
Data about people and their activities is passed around for research purposes, and it is important to be able to mine information from this data, in a way that is appropriate and within the legal constraints of the custodianship of personal data. Many advances in medicine, for example, are made purely by finding patterns in existing patient and biomedical data. This research saves lives.
The big danger in making such data public, however, is that you can unintentionally reveal sensitive data about an individual, such as their medical condition, or how much they were charged for treatment. This is, of course, illegal.
It is possible to mine data for hidden gems of information by looking at significant patterns of data. Unfortunately, this sometimes means that published datasets can reveal sensitive data when the publisher didn’t intend it, or even when they tried to prevent it by suppressing any part of the data that could enable individuals to be identified
Using creative querying, linking tables in ways that weren’t originally envisaged, as well as using well-known and documented analytical techniques, it’s often possible to infer the values of ‘suppressed’ data from the values provided in other, non-suppressed data. One man’s data mining is another man’s data inference attack.
Pseudonymized and Anonymized data
The problems of accidentally revealing the personal information of individuals has been well known for a time. To attempt to avoid this, one can use various data masking techniques to ‘pseudonymize’ the data.
However, pseudonymized data should not be confused with anonymized data. Pseudonymized data retains a level of detail in the replaced data that allows the data to be tracked back to its original state, whereas in anonymized data the level of detail is reduced by masking to the point where it becomes impossible to reverse the process.
Unfortunately, there is a common belief that by ‘pseudonymizing’ data, for example masking out any keys that can lead directly to a record being associated with an individual, you prevent individuals being identified. Absolutely not: naïve suppression doesn’t prevent privacy breaches. The more useful a record is for scientific or marketing research, the more vulnerable it is to inference attack.
While pseudonymized data is vital for research work, and will prevent the causal or accidental revelation of personal data, such data still requires strict access control. If you publish data, either accidentally or deliberately, that is only pseudonymized, and it is possible to identify individuals by inference, then you lead your company open to lawsuits and prosecution.
Any data to be made public, including data for use in database development, testing and training, ought to be fully and irreversibly anonymized, with the data retaining only the same distribution and ‘appearance’ as that of the real data.
The Inference Attack
For data to be valuable for scientific or marketing research, the relationship between the two variables you are assessing must be intact. If, for example you needed to detect whether people who lived near Chernobyl suffered from a higher incidence of cancer, it would be no good to you if the location data in the medical data had been entirely randomized. However, the more variables are left intact, the easier it is to infer the identity of the people whose data is being used.
It is highly unfortunate that some data that has been made public in the past has led to personal data being unintentionally revealed (see, for example, Identifying inference attacks against healthcare data repositories). Inference attacks are well known; the techniques are thoroughly documented, and include frequency analysis and sorting.
Frequency analysis
At their very simplest, inference attacks are derived from early mediaeval codebreaking, where codes were created by swapping around individual letters, or by substituting glyphs for the alphabetic characters (a Monoalphabetic Substitution Cipher). It is simple, once you have determined the relative frequency of the various letters in the language, to crack codes based on character substitution, or trigraph codes (see Frequency Analysis: Breaking the Code).
By the same logic, a pseudonymized database may have the County field disguised. Counties have a varying population, and if the population in the database conforms to a known population, those counties can be identified, and this tentative identification can be firmed up by looking at the distribution of town addresses within the county, or by other geographical quirks of individual counties. Every inference attack is slightly different because it depends on the data and relies on drilling down to a unique combination of characteristics.
Exploiting inference vulnerabilities
It is possible to pose several queries and correlate the results to obtain bounds. This can reveal details about individuals even when low-frequency aggregations are suppressed. There is a good account of the technique here.
Combination
The easiest way of revealing individual data is to combine two or more databases. Investigative journalists are adept at this. Once the individual is identified, an inference attack can then use the GPS location and movement data of a user, possibly with some auxiliary information, to deduce other personal data such as their home and place of work, interests and social network, and even home in on religion, health condition or business confidential data coming from the user’s employer.
As database people, we believe so strongly in the unique key that we forget that the more data that there is, the more likely we are to find a compound key that can uniquely identify an individual. The commonly used informal key of gender, ZIP code and date of birth can be very revealing, using just pseudonymized medical records and the voting list.
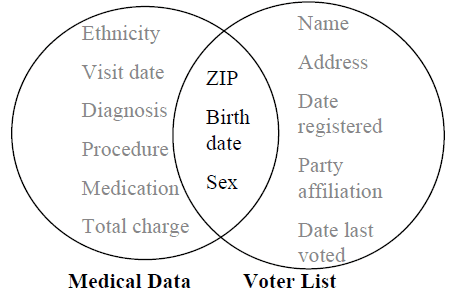
(source Sweeney 2001)
As an illustration of the technique, the HMO breach was possible because one can uniquely identify 63% of the U.S. population with knowledge only of the gender, ZIP code and date of birth of an individual. The HMO linkage attack combined two databases that shared these three attributes, the voter registration list for Cambridge Massachusetts and the Massachusetts Group Insurance Commission (GIC) medical encounter data.
The GIC sold their pseudonymized data, containing information for approximately 135,000 state employees, to industry because they believed the data was anonymous. By combining the two databases, individuals can still be identified. Ironically, a researcher, Latanya Sweeney, was able to identify the medical records of the governor of Massachusetts, William Weld.
In some cases, it is possible to identify individuals by cross-referencing data in the original data set with phonebook listings, as with the AOL Search Data Leak. In one case in the AOL leak, an AOL user was using search terms that suggested that he was contemplating murder or writing a crime novel.
The ‘Netflix Challenge’ data breach of 2006 was a development of an attack first used against MovieLens. It led to the famous ‘Jane Doe’ lawsuit that stated “To some, renting a movie such as Brokeback Mountain or even The Passion of the Christ can be a personal issue that they would not want published to the world.”
Netflix released a hundred million anonymized film ratings that included a unique subscriber ID, the movie title, year of release and the date on which the subscriber rated the movie. The database was cracked by two researchers, Narayanan and Shmatikov, who matched the ‘anonymized’ (‘perturbed’ by slightly randomizing the data) Netflix dataset with data crawled from the Internet Movie Database (IMDb). Even with a small sample of 50 IMDb users they were able to identify the records of two users. They were confident of success because of the dramatically higher matching score of the best candidate record than with any other record. Netflix never repeated that mistake.
Privacy models for advanced pseudonymization
Given that it is so easy to combine sets of data to gain information about individuals, there have been several attempts at providing a more robust pseudonymization process, which will remove the sensitive information or add randomness, to the point where it’s not possible to infer the values of original data with any degree of confidence.
These privacy models have been developed from k-anonymity and include l-diversity and t-closeness. The idea is that before a dataset ought to be anonymized to the point that it achieves the K-anonymity, l-diversity and t-closeness properties, before it is made public, or before further services are developed on it. More recently we have seen differential privacy, pan-privacy and empirical privacy.
Unfortunately, it has proved extraordinarily difficult to design a method that provides strong privacy guarantees while maintaining a high level of value to research. The AOL release and the Netflix challenge, discussed previously, showed that privacy can be compromised even where the data was pseudonymized and partially randomized. In 2008, Ganta, Kasiviswanathan and Smith showed how a type of intersection attack, called a composition attack, could identify individuals using only versions of the same pseudonymized database.
So far, all methods of pseudonymization have proved vulnerable to inference attack and nothing has provided a process that is generally appropriate. The difficulty is that every type of data comes with its own specific problems. Some types of data are especially difficult to pseudonymize convincingly, such as a genomic dataset, or location data that traces movements, or a social networking graph. Even data such as typical complaints or product reviews are tricky to pseudonymize effectively, while retaining data that seems authentic. However, it is important to be able to get this right, not only for staff training, but also for evaluating the risks and for assessing potential solutions to vulnerabilities to inference attack.
Conclusions
Intuitive pseudonymization methods to assure privacy are almost certain to fail. Successful pseudonymization requires a deep knowledge of the data. You also need to be able to design and formalize realistic adversary models, by getting into the head of the attackers, understanding their skills at inference and assessing what other background knowledge they might have acquired to help them re-identify individuals in your released data.
Even then, can you really be sure that your pseudonymized data is entirely proof from inference attack? Unfortunately, no; it is impossible to guarantee a method of pseudonymization because there will always be an item of auxiliary information that, combined with access to the database, will violate the privacy of an individual. Databases are designed to make links and discover new information, and it is hard to stop it happening.
All of this means that while pseudonymization is a necessary technique in preventing the casual revelation of sensitive data, for example during database training or during research, pseudononymised data still has to be handled in the same secure regime as the original data.
References
- Latanya Arvette Sweeney. Computational Disclosure Control- A Primer on Data Privacy Protection. PhD thesis. Massachusetts Institute of Technology, 2001.
- Privacy in Databases by Mathy Vanhoef (2012) [PDF]
- Arvind Narayanan and Vitaly Shmatikov. Robust de-anonymization of large sparse datasets. In Proceedings of the 2008 IEEE Symposium on Security and Privacy, pages 111- 125. IEEE Computer Society. 2008.
- Srivatsava Ranjit Ganta, Shiva Kasiviswanathan, and Adam Smith. Composition attacks and auxiliary information in data privacy. In Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 265 273. ACM Press, 2008.
- Only You, Your Doctor, and Many Others May Know by Latanya Sweeney
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments