



PostgreSQL has first-class support for range types (tsrange, tstzrange, int4range, daterange, and user-defined ranges) that enable concise modelling of time periods, numeric intervals, and any continuous value range. This article – Part 2 of my series on the overlap query problem in PostgreSQL – focuses on indexing range data and preventing overlapping values in tables.
Four key topics are featured in this article:
(1) GiST (Generalised Search Tree) indexes are PostgreSQL’s standard index type for range overlap queries – a single GiST index on a range column efficiently answers queries with && (overlap), @> (contains), and other range operators;
(2) EXCLUDE constraints using GiST – PostgreSQL’s unique mechanism for enforcing ‘no two rows have overlapping values’ at the database level, using EXCLUDE USING GIST (col1 WITH =, col2 WITH &&) – typical for reservation/scheduling systems;
(3) half-open range semantics – PostgreSQL ranges default to half-open [start, end) which matches SQL standard and avoids the boundary ambiguity of closed ranges;
(4) B-tree-plus-GiST indexes using the btree_gist extension – when range overlap queries also filter on equality predicates (like restaurant_id = 5 AND reservation_range && ‘[10:00, 11:00)’), a single composite GiST index including both columns via btree_gist outperforms separate indexes.
Each topic has SQL examples; prerequisite knowledge is basic PostgreSQL and Part 1 (introduction to range types.)
A Range For All Occasions
Our Part I query used the following WHERE clause:
|
1 |
WHERE tsrange(o.start_time, o.end_time) && tsrange(p.enter, p.leave) |
The “tsrange()” functions return timestamp ranges. But overlap queries aren’t limited to timestamps; they can be constructed from integers and floating-point values too. Imagine an arbitrage database that tracks the minimum and maximum price paid for a commodity. If you wish to find all customers who’ve paid between $1.35 and $1.65 for pork bellies, you would construct a numeric range using the “numrange()” function; the query WHERE clause would be:
|
1 |
WHERE numrange(min_price, max_price) && numrange(1.35, 1.65) |
For integer and bigint ranges, there are the functions int4range() and int8range(). Date-only chronological intervals (without time), can be constructed with daterange(), and there’s even a tstzrange() function, which takes into account timezone on the timestamp values involves. (But remember: like database columns defined using “with time zone”, the actual time zones aren’t stored, just a flag indicating that the timestamps should be converted to local time on the client.)
Preventing Overlapping Table Rows
A common need for overlap queries is to prevent rows containing overlapping time periods from being inserted into a table, similar to a UNIQUE restriction. For instance, a conference room booking list that doesn’t allow simultaneous reservations, or a podcast schedule that allows only one episode playing at any given time. Business logic like this can be done within the database using a trigger or stored procedure. But using GiST, there’s a simpler way.
To illustrate, consider a basic table for upcoming podcast episodes, holding the episode identifier, and two timestamps, indicating the planned start and stop times. To prevent any two rows from overlapping in time, use the “exclude” operator as shown below:
|
1 2 3 4 5 6 |
CREATE TABLE episodes ( episode_id INTEGER NOT NULL, planned_start TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL, planned_end TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL, EXCLUDE USING gist (tsrange(planned_start, planned_end) WITH &&) ); |
We can verify this by trying to insert two rows that conflict with each other:
|
1 2 3 4 |
INSERT INTO episodes VALUES (1, '11/5/2024 08:00 am', '11/5/2024 09:30 am'); INSERT INTO episodes VALUES (2, '11/5/2024 09:00 am', '11/5/2024 11:00 am'); |
Since episode 2 starts before episode 1 ends, the second insert fails with an error that starts like this:
ERROR: conflicting key value violates exclusion constraint …
Like a UNIQUE constraint, EXCLUDE creates the underlying index to support the constraint, meaning you don’t need to follow the table definition with a separate index creation statement.
Note: an actual business scenario would likely require additional criteria to determine an overlap error. A hotel reservation system would need the room number, for instance, or our podcast example above might support multiple channels, each broadcasting simultaneously. This can be done in an EXCLUDE statement, but it requires adding B-tree support to GiST, as described below.
Modifying Range Semantics
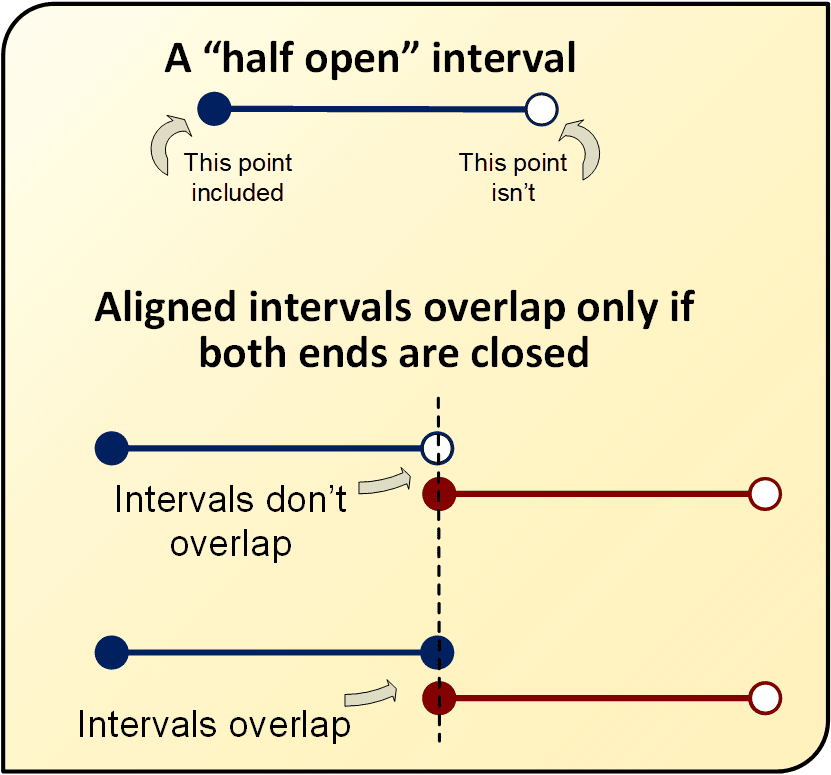
In Part I, we noted that standard SQL semantics define ranges as “half-open” — the start point of a range is inclusive (included in the range), but not the end point is exclusive (not included.) (Joe Celko noted in this article the idea of half open high, and half open low as well).
This method of storing ranges simplifies storage, but tends to complicate overlap calculations: an interval that ends at 5pm will not overlap with one that begins precisely at that same time (though it will overlap with one that begins even a millisecond sooner). All range construction functions (tsrange(), daterange(), etc.) follow these same semantics.
Get started with PostgreSQL – free book download
You can override this behavior easily. The constructor functions accept a third parameter: a two-character string indicating the status of each endpoint: a square bracket indicates inclusion; a parenthesis denotes exclusion. The following chart lists the possibilities:
|
Parameter |
Behavior |
|
‘()’ |
exclude both endpoints |
|
‘[]’ |
include both endpoints |
|
‘[)’ |
include start point; exclude end. (default) |
|
‘(]’ |
exclude start point; include end. |
To illustrate, let’s return to our podcast episodes example. In it, we created a “no overlap” constraint using the default “half open” semantics. This allows episodes that begin at exactly the same time as a previous episode ends. For instance, the following two rows don’t overlap, even though the end of one episode matches the start of the other:
|
1 2 3 4 |
INSERT INTO episodes VALUES (3, '11/6/2024 08:00 am', '11/6/2024 09:00 am'); INSERT INTO episodes VALUES (4, '11/6/2024 09:00 am', '11/6/2024 10:00 am'); |
But when creating the constraint, if we instruct the tsrange() function to include both endpoints like this:
|
1 2 |
EXCLUDE USING gist (tsrange(planned_start, planned_end, ‘[]’) WITH &&) |
The second INSERT would fail due to the constraint.
Boosting Performance: a Different Shade of GiST
Now let’s return to our main point: boosting performance. The GiST index type is a good choice for general-purpose overlap queries. But often, time-series data is distributed fairly evenly across a range of dates, without a great deal of overlapping values.
A good example is our sample data in Part I: it’s randomly spread across a 20-year interval, and any given row overlaps with only a small fraction of the other rows in the table. For data like this, a space-partitioned GiST index can yield better performance. PostgreSQL also supports this type of index – called “SP-GiST”.
The statement to create an SP-GiST index is nearly the same as regular GiST. Using our “patrons” example table from Part I, we created a normal GiST index like this:
|
1 |
CREATE INDEX ON PATRONS USING gist(tsrange(enter,leave)); |
For SP-GiST, we change the index type to “spgist” and specify an operator class:
|
1 |
CREATE INDEX ON USING spgist(tsrange(enter, leave) range_ops); |
Here, the built-in “range_ops” operator (unsurprisingly) means we want to perform range operations on ou  r index.
r index.
How much of a performance increase can we expect from our space-partitioned version of GiST? On our Part I test data, replacing the old GiST index with SP-GiST reduced the query time from 5.2s down to 3.7s – a healthy 30% boost. In a best-case scenario (say a table in which overlapping rows were disallowed), you might expect as much as a 50% increase. But on datasets with a high degree of overlap, SPGiST can perform worse. Test against your own data!
The SP-GiST index type has some drawbacks. For one, it doesn’t support multi-column indexes, meaning the next technique we describe below can’t be used with them.
Adding B-Tree support to GiST
Usually, an overlap query has criteria beyond the ranges themselves. A restaurant reservation doesn’t overlap with another unless they’re for the same table; a hospital can schedule multiple visits at the same time-period if the patients are different, etc.
Returning to our sample code in Part I which used an example of patrons and security outages at one museum: what if the data included multiple sites? Now an “overlap” only occurs if the patron and outage occurred at the same location. How does this change things?
Let’s recreate our tables, this time adding a location_id foreign key:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE patrons ( patron_id INT NOT NULL GENERATED ALWAYS AS IDENTITY, location_id INT NOT NULL, enter Timestamp(0) NOT NULL, leave Timestamp(0) NOT NULL ); CREATE TABLE outages ( location_id INT NOT NULL, start_time Timestamp(0) NOT NULL, end_time Timestamp(0) NOT NULL ) --Note, the code to load these tables is located in the Appendix |
Our query for overlapping values now has a join condition, rather than a CROSS JOIN:
|
1 2 3 4 |
SELECT * FROM patrons p INNER JOIN outages o ON p.location_id = o.location_id WHERE tsrange(o.start_time, o.end_time) && tsrange(p.enter, p.leave); |
Since this is randomly generated data, you may get back more or less rows, so your performance may vary.
If you run this query using the same GiST index we created in Part I, performance will be from bad to abysmal, depending on how many different location values exist. Let’s assume there are 20 possible locations and see if we can again improve performance.
Our natural instinct for a two-condition query like this is a multi-column index, one for each condition. And, since the timestamp range is much more specific than the location_id (in technical terms, its cardinality is higher), it should be the first column indexed. That leads us to try this command:
|
1 2 |
CREATE INDEX ON patrons USING GIST(tsrange(enter,leave), location_id); |
Our instincts are good, but on a default configuration of PostgreSQL, this statement displays an error.
ERROR: data type integer has no default operator class for access method "gist"
As powerful as they are, GiST indexes don’t support simple operations like direct comparisons of strings, dates, or (in this case) integers. Luckily, PostgreSQL ships with an extension that adds B-Tree type operations to GiST. All we need to do is install it:
|
1 |
CREATE EXTENSION btree_gist; |
Now we can create the index above without error, and a similar index on outages:
|
1 2 |
CREATE INDEX ON outages USING GIST(tsrange(start_time, end_time), location_id); |
This not only restores the performance in the query from Part I that lacked location_id:
|
1 2 3 4 5 |
SELECT * FROM patrons p CROSS JOIN outages o WHERE tsrange(o.start_time, o.end_time) && tsrange(p.enter, p.leave); |
But betters it slightly (4.9s on my test system, again with randomly generated data, as you can see in the full script to populate the test table, create indexes, and perform the query in Appendix I, below.
Note: Our location_id is a low-cardinality value (only 20 possible values, because I used TRUNC(RANDOM()*20) to generate them).
If there were many more locations (e.g. 100,000+), the index might likely be better structured with location_id as the first column; but in that case, performance would likely be no better than a default B-Tree index, as that’s the scenario these indexes are designed for.
Again: test with your own data!
In Part III of this series, we’ll explore uses of GiST beyond overlap-type queries.
Free desktop tool for fast PostgreSQL monitoring and diagnostics
Appendix I : Sample SQL Script
Here are some useful scripts for working with the example code in the article:
|
1 2 3 4 5 6 7 8 9 10 11 |
-- create tables CREATE TABLE patrons ( patron_id INT NOT NULL GENERATED ALWAYS AS IDENTITY, location_id INT NOT NULL, enter Timestamp(0) NOT NULL, leave Timestamp(0) NOT NULL ); CREATE TABLE outages ( location_id INT NOT NULL, start_time Timestamp(0) NOT NULL, end_time Timestamp(0) NOT NULL); |
For doing some of the examples, particularly those where timing is important, you can use this script to generate data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
-- create 1M random patrons and 250K random outages INSERT INTO patrons (location_id, enter,leave) ( SELECT TRUNC(RANDOM()*20), r, r + '1 minute'::INTERVAL * ROUND(RANDOM()+1 * 60) FROM (SELECT NOW() - '1 minute'::INTERVAL * ROUND(RANDOM() * 15768000) AS r FROM generate_series(1,1000000)) AS sub); INSERT INTO outages ( SELECT TRUNC(RANDOM()*20), r, r + '1 minute'::INTERVAL * ROUND(RANDOM() * 20) FROM (SELECT NOW() - '1 minute'::INTERVAL * ROUND(RANDOM() * 15768000) AS r FROM generate_series(1,250000)) AS sub); -- delete malformed entries from randomly generated data. DELETE FROM patrons WHERE enter >= leave; DELETE FROM outages WHERE start_time >= end_time; |
The following will create the indexes mentioned in this article. They will require the BTREE_GIST extension to execute.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- create indexes CREATE INDEX ON patrons USING gist(tsrange(enter,leave), location_id); CREATE INDEX ON outages USING gist(tsrange(start_time, end_time), location_id); -- run test query EXPLAIN ANALYZE SELECT * FROM patrons p INNER JOIN outages o ON p.location_id = o.location_id WHERE tsrange(o.start_time, o.end_time) && tsrange(p.enter, p.leave); |
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments