
Welcome to the second blog of the “magic of parameters” series. In the first entry, I covered memory parameters, and in this article. In this article will talk about PostgreSQL configuration parameters which manage the (auto)vacuum and (auto)analyze background processes.
Why vacuuming is necessary?
Before we start talking about vacuum and analyze-related parameters, we need to touch on the concept of vacuuming in PostgreSQL. This concept is Postgres-specific, and for DBAs coming from Oracle and Microsoft SQL Server it might feel confusing – you can’t directly map it to any previous experiences. (Note: both Oracle SQL Server do share some similarities in some of their configurations. For example, SQL Server memory optimized tables have a similar process referred to as garbage collection.)
Let’s start by looking at how data is stored in PostgreSQL database. The generic structure of a block is shown in Figure 1.
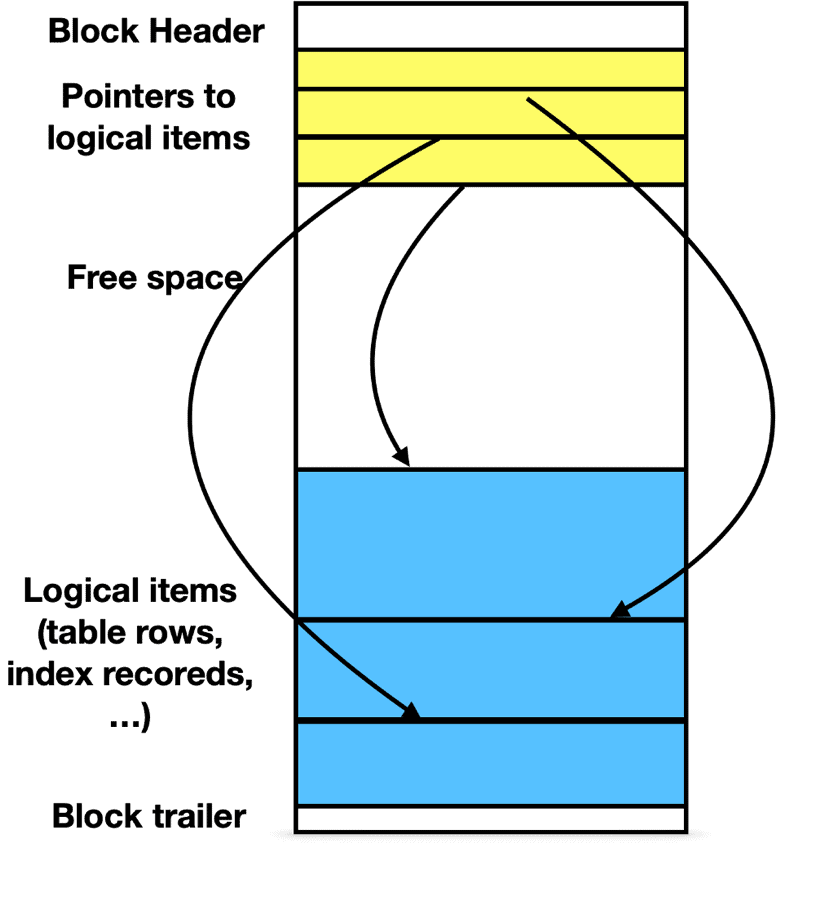
Figure 1. Generic block structure
Table rows are stored in a heap, and their order is not guaranteed. In Figure 1, you can see free space in the block, which can be filled with new rows of data. If your previous DBA experience is with a lock-based RDBMS engine, you would think that we should set up a fillfactor less than 100% for each table so that there will be some room to maintain most updated records in the same block.
Be ready for a surprise! Although you can define a fillfactor <100%, this option is rarely used in PostgreSQL. The reason is that PostgreSQL never updates a row in place due to how it implements concurrency controls!
Multi-version concurrency control
To allow multiple users to access data concurrently and to avoid waits when data is being updated, PostgreSQL uses multi-version concurrency control (MVCC). It is implemented using Snapshot Isolation (SI): each SQL statement sees a snapshot of data (a database version) as it was when the transaction started, regardless of the current state of the underlying data. This approach provides multiple advantages:
- It prevents statements from viewing inconsistent data due to table modifications made by other transactions
- It provides transaction isolation for each session
The modified tuples are saved in a new place, within the same block or in a different block, but if some transactions still are still actively accessing the old versions of the modified tuples, these tuples are kept “alive.”
How does Postgres know which versions should be kept alive, and which can be recycled? Each table has several “hidden” (system) attributes which you can’t see when you execute SELECT * FROM <table>. Two of these hidden attributes are xmin, which contains the ID of the transaction which created the row, and xmax, stores the ID of the transaction which deleted the row (either by updating or by deleting).
Now, for any processes transaction ID that is between greater or equal to xmin and less than xmax, this row is active and should be visible to that transaction. PostgreSQL marks a tuple dead if there are no more active transactions that the row could be visible to. Figure 2 presents a block layout with a dead tuple.
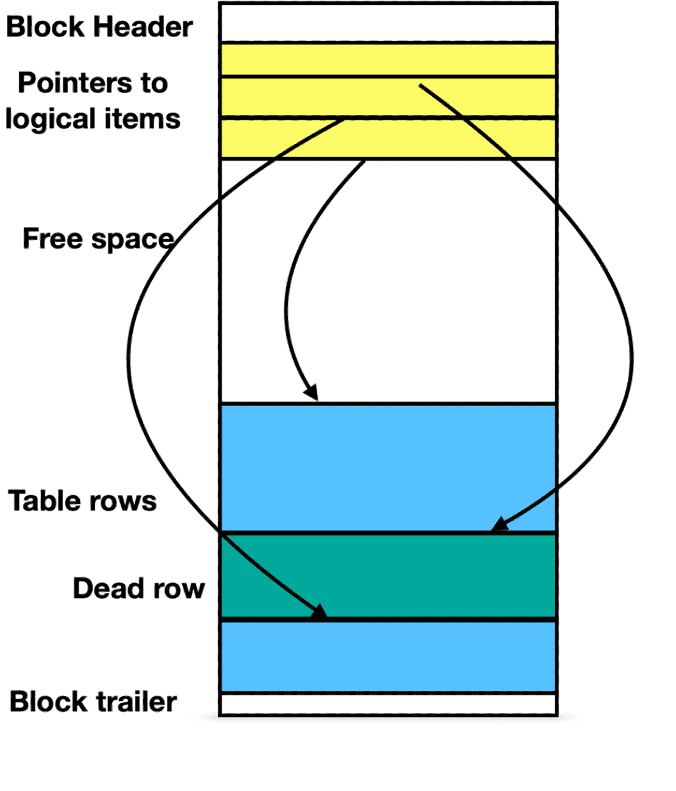
Figure 2. Block layout with dead tuple.
What is the effect of MVCC on the database performance? On the one hand, the absence of locking facilitates performance. On the other hand, having multiple versions and thereby dead tuples creates both table and index bloat.
What’s VACUUM for?
VACUUM checks all the blocks and marks the old tuples “dead.” It’s important to remember that VACUUM does not rewrite the block and does not “compress” the data. It simply marks the space occupied by dead tuples as “reusable.” You can compress data and return the unused space back to the operating system by running VACUUM FULL.
What else does VACUUM do?
By this time, it might already feel like “too much information”, especially if that’s the first time you are exposed to the concept of vacuuming in Postgres. But before we proceed further, let’s note that the job of VACUUM is not limited to reclaiming space. In addition, it:
- Updates data statistics used by the PostgreSQL query planner.
- Updates the visibility map, marking the blocks with no dead tuples
- Protects against loss of very old data due to transaction ID wraparound.
If your job is to manage Postgres instances, you might want to do more reading on the topic of vacuuming, beyond what we will cover, but for the start, let’s just keep in mind there are many things vacuum does.
What’s Autovacuum for?
Autovacuum is a daemon which periodically invokes vacuuming of tables and indexes. Autovacuum does not require any scheduling, instead, its behavior is driven by several system parameters, which will be described later in this article.
Myths about the vacuuming process
Since the concept of vacuuming is not as common in other RDBMS and is not all that we;; understood by PostgreSQL newbies (and some experienced people too!), it is a source for multiple common myths.
In this section I will do what I can to dispel these myths.
Myth #1. The vacuum process makes everything run slower
The reality. VACUUM (and by extension, autovacuum) is obviously not cost-free, but the cost is far less than if it was not executed. When rows are being modified, dead tuples begin to accumulate and everything can become slow when the autovacuum does not run regularly.
Tables become bloated (more details on table bloat later in the article), which makes sequential scans slower. Visibility map is not updated, which prevents the usage of index-only scan (PostgreSQL still needs to check the heap to make sure that index does not point to any dead tuples).
Myth #2. The vacuum process blocks other operations
The reality. The VACUUM process is aborted if it is blocking any write operation. The wait time is determined by the deadlock_timeout parameter. In fact, on a busy table, it may be beneficial to run vacuum often (ideally using autovacuum), because otherwise, it might not have a chance to finish for days and weeks, because it is blocked by write operations.
Myth #3. On busy mission-critical databases, it’s a good idea to disable autovacuum and run scheduled vacuum jobs during the quiet time.
The reality. “Busy systems” (in terms of modifying data) may be busy most of the day, not just certain times of the day, with very few exceptions. If you disable autovacuum and run vacuum on a schedule, such as during “quiet time,” vacuum will end up with more job to do (if the system is “busy” there could easily be a lot of dead tuples by that time!). Now, you might end up blocking the tables for longer periods of time, so you need to make sure that there are no write operations for the extended period of time.
In addition, even if the system behavior is predictable in general, there are chance of burst updates, and you may end up with more bloat than expected, with even more severe consequences.
Myth #4. If you use other ways to control bloat, like pg_squeeze, you do not need to run vacuum at all.
The reality. Recall that reclaiming the space is only one of several functions performed by VACUUM. You might be able to reclaim the space, but other vacuum functions won’t be performed, most importantly, old records won’t be frozen. Once again if we are talking about “busy systems” the risk of TXID wraparound is higher.
Myth #5. You need to monitor the autovacuum runs and make sure that all tables are vacuumed at least daily
The reality. On the tables with few writes autovacuum might run once a week or even less frequent. The parameters explained in the next section determine how often vacuuming will be performed on specific tables.
It is possible to view the statistics on updates for each table and to set up some monitoring based on this information, but that would effectively mean replicating the logic of autovacuum. More important is to monitor system performance and tables bloat
The most important parameters that govern the vacuum process
There are many vacuum-related parameters which allow very precise vacuum tuning. However, in practice, it is often enough to set up correctly just a handful of them. Most of them control autovacuum, to help tune the automatic execution of the vacuum process.
autovacuum_vacuum_cost_delay: amount of time the process will sleep after the max cost exceeded- The default value is 20 ms, which is very conservative and may result in vacuuming not keeping up with changes. Start with reducing it to 10ms, and if necessary, you can go as low as 2 ms.
- Note that this parameter is different from the naptime (see below)
autovacuum_max_workers: max parallel workers (across server) which are invoked for each autovacuum invocation.- Most often, this parameter is set to half of the total number of parallel workers defined for the instance, however, it is often beneficial to increase this number even more.
autovacuum_naptime: minimum delay between autovacuum runs on any given database.- Each time the
autovacuumdaemon starts, it examines the database and issuesVACUUMandANALYZEcommands as needed for tables in that database. Since this setting determines the wake-up time per database, anautovacuumworker process will begin as frequently asautovacuum_naptime / number of databases. For example, ifautovacuum_naptime = 1 minand we have five databases, anautovacuumworker process would be started every twenty seconds. - The default value for this parameter is 1 min, however, on busy databases with many writes it can be beneficial to increase its value to prevent autovacuum waking up too often. With this parameter, like with many others, there is a trade-off between “too often” and “too much work on each invocation”.
- Each time the
autovacuum_vacuum_scale_factor: percentage of changes to the table after which a vacuum should run- The default value for this parameter is 0.2; for larger tables, should be reduced to 0.05 (and consider this for all tables for that matter)
autovacuum_analyze_scale_factor: percentage of changes to the table after which an analyze should run
The default value is 0.1; for larger tables, should be reduced to 0.05 (and consider for all tables here as well) respectively.- Note: The default for the
autovacuum_vacuum_scale_factoris 0.2 (20%) andautovacuum_analyze_scale_factoris 0.1 (10%). While the default values perform acceptably for tables of a modest size (up to around 500MB), for larger tables these values are usually too high.
- Note: The default for the
- autovacuum_vacuum_cost_limit: The default value of -1 for
autovacuum_vacuum_cost_limitresults inautovacuum_vacuum_cost_limit = vacuum_cost_limit. However, this value is distributed proportionally among the running autovacuum workers. This is done in order that the sum of the limits of each worker never exceeds the limit on this variable. Therefore, the default value of 200 forvacuum_cost_limitis generally too low for a busy database server with multipleautovacuumworkers.should be set to -1 - vacuum_cost_limit: cumulative cost after which the vacuum should stop, should be set to 200 X number of workers
How to tune (auto)vacuum
Vacuuming is vital for PostgreSQL databases well-being, and autovacuum should never be turned off unless there are really exceptional and unusual circumstances. At the same time, autovacuum should be always tuned for specific environment needs.
Tuning autovacuum is challenging, because we need to take into account the vacuuming speed, level of I/O, and blocking. To start with, the default set of vacuum-related parameters would work adequately. After some time passes, check system bloat and if it appears to be high and adjust the autovacuum settings. What should be considered a high bloat depends on many factors.
On average, bloat below 20% is considered normal. For larger tables, 10% maybe considered a significant bloat, while for small tables, even 50% bloat maybe fine. If the bloat does not result in visible performance degradation, there is no pressing need to address it.
How to determine if your tables are bloated
There are examples of such queries that can be found in many PostgreSQL blogs and company’s websites. Many of the solutions require extensions, if you are up to installing additional extensions to monitor your bloat, you can use the following:
|
1 |
CREATE EXTENSION pgstattuple; |
This is one of many extensions provided with PostgreSQL contrib package, so you do not need to download anything, just execute the CREATE statement. The available functions are documented in PostgreSQL documentation.
If you do not want to install any extensions, the following queries will provide good estimates:
If your system is even somewhat active, it is essential that you monitor the bloat in your data objects.
How to monitor
Although you can find the last time when vacuum/autovacuum and analyze/autoanalyze were executed in the pg_stat_all_tables, we do not recommend monitoring this value. As it was mentioned in the previous section, if the updates didn’t reach a threshold, the is no need for autovacuum to run. However, the pg_stat_all_tables object contains a lot of valuable information which may be very useful for evaluating the database health.
For each table, pg_stat_all_tables contains the following information:
|
Column |
Description |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
As you can see, this table provides valuable information about the dynamics of each table. However, the only way to see whether the autovacuum is tuned correctly is to run bloat checking queries on regular basis.
Conclusion
It is not uncommon that new PostgreSQL users and even DBAs do not pay much attention to tuning autovacuum and monitoring tables and indexes bloat. This happens since these concepts are Postgres-specific and are not in the mental checklist of database professionals with previous experience elsewhere.
Thereby, it is important to educate yourself about the role vacuum and analyze play in the PostgreSQL databases well-being.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments