
Over the years, you probably have experienced or heard that using user-defined functions (UDF’s) do not scale well as the number of rows processed gets larger and larger. Which is too bad, because we have all heard that encapsulating your code into modules promotes code reuse and is a good programming practice. Now the Microsoft SQL Server team have added a new feature to the database engine in Azure SQL Database and SQL Server 2019 that allows UDF’s performance to scale when processing large recordsets. This new feature is known as T-SQL Scalar UDF Inlining.
T-SQL Scalar UDF Inlining is one of many new features to improve performance that was introduced in the Azure SQL Database and SQL Server 2019. This new feature contains many options available in the Intelligent Query Processing (IQP) feature set. Figure 1 from Intelligent Query Processing in SQL Databases shows all the IQP features introduced in Azure SQL Database and SQL Server 2019, as well as features that originally were part of the Adaptive Query Processing feature set that was included in the older generation of Azure SQL Database and SQL Server 2017.
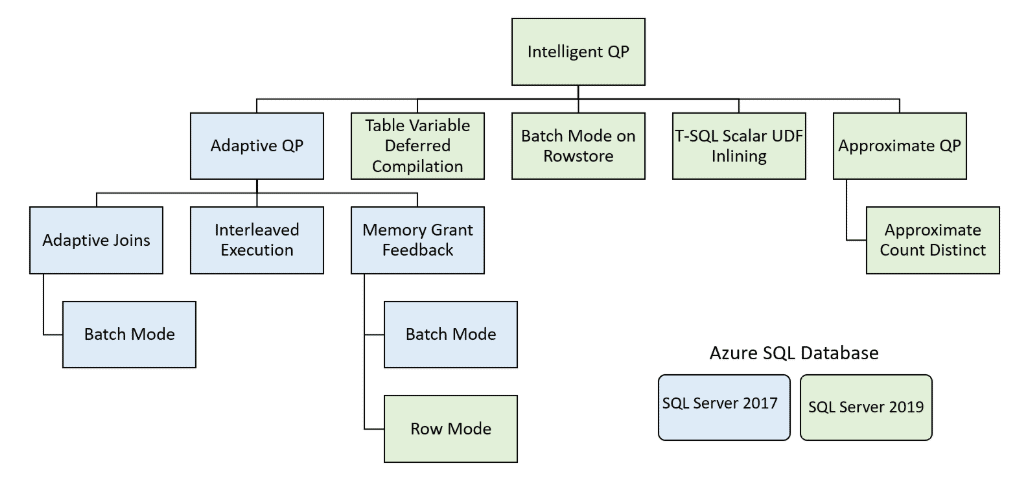
Figure 1: Intelligent Query Processing
The T-SQL Scalar UDF Inlining feature will automatically scale UDF code without having to make any coding changes. All that is needed is for your UDF to be running against a database in Azure SQL Database or SQL Server 2019, where the database has the compatibility level set to 150. Let me dig into the details of the new inlining feature a little more.
T-SQL Scalar UDF Inlining
The new T-SQL Scalar UDF Inlining feature will automatically change the way the database engine interprets, costs, and executes T-SQL queries when a scalar UDF is involved. Microsoft incorporated the FROID framework into the database engine to improve the way scalar UDFs are processed. This new framework refactors the imperative scalar UDF code into relational algebraic expressions and incorporates these expressions into the calling query automatically.
By refactoring the scalar UDF code, the database engine can improve the cost-based optimization of the query as well as perform set based optimization that allows the UDF code to go parallel if needed. Refactoring of scalar UDFs is done automatically when a database is running under compatibility level 150. Before I dig into the new scalar UDF inlining feature, let me review why scalar UDF’s are inherently slow, and discuss the differences between imperative and relational equivalent code.
Why are Scalar UDF Functions inherently slow?
When running a scaler UDF on a database with a compatibility level set to less than 150, they just don’t scale well. By scale, I mean they work fine for a few rows but run slower and slower as the number of rows processed gets larger and larger. Here are some of the reasons why scalar UDF’s don’t work well with large recordsets.
- When a T-SQL statement uses a scalar function, the database engine optimizer doesn’t look at the code inside a scalar function to determine its costing. This is because Scalar operators are not costed, whereas relational operators are costed. The optimizer considers scalar functions as a black box that uses minimal resources. Because scalar operations are not costed appropriately, the optimize is notorious for creating very bad plans when scalar functions perform expensive operations.
- A Scalar function is evaluated as a batch of statements where each statement is run sequentially one statement after another. Because of this, each statement has its own execution plan and is run in isolation from the other statements in the UDF, and therefore can’t take advantage of cross-statement optimization.
- The optimize will not allow queries that use a scalar function to go parallel. Keep in mind, parallelism may not improve all queries, but when a scalar UDF is being used in a query, that query’s execution plan will not go parallel.
Imperative and Relational Equivalent Code
Scalar UDFs are a great way to modularize your code to promote reuse, but all too often they contain procedural code. Procedural code might contain imperative code such as variable declarations, IF/ELSE structures, as well as WHILE looping. Imperative code is easy to write and read, hence why imperative code is so widely used when developing code for applications.
The problem with imperative code is that it is hard to optimize, and therefore query performance suffers when imperative code is executed. The performance of imperative code is fine when a small number of rows are involved, but as the row count grows, the performance starts to suffer. Because of this, you should not use them for larger record sets if they are executed on a database running with a compatibility less than 150. With the introduction of version 15.x of SQL Server, the scaling problem associated with UDFs has been solved by the refactoring of imperative code using a new optimization technique known as the FROID framework.
The FROID framework refactors imperative code into a single relational equivalent query. It does this by analyzing the scalar UDF imperative code and then converts blocks of imperative code into relational equivalent algebraic expressions. These relational expressions are then combined into a single T-SQL statement using APPLY operators. Additionally, the FROID framework looks for redundant or unused code and removes it from the final execution plan of the query. By converting the imperative code in a scalar UDF into re-factored relational expressions, the query optimizer can perform set-based operations and use parallelism to improve the scalar UDF performance. To further understand the difference between imperative code and relational equivalent code, let me show you an example.
Listing 1 contains some imperative code. By reviewing this listing, you can see it includes a couple of DECLARE statements and some IF/ELSE logic.
Listing 1: Imperative Code Example
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @Sex varchar(10) = 'Female'; DECLARE @SexCode int; IF @Sex = 'Female' SET @SexCode = 0 ELSE IF @Sex = 'Male' SET @SexCode = 1; ELSE SET @SexCode = 2; SELECT @SexCode AS SexCode; |
I have then re-factored the code in Listing 1 into a relational equivalent single SELECT statement in Listing 2, much like the FROID framework might doing it when compiling a scalar UDF.
Listing 2: Relational Code Example
|
1 2 3 4 5 6 |
SELECT B.SexCode FROM (SELECT 'Female' AS Sex) A OUTER APPLY (SELECT CASE WHEN A.Sex = 'Female' THEN 0 WHEN A.Sex = 'Male' THEN 1 ELSE 2 END AS SexCode) AS B; |
By looking at these two examples, you can see how easy it is to read the imperative code in Listing 1 to see what is going on. Whereas in Listing 2, which contains the relational equivalent code, requires a little more analysis/review to determine exactly what is happening.
- Currently, the FROID framework is able to rewrite the following scalar UDF coding constructs into relational algebraic expressions:
- Variable declaration and assignments using
DECLAREorSETstatement - Multiple variable assignments in a
SELECTstatement - Conditional testing using
IF/ELSElogic - Single or multiple
RETURNstatements - Nested/recursive function calls in a UDF
- Relational operations such as
EXISTSandISNULL
The two listings found in this section only logically demonstrate how the FROID framework might convert imperative UDF code into relational equivalent code using the FROID framework. For more detailed information on the FROID framework, I suggest you read this technical paper.
In order to see FROID optimization in action, let me show you an example that compares the performance of a scalar UDF running with and without FROID optimization.
Comparing Performance of Scalar UDF with and Without FROID Optimization
To test how a scalar UDF would perform with and without FROID optimization, I will run a test using the sample WorldWideImportersDW database (download here). In that database, I’ll create a scalar UDF called GetRating. The code for this UDF can be found in Listing 3.
Listing 3: Scalar UDF that contains imperative code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE OR ALTER FUNCTION dbo.GetRating(@CityKey int) RETURNS VARCHAR(13) AS BEGIN DECLARE @AvgQty DECIMAL(5,2); DECLARE @Rating VARCHAR(13); SELECT @AvgQty = AVG(CAST(Quantity AS DECIMAL(5,2))) FROM Fact.[Order] WHERE [City Key] = @CityKey; IF @AvgQty / 40 >= 1 SET @Rating = 'Above Average'; ELSE SET @Rating = 'Below Average'; RETURN @Rating END |
By reviewing the code in Listing 3 you can see that I am creating my scalar UDF that I will be using for testing. This function calculates a rating for a [City Key] value. The rating returned is either “Above Average” or “Below Average” based on 40 being the average rating. Note that this UDF contains imperative code.
In order to test how scalar inlining can improve performance I will be running the code in Listing 4.
Listing 4: Code to test performance of scalar UDF
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- Turn on Time Statistics SET STATISTICS TIME ON; GO USE WideWorldImportersDW; GO -- Set Compatibility level to 140 ALTER DATABASE WideWorldImportersDW SET COMPATIBILITY_LEVEL = 140; GO -- Test 1 SELECT DISTINCT ([City Key]), dbo.GetRating([City Key]) AS CityRating FROM Dimension.[City] -- Set Compatibility level to 150 ALTER DATABASE WideWorldImportersDW SET COMPATIBILITY_LEVEL = 150; GO -- Test 2 SELECT DISTINCT ([City Key]), dbo.GetRating([City Key]) AS CityRating FROM Dimension.[City] GO |
The code in Listing 4 runs two tests. The first test (Test 1) calls the scaler UDF dbo.GetRating using compatibility level 140 (SQL Server 2017). For the second test (Test 2), I only changed the compatibility level to 150 (SQL Server 2019) and ran the same UDF as Test 1 without making any coding changes to the UDF.
When I run Test 1 in Listing 4, I get the execution statistics shown in Figure 2 and the execution plan shown in Figure 3.

Figure 2: Execution Statistics for Test 1

Figure 3: Execution plan when using compatibility level 140 using Test 1
Prior to reviewing the time statistics and execution plan for Test 1 let me run Test 2. The time statistics and execution plan for Test 2 can be found in Figure 4 and Figure 5, respectfully.
![]()
Figure 4: Execution Statistics for Test 2

Figure 5: Execution plan when using compatibility level 150 using Test 2
Performance Comparison between Test 1 and Test 2
The only change I made between Test 1 and Test 2 was to change the compatibility level from 140 to 150. Let me review how the FROID optimization changed the execution plan and improved the performance when I executed my test using compatibility level 150.
Before running the two different tests, I turned on statistics time. Figure 6 compares the time statistics between the two different tests.
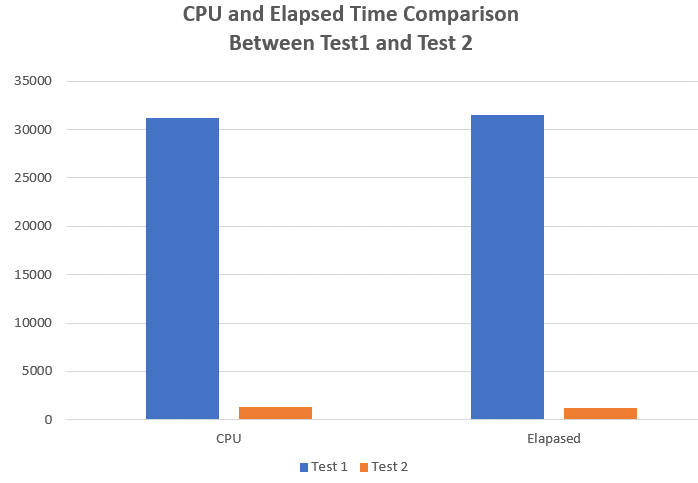
Figure 6: CPU and Elapsed Time Comparison Between Test 1 and Test 2
As you can see, when I executed the Test 1 SELECT statement in Listing 4 using compatibility level 140, the CPU and elapsed time took a little over 30 seconds. Whereas, when I changed the compatibility level to 150 and ran the Test 2 SELECT statement in Listing 4, my CPU and Elapsed time used just over 1second of time each. As you can see, Test 2, which used compatibility level 150 and the FROID framework, ran magnitudes faster than List 1 which ran under compatibility 140 without the FROID framework optimization. The improvement I gained using the FRIOD framework and compatibility level 150 achieved this performance improvement without changing a single line of code in my test scalar UDF. To better understand why the time comparisons were so drastically different between these two executions of the same SELECT statement, let me review the execution plans produced by each of these test SELECT queries.
If you look at Figure 3, you will see a simple execution plan when the SELECT statement was run under compatibility 140. This execution plan didn’t go parallel and only includes two operators. All the work related to calculating the city rating in the UDF using the data in the Fact.[Order] table is not included in this execution plan. To get the rating for each city, my scalar function had to run multiple times, once for every [City Key] value found in the Dimension.[City] table. You can’t see this in the execution plan, but if you monitor the query using an extended event, you can verify this. Each time the database engine needs to invoke my UDF in Test 1, a context switch has to occur. The cost of the row by row operation nature of calling my UDF over and over again causes the query in Test 1 to run slow.
If we look at the execution plan in Figure 5, which is for Test 2, you see a very different plan as compared to Test 1. When the SELECT statement in Test 2 was run, it ran under compatibility level 150, which allowed the scalar function to be inlined. By inlining the scalar function, FROID optimization converted my scalar UDF into a relational operation which allowed my UDF logic to be included in the execution plan of the calling SELECT statement. By doing this, the database engine was able to calculate the rating value for each [City Key] using a set-based operation, and then joins the rating value to all the cities in the Dimension.[City] table using an inner join nested loop operation. By doing this set based operation in Test 2, my query runs considerably faster and uses fewer resources than the row by row nature of my Test 1 query.
Not all Scalar Functions Can be Inlined
Not all scalar function can be inlined. If a scalar function contains coding practices that cannot be converted to relational algebraic expressions by the FRIOD framework, then your UDF will not be inlined. For instance, if a scalar UDF contains a WHILE loop, then the scalar function will not be inlined. To demonstrate this, I’m going to modify my original UDF code so it contains a dummy WHILE loop. My new UDF is called dbo.GetRating_Loop and can be found in Listing 5.
Listing 5: Scalar UDF containing a WHILE loop
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE OR ALTER FUNCTION dbo.GetRating_Loop(@CityKey int) RETURNS VARCHAR(13) AS BEGIN DECLARE @AvgQty DECIMAL(5,2); DECLARE @Rating VARCHAR(13); -- Dummy code to support WHILE loop DECLARE @I INT = 0; WHILE @I < 1 BEGIN SET @I = @I + 1; END SELECT @AvgQty = AVG(CAST(Quantity AS DECIMAL(5,2))) FROM Fact.[Order] WHERE [City Key] = @CityKey; IF @AvgQty / 40 >= 1 SET @Rating = 'Above Average'; ELSE SET @Rating = 'Below Average'; RETURN @Rating END |
By reviewing the code in Listing 5, you can see I added a dummy WHILE loop at the top of my original UDF. When I run this code using the code in Listing 6, I get the execution plan in Figure 7.
Listing 6: Code to run dbo.GetRating_Loop
|
1 2 3 4 5 6 7 8 9 10 |
USE WideWorldImportersDW; GO -- Set Compatibility level to 150 ALTER DATABASE WideWorldImportersDW SET COMPATIBILITY_LEVEL = 150; GO -- Test UDF With WHILE Loop SELECT DISTINCT ([City Key]), dbo.GetRating_Loop([City Key]) AS CityRating FROM Dimension.[City] GO |

Figure 7: Execution plan created while execution Listing 6.
By looking at the execution plan in Figure 7, you can see that my new UDF didn’t get inlined. The execution plan for this test looks very similar to the execution plan I got when I ran my original UDF in Listing 3 under database compatibility level 140. This example shows not all scalar UDF functions will be inlined. Just those scalar UDF that use only the functionality support by the FRIOD framework will be inline.
Disabling Scalar UDF Inlining
With this new version of SQL Server, the design team wanted to make sure you could disable any new features at the database level or statement level. Therefore, you can use the code in Listing 6 or 7 to disable scalar UDF inlining. Listing 6 shows how to disable scalar UDF inlining at the database level.
Listing 6: Disabling inlining at the database level
|
1 |
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF; |
Listing 7 shows how to disable scalar inlining when the scalar UDF is created.
Listing7: Disabling when defining UDF
|
1 2 3 4 |
CREATE FUNCTION dbo.MyScalarUDF (@Parm int) RETURNS INT WITH INLINE=OFF ... |
Make Your Scalar UDF just Run faster by Using SQL Server version 15.x
If you want to make your Scalar UDF run faster without making any coding changes, then SQL Server 2019 is for you. With this new version of SQL Server, the FROID framework was added. This framework will refactor a scalar UDF function into relational equivalent code that can be placed directly into the calling statement’s execution plan. By doing this, a scalar UDF is turned into a set-based operation instead of being called for every candidate row. All it takes to have a scalar UDF refactored is to set your database to compatibility level 150.
Load comments