


In my previous article (What is Microsoft Fabric All About) I explained what Microsoft Fabric is, how it came about and whether it brings anything new to the data insights domain.
In this article, I would like to go a bit deeper into the dark corners of Microsoft Fabric, since there are some gray areas, some amazing features, and some traps.
In my daily role as a Microsoft Fabric administrator for the past 6 months (not counting the years of PowerBI development and administration experience before that) I find myself sitting right on the ridge where three lands meet:
- The very popular Microsoft PR fluff about how great and mighty Fabric is
- The outcries and the struggles of the business users trying to deliver and consume data insights
- The comments of a guild of tech-savvy data engineers who for the most part refuse to bite into this Fabric apple.
Spoiler alert: while it is true that recently a single developer managed to incapacitate the Power BI reporting of an entire department for over 24 hours (this was done solely with MS Fabric out-of-the-box toolset), there are still some great features in Fabric that can be worth the risks and the hidden costs.
I should point out right off the bat that there are some significant features missing from Fabric, especially since these features are not new concepts.
Some of the shortcomings of Fabric
Let’s touch briefly on some of the possible issues you may have when you are using Fabric in the enterprise. These aren’t meant to scare you away from using it, but they are definitely concerns to look out for as you do:
- The lack of resource governance
- The lack of proper alerting method, even though there is plenty of telemetry data collected by Microsoft
- Considerable cost likely when it comes to the need to have separate capacities for dev and prod workloads
Resource Governance
There are absolutely no resource governance possibilities in the current setup of Fabric. This means that any item (workspace, report, dataset / semantic model) can get out of hand and this will affect the entire capacity.
I remember the good-old days when we were dancing happily when MS SQL Server Resource Governor got released and we could configure it to keep certain users and processes from exceeding certain threshold of the total resource pool. Ideally, this should have been in place before MS did the transition from “simple” premium capacity usage for data loads and reporting to a more performance-demanding data management do-it-all service.
Alerting
A big concern is the lack of an adequate alerting mechanism. This is particularly a concern when something goes out of hand. The admins may set up email alerts to be sent to users when a certain usage threshold of the capacity is exceeded, but these say nothing about who, what, and when. As we will see later, one of the suggested ways to deal with capacity overloads is to setup email alerts, however these alerts are very generic, and they don’t help if an overload starts because of a code change after hours and if there is no admin actively digging in the telemetry data until the next morning.
Capacity Resources
Let’s take a step back and explain what Capacity resources are, what smoothing and throttling is, and let’s use a simple analogy with a streaming service.
First of all, we need to select a capacity model, which costs a certain amount per month, and it gives certain Capacity Units (CUs). This is like what bandwidth you pay for with your internet service provider, or it could be how much content you can stream from your streaming service.
Smoothing is the mechanism which regulates how much compute can be borrowed from the future and in the short term this is a great feature because it helps us avoid throttling. In other words, smoothing is the mechanism which allows workloads to over-consume resources within given limits, assuming that the usage of resources will be a lot lower in the adjacent time period.
Over-consumption may be fine within a period of 9 minutes, Fabric averages the CU consumption over this rolling window, and if the over-consumed resources cannot be returned after this period, then throttling occurs. In the analogy, this means that we have streamed way too much over a short period and our service will be slowed down or eventually rejected.
Here is where the clumsiness of the over-consumption notifications come in: the capacity threshold may be exceeded either by background tasks (on-demand or scheduled refreshes) or by interactive tasks (report usage, visuals rendering, etc), but sometimes it may be just a single occurrence which is taken care of by the smoothing. However, at times, there may be an email notification and the borrowing-from-the-future may just make things worse for the entire capacity. What could make things absurd is if the borrowing starts in the evening and by the time the developers or admins establish the problem, there would be already an 8-hour performance debt.
During this debt there will be throttling to increasing degrees: interactive delay, interactive rejection, and eventually a background rejection.
As I mentioned, the good news is the smoothing, i.e. the overage protection. It is great for the consumption of resources up to 9 minutes. Your streaming is just running great.
If the overage exceeds the 10-minute threshold and is within the 60-minute mark, then Interactive Delay occurs, which means that there is some time delay when you try to load your Power BI reports. Your show starts with some delay, while you enjoy a moment of mindfulness.
Next, if the overconsumption continues between 1 and 24 hours, there is an Interactive Rejection. This means that the Fabric service refuses to display any content from Power BI reports which are in workspaces assigned to the overloaded capacity. Back to the streaming analogy, your show just does not start until you stop consuming resources and wait for as much time to pass as the overload lasted so far. In other words, if an overload started 8 hours ago, your service will be usable 8 hours from now.
If there is overconsumption for more than 24 hours, then there is Background Rejection – this means that the Fabric service refuses to refresh datasets for the time being.
For more details, here is the official MS documentation on Throttling.
Dealing with a throttled Fabric capacity?
According to the Microsoft documentation and support, the following topics are suggested:
- Enable autoscale
- Scale up the capacity
- Permanently move some heavy / important production workloads to another capacity
- Set up email alerts
- Work with the developers to optimize their datasets
- Reduce development dataset size
- Enable log analytics for heavy workloads and analyze the details
After looking at the items, there are not that many straightforward options. Most of the above options are proactive ‘best effort’ tasks, except for one – “Permanently move some heavy / important production workloads to another capacity”.
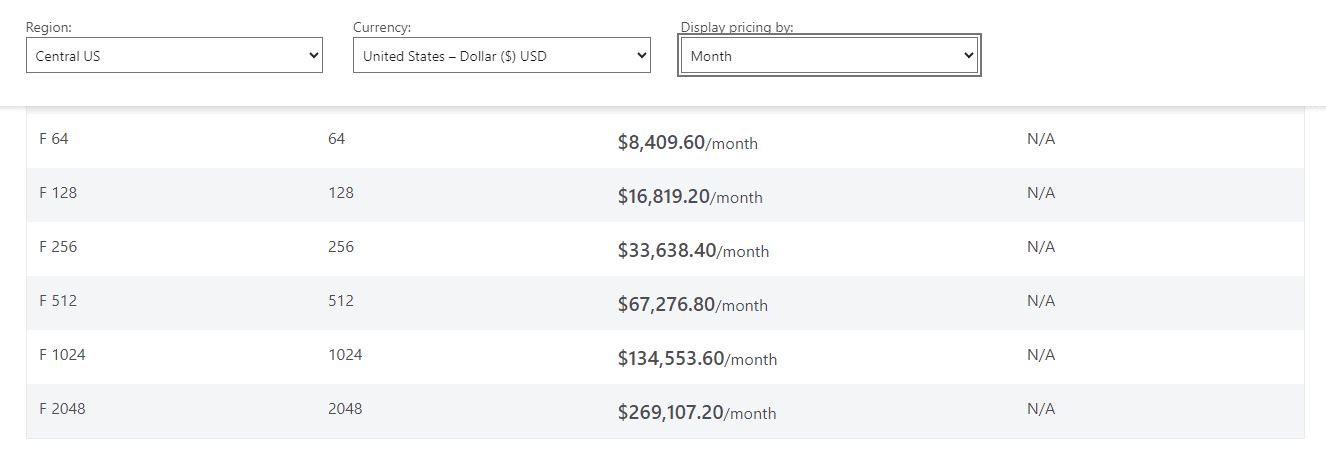
The above options may cause a few raised eyebrows, for several reasons. Considering the current Fabric costs, very few Enterprises will have the financial backup to keep separate Fabric capacities for testing and production workloads. (Fabric Pricing Calculator: https://azure.microsoft.com/en-us/pricing/details/microsoft-fabric/. Naturally, the prices are apt to change, and they differ between regions, but this is what they were in Central US when I wrote this in June 2024.)
And when disaster strikes, very few companies will have a separate capacity laying around, waiting for the critical production reporting to be reassigned to a clean working capacity so the CEO can get their data on time.
There is some good news, however: since very recently Fabric supports a pay-as-you-go option, which may be good for development purposes. It can be automated to be resumed and shutdown on a schedule via Power Automate, and in general it works quite well.
So far, we have looked at the business users and the developers in an Enterprise, as they are drawn by the self-service and drag-and-drop functionality of a SaaS platform.
Let’s turn our attention to the skilled Data Engineers who ask the question of comparison between Azure Databricks and Fabric. After all, the services are very similar and overlapping.
If we take a F64 Fabric capacity and a 8-core Spark environment (a cluster with one driver and 15 workers in Databricks) we can run some comparisons. The pricing patterns are very dependent on our usage patterns, but in general, an F64 capacity is more or less $8,409 per month (it depends on region), and Azure Databricks varies based on utilization between $4,500 and $13,735 per month.
The comparison is not easy at all, since we get different hidden hurdles, based on architecture and development strategy.
For example, in the above cases of overloading Fabric, we may need to pay $16,819 per month if we are to increase the capacity SKU and Databricks is $13,735. If Fabric is underutilized, we spend $8,409, and for a 50% underutilized Databricks, we spend about $4,500. It all depends because there is also seasonality in data management – some months have holidays, less reporting, etc.
There are, of course, other parameters to be thrown in the comparison, specifically the limitations and caveats of the Fabric and its Direct Lake. I will not get into details here but will just point to the Microsoft documentation on it: https://learn.microsoft.com/en-us/fabric/get-started/direct-lake-overview#fallback
There is one significant feature of Fabric that in reality will make it hard to replace in a lot of Enterprises: the fact that Power BI is an integral part of it. In other words, there is a clever vendor lock-in, since most business users and developers are accustomed to Power BI, and migrating to something else is seen as a vast effort.
Conclusion
As we have seen so far, there are several features missing from Fabric and there are some hidden costs, especially if there is no well-established architecture and development strategies in place.
Fabric may become a great product one day and only time will tell, but so far Fabric reminds me of the several stories of products in Microsoft’s history when they tried to bundle products that would be a fix-it-all for a great bundled price. One of the most famous stories is the attempt to make SharePoint a single do-it-all platform for the Enterprise, attempting to do even Business Intelligence reporting.
As I mentioned, while there are some serious challenges in Microsoft Fabric, it is indeed an evolving package and eventually it will be a great product. Only time will tell if Fabric stands the test of time against competitive technologies.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments