
I have recently been working on an ALM (Application Lifecycle Management) project for a large e-commerce company. The aim of this project is to achieve a ‘one-click’ deployment to production of the application code and the database schema. This will bring several benefits, the main one being that we take into consideration both database and application deployment at a much earlier stage in the development cycle. The framework that we developed uses many of the Continuous Integration (CI) principles in order to make production deployments more stable, predictable and repeatable. Additionally, we aim to speed development by cutting down on the number of manual schema-change scripts that the developers need to create. Where possible, we plan to use comparisons between schema and source control to produce the required change scripts.
The problem is that although, generally speaking, source control is the truth, a database doesn’t quite conform to the ideal because the target schema can, for valid reasons, contain other conflicting truths that can’t easily be captured in source control. A production database is likely to have in it objects that have either been inserted as a result of it being a participant in a replication, or auto-named objects concerned with declarative referential integrity (DRI) whose name varies from build to build.
Synchronization with these objects can take extra time, make the build fail, or interfere with the functionality of the production system. Ideally, any database comparison or synchronization would simply ignore these objects, but this is not practicable and so we need to remove them from the build. The only viable alternative to a manual system is a script that parses the SQL to find the offending parts of the script.
This article presents such a solution, using a PowerShell script and a SQL parser, provided as part of the SQL Server 2012 Feature Pack (it works with earlier version too).
I use a third party tool for schema comparison and synchronization (Red Gate’s SQL Compare), as well as a tool to manage source control from within SSMS (SQL Source Control). However, the article has no reliance on either tool, and the solution is applicable to any environment that manages deployments using schema comparison between Source-controlled scripts and the target system.
DRI Objects with “Junk” names
Unnamed constraints are one common cause of differences between what is in Source Control and what is in the Production schema. SQL Server does provide, within the metadata, a name for “unnamed” constraints; it uses a ‘junk’ naming convention for them to guarantee uniqueness, but this name will change on every build.
For example, if a Primary Key is created but left unnamed, SQL Server uses a default auto-generated name, PK__TableName__Junk (for example, PK__Customer__A4AE64082CE326F2). This will cause SQL Compare to drop the Primary Key and recreate it, because the Junk portion of its name will be different on different databases.
This means that even though there has been no functional change, any change scripts generated using comparison software will, upon every new build, attempt to remove the ‘old’ constraint and add the ‘new’ one. Dropping and recreating a primary key on a table can be a very costly operation and since there has been no functional change, one that we can well live without.
We can avoid this problem simply by naming all constraints, even when naming is only optional. This would involve using sp_rename on the objects on the databases (development and production) outside of any automated deployment process, and matching those changes inside source control.
Pollution from Installing Replication
Another common thorny issue is replication pollution. In the schema for a production database that supports replication, SQL Server auto-creates many objects such as stored procedures, to support the replication processes.
Once again, an automated schema comparison script will always make the target schema look like the source. Therefore, if a production system that is participating in a replication scheme is compared with the version in source control, generated from a development instance that is not a replication target, then many of the stored procedures, constraints, triggers and so on that are required by replication will be dropped from the target schema.
To help illustrate some of the problems that can arise with replication ‘pollution’, consider a very simple system that uses two of the more common forms of replication (transactional and merge).
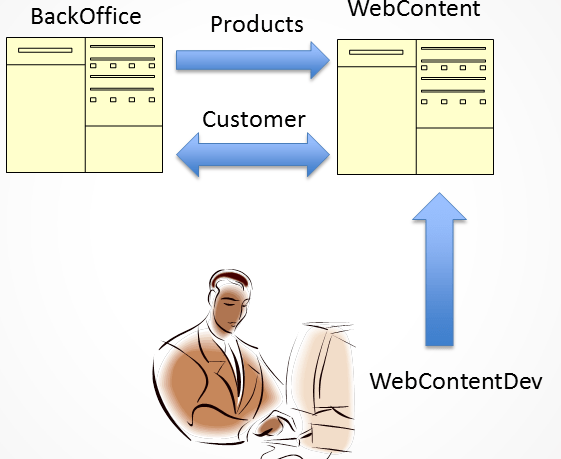
Figure 1: Pushing changes to a production database that uses replication
We have two production databases BackOffice and WebContent. The Products table is a one-way transactional replication from BackOffice to WebContent and the Customer table is using merge replication, with the publisher being WebContent. Our developer is using a database WebContentDev on his local machine and is using SQL Source control to manage his code base. In-line with best advice from Red Gate, his development database is not a replication target, and as such does not contain the replication-related stored procedures, constraints and triggers that will exist on the production database. Right now, he wishes to make two changes to the production WebContent database. Firstly, he wishes to add a column called TitleId to the Customer table and secondly to add a procedure called GetCustomer. The risk is that when the developer uses SQL Compare to produce a schema change script, in order to push the changes to the production database, WebContent, then the replication objects could be changed or dropped. This would quite naturally cause us severe problems; replication would break in a quite hideous fashion because its ‘plumbing’ would no longer exist.
In order to understand why this might happen, we need to look “under the covers” at the objects that SQL Server auto-creates to support replication processes. To support replication of the Products table, SQL Server has created insert, update and delete stored procedures in the WebContent database, as shown in Figure 2. These custom stored procedures modify the subscription database, as appropriate, whenever data is inserted, updated or deleted. We can change the replication setting to use direct SQL statements rather than stored procedures, and so avoid this issue, but stored procedures are the default, and better, method.
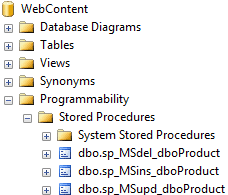
Figure 2: Stored procedures created by SQL Server in WebContent, to support 1-way transactional replication
The merge replication of Customer requires SQL Server to make a few more schema changes to the WebContent database, as shown in Figure 3.
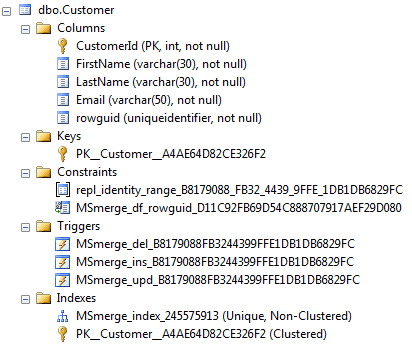
Figure 3: Changes made by SQL Server to the WebContent schema to support merge replication
SQL Server has added to the Customer table a column called rowguid, along with two constraints, three triggers and an index. In addition to the replication-related objects, note that we also have an auto-named Primary Key, as discussed earlier.
To support merge replication, SQL Server has added a uniqueidentifier column called rowguid to the Customer table and assigned it the special property of ROWGUIDCOL. On this column, SQL Server has created a default constraint, MSMerge_df_rowguid_Junk, which assigns a unique identifier to any newly inserted rows usingnewsequentialid. As with unnamed Primary Keys, the Junk portion of the default constraint’s name will not be consistent across servers and a change will be required.
SQL Server has also added a CHECK constraint to the Customer table. Figure 4 shows its definition.

Figure 4: Definition of the CHECK constraint created to support replication
The _junk naming of the constraint is a problem, as we have discussed, but this is a minor issue compared with the problem of the constraint’s definition. This constraint ensures that the identity column for this node of the replication topology uses a different range of values from any other node that might also be subject to updates.
If this object doesn’t exist in development it will, like all the others, be dropped in the synchronization script (see Listing 1). However, even we adopt the approach of adding the object to our source control system, with a name and definition that matches what is in production, we’ll still run into a serious problem when we run the synchronization script as it’s likely we’d be creating a production system constraint with the wrong range definition. The version of the constraint in Figure 4 ensures that only IDs in the ranges 1 to 1001 and 1002 to 2001 can be inserted. Even though CustomerIDis an IDENTITY column, this check still has to be made to guarantee consistency. However, in the meantime, as more rows are added to the Customer table in our production system, SQL Server automatically updates the CHECK constraint to reflect the new range requirements. Therefore, when we come to run our synchronization script, we’ll replace the current version of the constraint with the one that existed at the time we copied it from production, and the next customer inserted in production would have a CustomerID that would cause the constraint to fail and stop us being able to add new customers.
Listing 1 shows an extract from the script outputted from SQL Compare when comparing WebContentDev and WebContent. The full script is available as a download (SQLCompareOut.sql) with this article, but I’ve extracted enough to drive home the point that the developer’s requested changes appear within a raft of DROP and ALTER statements that reflect the fact that the comparison engine is detecting replications objects that exist in production (WebContent) but not in development (WebContentDev).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
USE [WebContent] GO PRINT N'Dropping constraints from [dbo].[Customer]' GO -- Dropping the CHECK constraint ALTER TABLE [dbo].[Customer] DROP CONSTRAINT [repl_identity_range_B8179088_FB32_4439_9FFE_1DB1DB6829FC] GO PRINT N'Dropping constraints from [dbo].[Customer]' GO -- Dropping our "unnamed" PK ALTER TABLE [dbo].[Customer] DROP CONSTRAINT [PK__Customer__A4AE64D82CE326F2] GO PRINT N'Dropping index [MSmerge_index_245575913] from [dbo].[Customer]' GO -- Dropping the merge replication index DROP INDEX [MSmerge_index_245575913] ON [dbo].[Customer] GO PRINT N'Dropping trigger [dbo].[MSmerge_del_B8179088FB3244399FFE1DB1DB6829FC] from [dbo].[Customer]' GO -- Dropping the three replication triggers DROP TRIGGER [dbo].[MSmerge_del_B8179088FB3244399FFE1DB1DB6829FC] GO --<...similar stmts for dropping the insert and update triggers...> PRINT N'Dropping [dbo].[sp_MSdel_dboProduct]' GO -- Dropping the three replication stored procedures DROP PROCEDURE [dbo].[sp_MSdel_dboProduct] GO --<...similar stmts for dropping the insert and update sprocs...> PRINT N'Altering [dbo].[Customer]' GO ALTER TABLE [dbo].[Customer] ALTER COLUMN [rowguid] DROP ROWGUIDCOL GO -- one of the developer's required changes! ALTER TABLE [dbo].[Customer] ADD [TitleID] [tinyint] NULL GO ALTER TABLE [dbo].[Customer] DROP COLUMN [rowguid] GO ALTER TABLE [dbo].[Customer] ALTER COLUMN [CustomerId] DROP NOT FOR REPLICATION GO PRINT N'Creating primary key [PK__Customer__A4AE64D83D0597BE] on [dbo].[Customer]' GO ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [PK__Customer__A4AE64D83D0597BE] PRIMARY KEY CLUSTERED ([CustomerId]) GO PRINT N'Creating [dbo].[GetCustomer]' GO -- the second of the developer's required changes! CREATE PROCEDURE [dbo].[GetCustomer] @CustomerID INTEGER AS SELECT Firstname , Lastname , TitleID FROM dbo.Customer WHERE CustomerID = @CustomerID GO PRINT N'Altering [dbo].[Product]' GO ALTER TABLE [dbo].[Product] ALTER COLUMN [ProductId] DROP NOT FOR REPLICATION GO PRINT N'Creating primary key [PK__Product__B40CC6CDC08944FD] on [dbo].[Product]' GO ALTER TABLE [dbo].[Product] ADD CONSTRAINT [PK__Product__B40CC6CDC08944FD] PRIMARY KEY CLUSTERED ([ProductId]) GO /* Start of RedGate SQL Source Control versioning database-level extended properties. */ --<...content omitted...> |
Listing 1: Summarized SQL Compare-generated script to synchronize the production WebContent database
Cleaning up Synchronization Scripts
The problem with these issues, in my experience, is that there were reasonable solutions for a few of them, limited solutions for others, but no single, easy solution that would deal with all of them in one go.
Explicit Object Naming
As discussed, we can circumvent some of these problems if we explicitly name all our objects. For example, if we explicitly name any Primary Keys then we can simply reproduce the same object in Source Control, the source and target objects will always match, and we’ll avoid any unnecessary synchronization code relating to these objects.
Likewise, instead of allowing SQL Server to auto-create theROWGUIDCOL column that it needs to support replication, we can simply define a named ROWGUIDCOL column on the table so that the replication functionality will use it, instead of auto-creating it.
Using Synchronization Tool Options
Schema synchronization tools such as SQL Compare offers some optional switches to reduce some of these unnecessary changes. For example, use of options such as ‘Ignore Replication Triggers’ and ‘Ignore Not for replication’ will, as their naming suggests, mean that changes in those functional areas are ignored, but these options are very limited in scope.
Including Replication Objects in Source Control
Generally, it is reasonable to expect that only those objects that a developer is able to maintain should be included within source control. However, it is possible that we can copy replication objects from production to Source Control (and so, in turn, to the development environment), so that any schema comparison no longer sees a change, since the source and target match.
However, several difficulties with this approach make it untenable in the long term. While it can work for ‘static’ objects, some of these replication objects are moving targets.
What happens, for example, when we make a change to the Products table, such as adding a new column? When we perform a schema comparison to push this change to production, SQL Server will create new versions of the replication-stored procedures to account for the new column. However, we would still have the old version of these procedures in Source Control, and so we risk overwriting the newer versions of the stored procedures with our existing (and now incorrect) versions inside source control. This will happen unless the developer has been very diligent in re-syncing source control for these procedures, though the question does arise of how the developer gets the new versions of these procedures. They only exist on the production database and the replication engine creates the new versions automatically having completed the schema changes, so they simply don’t exist at the point in time that the developer needs to include them into source control. It’s almost as if the developer needs to travel forwards in time to get the newer versions of the procedures to include into source control so that when the schema compare occurs there is ‘no change’.
Finally, we have issues such as that described previously for the CHECK constraint: even if we reproduce such objects in development, it is likely that their range definition will be incorrect, and so will cause serious problems when the synchronization code pushes them into production.
Using a T-SQL Parser to remove unwanted synchronization code
If we were to adopt all the practices discussed previously and employ the optional settings in our synchronization tools, we could still have many destructive and damaging changes within our script, if executed on a production machine.
We need a method that can be easily extendable and to mitigate the chances of a ‘bad’ change happening to a production environment. Bear in mind that this is just part of a wider automated deployment mechanism and although we can be 99.99% certain that we have caught and removed all of the extraneous changes, we can never be 100% certain.
To clean up the synchronization script (Listing 1), with very granular control over the sections of the script that we remove, we need initially to extract each SQL batch from the full script i.e. split the script on GOs. We could use a text pattern matcher (regex or similar) to do this, however this approach can be unreliable. For example, if text is being processed that contains the word SELECT, there is a big logical difference between it being the keyword SELECT for a SELECT statement and a piece of text that just happens to be SELECT, or a SELECT statement commented out.
Look at Listing 2; how would you approach the task of identifying the SELECT keyword in this sort of code, reliably, without a parser that has knowledge of the TSQL language?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE SCHEMA [SELECT] --and a [SELECT] table to go in it. CREATE TABLE [SELECT].[SELECT] ( [SELECT] INT, [SELECT SELECT SELECT] INT ) GO --and a function called [SELECT] CREATE FUNCTION [SELECT] ( ) RETURNS TABLE AS RETURN ( SELECT 1 AS [SELECT] , 'Select select select' AS [SELECT SELECT] --SELECT 1 AS [SELECT] ) GO INSERT INTO [SELECT].[SELECT] ( [SELECT SELECT SELECT] , [SELECT] ) SELECT [SELECT] , [SELECT] FROM [SELECT]() |
Listing 2: The difficulties of parsing SQL
For unrelated projects into the past, I have created parsers using Lex and Yacc and have even considered writing a T-SQL parser too. However, to create a new T-SQL parser and then to continually refine it, as the T-SQL language develops, would be a mountain of a task.
Fortunately, the SQL Server team has made a supported T-SQL parser freely available. As part of the “SQL Server 2012 Feature Pack”, there is a .component entitled “Microsoft SQL Server 2012 Transact-SQL Language Service“, which provides “parsing validation and IntelliSense services for Transact-SQL for SQL Server 2012, SQL Server 2008 R2, and SQL Server 2008 “.
The SQL parser comes in the form of a.NET assembly called Microsoft.SqlServer.Management.SqlParser and the object that we will be utilizing is Microsoft.SqlServer.Management.SqlParser.Parser.Scanner. If you have used a parser before you should be right at home with it, but even for those who haven’t used one, its operation is straightforward.
The function in the SQL Parser assembly that is of most use to us is GetNext and we use it in PowerShell, like this:
|
1 2 |
$Token = $Parser.GetNext([ref]$State ,[ref]$Start, [ref]$End, [ref]$IsMatched, [ref]$IsExecAutoParamHelp ) |
Listing 3: Example of PowerShell call to GetNext function
When we call GetNext theToken parameter is populated with an integer value, which represents a SQL Keyword, or a Lexical action. By casting this value to the enum Microsoft.SqlServer.Management.SqlParser.Parser.Tokens, we can derive a more descriptive value. So, for example, when GetNext returns the value of 128, this can be cast using the enum Tokens, which will then derive the value of EOF (End Of File), at which point we can complete our operation, as there is no more data to be read. When 605 is returned by GetNext, this evaluates to the value of LEX_BATCH_SEPERATOR in the enum. As is self-evident from the name, we have reached a batch separator, i.e. a GO statement, and should take appropriate action.
The values of the Start and End parameters denote the starting and ending character positions of the ‘word’ that has been parsed by GetNext within the input SQL statement.
When the parser encounters a non-keyword, such as a table name or column name, GetNext returns a value that will resolve to TOKEN_ID, when cast. Note that some character values, such as *, ( and ), do not cast and will throw an error. Our process will need to catch these in a TRY/CATCH block and we’ll have to interrogate the text from the input SQL, with Start and End, to take appropriate action.
The other parameters, State, IsMatched and IsExecAutoParamHelp are ones for which I have not found much use.
In order to see this in action, we’ll use the following simple SQL batch and show the value of the returned parameters of each call to the GetNext function:
|
1 2 |
SELECT * FROM MYTAB GO |
Firstly, lets visualize that batch as an array of ASCII characters.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| S | E | L | E | C | T | * | F | R | O | M | M | Y | T | A | B |
CR |
LF |
G | O |
Next, is a table that shows the values returned from the GetNext function, the token enum and the key word extracted from the original batch using values of the Start and End parameters.
| Iteration | Token | TokenEnum | Start | End | Key Word |
| 1 | 286 | TOKEN_SELECT | 0 | 5 | SELECT |
| 2 | 42 | ERROR | 7 | 7 | * |
| 3 | 242 | TOKEN_FROM | 9 | 12 | FROM |
| 4 | 171 | TOKEN_ID | 14 | 18 | MYTAB |
| 5 | 605 | LEX_BATCH_SEPERATOR | 21 | 22 | GO |
| 6 | 128 | EOF | 23 | 23 |
Note that, in my opinion, the parsing is not complete. The white spacing is not returned. Although white spacing (spaces, tabs, carriage returns, line feeds etc.) are not functionally important, if we are using the parser and then reconstructing a statement directly from its output, then white spacing will be significant, especially for readability purposes.
For our synchronization script file, generated by SQL Compare, we can use the parser and extract each SQL batch in order to find those statements that would be harmful if executed on the production server. With each batch extracted using the parser, we can compare them one at a time against a series of regex (regular expression) patterns that, when matched, will signify that we should reject the batch. Working with regex patterns is a bit of a dark art itself and I will briefly summarize one of the patterns I am using. Take, for example, this pattern.
|
1 |
\A\s*ALTER TABLE \[\w+\]\.\[\w+]\s+DROP\s+CONSTRAINT\s+\[PK__ |
This will match against the SQL statement from our example in Listing 1 of:
|
1 2 |
ALTER TABLE [dbo].[Product] DROP CONSTRAINT [PK__Product__B40CC6CD3D686EF8] |
Regex patterns are similar to using wildcards (‘%’ and ‘?’) in SQL, but much more precise. This article is not a tutorial of regex and further reading is highly recommended. However, let’s now briefly pull the pattern apart and see how it works.
| \A | The string being matched must start with the following pattern |
| \s | This is the symbol for whitespace (spaces, carriage return, line feeds) |
| * | Appending an asterisk to any regex code signifies that 0 or more are allowed |
| ALTER TABLE | Match the literal string ‘ALTER TABLE‘ |
| \[ | The [ and ] characters are significant to regex and are used to group codes to add OR style logic. Using the \ (backslash) character tells the engine that we require the following character, so here we want a literal ‘[‘ character. |
| \w | Any word character A-Za-z0-9 can be accepted |
| + | Appending a + to a regex code signifies that 1 or more characters of that type are allowed |
| \] | A literal ‘]’ character |
| \. | Similar to the ‘w’ and ‘s’ codes the . (period) character represents any character, so prefixing with a \ character makes it an actual period. |
The rest of the pattern repeats the above series of codes.
The PowerShell script, in Listing 4, shows this functionality and accepts or rejects each batch based on very specific regex pattern rules.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
$Script:regexExpressions =@( "\A\s*ALTER TABLE \[\w+\]\.\[\w+]\s+DROP\s+CONSTRAINT\s+\[PK__", "\A\s*ALTER TABLE \[\w+\]\.\[\w+]\s+ADD\s+CONSTRAINT\s+\[PK__", "\A\s*CREATE PROCEDURE\s+\[dbo\]\.\[sp_MS[\w]*\s*", "\A\s*DROP PROCEDURE\s+\[dbo\]\.\[sp_MS[\w]*\s*", "\A\s*ALTER TABLE \[[\w]*\]\.\[[\w]*\] ALTER COLUMN \[[\w]*\] DROP NOT FOR REPLICATION", "\A\s*ALTER TABLE \[[\w]*\]\.\[[\w]*\] ALTER COLUMN \[[\w]*\] ADD NOT FOR REPLICATION" "\A\s*ALTER TABLE \[[\w]*\]\.\[[\w]*\] DROP CONSTRAINT \[repl_identity_range_[\w]*\]", "\A\s*ALTER TABLE \[[\w]*\]\.\[[\w]*\] DROP CONSTRAINT \[MSmerge_df_rowguid[\w]*\]", "\A\s*ALTER TABLE \[[\w]*\]\.\[[\w]*\] ALTER COLUMN \[rowguid\] DROP ROWGUIDCOL", "\A\s*ALTER TABLE \[[\w]*\]\.\[[\w]*\] DROP[\w\s]*COLUMN \[rowguid\]", "\A\s*DROP TRIGGER+[\s]+\[\w+\]\.\[MsMerge", "\A\s*DROP INDEX+[\s]+\[MSMerge_index", "\A\s*EXEC sp_droprolemember N'MSMerge_PAL_role', N'MSmerge_[\w]*'", "\A\s*DROP ROLE \[MSmerge_[\w]*\]", "\A\s*DROP SCHEMA \[MSmerge_[\w]*\]", "\A\s*PRINT N'[\w\s\[\]\.]*'\s*\Z" ) function Should-Exclude([String]$TestString) { $result = $false; foreach($regexExp in $regexExpressions){ $regex = new-object System.Text.RegularExpressions.Regex("$regexExp", [System.Text.RegularExpressions.RegexOptions]::IgnoreCase ) if($regex.IsMatch($TestString)){ return $true } } return $false } cls #Load the assembly [System.Reflection.Assembly]:: LoadWithPartialName("Microsoft.SqlServer.Management.SqlParser") | Out-Null $ParseOptions = New-Object Microsoft.SqlServer.Management.SqlParser.Parser.ParseOptions $ParseOptions.BatchSeparator = 'GO' #Create the object $Parser = new-object Microsoft.SqlServer.Management.SqlParser.Parser.Scanner($ParseOptions) $SqlArr = Get-Content "C:\compare\out.sql" $Sql = "" foreach($Line in $SqlArr){ $Sql+=$Line $Sql+="`r`n" } $Parser.SetSource($Sql,0) $Token=[Microsoft.SqlServer.Management.SqlParser.Parser.Tokens]::TOKEN_SET $IsEndOfBatch = $false $IsMatched = $false $IsExecAutoParamHelp = $false $Batch = "" $BatchStart =0 $State =4 $Start=0 $End=0 while(($Token = $Parser.GetNext([ref]$State ,[ref]$Start, [ref]$End, [ref]$IsMatched, [ref]$IsExecAutoParamHelp ))-ne [Microsoft.SqlServer.Management.SqlParser.Parser.Tokens]::EOF) { try{ ($TokenPrs =[Microsoft.SqlServer.Management.SqlParser.Parser.Tokens]$Token) | Out-Null if($TokenPrs -eq [Microsoft.SqlServer.Management.SqlParser.Parser.Tokens]::LEX_BATCH_SEPERATOR){ $BatchEnd = $End $Batch = $Sql.Substring($BatchStart,($Batchend-$BatchStart)+1) $ShouldExclude = Should-Exclude $Batch if(-not $ShouldExclude){ Write-Host $Batch -ForegroundColor Blue } $BatchStart=$End+1 } }catch{ #$Error $TokenPrs = $null } } |
Listing 4: The PowerShell Script to parse the SQL Compare synchronization script
The array regexExpressions contains all the regular expression that, when matched against, will cause the batch to be rejected. As you can see from the matching rules at the start of the script, I am being quite specific about the batches that I wish to exclude, and so the regex matching should raise no false positives (i.e. a change that the developer wishes to make being flagged incorrectly for rejection).
However, if this proved to be the case, we could then build more intelligence into the functionality of the script to take account of more of the parser output. For example, if we are parsing a DROP PROCEDURE statement then we could build in an extra lookup to a white (or black) list of procedures and take an appropriate action.
Listing 5 shows the new synchronization script, post-parsing and filtering by the script in Listing 4.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
USE [WebContent] GO ALTER TABLE [dbo].[Customer] ADD [TitleID] [tinyint] NULL GO CREATE PROCEDURE [dbo].[GetCustomer] @CustomerID INTEGER AS SELECT Firstname , Lastname , TitleID FROM dbo.Customer WHERE CustomerID = @CustomerID GO /* Start of RedGate SQL Source Control versioning database-level extended properties. */ --<...content omitted...> |
Listing 5: The parsed synchronization script
As you can see, it contains just the changes our developer wishes to make, and includes the database versioning extended properties from SQL Source Control (not shown here).
Summary
The technique I present in this article moves us a bit nearer to the aim of an automated deployment strategy, by ensuring that there will be no bad surprises within the synchronization scripts.
There are many other uses of the parser too: we could write logic to enforce naming conventions, check on the misuse of table hints, to ensure that keyword capitalization, or to enforce any number of company policies.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments