
Contents
- NoSQL for the RDBMS fan
- Graph databases
- Getting started with graph databases
- First look at the Cypher language
- The Neo4J web user interface
- Creating nodes and relationships
- Using Neo4J in conjunction with SQL Server
- Avoiding graph anti-patterns
- Working with other database platforms
NoSQL for the RDBMS fan
I first heard the term NoSQL back in April 2010 at SQLBits VI Westminster during a session by Simon Munro. His session was certainly thought provoking, and I found his arguments compelling. The gist of them was “do we really need the overhead of an RDBMS for all of our data needs“?
The slides and presentation are still available on the SQLBits web site.
Since 2010, NOSQL solutions have certainly had a lot of press and generated much excitement in the developer community but, it has to be said, considerably less in the DBA community.
One of the points that Simon made during his presentation was that the NOSQL acronym means “Not Only” SQL. NOSQL solutions are not a replacement or successor for RDMBS systems, nor were they ever intended to be. They are useful tools to be used for specific purposes. They are to be used as part of an organisation’s data management solution and not as a total replacement for the existing solution.
Another point to bear in mind is that, by definition, the term NOSQL describes every data storage and retrieval mechanism that is not a traditional SQL database so they represent a very broad church with many hundreds of variations. A good starting point is to read Kristof Kovac’s blog piece on some of the larger players in the market place.
Graph databases
Of all the NOSQL databases, graph databases are the ones that fascinate me most. The idea is that, instead of tables specific to each type of element, there are nodes; and instead of fields representing entities, you simply have attributes and labels.
In the RDBMS world, customers and employees would almost certainly be stored in separate tables. Any relationships between a customer and an employee would then require additional tables to describe the relationship complete with foreign key relationships.
The employee hierarchy that represents the organisational structure would also require additional tables and foreign key relationships.
In a graph database there are merely nodes (sometimes called edges) and relationships (sometimes called vertices). To marry two different nodes together, the appropriate relationship can be created as a self-describing entity in its own right. There is no need for additional objects to facilitate that relationship.
Getting started with graph databases
Microsoft Research has a project called Trinity, which is a cloud-based graph database for which there is a growing body of information, but it is not yet available for use..
Neo4J is a popular open-source graph database and we will use this to demonstrate the power of graphs.
Installing Neo4J on Windows is straightforward.
- Download from http://www.neo4j.org/
- Run the resulting EXE file
- Run the program from the Windows start menu
- Click the Start button on the dialogue box shown below
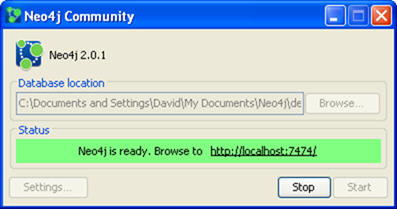
- Open a browser and go to
http://localhost:7474as shown in the dialogue box and you are ready to begin.
First look at the Cypher language
Neo4J has four ways of interacting with the database
- Using the API in a JVM-friendly language such as Java, Scala or Clojure.
- Using the REST web service interface
- Using the Cypher language in the web user interface
- Using the Cypher language in the Neo4J command shell.
The API is analogous to the SQL Server Management Objects offering a richer set of features than the Cypher query language.
Using Cypher within the web user interface is a good starting point for learning about graph databases and get used to the different way of thinking required to get the most out of them.
To some extent, Cypher is a pictorial language in that the queries look like the pattern of nodes and relationships that you are trying to retrieve.
- Nodes are described with rounded brackets
- Relationships are described with square brackets
A simple Cypher query look something like the following:-
|
1 |
MATCH(n)-[]->(r) WHERE r.name="SalesTerritory" RETURN n |
The MATCH statement is describing the node and relationship pattern we want to retrieve.
The RETURN statement is analogous to the SQL SELECT statement. In the example above it is like saying
|
1 |
SELECT n.* FROM SalesTerritory |
So this cypher query simply retrieves all the nodes that have a directed relationship of any description with a node with a name attribute of “SalesTerritory “.
Cypher also has a number of keywords that have a direct equivalence with SQL which makes it a curiously familiar language.
WHEREORDER BYLIMITSUM, COUNT, STDEVP, MIN, MAXetcLTRIM, UPPER, LOWER, REPLACE, LEFT, RIGHT, SUBSTRINGDISTINCTCASE
The Neo4J web user interface
The web user-interface is clearly laid out as shown below
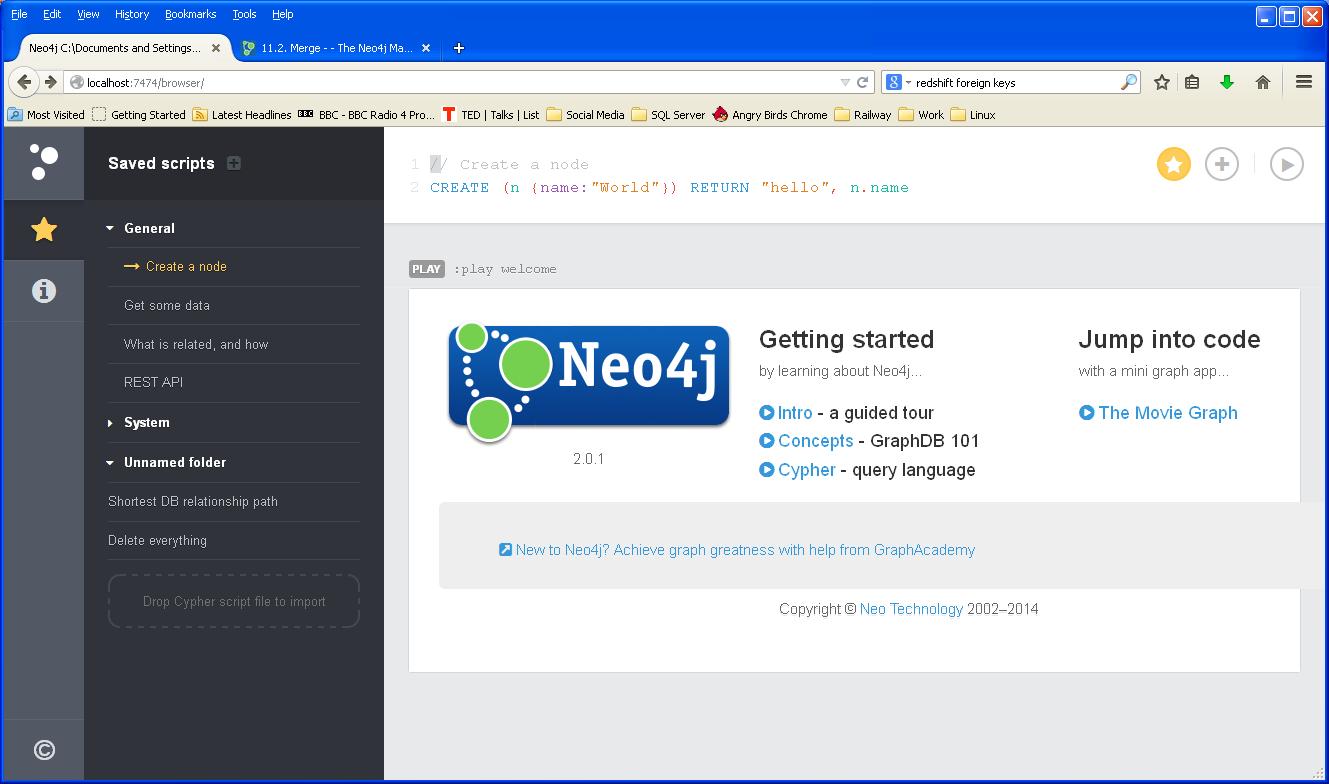
The left -hand pane is a short-cut mechanism for running pre-canned queries and accessing help content.
The large top-panel allows Cypher queries to be entered where they can be run or saved into the left hand panel. Note that files containing queries can be dragged into the bottom of the left hand navigation highlighted in red.
One useful tip is to include a comment at the top of the query and save it using the STAR symbol on the top right of the query pane. For example saving the following will show “Delete everything” as a saved query in the left hand pane.
|
1 2 3 4 |
// Delete everything MATCH(n) OPTIONAL MATCH (n)-[r]-() DELETE n,r |
The bottom half of the screen shows the results of queries.
Creating nodes and relationships
A word of warning before we start: The web user interface where we will be entering our Cypher queries is fussy about white space. Always leave a space between the query clause and the bracket that denotes the node.
So let us start with some entities which we are going to represent as nodes.
- Red-Gate software – Company
- Simple-Talk – website
- SQLServerCentral – website
- David Poole – amateur writer
- Steve Jones – Professional writer and editor
The Cypher to create these five entitles would be as follows:-
MERGE (:Company{name:"Red-Gate software"})MERGE (:Website{name:"Simple-Talk",url:"http://www.simple-talk.com"})MERGE (:Website{name:"SQLServerCentral",url:"http://www.sqlservercentral.com"})MERGE (:writer{name:"David Poole",category:"Amateur"})MERGE (:writer:editor{name:"Steve Jones",category:"Professional"})
This can be copied and pasted into the top pane of the web user interface as shown earlier.
We can now start to create the relationships. To do this we use the MATCH statement to retrieve two nodes and then create a relationship between them
|
1 2 3 |
MATCH(a:Company{name:"Red-Gate software"}),(b:Website{name:"Simple-Talk"}) MERGE (a)-[r:OWNS]->(b) RETURN r |
We are being quite explicit in our MATCH statement.
- Retrieve a node with a label of “Company” and whose name attribute is “Red-Gate software”
- Retrieve a node with a label of “Website” and whose name attribute is “Simple-Talk”
Given that the names are unique we could also have written our MATCH statement as …
|
1 |
MATCH(a{name:"Red-Gate software"}),(b{name:"Simple-Talk"}) |
Or, instead of selecting the attributes in our MATCH statement, we could have written the query as follows:-
|
1 2 3 4 |
MATCH(a),(b) WHERE a.name="Red-Gate software" AND b.name="Simple-Talk" MERGE (a)-[r:OWNS]->(b) RETURN r |
This is fine if we want to create our relationships one-by-one: but what if we want to create our nodes and relationships en-masse? We can do this by executing the script below.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
MERGE (a:Company{name:"Red-Gate software"}) MERGE (b:Website{name:"Simple-Talk",url:"http://www.simple-talk.com"}) MERGE (c:Website{name:"SQLServerCentral",url:"http://www.sqlservercentral.com"}) MERGE (d:writer{name:"David Poole",category:"Amateur"}) MERGE (e:writer:editor{name:"Steve Jones",category:"Professional"}) MERGE (a)-[:OWNS]->(b) MERGE (a)-[:OWNS]->(c) MERGE (d)-[:WRITES_FOR]->(b) MERGE (d)-[:WRITES_FOR]->(c) MERGE (e)-[:WRITES_FOR]->(c) MERGE (e)-[:EDITOR_OF]->(c) MERGE (e)-[:KNOWS]->(d) |
By giving our nodes identifiers (a, b, c, d & e ) when we create them, we can then use those identifiers further down our script to create the relationships
By running the following Cypher script, we will get a graphical representation of the items we have just created.
|
1 |
MATCH(n) RETURN n |
This simply retrieves every node and returns it.
The difference between the CREATE and the MERGE statement
It seems strange not to use a CREATE statement to create things. In fact we could have done so by replacing the MERGE statement with CREATE in our script and got exactly the same result.
The key differences are as follows:-
- MERGE will create a node or relationship only if there is no identical node or relationship.
- CREATE will simply create nodes and relationships irrespective of whether identical ones already exists.
- CREATE can create multiple nodes and relationships all at once. For example we could create the relationship between Red-Gate software, Simple-Talk and SQLServerCentral in one command.
|
1 |
CREATE (c:Website{name:"SQLServerCentral",url:"http://www.sqlservercentral.com"})<-[:OWNS]-(a:Company{name:"Red-Gate software"})-[:OWNS]->(b:Website{name:"Simple-Talk",url:"http://www.simple-talk.com"}) |
The Neo4J command shell
Neo4J does possess a command shell to give the equivalent of SQLCMD. Although this is not included in the community edition installer it is available for download.
To get this working with my existing installation of Neo4J I extracted the Neo4JShell.bat file from the downloaded ZIP file into my \Neo4j Community\bin\ folder.
After some experimentation I found that I had to edit Neo4JShell.bat
- If the batch file complains that it cannot find a JAR file then take the following steps
- Open the batch file in your preferred editor
- Navitage to the line that appears as follows
1%JAVACMD% %JAVA_OPTS% %EXTRA_JVM_ARGUMENTS% -classpath %CLASSPATH_PREFIX%;%CLASSPATH% -Dapp.name="neo4j-shell" -Dapp.repo="%REPO%" -Dbasedir="%BASEDIR%" org.neo4j.shell.StartClient %CMD_LINE_ARGS% - Replace the entirety of
%CLASSPATH_PREFIXand%CLASSPATH%with the path and JAR file name of neo4j-desktop-2.0.1.jar. In my particular case the line was edited to the following: –1%JAVACMD% %JAVA_OPTS% %EXTRA_JVM_ARGUMENTS% -classpath "C:\Program Files\Neo4j Community\bin\neo4j-desktop-2.0.1.jar" -Dapp.name="neo4j-shell" -Dapp.repo="%REPO%" -Dbasedir="%BASEDIR%" org.neo4j.shell.StartClient %CMD_LINE_ARGS%
Differences between the command shell and the Web UI
In both cases the batch terminator is a semi-colon character.
The Web UI can only execute a single batch even when it is running an imported file
The shell can run multiple batches provided each batch is separated with the semi-colon batch terminator.
The semi-colon batch terminator is mandatory in the Neo4J shell
Using Neo4J in conjunction with SQL Server
The main strength of a graph database is its ability to traverse the graph to find patterns. This includes the ability to find the shortest route between two points.
One of the challenges facing users of a data warehouse is to understand how the different tables within the warehouse relate to each other.
A graph database can solve this problem easily if we copy the table and foreign key metadata into a Cypher script.
Creating the nodes
For any given table we could set up nodes to record the following attributes:-
- Schema name
- Table name
- Table description – As stored in the
MS_DESCRIPTIONproperty.
As we will want to form the relationships we will also want to attach an identity to the node and assign different labels to the objects.
Using the Adventureworks database as the basis for creating nodes a typical node creation statement would appear as follows:-
|
1 |
CREATE (n:Productiontable{name:'ProductPhoto',schema:'Production',description:'Product images.'}) |
We can use a SQL view to generate the Cypher script we need from two system tables
- Sys.tables
- Sys.extended_properties
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE VIEW dbo.Cypher_Nodes AS WITH Datadictionary_Tables(ObjectID,SchemaName,TableName,TableDescription) AS ( SELECT CypherScript=T.OBJECT_ID, SchemaName=OBJECT_SCHEMA_NAME(T.object_id), TableName=T.NAME, TableDescription=COALESCE(CAST(EP.VALUE AS VARCHAR(MAX)),'') FROM sys.tables AS T LEFT JOIN sys.extended_properties AS EP ON T.object_id=EP.major_id and EP.minor_id=0 -- We only want the table descriptions and EP.name='MS_DESCRIPTION' ) SELECT CypherScript='CREATE (n' + CAST(objectID AS VARCHAR(10)) +':' + SchemaName + 'table{name:"' + tablename + ''',schema:"' + SchemaName + '",description:"' + REPLACE(TableDescription,char(34),'\"'+char(39)) + '"})' FROM DataDictionary_tables GO |
The key points for the query are as follows:-
- We use a common table expression to separate out data retrieval from data presentation
- Not all tables will have an extended property but when they do, we are only interested in the
MS_DESCRIPTIONproperty for the table and not any field descriptions represented by minor_id 1+ - The Cypher node identifier is a concatenation of “n” + the SQL Server object id because we need to reference that identifier to create the node relationships.
I have written the script to use the CREATE statement rather than the MERGE statement simply because any changes to the MS_DESCRIPTION property will cause MERGE to create a new node thereby limiting its effectiveness. Repopulating the graph is best done by deleting everything and starting again.
Creating the relationships
The Cypher to create the relationships will appear as follows:-
|
1 |
CREATE (n1173579219)-[:IS_RELATED_TO]->(n1698105090) |
The query to generate this can be generated straight from the system view sys.foreign_keys . Again we can encapsulate the query in a view.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE VIEW dbo.Cypher_Relationships AS SELECT CypherScript='CREATE (n' + CAST(parent_object_id AS varchar(10)) + ')-[:IS_RELATED_TO]->(n' + CAST(referenced_object_id AS varchar(10)) + ')' FROM sys.foreign_keys GO O |
To get our full Cypher script we could simply wrap both views up in a master view separated by the UNION ALL statement.
|
1 2 3 4 5 6 7 |
CREATE VIEW dbo.Cypher_GenerateNodesAndRelationships AS SELECT CypherScript FROM dbo.Cypher_Nodes UNION ALL SELECT CypherScript FROM dbo.Cypher_Relationships GO |
Querying the graph
To get a view of the entire graph simply run the “Get Some Data” command from the left hand pane of the Neo4J user interface. This simply issues the following command
|
1 |
MATCH(n) RETURN n LIMIT 100 |
This will produce a graphical representation of Adventureworks similar to the one below.
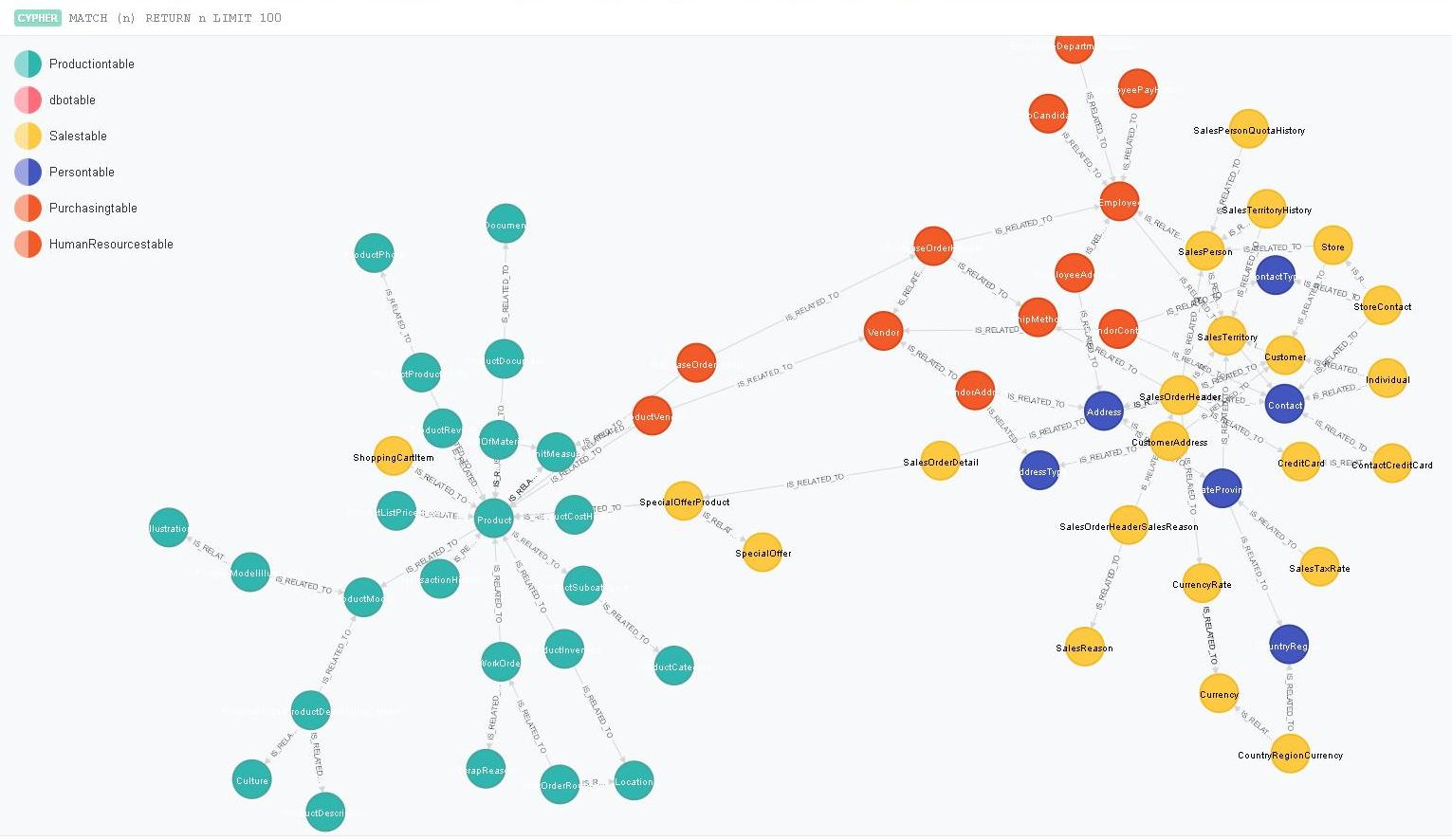
This is certainly picturesque but the real power of the graph becomes apparent when I run the query below
|
1 2 3 4 |
//Shortest DB relationship path MATCH(startTable { name:"ProductPhoto" }),(endTable { name:"Customer" }), p = shortestPath((startTable)-[*..15]-(endTable)) RETURN p |
In this query we are specifying two tables and asking the graph to find the shortest chain of relationships between the two up to a maximum of 15 links. The pictorial representation is shown below.
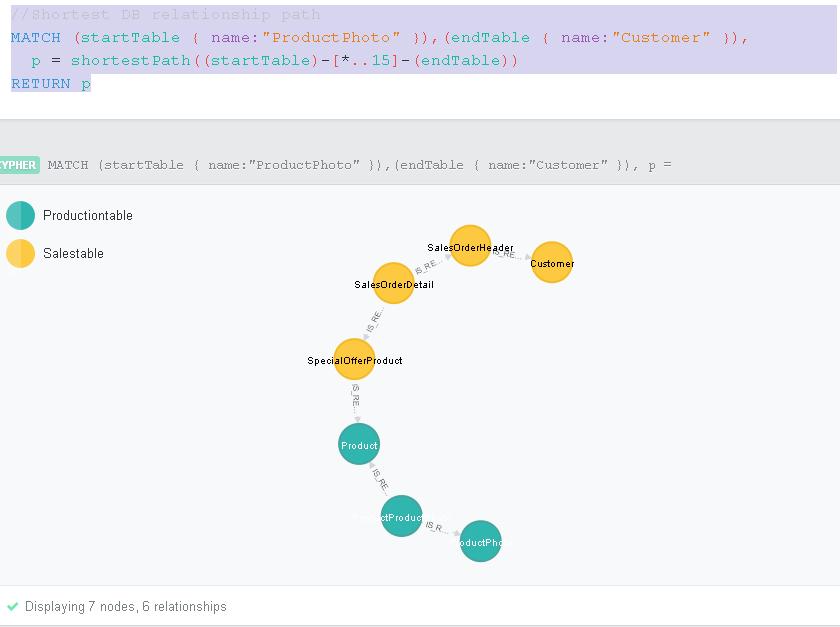
By clicking on the “Customer” node a dialogue box will appear as shown below.
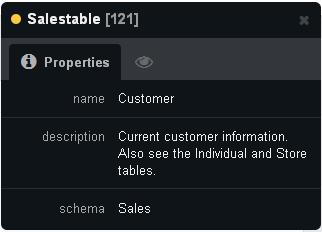
Here we can clearly see the properties we extracted from the Adventureworks schema.
Automating the import
The existence of the Neo4JShell.bat makes automation a straight-forward process.
The first stage is to create a SQL view that will return the Cypher that will remove all nodes and relationships from the graph
|
1 2 3 4 |
CREATE VIEW dbo.CypherDeleteAll AS SELECT 'MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r;' AS CypherScript |
Note the batch terminating semi-colon at the end of the generated Cypher command.
I create a further view to generate all Cypher commands required to enable the Neo4J shell to function
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE VIEW dbo.CypherRebuildAllNodesAndRelationships AS SELECT CypherScript FROM dbo.CypherDeleteAll UNION ALL SELECT CypherScript FROM dbo.Cypher_Nodes UNION ALL SELECT CypherScript FROM dbo.Cypher_Relationships UNION ALL SELECT ';' AS CypherScript GO |
As mentioned earlier a batch terminator is mandatory in the Neo4J shell hence the final SELECT in the above view.
I created a directory called c:\data\ and used BCP to pipe the output from this view to a file.
|
1 |
Bcp "Adventureworks.dbo.CypherRebuildAllNodesAndRelationships" out "c:\data\NEO.cql" -c -T -Slocalhost |
We are now ready to put together the constituent parts we need to build an automated metadata graph.
Within my c:\data\ directory I created a Windows command file as follows:-
|
1 2 3 4 5 |
echo off cls cd \Program Files\Neo4j Community\bin Bcp "Adventureworks.dbo.CypherRebuildAllNodesAndRelationships" out "c:\data\NEO.cql" -c -T -Slocalhost Neo4JShell -file "c:\data\Neo.cql" |
This successfully extracted the desired Cypher commands to a file and then executed those Cypher commands in the Neo4J shell.
Data warehouse concerns
The technique that we’ve described so far relies on the SQL database containing foreign key constraints.
In SQL Server, foreign keys can be disabled during the load, and the ETL process will then handle the data referential integrity enforcement. The syntax to do so is as follows.
|
1 |
ALTER TABLE <table name> NOCHECK CONSTRAINT <foreign key constraint name> |
I have seen data warehouse implementations where the foreign key relationships were left out altogether and therefore the techniques described in this article would not work.
I would take the view that foreign keys provide useful metadata, even if they are disabled and have no functional affect in the warehouse.
In database platforms such as HP Vertica and Amazon Red-Shift, foreign key constraints are purely metadata items. Note that HP Vertica does have a function that allows the retrospective identification of constraint violations.
Avoiding graph anti-patterns
It is possible for the relationships themselves to have properties so in our Adventureworks example it would be tempting to add details of the foreign key relationships to our Neo4J relationships.
This would be an anti-pattern
Properties on Neo4J relationships are intended to model the weight or importance of a relationship.
If we wanted to represent foreign key relationships in our Neo4J model and have a richer set of informational attributes then it would rather suggest that we should represent foreign keys as nodes in their own right.
Working with other database platforms
The technique described here will work with any SQL database that allows its table and relationship metadata to be queried.
MySQL Example queries
MySQL requires a slightly different query as it does not have the concept of an object id property or schemas within a database. In this case we will use the table name as an identifier.
Note that in MySQL, every property including the table description is held in viewINFORMATION_SCHEMA.TABLES.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT CONCAT ('CREATE (' , S.table_name , ':table{name:"' , S.table_name , '",schema:"' , S.table_schema , '",description:"' , COALESCE(S.TABLE_COMMENT ,'') , '"})' ) AS CypherScript FROM information_Schema.TABLES AS S where TABLE_TYPE='BASE TABLE' and TABLE_SCHEMA='quickestimate' SELECT CONCAT ('CREATE (' , REF.table_name , ')-[:IS_RELATED_TO]->(' , REF.REFERENCED_TABLE_NAME ,')') AS CypherScript FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS AS REF |
HP Vertica Example queries
HP Vertica is a platform where there is a single database instance containing one or more schemas.
It also has a rich set of system tables in a schema calledv_catalog . These are similar to the SQL Server sys views.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
SELECT 'CREATE (n' || CAST(S.table_id AS VARCHAR(10)) || ':' || S.table_schema || 'table{name:"' || S.table_name || '",schema:"' || S.table_schema || '",description:"' || COALESCE(C.comment ,'') || '"})' FROM v_catalog.tables AS S LEFT JOIN v_catalog.comments C ON S.table_schema = C.object_schema AND S.table_name = C.object_name WHERE S.table_name NOT IN ('v_internal', 'v_monitor', 'v_catalog') ORDER BY S.table_schema, S.table_name SELECT 'CREATE(n' || cast(P.table_id as varchar(10)) || ')-[:IS_RELATED_TO]->(n' || cast(C.table_id as varchar(10)) || ')' FROM v_catalog.foreign_keys AS FK INNER JOIN v_catalog.tables AS P on FK.table_schema = P.table_Schema and FK.table_name = P.table_name INNER JOIN v_catalog.tables AS C on FK.reference_table_schema = C.table_Schema and FK.reference_table_name = C.table_name |
Concluding thoughts on Neo4J
I have been impressed by the ease of use in setting up Neo4J and getting it working.
I was very struck by the fact that, with a very simple use-case, I soon got tangible benefits. This gave me a sense of the considerable potential of graph databases.
The Neo4J online documentation and tutorials are of a good standard and sufficiently clear to encourage experimentation. The inclusion of the “movies” database in the distribution gives a sufficiently varied dataset to try out most of the functionality on offer.
The web user interface, with its pictorial representation of the Cypher query-results, is a compelling way of demonstrating the effectiveness of a graph databases. Data can be a dry subject, so to have a user-interface that adds zest can only be a good thing.
I will certainly be carrying out further experiments with the technology.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments