
Next to making sure you’re running database backups, knowing that what you’re backing up is a valid database – in good shape, not corrupted, fully functional, etc. – is probably the most important thing you can do on the systems you manage. The mechanism to ensure that the databases under your charge are correct is known as the Database Consistency Checker or DBCC. The DBCC command in SQL Server has a number of options and methods for checking the database, but the one that most people use is DBCC CHECKDB.
The CHECKDB process is actually several different consistency checks run one after another: CHECKALLOC, CHECKTABLE and CHECKCATALOG. CHECKALLOC goes through the allocation of pages on the disk for the database in question. CHECKTABLE performs a very thorough check of the structure of the database pages, specifically, ensuring that they’re linked appropriately and put together in a consistent manner. Finally, CHECKCATALOG performs a check against the system tables. All these together are run through the DBCC CHECKDB command. After running this successfully, you know that the database in question is stored correctly on your disk and is internally consistent, the basic requirements for successful storage and retrieval of your company’s data.
The goal here is not a detailed analysis of consistency checking. Instead, I want to talk about how you can reduce the overhead for running DBCC CHECKDB. Microsoft has an entry in Books Online on how to enhance the performance of CHECKDB: http://msdn.microsoft.com/en-us/library/ms175515.aspx. Basically, the entry explains that CHECKDB is extremely I/O intensive, so you need to avoid contention. Further, the functions within CHECKDB make very heavy use of the tempdb, so you should store tempdb on fast disks configured for optimal throughput. And that’s about all it says.
I have a test database I created, called MovieManagement, which is allocated to 125gb of space but only takes up about 100gb. Running DBCC on this database, which is not under any type of load, takes 26 minutes. If that same database were on a production system, especially one that was running 24/7, you can expect that time to go up. So what do you do if you have a large database and a heavy transactional load on the system?
DBCC Offline
You’re not supposed to run DBCC CHECKDB against a system that is under stress, because it will interfere with both the performance of the system and the performance of CHECKDB. To get around this issue on systems that are under load, you can do a little trick. Instead of running CHECKDB prior to your backup, as is common, run it after your backup. “Ah, but, Grant,” you say, “if we did that we wouldn’t be sure that our backups were consistent and besides, how does that help us to reduce the load on the system?” I get it. After all, before the backup, after the backup, neither will change the load that DBCC CHECKDB puts on your server, right? Well, not exactly. What if you cheat?
The backup process is a bit-by-bit copy of the database, storing it more or less exactly as it’s stored on your server. That means when you restore a database, it comes back in exactly the same state. If your database is inconsistent, if you have storage or allocation problems, the backup will store those too. Ever found a database with errors in it, and when you went to the backup, there they were? Yeah, that’s awful, best avoided, right? Wrong. Because the backup is an exact copy of that messed up database, couldn’t we use it to validate the database? Bear with me a moment.
What if, instead of running a DBCC check on your system and then backing it up (assuming the DBCC check passed), you just back up the system. Then, you take that backup and restore it to a different server. On that server, which doesn’t have all your active users submitting their transactions, you quietly check the consistency of the database. If there’s a problem, yeah, you still need to go back to your production system and fix it, as well as take a new backup. But, if there’s not a problem, you’ve done several useful things:
- Performed a consistency check of your database
- Removed the load incurred by the consistency check from your production system
- Checked that you have a good backup.
If you’ve been following along closely, I’m sure you knew the first two points were coming, but the third is a free little bonus that comes with this approach.
That’s it then, right? You’re running back to your office to start setting up this methodology right away… but wait, you think. We don’t have hundreds of gigabytes, or even terabytes, of extra storage just lying around. How the heck are we supposed to do this? Ah, but I wouldn’t have suggested this if I didn’t have a solution in mind, now would I?
SQL Virtual Restore to the Rescue
You need to restore a copy of your database to a different server, but you only own so much stock in EMC and don’t want to have to purchase an entire second SAN just to support DBCC checks. But, if you use SQL Virtual Restore, you can restore a database from your backup, and run DBCC checks against it, while never actually allocating all that disk space for the backup. Done. Thanks for stopping by. Talk to you later. What’s that? You don’t believe it. OK. Here’s an example.
Back to my test database, MovieManagement. On my system, creating a backup of this database to disk takes about 49 minutes and results in a 93gb file. If I restore the database to my server, it’s going to be 125gb more of storage. Since my test machine only has about 300gb and I have other test databases on it, I’ve hit the limit for the number of times I can put this database on to my system. Instead, I’m going to use SQL Virtual Restore to create a virtual copy of the database.
If I were to do a full restore, it would take about 51 minutes (based on tests). If I run a SQL Virtual Restore on the native backup, it takes about 19 minutes and results in a database that is 3mb in size, in addition to the backup file. Yes, that is an ‘m’ and not a ‘g’ next to that 3. Here’s the script for doing that:
|
1 2 3 |
RESTORE DATABASE [MovieManagement_Virtual] FROM DISK=N'D:\BU\MovieManagement.bak' WITH MOVE N'MovieManagement' TO N'D:\Data\MovieManagement_MovieManagement_Virtual.vmdf', MOVE N'MovieManagement_log' TO N'D:\Data\MovieManagement_log_MovieManagement_Virtual.vldf' |
You’ll note that I’m just using standard syntax to restore the database, the exception being the change on the file extension to use the letter “v.” The HyperBac Engine, the Windows service which powers SQL Virtual Restore, picks up on this query, creates a small space, and keeps a connection open to the backup file. It’s this small size and reduced time that makes offloading the DBCC with SQL Virtual Restore that much easier.
I can make it easier still. The SQL Virtual Restore Wizard provides me with several options when I’m setting up the restore:
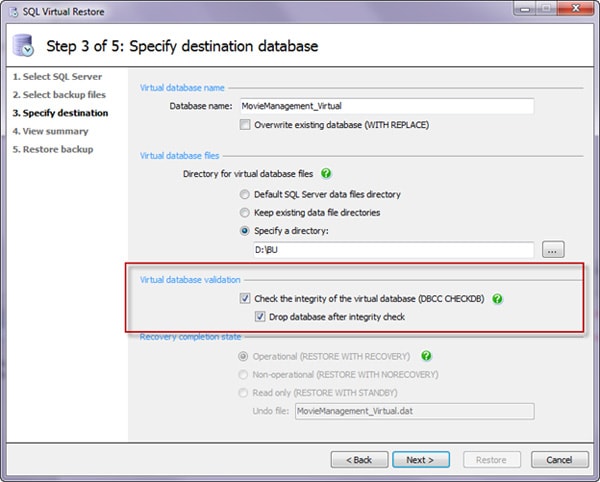
Notice the area with the red box around it. When configuring my backup, I could have SQL Virtual Restore run a DBCC check and then drop the database immediately afterwards. The script ends up looking like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
RESTORE DATABASE [MovieManagement_Virtual] FROM DISK=N'D:\BU\MovieManagement.bak' WITH MOVE N'MovieManagement' TO N'D:\BU\MovieManagement_MovieManagement_Virtual.vmdf', MOVE N'MovieManagement_log' TO N'D:\BU\MovieManagement_log_MovieManagement_Virtual.vldf', NORECOVERY, STATS=1 GO RESTORE DATABASE [MovieManagement_Virtual] WITH RECOVERY, RESTRICTED_USER GO DBCC CHECKDB ([MovieManagement_Virtual]) GO DROP DATABASE [MovieManagement_Virtual] GO |
Those are generated scripts, but with a minimal amount of work, you could incorporate this into your own routines, up to and including setting up alerts when the DBCC fails, so you know to address issues in your production system. Oh, and by the way, the full DBCC check against the backup took just about 27 minutes, compared to 26 minutes against the original database.
Summary
Running DBCC CHECKDB is a vital part of protecting your system. And you must backup your databases. By putting SQL Virtual Restore to work, you can take DBCC checks from your production system, and move them to some other system where they won’t interfere with ongoing transactions, speeding up both processes. You get an automatic validation that your backup process is working, and you can run DBCC in no more time than it takes on the production system. All this without having to sacrifice hundreds of gigabytes of storage. Finally, because you can set all this up to run through T-SQL using standard commands, you don’t have to throw out any code you’ve developed for dealing with consistency checks on your database. How’s that for a process improvement?
If you’ve found this article useful, you can download a free 14-day trial of Red Gate SQL Virtual Restore. Restore, verify, and optionally drop your backups in one automatic process. Get it here.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments