

Partitioning in PostgreSQL was for many years a feature almost entirely ignored, and even today is often thought of only as a means to increase performance on large tables. While it’s certainly useful for this, it’s also an invaluable tool for solving common data maintenance problems. In this article, we’ll examine the feature from this perspective.
Let’s consider a common situation: a table continually ingesting time series data ordered chronologically: purchase orders, forum posts, time-series data, whatever. Most systems contain more than one table like this. And because we live in a world of Big Data, these tables can contain hundreds of millions, even billions of rows. Business rules require the data to remain active for some fixed period of time, then be deleted, (or archived first, then deleted). Commonly this is a monthly process: every month copy data that has “aged out” to another location, then delete the rows from the live table.
This leads to problems. Deleting millions of rows in a single transaction can take hours, and is a concurrency nightmare that can stall the entire system. Breaking the delete into multiple transactions helps concurrency, but takes even longer. Performing the process daily (or more frequently) is inconvenient, might cause problems for month-oriented reports, and — depending on where you’re archiving to — may not even be possible. Finally, you have a data integrity issue. If data is archived (or copied) in one transaction, then deleted in another, then a row updated during that interval can lose those changes.
There are workarounds for all this, but with partitioning, the problems vanish.
Creating a Partitioned Table
A partitioned table in PostgreSQL is stored internally as a series of smaller sub-tables, each containing a portion of the total rows. This partitioning is invisible to SQL statements on the main table; you can write a query to update or return rows without knowing where the rows actually are. This is a crucial point: if your convert a table to partitioning, all existing queries will work unchanged.
There are different ways you can define how the rows are divided up, but the most common is by a range of dates. For example, a simple table holding user’s posts to a web forum could be defined as:
|
1 2 3 4 5 |
CREATE TABLE Posts ( user_id INT NOT NULL, post_time TIMESTAMP(0) NOT NULL, contents TEXT ) PARTITION BY RANGE(post_time); -- sets the partition |
Note the “partition by range” clause. This defines a table partitioned by the range of values in the column post_time. At this point the table isn’t fully created yet — it’s just a ‘shell’. We can query it (and see zero rows) but if we attempt an INSERT, we’ll get an error.
For example:
|
1 2 |
insert into Posts (user_id, post_time, contents) values (1,'1/1/2024','test'); |
This causes the following error:
SQL Error [23514]: ERROR: no partition of relation "posts" found for row
Detail: Partition key of the failing row contains (post_time) = (1900-01-01 00:00:00).
To do this, we must define at least one partition. Let’s create three partitions, each one month in size:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE Posts_Jun2024 PARTITION OF Posts FOR VALUES FROM ('2024-06-01') to ('2024-07-01'); CREATE TABLE Posts_Jul2024 PARTITION OF Posts FOR VALUES FROM ('2024-07-01') to ('2024-08-01'); CREATE TABLE Posts_Aug2024 PARTITION OF Posts FOR VALUES FROM ('2024-08-01') to ('2024-09-01'); |
The partition names can be any name that would be valid for a table name, but following a descriptive format is helpful. Note that the end of each partition starts at the first day of the following month. This follows the SQL standard of “half open” intervals, the actual range includes all values up to (but not including) the end value. Or as the PostgreSQL documentation defines “Each range’s bounds are understood as being inclusive at the lower end and exclusive at the upper end.”
In the end, you will end up with a data structure that is displayed in the following diagram:
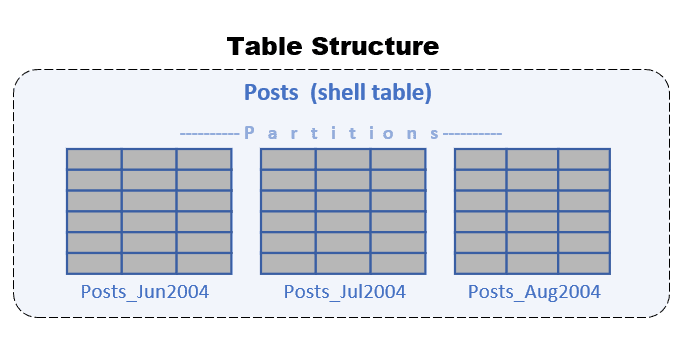
You can query each of the partition tables independently, but you can also query the shell table just like any other table, including all the DML operations.
Managing data in a Partitioned Table
Now let’s add some data. You may not be surprised that it works just like it would if not partitioned:
|
1 2 3 4 5 6 7 8 |
INSERT INTO Posts VALUES (1, '2024-06-15 20:45:00', 'A post in June.'); INSERT INTO Posts VALUES (2, '2024-07-04 15:37:00', 'A post in July'); INSERT INTO Posts VALUES (3, '2024-08-29 08:13:00', 'A post in August'); INSERT INTO Posts VALUES (4, '2024-09-01 00:00:00', 'This will fail'); |
The last query fails with the following error because 2024-09-01 00:00:00 is just outside of the end boundary in the Posts_Aug2024 partition.
SQL Error [23514]: ERROR: no partition of relation "posts" found for row
Detail: Partition key of the failing row contains (post_time) = (2024-09-01 12:00:00).
Note we don’t insert into the individual partitions, but into the main Posts table.
We haven’t created a partition for September yet, so the last insert fails! If you attempt to insert rows with dates that don’t match an existing partition, you’ll get this error, so it’s important to define partitions in advance. (Most production systems will use a tool like the PostgreSQL extension pg_Partman to do this automatically.)
Let’s verify the data is there. Again: we don’t query the individual partitions: selecting from the main table pulls data from all of them:
|
1 |
SELECT * FROM Posts; |
Yes, three rows:
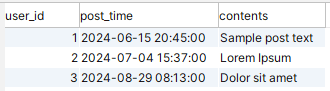
So far we’ve gone to a lot of work just to confirm a partitioned table works like an ordinary one. Where’s the benefit? Hang on, because here comes the payoff. Let’s roll the clock forward a year. Now the data from June of 2024 has ‘aged out’ and is ready to be removed from production. How do we do this? Run one command:
|
1 |
ALTER TABLE Posts DETACH PARTITION Posts_Jun2024; |
That’s it — done! The Posts table now no longer has data for June of 2024, and Posts_Jun2004 is now a separate table that can be queried, archived, or deleted without affecting the main table. Let’s verify by running our same SELECT statement again, to receive this:
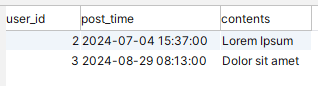
Just two rows — our June data no longer exists in the main Posts table. But we can query the detached June partition as a separate table:
|
1 |
SELECT * FROM Post_Jun2004; |
And see this:
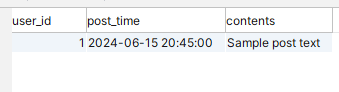
Here’s the best part. We only detached one row in this example, but the detach statement should complete near-instantly, no matter how many rows are in the partition. You can remove a hundred million rows in a fraction of a second. No more waiting hours to clean out old data.
The partition table can be left in the database, if desired, or it can be deleted instantly with a drop command. In fact, if there’s no requirement to archive old data, you can skip the detach entirely and simply do this from the start:
|
1 |
DROP TABLE Posts_Jun2004; |
Again, this will return almost instantly. Both forms require a (very brief) access exclusive lock on the table; if this is a problem, run the detach statement with the CONCURRENTLY keyword, which requires only a shared lock.
Partitioning Existing Tables
PostgreSQL doesn’t allow a table to be directly converted to partitioned. There is a workaround though: rename the existing table, create a partitioned table with the original name, then attach the renamed table to the new.
Example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
--Rename the table for transitioning structures ALTER TABLE Posts RENAME TO Posts_old; --Create the new table CREATE TABLE Posts( user_id INT NOT NULL, post_time TIMESTAMP(0) NOT NULL, contents TEXT ) PARTITION BY RANGE(post_date); CREATE TABLE Posts( post_date DATE, post_id INT ) PARTITION BY RANGE(post_date);--Add a partition ALTER TABLE Posts ATTACH PARTITION Posts_old FOR VALUES FROM ('2000-01-01') TO ('2024-06-01'); -- now define monthly partitions for future data |
Obviously, with all the existing data in one partition, this approach will take time to see the full benefits.
An alternative plan is to create a new partition table, perhaps named Posts_Partitioned, create partitions for the existing data, then load data into the partition tables directly. This can be a safer bet when you want to reorganize the table into many partitions.
Performance Considerations
This article focuses on data administration, but it would be remiss to not mention the subject of performance. Partitioning slices up a table’s indexes just as it does the table itself. For high-speed ingestion of chronologically-ordered data, this is a huge speed boost, as only the index on the current partition must be updated.
One recent system I converted a time-series table to partitioned resulted in an 80%+ increase in insert performance, and allowed the table to handle several million inserts per minute, and even larger gains are possible.
There are use cases where partitioning reduces performance though, so be sure the feature is a good fit before choosing it (and not just academically… test your system with and without partitioning. )
A (Small) Warning
One problem is that unique constraints can’t operate across partitions. For instance, if you try to define the following table:
|
1 2 3 4 5 6 |
CREATE TABLE Orders ( order_id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY PRIMARY KEY, order_date DATE NOT NULL, … ) PARTITION BY RANGE(order_date); |
The statement will fail, with the following error:
SQL Error [0A000]: ERROR: unique constraint on partitioned table must include all partitioning columns
Detail: PRIMARY KEY constraint on table "orders" lacks column "order_date" which is part of the partition key.
This is because the primary key clause creates a unique constraint (enforced by creating a unique index,) and this cannot span the partitioned tables.
There are workarounds for this but they are not completely straightforward and do require some care and management. The easiest is simply to remove the unique constraint and enforce uniqueness elsewhere. For example, our orders table could be defined as:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE Orders ( order_id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY --No PRIMARY KEY HERE order_date DATE NOT NULL, … ) PARTITION BY RANGE(order_date); --for performance, but not uniqueness CREATE INDEX ON Orders USING BTREE(order_id); |
With the (non-unique) index on order_id, you can still use the column like a primary key. To enforce uniqueness, use an update trigger (or an update/insert trigger if you’re not auto-generating key values.)
A more radical solution is to define partitions by the key itself. In this case, we’re no longer barred from unique constraints on the key. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE Orders ( order_id BIGINT NOT NULL GENERATED ALWAYS AS IDENTITY PRIMARY KEY, order_date DATE NOT NULL, … ) PARTITION BY RANGE(order_id); CREATE TABLE Orders_1_50K PARTITION OF Orders FOR VALUES FROM (1) to (50000); CREATE TABLE Orders_1_50K PARTITION OF Orders FOR VALUES FROM (50001) to (100000); |
Each partition now holds a fixed number of rows, rather than a specific date range. This example defines partitions with 50,000 rows, but can be any number. This solution might not meet your business requirements: partitions now longer line up with specific months. But the advantage is that each partition is now a fixed size, which can be a big plus. For instance, you can set a partition size to match the backup media. If the table contains variable-length columns, the size in bytes won’t be perfectly equal. But for a large number of rows, the law of averages comes into play and the variance will be small.
Finally, there’s always the possibility you don’t need to enforce uniqueness at all. For instance, tables designed to be immutable (holding data that business rules forbid editing once inserted) often don’t need a unique key constraint.
Conclusion
Partitioning comes with big pluses — and some minuses. Its proper use can make administration much easier, and the database more performant. Learn when the feature makes sense and add it to your arsenal.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments