
My last article, SQL Server Database Growth and Autogrowth Settings, discussed why it is generally a bad practice to use the default ‘auto-grow’ settings for a database: there is a risk that it will result in the creation of a huge numbers of virtual log files (VLFs) in the transaction log. This “internal” fragmentation of the log file can affect the performance of any process that needs to read the log file, such as database and log backups, DBCC CHECKDB, crash recovery, and more. Furthermore, the auto-growth events that lead to fragmentation can slow down the performance of log writes during data loads.
How many virtual log files do your transaction logs contain? This article will explain the concept of the virtual log file, how to detect the number of VLFs in a log file, and how to fix log fragmentation, by decreasing the virtual log files to a reasonable number.
What is a Virtual Log File?
During normal operation, SQL Server writes sequentially to the log file, recording the details of all DDL and DML operations on the database with which the log file is associated. Each log record written to the log file is stamped with a Logical Sequence Number (LSN). These LSNs are ever-increasing, so that the LSN2 log record will record an action that occurred after the one recorded in the LSN1 log record, and so on, and the most-recently added log record will have the highest LSN, and marks the logical end of the log file.
Internally, SQL Server divides the space in a transaction log file into a number of ‘chunks’ called virtual log files (VLFs). Figure 1 depicts the log file for a newly-created database, with four VLFs.

Figure 1: Four empty VLFs
SQL Server begins writing transaction details into the first available VLF, which in this case is VLF1. It writes log records to each VLF, in turn, moving on to the next VLF when the one it is writing to is full. It keeps writing to the next VLF until it reaches the physical end of the log file, at which point it circles round and begins to reuse space in the first VLF at the start of the file, assuming that space in the first VLF is now available for reuse. In the simplified depiction in Figure 2, our VLFs holds log records for four transactions. These log records, hold detail information for the four transactions, followed by a database CHECKPOINT operation. So, for example, LSN1 records the start of transaction T1, LSN2, an UPDATE operation performed by T1, LSN3 record the COMMIT of T1, LSN4 records the start of transaction T2, and so on.
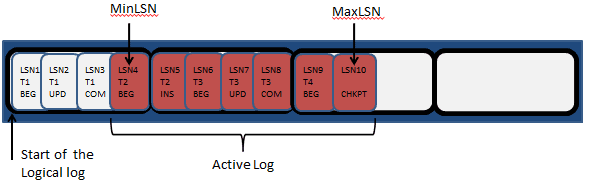
Figure 2: A simplified depiction of the active log
The log record with the MinLSN, shown in Figure 2, is defined as the “oldest log record that is required for a successful database-wide rollback or by another activity or operation in the database“. Any log record with a higher LSN than the MinLSN, regardless of whether it relates to an open or closed transaction, is part of the active log.
Any log record relating to an open transaction is required for possible rollback and so must be part of the active log. In our case, T2 is the oldest open transaction and so LSN4 marks the start of what is termed the active log. Note that T1 is committed, and we have assumed that it is no longer required by other database activity, such as replication or Change Data Capture. Also, note that for a database operating in FULL or BULK_LOGGED recovery model, all log records added since the last log backup must remain part of the active log, so in this example we are assuming a database operating in SIMPLE recovery model.
A VLF is “active” if it contains any part of the active log, or “inactive”, if it doesn’t. When the database CHECKPOINT operation occurs (LSN10), all dirty data and log pages are flushed from cache to disk (always writing to the log first) and, if the database is operating in SIMPLE recovery model, any space prior to the MinLSN can be made available for reuse ( a process known as log truncation).
However, no active VLF can ever be truncated, and since in this case VLFs 1-3 all contain part of the active log, no space in any of these VLFs can currently be made available for reuse. Figure 3 moves the action on a little further.
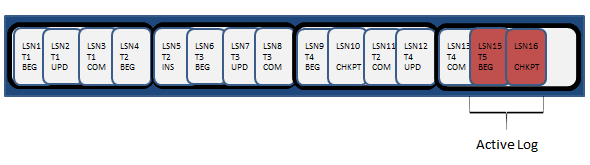
Figure 3: Log truncation (simplified)
T2 has now committed (LSN11), as has T4 (LSN13) and one new transaction has started. Now, when a CHECKPOINT occurs, VLFs 1-3 contain no part of the active log so the space in them can be made available for reuse. When SQL Server hits the end of VLF4, it will simply circle round and start reusing the space in VLF1.
However, what happens if SQL Server reaches the end of VLF4 and detects that the next VLF contains part of the active log? It cannot be overwritten and so the log file is full and must be grown, adding more VLFs, so that SQL Server can then continue to write transaction log records. If the transaction log can’t grow, either because autogrow is disabled, or there is no more room on the physical disk that holds the log file, then you will see a “transaction log full” error and the database will become read-only, and any unfortunate applications that are using it will stop working.
Common Causes of Log Growth
Assuming autogrowth is enabled, there are a number of reasons why a log file may experience rapid growth, adding more and more VLFs with each growth event. The primary reason is operating a database in FULL (or BULK_LOGGED) recovery model without taking regular log backups. If, in our previous example, the database were operating in FULL recovery model then even though the first four transactions had all committed, in Figure 3, the start of the active log would still be pinned back at LSN1, since this log record, and all subsequent records, are required to remain part of the active log until a log backup is taken. In the absence of a log backup, the log would need to grow, adding more VLFs, when VLF was full. If a log backup was taken then this operation could mark the space in the VLFs1-3 as available for reuse.
Another common cause is long-running transactions. As we noted, until T2 committed, large areas of the log were unavailable for reuse. Another related cause is large batch operations that are not appropriately committing transactions.
Finally, of course, the log file will be forced to grow readily if the log file was simply too small to cope with the normal database workload.
Log Growth and the Number of VLFs
No DBA wants any of their databases to get into an unusable state, as a result of a full transaction log and so it’s advisable to enable autogrowth. Equally, however, it is inadvisable to let the log grow in an uncontrolled fashion, with lots of small growth events, because:
- It can result in a very high number of VLFs – this internal log fragmentation can slow down processes that have to read the log file, and even normal database modifications.
- Each log auto-growth event eats up CPU and I/O resources – log growth events can’t take advantage of instance file initialization so SQL Server needs to go through its file initialization process every time it grows the log. See my previously-referenced article for a script that uses the default trace file to identify the length of time taken to perform auto-growth events (which will depend on how much space is being added each time).
Unfortunately, if you choose to use the default initial size, and auto-growth settings when you created a new database, then you may find your transaction log file does, ultimately, end up with hundreds or thousands of VLFs.
The problem is that the default size and growth settings for all user databases are inherited from the model database. Out of the box, a typical initial size for the transaction log file is 1 MB, with a growth rate of 10 %. This is a ‘double whammy’ in the sense that not only will you start with a very small transaction log, but it will also grow, initially at least, in very small increments.
Table 1 shows the number of VLFs that will be added depending on the amount of space added to the transaction log.
| Number of VLFs | Growth Size |
| 4 | <64MB |
| 8 | >=64MB and < 1GB |
| 16 | >=1GB |
Table 1: Number of VLFs added based on Growth Size of Transaction Log
So a “default” database would start off with 4 VLFs and another 4 VLFs will be added (initially at least) each time the log file needs to grow.
Unless you allocate a lot of very small databases, I would recommend that you adjust the settings for the model database such that your user databases inherit size and growth properties that are appropriate for your environment, or make sure you always set an appropriate size for a transaction log file, when creating any new database.
Hopefully, the following example will illustrate why this is important. Listing 1 creates a new database, mimicking the default size and growth settings that would normally be inherited from model. It sets the recovery model to FULL and takes a full database backup, so that the database is fully engaged in this mode of operation, and the log can only be truncated by a log backup.
|
1 |
-- TEST #1 ------------------------------------------- USE master; GO CREATE DATABASE VLFTest1 ON (NAME = VLFTest1, FILENAME = 'C:\SQLData\VLFTest1_data.mdf', SIZE = 3MB, FILEGROWTH = 1) LOG ON (NAME = VLFTest1_log, FILENAME = 'D:\SQLData\VLFTest1_log.ldf', SIZE = 1MB, FILEGROWTH = 10%); GO ALTER DATABASE VLFTest1 SET RECOVERY FULL; GO BACKUP DATABASE VLFTest1 TO DISK = 'E:\SQLBackups\VLFTest1_Full.bak'; GO |
Listing 1: Creating the VLFTest1 database with default size and auto-growth settings
In Listing 2, we use the undocumented DBCC LOGINFO command to investigate the number of VLFs in our log file. We’ll delve into the output of this command in more detail shortly; for the time being we are interested only in the number of rows it returns, which is one for every VLF. In this case, we see four rows, meaning four VLFs, as expected.
|
1 |
USE VLFTest1 DBCC LOGINFO () WITH NO_INFOMSGS; GO /*OUTPUT: FileId FileSize StartOffset FSeqNo Status Parity CreateLSN ----------- -------------------- -------------------- ----------- ----------- ------ - 2 253952 8192 26 2 64 0 2 253952 262144 0 0 0 0 2 253952 516096 0 0 0 0 2 278528 770048 0 0 0 0 */ |
Listing 2: Script to show number of VLFs in VLFTest1
Now, in Listing 3, we create a new table, MyTable and then, within a transaction, insert 10,000 rows, in a loop, into the table, and measure the time taken to run the test.
|
1 |
SET NOCOUNT ON; USE VLFTest1; GO CREATE TABLE MyTable ( Id INT IDENTITY , MyDesc CHAR(8000) ); DECLARE @I INT = 0 DECLARE @S DATETIME = GETDATE(); BEGIN TRANSACTION; WHILE @I < 100000 BEGIN SET @I += 1; INSERT INTO MyTable VALUES ( REPLICATE('ABCD', 2000) ); END COMMIT TRANSACTION; SELECT 'Time to run Test #1: ' + CAST(DATEDIFF(SS, @S, GETDATE()) AS VARCHAR(4)) + 'Seconds'; |
Listing 3: 10 K row data load test for VLFTest1
In my case, the tests took as average of 54 seconds to run. On completion, I re-ran listing 2 and saw that the log file now has 251 VLFs.
Now, create a new database, as shown in Listing 4, but this time sizing and growing the log file in more controlled manner, appropriate for the expected data load.
|
1 |
-- TEST #2 ------------------------------------------- USE master; GO CREATE DATABASE VLFTest2 ON (NAME = VLFTest2, FILENAME = 'C:\SQLData\VLFTest2_data.mdf', SIZE = 3MB, FILEGROWTH = 1) LOG ON (NAME = VLFTest2_log, FILENAME = 'D:\SQLData\VLFTest2_log.ldf', SIZE = 1000MB, FILEGROWTH = 250MB); GO ALTER DATABASE VLFTest2 SET RECOVERY FULL; GO BACKUP DATABASE VLFTest2 TO DISK = 'E:\SQLBackups\VLFTest2_Full.bak'; GO |
Listing 4: Creating the VLFTest2 database with manual size and auto-growth settings
Running DBCC LOGINFO for this database, we should see 8 VLFs since the initial database size is >=64 MB and < 1 GB. Next, simply adapt Listing 3 to use the VLFTest2 database, and repeat the data load test. Re-running DBCC LOGINFO should confirm that the log still has 8 VLFs, and the absence of any growth events, during the data load, should lead to a measurable performance increase. Obviously the size of this performance increase will vary greatly depending on the exact file architecture, the nature of the underlying hardware, and so on. However, in my tests I saw the test time for Listing 3 decrease by almost half, to around 28 seconds.
I also performed some tests to compare the performance of an operation, namely a log backup, which would need to read the log file, for the VLFTest1 and VLFTest2 databases. My conclusions were that at this level of fragmentation, the performance detriment to log backups on VLFTest1 (251 VLFs) versus VLFTest2 (8 VLFs) was small but reproducible, at around 15%. Again, your results may vary, depending on environment.
A Deeper Look at DBCC LOGINFO
Up to now, we’ve used the undocumented DBCC LOGINFO command without much commentary, simply to find out the number of VLFs in a log file. However, it can tell us a bit more information about the way in which the space in the log is used, so let’s take a slightly deeper look at the columns it returns. Drop the existing VLFTest1 database and then recreate it using the CREATE DATABASE command in Listing 1, with small initial size and small growth increments.
Rerun the DBCC LOGINFO command from Listing 2 and you should see 4 rows returned, each one representing a VLF
|
1 |
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN -------- ------------- ---------------- ---------- ---------- ------ --------- 2 253952 8192 30 2 64 0 2 253952 262144 0 0 0 0 2 253952 516096 0 0 0 0 2 278528 770048 0 0 0 0 |
These columns have the following meaning:
- FileID – the
FileIDnumber as found insysfiles - FileSize – the size of the VLF in bytes
- StartOffset – the start of the VLF in bytes, from the front of the transaction log
- FSeqNo – indicates the order in which transactions have been written to the different VLF files. The VLF with the highest number is the VLF to which log records are currently being written.
- Status – identifies whether or not a VLF contains part of the active log. A value of 2 indicates an active VLF that can’t be overwritten.
- Parity – the Parity Value, which can be 0, 64 or 128 (see the Additional Resources section at the end of this article for more information)
- CreateLSN – Identifies the LSN when the VLF was created. A value of zero indicates that the VLF was created when the database was created. If two VLFs have the same number then they were created at the same time, via an auto-grow event.
We can see from the command output that all of the VLFs were created when the database was created and that we currently have a single active VLF. Let’s now load in some data, as shown in Listing 5, to cause some log growth events.
|
1 |
SET NOCOUNT ON; USE VLFTest1; GO CREATE TABLE MyTable ( Id INT IDENTITY , MyDesc CHAR(8000) ); DECLARE @I INT = 0 WHILE @I < 100000 BEGIN SET @I += 1; INSERT INTO MyTable VALUES ( REPLICATE('A', 8000) ); END |
Listing 5: Script to cause auto-grow event on VLFTest1
Rerun our DBCC LOGINFO command, and it should return 15 rows, as shown below:
|
1 |
FileId FileSize StartOffset FSeqNo Status Parity CreateLSN -------- ------------- ---------------- ---------- ---------- ------ ------------------ 2 253952 8192 30 0 64 0 2 253952 262144 31 0 64 0 2 253952 516096 32 0 64 0 2 278528 770048 33 0 64 0 2 262144 1048576 34 0 64 32000000037600016 2 262144 1310720 35 0 64 33000000025500044 2 262144 1572864 36 0 64 34000000013600036 2 262144 1835008 37 0 64 35000000006700028 2 262144 2097152 38 0 64 35000000048700008 2 262144 2359296 39 0 64 36000000037600052 2 262144 2621440 40 0 64 37000000029600022 2 327680 2883584 41 0 64 38000000025600016 2 327680 3211264 42 2 64 39000000025500044 2 393216 3538944 0 0 0 40000000025600060 2 393216 3932160 0 0 0 41000000049500016 |
From the output, we can again see that we have one active VLF, and that 11 new VLFs were added as a result of the data load.
Keeping VLFs under Control
The primary cause of internal log fragmentation is allowing the transaction log to grow many times, in very small increments, and you will probably find that the databases on your system that have lots of VLFs are those same databases that are set up to use the default auto- growth settings.
As such, the obvious preventative medicine is to size your database files appropriately, when the database is created, to account for the current database size plus expected growth over a given period (a year, say). At the same time, it is best to avoid creating a huge log file, with very few VLFs, since this could mean that large areas of the log will be unavailable for reuse for long periods, and it will also mean that your log file will take up a lot of disk space that probably isn’t required.
Unfortunately, there is no simple formula that will accurately predict growth rates for the log file, over such a period; it depend on factors such as the transaction rate, read:write ratio for the workload, how often you can backup up the log, and so on. Therefore, auto-growth should still be enabled, but used merely as a safety net, in case your sizing and growth calculations were amiss.
When you set the auto-growth increment size, it is best to set it so that the log grows in relatively large chunks, compared to the size of log. I like to set the auto-growth rate to fixed sizes, instead of a percentage. The problem with the latter, of course, is that the log will grow in relatively small increments initially, and then very large increments later on, possibly causing the log to grow much larger than is needed.
I normally specify a growth increment of 25% the initial size of the transaction log, and then then monitor the growth rate of the transaction log and adjust the auto-growth size if I observe frequent growth events. The fewer auto-grow events, the lower the number of VLFs in the transaction log.
Curing a Fragmented Log
If you occasionally find a database with many VLFs, there is a fix that will use DBCC SHRINKFILE to shrink the log file to a minimum, or specified, size to remove most of the VLFs, and then the ALTER DATABASE command to resize the log to be the appropriate size for that database. Please note that, ideally, this will be a one-time operation. If you find that you’re frequently resizing the log for a given database then you need to reassess the size and growth characteristics for that database.
In order to perform the “log defragmentation” operation, pick a period of low database activity, such as in the evening, early morning or weekend, and backup the transaction log.
Next, run a DBCC LOGINFO command to determine which VLF files contain the active part of the transaction log. If a large portion of the log is still unavailable for reuse, then you need to investigate possible causes of this, such as uncommitted transactions and so on. Having successfully freed up a sizeable portion of the log, we can then shrink the transaction log down in size by issuing the following command:
|
1 |
DBCC SHRINKFILE(<transaction log logical file name>); |
Use the sp_helpfile system stored procedure to find the logical file name for the transaction log, if you don’t already know it. This will shrink the log to the smallest possible size and then we can immediately resize the log appropriately using the following command:
|
1 |
ALTER DATABASE <yourdatabase> MODIFY FILE (NAME=<transaction log logical file name>, SIZE = newtotalsize); |
Summary
When a databases auto-grows, the number of VLFs will steadily rise, to the point where it may start to affect the performance of operations that need to read the log file. Furthermore, the CPU load caused by rapid auto-growth during data loads may affect the performance of those operations, and any other occurring during that period.
By properly sizing your transaction logs you should be able to keep the number of VLFs under control. If you find your databases have grown unchecked, and you have many VLFs, then find a time to perform the necessary defragmentation, and then adjust the size and growth properties so that it doesn’t happen again.
For more information about how to monitor your databases for the number of VLFs, review Thomas LaRock’s Monitoring SQL Server Virtual Log File Fragmentation article.
Additional Resources
The following posts provide additional resources and information regarding VLFs. The first two are blog posts on transaction log management by Kimberly Tripp. The last one, by Paul Randal, discusses the parity value setting, when running the DBCC LOGINFO command.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments