
An indexed view in SQL Server is a view with a unique clustered index physically built on it – persisting the view’s result set on disk rather than recomputing it on every query. This makes complex aggregations and multi-table joins significantly faster when the same view is queried frequently, at the cost of additional storage and write overhead. SQL Server’s indexed views are equivalent to what other databases call materialised views.
Creating an indexed view requires two conditions: the view must be created WITH SCHEMABINDING (locking the underlying table schema), and a unique clustered index must be created on the view. In Enterprise Edition, the query optimiser automatically considers indexed views to satisfy queries; in Standard Edition, you must use the NOEXPAND hint explicitly.
SQL Server views are helpful in many ways, for example in encapsulating complex multi-table query logic, allowing us to simplify client code. Views make queries faster to write, but they don’t improve the underlying query performance. However, we can add a unique, clustered index to a view, creating an indexed view, and realize potential and sometimes significant performance benefits, especially when performing complex aggregations and other calculations. In short, if an indexed view can satisfy a query, then under certain circumstances, this can drastically reduce the amount of work that SQL Server needs to do to return the required data, and so improve query performance.
Indexed views can be a powerful tool, but they are not a ‘free lunch’ and we need to use them with care. Once we create an indexed view, every time we modify data in the underlying tables then not only must SQL Server maintain the index entries on those tables, but also the index entries on the view. This can affect write performance. In addition, they also have the potential to cause other issues. For example, if one or more of the base tables is subject to frequent updates, then, depending on the aggregations we perform in the indexed view, it is possible that we will increase lock contention on the view’s index.
This article will start from the basics of creating indexed views, and the underlying requirements in order to do so, and then discuss their advantages and the situations in which they can offer a significant boost to query performance. We’ll also consider the potential pitfalls of which you need to be aware before deciding to implement an indexed view.
From Views to Indexed Views
Nobody sets out to write overly complex queries. Unfortunately, however, applications grow more complex as the users demand new features, and so the accompanying queries grow more complex also. We don’t always have time to rewrite a query completely, or may not even know a better way to write it.
Standard SQL Server views can help. When we encapsulate complex multi-table query logic in a view, any application that needs that data is then able to issue a much simpler query against the view, rather than a complex multi-JOIN query against the underlying tables. Views bring other advantages too. We can grant users SELECT permissions on the view, rather than the underlying tables, and use the view to restrict the columns and rows that are accessible to the user. We can use views to aggregate data in a meaningful way.
Let’s say we need to run various queries against the AdventureWorks2012 database to return information regarding items that customers have purchased. The query in Listing 1 joins five tables to get information such as the client name, the order number and date, the products and quantities ordered.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT CUST.CustomerID , PER.FirstName , PER.LastName , SOH.SalesOrderID , SOH.OrderDate , SOH.[Status] , SOD.ProductID , PROD.Name , SOD.OrderQty FROM Sales.SalesOrderHeader SOH INNER JOIN Sales.SalesOrderDetail SOD ON SOH.SalesOrderID = SOD.SalesOrderID INNER JOIN Production.Product PROD ON PROD.ProductID = SOD.ProductID INNER JOIN Sales.Customer CUST ON SOH.CustomerID = CUST.CustomerID INNER JOIN Person.Person PER ON PER.BusinessEntityID = CUST.PersonID; |
Listing 1
Notice that we use two-part naming for all tables. Not only is this a good practice, it’s also a requirement when creating an indexed view (we’ll discuss further requirements as we progress). Let’s assume that many applications need to run queries like this, joining the same tables, and referencing the same columns in various combinations. To make it easier for our application to consume this data, we can create a view
Create a View
Listing 2 creates a view based on our query definition, as shown in Listing 2.
|
1 2 3 4 |
CREATE VIEW Sales.vCustomerOrders WITH SCHEMABINDING AS <Select Statmenet from Listing 1> |
Listing 2
Note that the WITH SCHEMABINDING option is included here and is a requirement for creating an index on the view, which we’ll want to do shortly. This option stipulates that we cannot delete any of the base tables for the view, or ALTER any of the columns in those tables. In order to make one of these changes, we would have to drop the view, change the table, and then recreate the view (and any indexes on the view).
Now, each application simply has to run a much simpler query referencing the view, as shown in Listing 3.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT CustomerID , FirstName , LastName , SalesOrderID , OrderDate , Status , ProductID , Name , OrderQty FROM Sales.vCustomerOrders CO; |
Listing 3
However, when looking at the execution plan (Figure 1) we can see that SQL Server still performs index scans against each of the five underlying tables.
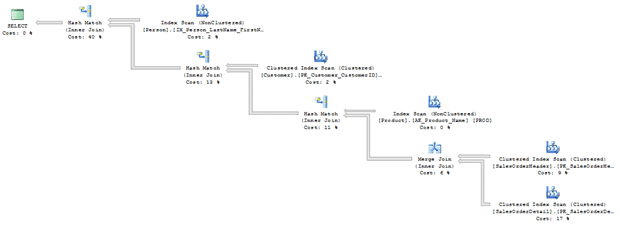
Figure 1
Likewise, the STATISTICS IO output (Figure 2) shows that SQL Server performed 2,172 logical reads against the five base tables.

Figure 2
The execution plan reports the query cost as 6.01323, as shown in Figure 3.
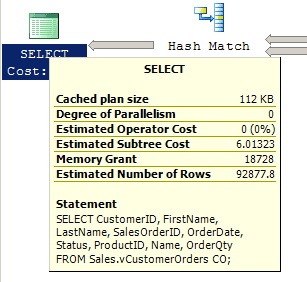
Figure 3
We see the exact same execution plan, STATISTICS IO output, and query cost if we run the query in Listing 1 again.
Although the use of the view made writing the query easier, it had no impact on query performance. A simple view is just a virtual table, generated from a saved query. It does not have its own physical page structure to use, so it reads the pages of its underlying tables. In other words, when we query a simple view, the optimizer still has to access all of the underlying tables and perform the necessary JOINs and aggregations. It derives cardinality estimations, and hence the query plan, from statistics associated with those tables.
Let’s see what happens, however, if we turn our standard view into an indexed view.
Create a Unique, Clustered Index
Before we start, I should mention that there are a host of requirements attached to the creation of indexed views, in any SQL Server Edition. We’ll discuss these in more detail in the Indexed View Requirements section, but if you have trouble creating an index on a view, it’s likely you’re breaking one of the rules.
In order to turn our normal Sales.vCustomerOrders view into an indexed view, we need to add a unique clustered index, as shown in Listing 4.
|
1 2 |
CREATE UNIQUE CLUSTERED INDEX CIX_vCustomerOrders ON Sales.vCustomerOrders(CustomerID, SalesOrderID, ProductID); |
Listing 4
When we add a unique clustered index to a view, we ‘materialize’ it. In other words, the ‘virtual table’ persists to disk, with its own page structure, and we can treat it just like a normal table. Any aggregations defined by the indexed view are now pre-computed, and any joins pre-joined, so the engine no longer has to do this work at execution time. SQL Server creates statistics for the indexed view, different from those of the underlying tables, to optimize cardinality estimations.
A well-crafted indexed view can write fewer pages to disk than the underlying tables, meaning fewer pages queries need to read fewer pages to return results. This means faster, more efficient queries. Use the techniques and tips in this article to ensure your views are optimal!
Let’s see the impact of our indexed view on query performance. These examples assume you’re running SQL Server Enterprise Edition, which will automatically consider indexes on a view when creating a query execution plan, whereas SQL Server Standard Edition won’t; you’ll need to use the WITH (NOEXPAND) table hint directly in the FROM clause of any query you wish to use the view (more on this shortly).
When we re-run the query from Listing 3, we get the same result set, but the execution plan, shown in Figure 4, looks very different. Rather than several index scans with joins, the optimizer now determines that the optimal way to satisfy the query is to scan the clustered index of our view.

Figure 4
The optimizer now reads all the pages required from one index, rather than five, and STATISTICS IO output reveals that this results in a 27% reduction in the number of logical reads the engine must perform in order to return the data, from 2,172 to 1,590.
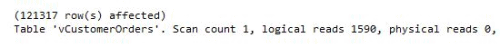
Figure 5
The overall query cost falls to 1.30858, as seen in Figure 6.
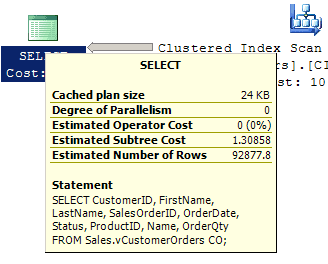
Figure 6
It’s not only queries that reference the view directly that will benefit in this way. Any query that the Optimizer determines the view could satisfy can use the indexed view rather than underlying tables, a process termed view matching. Try re-running Listing 1, which references the base tables rather than our indexed view. The Optimizer determines that the view’s index is the optimal way to retrieve the data and the execution plan will be identical to that in Figure 4.
In Listing 5, we access the same base tables but also perform some aggregations.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT CUST.CustomerID , SOH.SalesOrderID , SOH.OrderDate , SOD.ProductID , PROD.Name , SUM(SOD.OrderQty) AS TotalSpent FROM Sales.SalesOrderHeader SOH INNER JOIN Sales.SalesOrderDetail SOD ON SOH.SalesOrderID = SOD.SalesOrderID INNER JOIN Production.Product PROD ON PROD.ProductID = SOD.ProductID INNER JOIN Sales.Customer CUST ON SOH.CustomerID = CUST.CustomerID INNER JOIN Person.Person PER ON PER.BusinessEntityID = CUST.PersonID GROUP BY CUST.CustomerID , SOH.SalesOrderID , SOH.OrderDate , SOD.ProductID , PROD.Name; |
Listing 5
Here, the execution plan shows that the Optimizer chose to use the clustered index on the view, rather than indexes on the base tables.
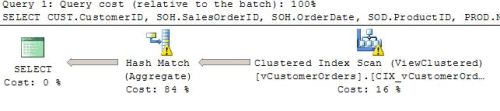
Figure 7
This execution plan shows a yellow exclamation point over the clustered index scan, which is warning us of “Columns with no statistics”. We’ll discuss this in more detail shortly.
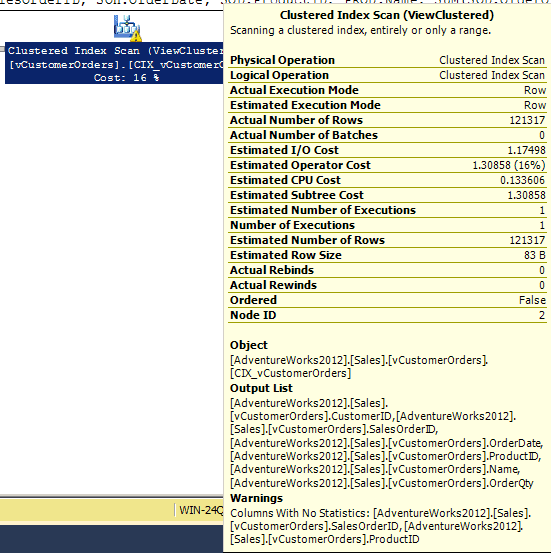
Figure 8
Aggregating Data with Indexed Views
Indexed views can really come into their own when we have many applications that need to perform complex aggregations, and other calculations, on the same set of base tables. Rather than force SQL Server to perform these aggregations and calculations every time, upon query execution, we can encapsulate them in an indexed view. This can significantly reduce the amount of IO SQL Server must perform to retrieve the necessary data, and CPU time required to perform the calculations, and so can provide tremendous performance boosts.
Before we dive into another example, it’s worth mentioning again that, despite the potential performance benefits, caution is required when implementing an indexed view unless the base tables are relatively static. We’ll discuss this in more detail shortly.
Consider the query in Listing 6.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT CUST.CustomerID , SOH.SalesOrderID , SOD.ProductID , SUM(SOD.OrderQty) AS TotalOrderQty , SUM(LineTotal) AS TotalValue FROM Sales.SalesOrderHeader SOH INNER JOIN Sales.SalesOrderDetail SOD ON SOH.SalesOrderID = SOD.SalesOrderID INNER JOIN Production.Product PROD ON PROD.ProductID = SOD.ProductID INNER JOIN Sales.Customer CUST ON SOH.CustomerID = CUST.CustomerID INNER JOIN Person.Person PER ON PER.BusinessEntityID = CUST.PersonID GROUP BY CUST.CustomerID , SOH.SalesOrderID , SOD.ProductID; |
Listing 6
This query produces an execution plan with several index scans and joins, shown in Figure 9. It also requires aggregation. Its execution plan is similar in nature to the one we saw in Figure 4, but with additional operations and a higher cost, of 7.62038.
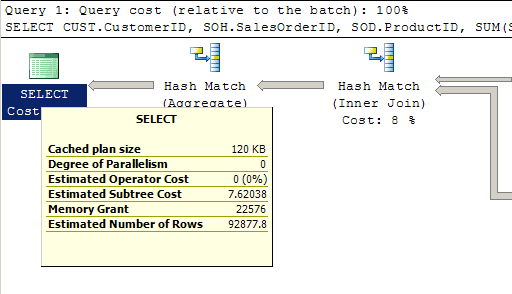
Figure 9
The logical reads are high as well, spanning several tables, as seen in Figure 10.
|
1 2 3 4 5 6 7 |
(121317 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderDetail'. Scan count 1, logical reads 1246, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeader'. Scan count 1, logical reads 58, physical reads 1, read-ahead reads 63, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 1, logical reads 123, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 1, logical reads 67, physical reads 1, read-ahead reads 65, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Product'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
Figure 10
Listing 7 creates an indexed view, vSalesSummaryCustomerProduct, to help reduce the cost of this and similar queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE VIEW Sales.vSalesSummaryCustomerProduct WITH SCHEMABINDING AS SELECT CUST.CustomerID , SOH.SalesOrderID , SOD.ProductID , SUM(SOD.OrderQty) AS TotalOrderQty , SUM(LineTotal) AS TotalValue , COUNT_BIG(*) AS CountLines FROM Sales.SalesOrderHeader SOH INNER JOIN Sales.SalesOrderDetail SOD ON SOH.SalesOrderID = SOD.SalesOrderID INNER JOIN Production.Product PROD ON PROD.ProductID = SOD.ProductID INNER JOIN Sales.Customer CUST ON SOH.CustomerID = CUST.CustomerID INNER JOIN Person.Person PER ON PER.BusinessEntityID = CUST.PersonID GROUP BY CUST.CustomerID , SOH.SalesOrderID , SOD.ProductID; GO CREATE UNIQUE CLUSTERED INDEX CX_vSalesSummaryCustomerProduct ON Sales.vSalesSummaryCustomerProduct(CustomerID, SalesOrderID, ProductID); GO |
Listing 7
Note the use of COUNT_ BIG( *) in this view, a requirement for indexed views that have a GROUP BY. It is there for the internal maintenance of indexed views – it maintains a count of the rows per group in the indexed view.
Now we can return the same result set by running the simple query in Listing 8.
|
1 2 3 4 5 |
SELECT CustomerID , SalesOrderID , TotalOrderQty , TotalValue FROM Sales.vSalesSummaryCustomerProduct; |
Listing 8
Figure 11 shows that we’ve reduced the query cost from 7.62038 to 0.694508. If we check the STATISTICS IO output, we’ll also find a substantial reduction in the number logical reads, from 1,498 across five indexes to 758.
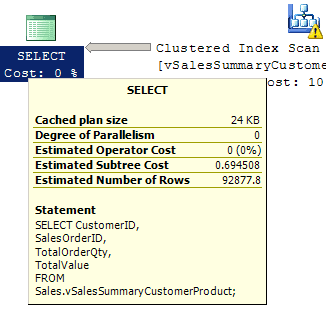
Figure 11
Again, notice the yellow exclamation mark; hovering over the index scan icon reveals that it is a “Columns with no statistics” warning on the SalesOrderID column, the second column in the clustered index key. We can see that SQL Server has created a statistics object for this clustered index, as shown in Figure 12.
Figure 12
However, if we run the query using the WITH (NOEXPAND) hint, as shown in Figure 14, we will no longer see the warning.
|
1 2 3 4 5 |
SELECT CustomerID , SalesOrderID , TotalOrderQty , TotalValue FROM Sales.vSalesSummaryCustomerProduct WITH ( NOEXPAND ); |
Listing 9
What is going on? The difference lies in when and how SQL Server creates automatic statistics, and when it uses them. Simply put, if we do not use the WITH (NOEXPAND) hint when querying an indexed view, the query optimizer will not use statistics created on the indexed view and neither will it create or update statistics automatically (i.e. those statistics objects that begin with _WA_SYS).
Without automatically created or updated statistics, there can be a slight or even drastic difference between the numbers of rows the optimizer estimates a query will return, and the actual number of rows returned. Pay attention to statistics warnings if you see them!
What is the lesson to be learned here? Using the WITH (NOEXPAND) hint when writing queries that reference indexed views is the best way to ensure optimal query plans.
For a more in-depth review of statistics, try Managing SQL Server Statistics, by Erin Stellato. For a thorough review of indexed views and statistics, reference Paul White’s article Indexed Views and Statistics.
Wait, SQL Server didn’t use my index!
Unfortunately, there may still be occasions when the query optimizer decides not to use an indexed view, even though it seems that it could satisfy a query. In fact, SQL Server may refuse to use the clustered index (or any non-clustered indexes) on a view, even if we reference the view directly in the query.
Let’s return to our vCustomerOrders example. Let’s say we want to query the view for the total number of orders a customer has placed, along with the total value of those orders, and we want to search by CustomerID.
|
1 2 3 4 5 6 |
SELECT CustomerID , COUNT(SalesOrderID) AS OrderCount , SUM(TotalValue) AS OrderValue FROM Sales.vSalesSummaryCustomerProduct WHERE CustomerID = 30103 GROUP BY CustomerID; |
Listing 10
The execution plan, in Figure 13, shows that the plan references the underlying tables and ignores our view and its index. The query cost is .072399.
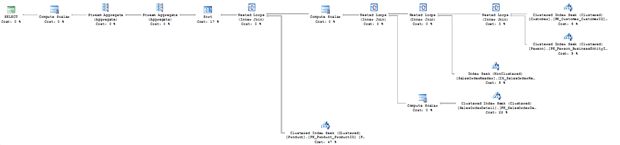
Figure 13
To make the query optimizer use the unique clustered index I created on vSalesSummaryCustomerProduct, we can use the NOEXPAND hint.
|
1 2 3 4 5 6 |
SELECT CustomerID , COUNT(SalesOrderID) AS OrderCount , SUM(TotalValue) AS OrderValue FROM Sales.vSalesSummaryCustomerProduct WITH ( NOEXPAND ) WHERE CustomerID = 30103 GROUP BY CustomerID; |
Listing 11
Now, the execution plan shows a clustered index seek, as shown in Figure 14, and the query cost is .003522.

Figure 14
Adding Non-clustered Indexes to an Indexed View
Once we’ve created an indexed view we can then treat it in much the same way as a normal table. We can add non-clustered indexes to boost query performance. Once again, exercise care. SQL Server has to maintain every index we add to a view, every time someone updates one of the contributing base tables. Indexed views work better for relatively static base tables.
Let’s say we want to query our Sales.vCustomerOrders view by product name.
|
1 2 3 4 5 6 7 8 9 |
DECLARE @ProductName VARCHAR(50) SET @ProductName = 'LL Mountain Frame - Black, 44' SELECT CustomerID , SalesOrderID , OrderQty , Name FROM Sales.vCustomerOrders WHERE Name = @ProductName; |
Listing 12
We get a clustered index scan on the view and the query cost is 1.30858.
Figure 15
It’s great that SQL Server is using the clustered index on the view; but a scan isn’t what we want; a seek would be better. However, once the clustered index exists, we can easily add useful non-clustered indexes, just as we can for any normal table.
|
1 2 |
CREATE NONCLUSTERED INDEX IX_vCustomerOrders_Name ON Sales.vCustomerOrders(Name); |
Listing 13
When we run the query in Listing 12 again, the execution plan is as shown in Figure 16. The query cost has gone down, to 1.27252.
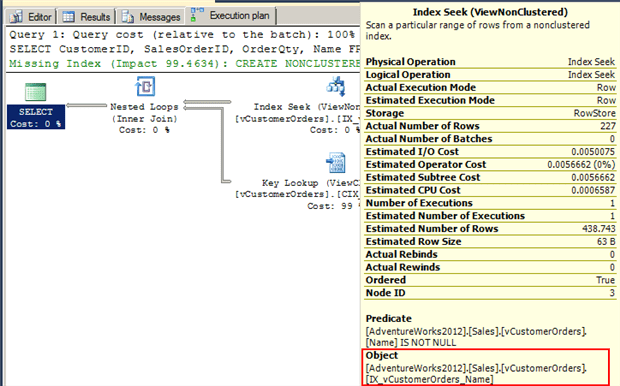
Figure 16
This time the optimizer chose a seek operation on the new non-clustered index, which is what we wanted. However, it also needed to perform a key lookup to return the additional columns contained in the SELECT clause but not included in the non-clustered index.
To make this index more effective, we can make it a covering index for this query by including all of the columns the query references, as shown in Listing 14.
|
1 2 3 4 5 6 7 |
DROP INDEX IX_vCustomerOrders_Name ON Sales.vCustomerOrders; GO CREATE NONCLUSTERED INDEX IX_vCustomerOrders_Name ON Sales.vCustomerOrders(Name) INCLUDE (SalesOrderID, CustomerID, OrderQty); GO |
Listing 14
When we run the query again, we see an optimized index seek on the non-clustered index. We also see a significantly reduced query cost, down to .0059714.
Indexed View Requirements
An underlying assumption of all previous query examples was use of SQL Server Enterprise Edition. In this edition, SQL Server’s query optimizer will automatically consider indexes on a view when creating a query execution plan. In SQL Server Standard Edition, we can still create indexed views, but the optimizer will not automatically consider its indexes when formulating an execution plan for a query; it will simply access all of the underlying tables. We have to use the WITH (NOEXPAND) table hint, directly in the FROM clause of each query, to force SQL Server to use the indexed view.
|
1 2 |
SELECT <column-list> FROM Sales.vCustomerOrders CO WITH ( NOEXPAND ); |
Listing 15
We also noted occasions, even when using SQL Server Enterprise Edition, when we may need to use this hint to get the plan we expect. However, it can be dangerous to boss the query optimizer around, telling it what it can or can’t do. Bear in mind also that if you write queries in stored procedures, your applications, or reports that use WITH (NOEXPAND) and then drop the index on the view at a later point in time, the queries that reference that index will fail. In short, the same proviso applies here as applies to the use of any table (index), join, or query hints: use them cautiously and sparingly, and document them.
As well as this requirement when using views on Standard Edition, there is a lengthy list of ‘requirements’ attached to the creation of indexed views, in any SQL Server Edition. We’ve encountered several already, in the need to create them with the SCHEMABINDING option, use fully qualified table references, and use COUNT_ BIG ( *) if the view definition contains a GROUP BY clause. Another, implied but not discussed directly, is that the indexed view definition can only reference tables, not other views.
The Microsoft documentation (http://msdn.microsoft.com/en-us/library/ms191432.aspx) provides a full list of limitations and requirements, so I’ll just briefly summarize some of the more significant here:
- Certain database
SEToptions have required values if we wish to create any indexed views in that database – for example,ANSI_NULLS,ANSI_PADDING,ANSI_WARNINGS,ARITHABORT,CONCAT_NULL_YIELDS_NULL, andQUOTED_IDENTIFIERmust beON;NUMERIC_ROUNDABORTmust beOFF. - All columns referenced in the view must be deterministic – that is, they must return the same value each time. As an example,
GETDATE( )is non-deterministic.DATEADDandDATEDIFFare deterministic. - We cannot include certain common functions in an indexed view –
COUNT,DISTINCT,MIN,MAX,TOP, and more. - You can’t have a self-join or an outer join, an
OUTER APPLYor aCROSS APPLY.
If you are having difficulty creating an index on a view, reference the Microsoft documentation, as you’ve broken one of the ‘rules’.
Impact of Updating the Base Tables
A few times, I’ve mentioned the impact of modifying data, i.e. inserting into, updating or deleting from, the base tables of an indexed view, and it’s now time to discuss this issue in more detail.
SQL Server has to guarantee that it can return a consistent result set regardless of whether a query accesses a view or the underlying tables, so it will automatically maintain indexes in response to data modifications on the base tables. We can see this in action if we update one of the base tables that make up our vSalesSummaryCustomerProduct view.
|
1 2 3 4 |
UPDATE Sales.SalesOrderDetail SET OrderQty = 5 WHERE SalesOrderID = 71803 AND ProductID = 917; |
Listing 16
|
1 2 3 4 5 6 7 8 |
Table 'vCustomerOrders'. Scan count 0, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Product'. Scan count 0, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 0, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 0, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeader'. Scan count 0, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 3, logical reads 11, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'vSalesSummaryCustomerProduct'. Scan count 0, logical reads 15, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderDetail'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
Figure 17
The execution plan includes many operators, including an update of the vSalesSummaryCustomerProduct clustered index.
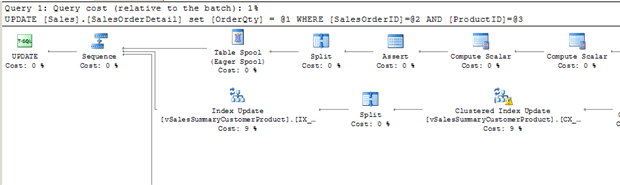
Figure 18
SQL Server must always ensure that the data in the index and base tables is synchronized, so we need to be careful when adding indexes to views. Every time an underlying column has a new row added or deleted, or is updated, SQL Server must maintain every clustered and non-clustered index, whether on the base table or the referenced indexed view. This will lead to additional writes, which can decrease performance.
Another side effect of indexed views is increased potential for blocking on the base tables during inserts, updates, and deletes, due to increased lock contention on the view’s index. Let’s say we want to insert two records into the SalesOrderHeader table. With no indexed view referenced by the table, both inserts will succeed. However, add an indexed view and the behavior will change. The first insert will have to modify a row in the table, and it will have to modify the index. It will hold locks on both objects. Until that has completed, the second operation will not be able to complete because it also needs locks on both objects.
A great demo of this is available from Alex Kuznetsov in his article, Be ready to drop your indexed view.
Directly Modifying a View
Can we, and should we, insert into, update, or delete from an indexed view, directly? Yes, we can, and no, we probably shouldn’t.
The conditions for directly modifying data in an indexed view are the same as for a regular view, namely:
- The columns can only be from one underlying table
- The columns can’t be derived – so you can’t have an aggregation, function, or computation
- The columns can’t be affected by
GROUP BY,HAVING, orDISTINCT - The view can’t use
TOPwithWITH CHECK OPTION
Those are the official rules, but there are a host of other things to think about, as well. For example, when inserting into a table via a view, if there are NOT NULL columns defined in the table, but are not in the view, your insert will fail, as demonstrated with this example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE VIEW Production.vProductInfoCategory WITH SCHEMABINDING AS SELECT PC.Name AS CategoryName , PSC.Name AS SubcategoryName , PROD.ProductID , PROD.ProductNumber , PROD.Name AS ProductName FROM Production.Product PROD INNER JOIN Production.ProductSubcategory PSC ON PSC.ProductSubcategoryID = PROD.ProductSubcategoryID INNER JOIN Production.ProductCategory PC ON PC.ProductCategoryID = PSC.ProductCategoryID; GO CREATE UNIQUE CLUSTERED INDEX CIX_vProductInfoCategory ON Production.vProductInfoCategory(ProductID); GO INSERT INTO Production.vProductInfoCategory ( ProductNumber , ProductName ) VALUES ( 'VE-C304-XL' , 'Classic Vest, XL' ); GO |
Listing 17
Running this query results in the error in Figure 19.
|
1 2 3 |
Msg 515, Level 16, State 2, Line 1 Cannot insert the value NULL into column 'SafetyStockLevel', table 'AdventureWorks2012.Production.Product'; column does not allow nulls. INSERT fails. |
Figure 19
The column SafetyStockLevel was not part of the view, and not part of my insert, but it is one of the NOT NULL columns defined in the table.
Generally, unless there are security reasons to use a view for inserts, or you are using an indexed view to enforce a uniqueness constraint, I don’t recommend inserting, updating, or deleting in views. It is much easier to deal directly with the base tables.
Summary
Views are a powerful tool in SQL Server to help you write queries more efficiently and provide a layer of additional security. With indexed views, we can also significantly reduce the I/O, cost, and duration for a query. They can make complex aggregations more efficient and we can even apply additional non-clustered indexes to help satisfy further queries.
As with any tool, we must use it with care. In the case of indexed views, it’s best to assess the volatility of the data in the underlying tables, since every time someone modifies the base table, SQL Server must maintain all indexes, including those on the view. This can affect write performance and it can sometimes lead to increased lock contention and blocking during data modifications.
Learn the benefits and drawbacks of indexed views and test them in your environment. They are another tool to have in your T-SQL toolbox.
Further Reading
- SQL View Basics https://www.simple-talk.com/sql/learn-sql-server/sql-view-basics/
- Create Index Views http://msdn.microsoft.com/en-us/library/ms191432.aspx
- Designing and Implementing Views http://technet.microsoft.com/en-us/library/ms189918(v=sql.105).aspx
- Improving Performance with SQL Server 2008 Indexed Views http://msdn.microsoft.com/en-us/library/dd171921.aspx
- Indexed Views and Statistics http://www.sqlperformance.com/2014/01/sql-plan/indexed-views-and-statistics
- Incorrect results with indexed views http://sqlblog.com/blogs/paul_white/archive/2013/02/06/incorrect-results-with-indexed-views.aspx
- Caution with Indexed Views http://blogs.msdn.com/b/microsoftbob/archive/2009/08/15/cautions-with-indexed-views.aspx
- Be ready to drop your indexed view http://sqlblog.com/blogs/alexander_kuznetsov/archive/2009/06/02/be-ready-to-drop-your-indexed-view.aspx
- Optimizing Queries Using Materialized Views: A Practical, Scalable Solution http://db.uwaterloo.ca/db_seminars/notes/larson-paper.pdf
FAQs: Indexed views in SQL Server
1. What is an indexed view in SQL Server?
An indexed view is a view with a unique clustered index physically materialised on it. Unlike a standard view (which executes its underlying query on every access), an indexed view stores the query results on disk – similar to a table. This makes it fast for read-heavy workloads with complex aggregations, but adds write overhead because INSERT, UPDATE, and DELETE operations on the base tables must also update the indexed view’s stored data.
2. What is the difference between a SQL Server indexed view and a materialized view?
They are the same concept under different names. SQL Server calls them indexed views; Oracle, PostgreSQL, and other databases call the same concept materialized views. Both persist view results to disk for fast repeated query access. The implementation details differ: SQL Server requires WITH SCHEMABINDING and a unique clustered index; PostgreSQL uses CREATE MATERIALIZED VIEW directly without requiring a separate index creation step.
3. What are the requirements for creating an indexed view in SQL Server?
(1) The view must be created WITH SCHEMABINDING – this locks the underlying table schema so columns referenced by the view cannot be dropped or altered without dropping the view first. (2) The view cannot use *, subqueries, derived tables, row-set functions, UNION, OUTER JOIN, or non-deterministic functions. (3) The first index on the view must be a unique clustered index. (4) For the optimiser to automatically use the indexed view in Enterprise Edition, the view definition and the query must reference the same base tables. In Standard Edition, use NOEXPAND hint to force usage.
4. When should I use an indexed view in SQL Server?
Indexed views are most valuable when: (1) the view is queried frequently and the underlying query is expensive (multi-table join with aggregations); (2) the base tables are updated infrequently relative to the read frequency (otherwise write overhead outweighs read gains); and (3) you are using Enterprise Edition and want the optimiser to consider the indexed view automatically. Avoid indexed views for views on OLTP tables with high write rates – the write overhead on the indexed view can become a bottleneck.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments