
Jonathan Lewis' continuing series on the Oracle optimizer and how it transforms queries into execution plans:
- Transformations by the Oracle Optimizer
- The effects of NULL with NOT IN on Oracle transformations
- Oracle subquery caching and subquery pushing
- Oracle optimizer removing or coalescing subqueries
- Oracle optimizer Or Expansion Transformations
There are two versions of this transformation, the “legacy” Or-Expansion – formerly known as “Concatenation” – and the new (12.2) implementation that allows Oracle greater scope and flexibility in its use. The basic mechanism is essentially the same in both versions though the shape of the execution plan does change. The key feature is that the optimizer can take a single query block and transform it into a UNION ALL of 2 or more query blocks which can then be optimized and run separately.
Here’s some code to create a table that I will use to demonstrate the principle:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
create table t1 as with generator as ( select rownum id from dual connect by level <= 1e4 -- > comment to avoid -- Wordpress format issue ) select cast(rownum as number(8,0)) id, cast(mod(rownum,1949) as number(8,0)) n1949, cast(mod(rownum,1951) as number(8,0)) n1951, cast(lpad(rownum,10,'0') as varchar2(10)) v1, cast(lpad('x',100,'x') as varchar2(100)) padding from generator order by dbms_random.value ; create index t1_i1949 on t1(n1949); create index t1_i1951 on t1(n1951); |
The table t1 holds 10,000 rows. In case you’re wondering, 1949 and 1951 are prime numbers and since they are both slightly less than 2,000 most values in the two columns will appear 5 times each, but a few will appear six times. It’s worth doing a couple of quick queries to get a better intuitive feel for the data:
|
1 2 3 4 5 |
select v1, n1949, n1951 from t1 where n1949 = 3; select v1, n1949, n1951 from t1 where n1951 = 3; select v1, n1949, n1951 from t1 where n1949 = 3 or n1951 = 3; |
And here are the three sets of results from my test (in the absence of an “order by” clause your results may appear in a different order):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
V1 N1949 N1951 ---------- ---------- ---------- 0000007799 3 1946 0000009748 3 1944 0000001952 3 1 0000005850 3 1948 0000000003 3 3 0000003901 3 1950 6 rows selected. V1 N1949 N1951 ---------- ---------- ---------- 0000009758 13 3 0000005856 9 3 0000001954 5 3 0000007807 11 3 0000003905 7 3 0000000003 3 3 6 rows selected. V1 N1949 N1951 ---------- ---------- ---------- 0000009758 13 3 0000005856 9 3 0000007799 3 1946 0000001954 5 3 0000007807 11 3 0000003905 7 3 0000009748 3 1944 0000001952 3 1 0000005850 3 1948 0000000003 3 3 0000003901 3 1950 11 rows selected. |
You’ll notice, of course, that the two simple queries returned 6 rows, but the disjunct (“OR”) of the two separate predicates returned only 11 rows. A little visual inspection shows that the row where v1 = '0000000003' appears in both of the first two result sets when it’s only going to appear once in the final query.
This example is so simple that the final plan doesn’t show OR expansion it has used a completely different option to access the data using a method that the optimizer thinks is cheaper (partly because of a limitation – not a bug – in the optimizer’s model). Here’s the plan (pulled from memory after checking the SQL_ID of the query):
|
1 |
select * from table(dbms_xplan.display_cursor('7ykzsaf3r0umb',null)); |
This returns:

The optimizer has decided to use btree/bitmap conversion. The plan does an index range scan of the two indexes, one for each predicate, then converts the two lists of rowids into two bit-strings, does a Bitmap-OR of the two strings then converts the resulting string back into a list of rowids. It’s an unfortunate feature of execution plans that bitmap strategies don’t include estimates of how many bits are “set” (i.e. 1) and how many rowids will be produced before showing the final estimate of rows returned after the table has been accessed by rowid and filtered.
Side note: Since the optimizer has no idea how the pattern of bits in a bitmap is related to the scattering of data (and the clustering_factor of a bitmap index is simply a count of the number of bitmap chunks in that index) the optimizer simply makes a guess about the data scatter. Roughly speaking it assumes that 80% of the rows identified through a bitmap predicate will be very well clustered, and that the remaining 20% will be widely scattered. Inevitably the resulting cost estimate of using the bitmap approach will be far too high in some cases and far too low in others.
Or-Expansion plans
Since the example allows the optimizer to use btree/bitmap conversion, the query will need a hint to disable that choice. Unfortunately, there’s no explicit hint to switch the mechanism off (you can force it to appear with the /*+ index_combine(alias) */ hint but there’s no “no_index_combine()” hint), so it’s necessary to fall back on the opt_param() hint to modify one of the optimizer parameters for the duration of the query.
Since I’m running 19.11.0.0 I’m going to run two more versions of the sample query – the first simply disables the btree/bitmap feature, the second also takes the optimizer back to the 12.1.0.2 optimizer feature level:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
select /*+ opt_param('_b_tree_bitmap_plans','false') */ v1, n1949, n1951 from t1 where n1949 = 3 or n1951 = 3; select /*+ opt_param('_b_tree_bitmap_plans','false') optimizer_features_enable('12.1.0.2') */ v1, n1949, n1951 from t1 where n1949 = 3 or n1951 = 3; |
Here are the resulting plans – first the baseline 19.11.0.0 plan showing the newer Or-Expansion:

And here’s the 12.1.0.2 plan showing “Legacy” Or-Expansion (i.e. Concatenation):
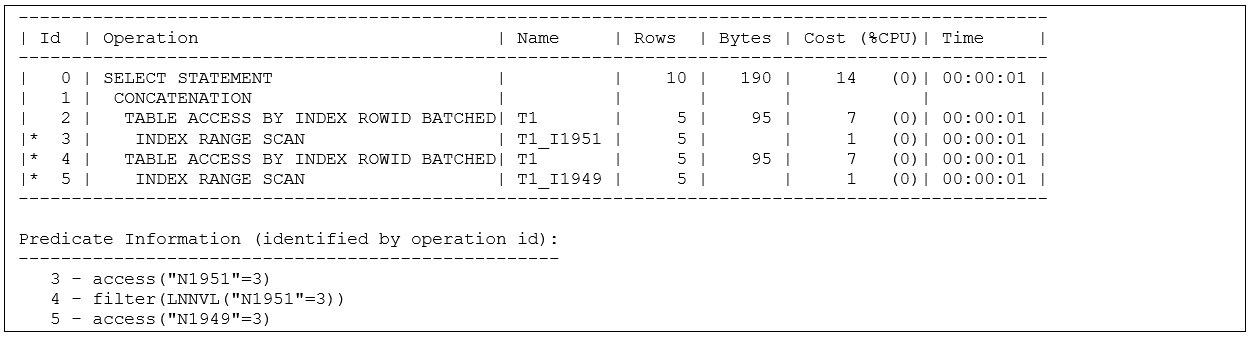
The plans are clearly similar – both show two index range scans and the access predicate associated with each range scan uses the obvious index.
Both plans report an unusual filter predicate of the form lnnvl(column = constant) – and if you check the plan body and Predicate Information you’ll notice that this lnnvl() predicate is used during access to the second child of the Concatenation/Union All, but the “predicate within a predicate” echoes the predicate used during access to the first child of the plan. This is Oracle making sure that rows that were reported in the first part of the Concatenation/Union All do not get repeated by the second part.
The lnnvl() function takes a predicate as its single parameter, returning FALSE if the input predicate evaluates to TRUE, and TRUE if the predicate evaluates to FALSE or NULL. Effectively it is the “is not true()” function, engineered to work around some of the difficulties caused by SQL’s “three-value logic”.
There are several cosmetic differences between the plans – the view VW_ORE_xxxxxxxx makes it very clear that the plan includes Or-Expansion, and there’s an explicit UNION ALL operation that shows very clearly how Oracle is operating. One curious difference is the reversal of the order in which the original predicates become the separate branches of the transformed query – there doesn’t appear to be any clever arithmetic involved, it just seems to be a switch from bottom-up to top-down.
As a side note – this does mean that when you upgrade from a “Concatenation version” of Oracle” to Or-Expansion a query that you’ve written to “select first N rows” without including an “order by” clause may now return a different set of rows.
In effect, Or-Expansion has taken the original text and transformed it into a select from a UNION ALL view (text extracted from the CBO trace file and edited for readability – “test_user” was the name of the schema running the demo):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT VW_ORE_BA8ECEFB.ITEM_1 V1, VW_ORE_BA8ECEFB.ITEM_2 N1949, VW_ORE_BA8ECEFB.ITEM_3 N1951 FROM ( ( SELECT T1.V1 ITEM_1, T1.N1949 ITEM_2, T1.N1951 ITEM_3 FROM TEST_USER.T1 T1 WHERE T1.N1949=3 ) UNION ALL ( SELECT T1.V1 ITEM_1, T1.N1949 ITEM_2, T1.N1951 ITEM_3 FROM TEST_USER.T1 T1 WHERE T1.N1951=3 AND LNNVL(T1.N1949=3) ) ) VW_ORE_BA8ECEFB ; |
In more complex queries, of course, once this transformation has been done the optimizer may find ways other parts of the query can be transformed with the different query blocks embedded in this UNION ALL view. Again, this may cause some surprises when an upgrade takes you from Concatenation to Or-Expansion: plans may change because there are more cases where the optimizer can apply the basic expansion then carry on doing further transformations to individual branches of the UNION ALL.
Or-Expansion threats
A critical difference between Concatenation and Or-Expansion is that the OR’ed access predicates for the driving table must all be indexed before Concatenation can be used. The same restriction is not required for Or-Expansion and this means the optimizer will spend more time considering more execution plans while optimizing the query. Consider a query joining table tA and table tB with the following where clause:
|
1 2 3 4 5 6 7 8 |
SELECT {list of columns} FROM tA, tB WHERE (tA.indexed_column = 'Y' or tA.unindexed_column = 'N') AND tB.join_column = tA.join_column AND tB.another_indexed_column = 'X' ; |
This could be expanded to:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
WHERE tA.indexed_column = 'Y' AND tB.join_column = tA.join_column AND tB.another_indexed_column = 'X' ... UNION ALL ... WHERE tA.unindexed_column = 'N' AND tB.join_column = tA.join_column AND tB.another_indexed_column = 'X' AND lnnvl(tA.indexed_column = 'Y') |
This expansion would not be legal for Concatenation because (as indicated by the choice of column names) there is no indexed access path for the predicate tA.unindexed_column = ‘N’, but Or-Expansion would allow the transformation. At first sight that might seem like a silly choice – but now that the optimizer has two separate query blocks to examine, one of the options open to it is to produce a plan where the first query block uses an index into tA followed by a nested loop into tB while the second query block uses an index into tB followed by a nested loop into tA.
Generally we would expect the improved performance of the final plan to more than offset the extra time the optimizer spends investigating the extra execution plans but there are patterns where the optimizer tries too hard and things can go badly wrong; here’s an example from a few years ago that modelled a production performance problem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
drop table t1 purge; CREATE TABLE t1 AS WITH GENERATOR AS ( SELECT --+ materialize rownum id FROM dual CONNECT BY level <= 1e4 ) SELECT rownum id1, rownum id2, rownum id, lpad(rownum,10) v1, rpad('x',100) padding FROM generator v1, generator v2 WHERE rownum <= 1e5 -- > comment to avoid -- wordpress format issue ; CREATE INDEX t1_i1 ON t1(id1, id2); SELECT * FROM t1 WHERE ( id1 = 1001 AND id2 in (1,2)) OR ( id1 = 1002 AND id2 in (2,3)) ... OR ( id1 = 1249 AND id2 in (249,250)) OR ( id1 = 1250 AND id2 in (250,251)) ; |
I’ve removed 246 lines from the query but you can probably see the pattern from the remaining 4 predicates. I didn’t write this query by hand, of course, I wrote a query to generate it. If you want to see the entire script (with some variations) you can find it at https://jonathanlewis.wordpress.com/2013/05/13/parse-time/
Running version 19.11 on my sandbox this query took 21.2 seconds to parse (optimize) out of a total run time of 22.1 seconds. The session also demanded 453 MB of PGA (Program Global Area) memory while optimizing the query. The execution plan was a full tablescan – but the optimizer spent most of its time costing Or-Expansion before discarding that option and picking a simple tablescan path.
After a little trial and error I reduced the number of predicates to 206 at which point the plan switched from a full tablescan to using Or-Expansion (the cost was 618 for Or-Expansion and 619 for a hinted full tablescan, at 207 predicates the costs were 221 and 220 respectively). The counter-intuitive side effect of this change was to increase the optimization time to 27 seconds and the memory demand to 575MB. The reason for this was that having discovered that the initial OR-Expansion produced a lower cost than the tablescan the optimizer then evaluated a number of further transformations of the resulting UNION ALL view to see if it could produce an even lower cost.
Apart from the increase in the workload associated with the Or-Expansion another threat comes from an error in the estimate of CPU usage at actual run-time. Here are a few lines from the body of the execution plan with 206 predicates, and a few lines from the Predicate Information for just the last operation in the plan:
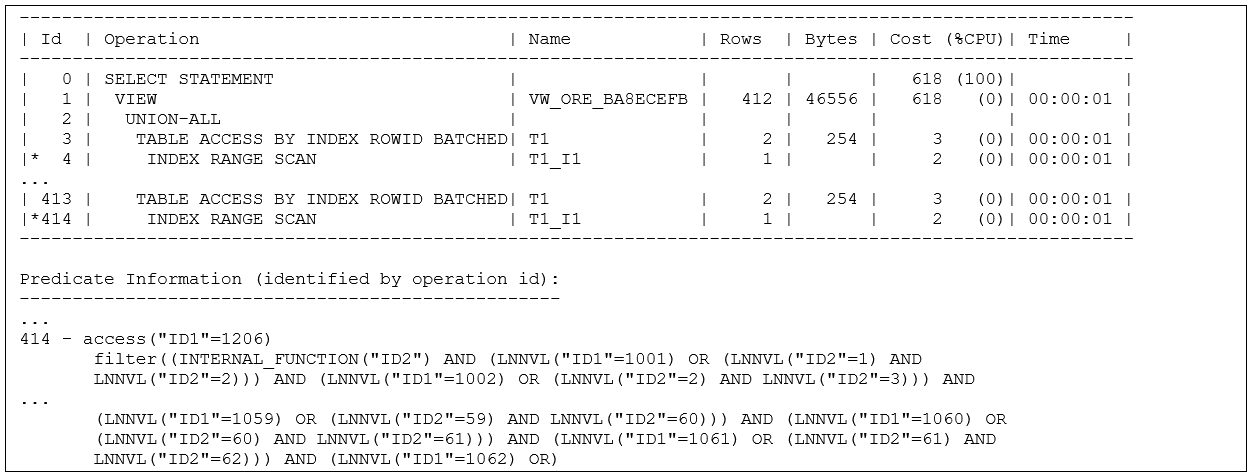
The plan includes 206 separate query blocks that do a basic index range scan with table access (I’ve shown just two of them) and as you work down the list the filter() predicate for each index range scan gets one more set of lnnvl() predicates than the previous one. In fact, by time the optimizer got to operation 128 – which is from the 63rd query block in the Union All – the number of bytes allowed in v$sql_plan for reporting the filter predicate was too few to hold the entire predicate and, as you can see at the end of the sample above, the filter predicate has stopped at references to the values 61 and 62, and is nowhere near the values 206 and 207 which would have appeared in the last line of the original SQL statement. There’s a lot of lnnvl() checking that has to go on as the number of branches in the expansion increases – and that’s going to be burning up CPU at run-time.
To block the transformation and cut down the optimization time, all that was needed was the addition of the hint /*+ no_or_expand(@sel$1) */ to the query (sel$1 because I hadn’t used the qb_name() hint to give the query a programmer-friendly name) and this reduced the parse time from 27 seconds to 0.4 seconds and the memory demand to 7 MB.
Side note: It’s worth pointing out that when you run a query the memory used for optimization is in your PGA, and the memory you’re using will reduce the “aggregate PGA auto target” which affects the limit for every other user. On the other hand if you call “explain plan” to generate an execution plan without executing the query the memory used comes from the SGA (i.e. the shared pool), which means that when the optimizer goes a little mad with Or-Expansion your session may flush lots of useful information from the library cache, with far greater impact on the entire system. This is just one more reason for not depending on “explain plan” to give you execution plans.
If you’re responsible for the performance of a system, there are some clues about the overheads of optimization in extreme cases. One point to check is the active session history (ASH – v$active_session_history or dba_hist_active_sess_history) where you could aggregate SQLexecutions to check for statements that record more than one sample in a hard parse, e.g:
|
1 2 3 4 5 6 7 8 9 10 11 |
break on sql_id skip 1 select sql_id, sql_exec_id, in_hard_parse, count(*) from v$active_session_history group by sql_id, sql_exec_id, in_hard_parse having count(*) > 1 order by 1,2,3 |
This returns
|
1 2 3 4 5 6 7 8 |
SQL_ID SQL_EXEC_ID I COUNT(*) ------------- ----------- - ---------- 1v1mm1224up26 Y 18 2kt6gcu4ns3kq N 2 Y 64 7zc0gjc4uamz6 Y 21 d47kdkn618bu4 16777216 Y 2 g1rvj7fumzxda 16777216 N 4 |
This isn’t a perfect search, unfortunately – if a statement is parsing, then it’s not yet executing so it doesn’t have an execution id (sql_exec_id), so when you see that sql_id“2kt6gcu4ns3kq” has recorded 64 samples “in hard parse” that might mean there have been lots of short hard parses (though that’s a little suspicious anyway) or a few long hard parses. You’d have to drill into sample times to get a better idea of what the larger numbers are telling you (64 consecutive sample times would be a fairly strong indication the statement was a threat).
Another thing you can check retrospectively is the alert log, as this may tell you about the memory aspect of extreme optimization problems. Here’s a short extract from my alert log following one of my nasty parse calls:
This isn’t saying anything about the hundreds of megabytes of PGA memory I’ve been using, it’s saying that someone pushed a “large object” into the SGA – but there’s a chance that an object that large is interesting and you’ll want to find out what it was, and the last few lines in the extract show that this one was an SQL statement that looks familiar. (The 51200K mentioned as the “notification threshold” is set by the hidden parameter _kgl_large_heap_warning_threshold.)

Summary
The Concatenation operation from earlier versions of Oracle has been superseded by the Or-Expansion operation, which is more flexible and can allow further transformations to be applied after the initial transformation in more ways than were available following the Concatenation operator. Or-Expansion is easily visible in execution plans, reporting a VIEW operation with a name like VW_ORE_xxxxxxxx followed by a UNION ALL operation.
On the plus side, some queries will be able to execute much more efficiently because the optimizer can find better plans for the different branches of the expansion; on the minus side the time spent in optimization can increase significantly and there will be cases where the cost of optimisation far outweighs the benefit of the faster execution. Although the CPU and elapsed time are the obvious costs of the optimization stage of Or-Expansion it is important to keep an eye on the demands for PGA that can also appear, so queries which have a large number of “OR’ed” predicates should be viewed with caution – and this includes queries with long “IN” lists, though the simplest type of IN-lists are likely to be transformed into “INLIST ITERATORS” rather than UNION ALL operations.
If you find cases where the optimizer persistently tries to use Or-Expansion when it’s a bad idea you can use the hint /*+ no_or_expand(@qbname) */ to block the expansion. The hint /*+ or_expand() */ is also available to force Or-Expansion (but it’s not a hint to use casually). If you aren’t allowed to block Or-Expansion through a hint or SQL patch then you could consider disabling the feature entirely by setting the hidden parameter _no_or_expansion to true at the system or session level.
Load comments