where some packages were not scanned. A typical result lists each island as a start-end range (e.g., 1-10, 15-18) and each gap similarly (e.g., 11-14, 19-19). The number of gaps is always one less than the number of islands in a given sequence.
2. How do you solve the gaps and islands problem in SQL Server?
The two most efficient set-based approaches are: (1) the row-number difference method, where you subtract a ROW_NUMBER() value from the sequence value – consecutive values in the same island produce the same difference, so you can GROUP BY that difference to find island boundaries; and (2) a self-join approach that finds rows whose neighbours are non-consecutive, marking those as island boundaries. This article demonstrates both, plus an alternative that converts the islands problem to a gaps problem and back. All approaches are pure T-SQL with no cursors, and benchmark test data shows each scales differently depending on the shape of the input data.
3. What is the fastest way to find gaps in a SQL sequence?
The fastest approach depends on the shape of the data – specifically the ratio of gap rows to island rows. For data with few gaps, a self-join that compares each row to the previous row (using LEAD() or LAG() in SQL Server 2012+) is very fast because most comparisons succeed quickly. For data with many gaps, the row-number difference approach is often faster because it processes each row exactly once. The article’s performance test harness benchmarks both approaches at 200,000 to 2,000,000 rows so you can see the crossover point for your own data shape.
4. What is the difference between gaps and islands in SQL?
Islands are unbroken runs of consecutive values in a sequence – groups where each value is exactly one more than the previous value. Gaps are the missing values between islands – ranges where no rows exist. In a sample set like (1, 2, 5, 6, 8, 9, 10), the islands are (1-2), (5-6), and (8-10); the gaps are (3-4) and (7-7). The two problems are complementary: solving one typically gets you the data you need to compute the other. The number of gaps is always one less than the number of islands when both are bounded by the same dataset.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments