
This article is part of Aisha Bukar's 6 part series: A Beginners Guide to MySQL Replication. The entries include:
Welcome back to the world of MySQL Replication! If you’ve been following this series, thank you for your support! And if you’re new here, welcome! Before we dive in, I suggest checking out the first part of the series to get up to speed.
In this article, I’ll be delving into multi-source replication and explaining in a way that’s easy to understand. We’ll look at how to set up the MySQL replication process, how to stop and reset it if needed, and the advantages of using this technique. So, let’s get to the exciting part, shall we?
WHAT IS MULTI-SOURCE REPLICATION?
MySQL’s multi-source replication allows a replica server to receive data from multiple source servers. Let’s say you have a replica server at your workplace, and there are multiple source servers in different locations, you need a way to directly receive data from these source servers to your replica server. This is where the multi-source replication technique comes into play. It allows you to efficiently gather data from various sources and consolidate it on your replica server.
But, how does this work?
For a replica server to be able to receive data from multiple source servers, it creates multiple paths(channels) where each path is linked to an individual source server, this is how data is transferred from multiple source servers to the replica server.
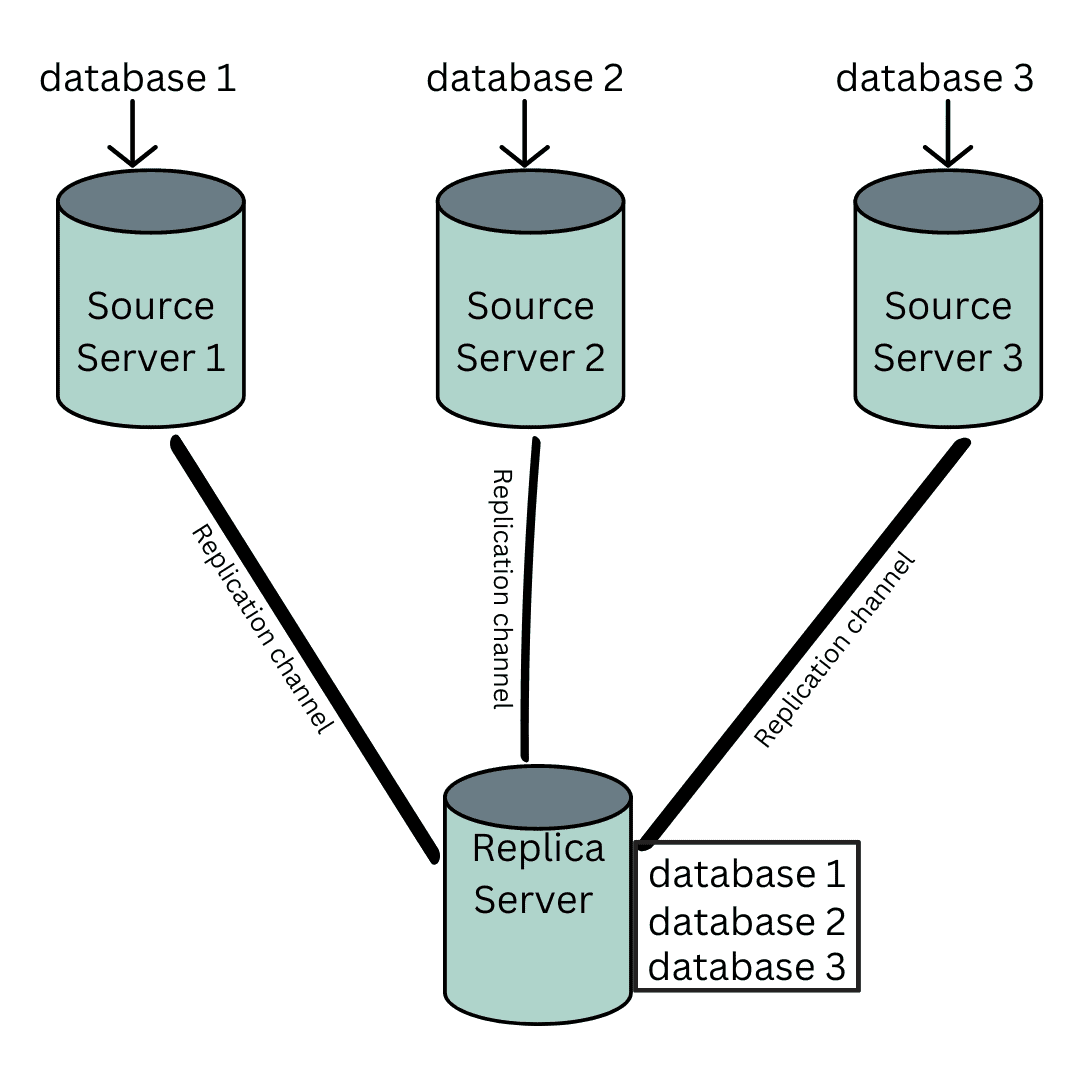
Each replication path also includes one or more SQL threads, relay logs, and an independent I/O thread that aids in performance and memory management. It is important to note that a maximum of 256 paths can be created by a replica server in a multi-source replication architecture, and that each replication path must have a unique name and cannot be null.
Some things to note..
MySQL’s multi-source replication is a great technique, however, here are some of the problems that may be considered when using multi-source replication:
1. MySQL’s multi-source replication does not carry out conflict resolution. It is the responsibility of the application or the user to implement conflict resolution logic when using multi-source replication. It does not provide built-in mechanisms to resolve conflicts that may arise when data from multiple sources is replicated to a single replica server.
2. MySQL’s multi-source replication does not support setting up multiple paths from a single source server to the replica server.
SETTING UP MULTI-SOURCE REPLICATION
To set up multi-source replication in MySQL, you are required to set any number of source servers of your choice starting with a minimum of two source servers. This involves specifying the necessary connection details, such as the hostnames or IP addresses, authentication credentials, and other replication options. If you had been following up with this series, you probably already know how to set up your source and replica servers by now, but if you don’t, then you can refer back to the previous part of this series. Here are the steps required:
1. Set up any number of source servers (minimum of 2): For this article, we would be setting up 3 source servers and a replica. The replica server replicates one database from each source, that is:
- Database1 from source server 1
- Database2 from source server 2
- Database3 from source server 3
- Replica server
2. Configure your source servers to use the binary log position-based replication: You can also use the GTID-based replication, but since we started this article with using the binary log based replication, we would stick with that.
Remember that, to set up the source servers using binary log file position, it is important to make sure that the binary logging is enabled and a unique non-zero server_id is set up for each source server. This is so that we can identify each source server in the replication topology. MySQL uses a default server ID of 1, but we can change this using the following command:
|
1 |
SET GLOBAL server_id =30; |
3. Create a user account for all the source servers: A user account is required for all the source servers to ensure that the replica server is able to connect to each source. There are two ways to do this, you can use the same account on all source servers OR you can create different accounts for each source server.
If an account is created solely for replication purposes, then the account needs only the REPLICATION SLAVE privilege. This can be done using the following query:
|
1 2 3 |
CREATE USER ‘aisha@replicahost’ IDENTIFIED BY ‘password’; GRANT REPLICATION SLAVE ON *.* TO ‘aisha@replicahost’; |
4. Configure a replication path for each source server: To configure a replication path(channel) for each source server in MySQL, we first need to ensure that the replica server and multi-source server are properly set up. This will allow us to identify the specific source servers from which we intend to replicate data. However, the configuration process involves setting up several essential parameters:
SOURCE_HOST: This parameter specifies the hostname or IP address of the source server that you want to configure as the replication source. In this case, it is set to “source_server1”.
SOURCE_USER: This parameter specifies the username of the replication user account on the source server. It should be a user account with the necessary replication privileges.
SOURCE_PASSWORD: This parameter specifies the password for the replication user account on the source server. It is the password associated with the user.
SOURCE_LOG_FILE: This parameter specifies the name of the binary log file on the source server from where replication should start. It identifies the position in the source server’s binary log where the replication process will begin.
SOURCE_LOG_POS: This parameter specifies the position within the binary log file (SOURCE_LOG_FILE) where the replication process should start.
FOR CHANNEL: This parameter specifies the name of the replication channel for which the source server configuration is being changed. It helps identify and differentiate multiple replication channels.
The following command is applicable for MySQL version 8.0.23 or greater
|
1 2 3 4 5 6 |
--Replication path for source server 1 CHANGE REPLICATION SOURCE TO SOURCE_HOST=”source_server1”, SOURCE_USER=”aisha”, SOURCE_PASSWORD=”password”, SOURCE_LOG_FILE=”source_server1-bin.000005”, SOURCE_LOG_POS=30 FOR CHANNEL “source_server1”; |
|
1 2 3 4 5 6 |
--Replication path for source server 2 CHANGE REPLICATION SOURCE TO SOURCE_HOST=”source_server2”, SOURCE_USER=”aisha”,SOURCE_PASSWORD=”password”, SOURCE_LOG_FILE=”source_server2-bin.000006”, SOURCE_LOG_POS=130 FOR CHANNEL “source_server2”; |
|
1 2 3 4 5 6 |
--Replication path for source server 3 CHANGE REPLICATION SOURCE TO SOURCE_HOST=”source_server3”, SOURCE_USER=”aisha”, SOURCE_PASSWORD=”password”, SOURCE_LOG_FILE=”source_server3-bin.000007”, SOURCE_LOG_POS=60 FOR CHANNEL “source_server3”; |
For MySQL version 8.0.23 or less, the following command is applicable:
|
1 2 3 4 5 6 |
--Replication path for source server 1 CHANGE MASTER TO MASTER_HOST=”source_server1”, MASTER_USER=”aisha”, MASTER_PASSWORD=”password”, MASTER_LOG_FILE=”source_server1-bin.000005”, MASTER_LOG_POS=130 FOR CHANNEL “source_server1”; |
|
1 2 3 4 5 6 |
--Replication path for source server 2 CHANGE MASTER TO MASTER_HOST=”source_server2”, MASTER_USER=”aisha”, MASTER_PASSWORD=”password”, MASTER_LOG_FILE=”source_server2-bin.000006”, MASTER_LOG_POS=220 FOR CHANNEL “source_server2”; |
|
1 2 3 4 5 6 |
--Replication path for source server 3 CHANGE MASTER TO MASTER_HOST=”source_server3”, MASTER_USER=”aisha”, MASTER_PASSWORD=”password”, MASTER_LOG_FILE=”source_server3-bin.000007”, MASTER_LOG_POS=30 FOR CHANNEL “source_server3”; |
5. Replicate the database: The next step would be to make the replica server replicate the database of our choice, that is, database1, database2, and database3. This can be achieved using the CHANGE REPLICATION FILTER statement. The CHANGE REPLICATION FILTER statement applies a replication filtering rule to the replica server.
|
1 2 3 4 5 6 7 8 9 10 |
--To replicate the database of our choice CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE=(‘database1.%’) FOR CHANNEL “source_server1”; CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE=(‘database2.%’) FOR CHANNEL “source_server2”; CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE=(‘database3.%’) FOR CHANNEL “source_server3”; |
INITIATING THE MULTI-SOURCE REPLICATION PROCESS
Once the configuration has been set up, we would need to start our multi-source replica servers in order to get it to work. Initiating the multi-source replication process involves setting up and configuring the necessary components to enable the replica server to receive data from multiple source servers.
To begin, you’ll need to identify the source servers from which you want to replicate data. These source servers can be located in different locations or environments. You can choose to start all the paths(channels) by using the following command:
|
1 2 3 |
--To start paths/channels for MySQL version 8.0.23 or less START SLAVE; |
|
1 2 3 |
--To reset all paths/channels for MySQL version 8.0.23 or greater START REPLICA; |
You can also select specific paths to start by using the following command:
|
1 2 3 4 5 6 7 |
--To start a specific path/channel for MySQL version 8.0.23 or less START SLAVE FOR CHANNEL “source_server1”; START SLAVE FOR CHANNEL “source_server2”; START SLAVE FOR CHANNEL “source_server3”; |
|
1 2 3 4 5 6 7 |
--To start a specific path/channel for MySQL version 8.0.23 or greater START REPLICA FOR CHANNEL “source_server1”; START REPLICA FOR CHANNEL “source_server2”; START REPLICA FOR CHANNEL “source_server3”; |
To verify that the channels have started, we can use the SHOW SLAVE/REPLICA STATUS command:
|
1 2 3 4 5 6 7 |
--To start a specific path/channel for MySQL version 8.0.23 or less SHOW SLAVE STATUS FOR CHANNEL “source_server1”; SHOW SLAVE STATUS FOR CHANNEL “source_server2”; SHOW SLAVE STATUS FOR CHANNEL “source_server3”; |
|
1 2 3 4 5 6 7 |
--To start a specific path/channel for MySQL version 8.0.23 or greater SHOW REPLICA STATUS FOR CHANNEL “source_server1”; SHOW REPLICA STATUS FOR CHANNEL “source_server2”; SHOW REPLICA STATUS FOR CHANNEL “source_server3”; |
STOPPING THE MULTI-SOURCE REPLICATION PROCESS
When you decide to stop or halt the multi-source replication process, it means you want to temporarily or permanently suspend the replication of data from the source servers to the replica server. To stop the multi-source replica servers, we can use the STOP REPLICA/SLAVE statement. This statement allows us to stop all channels.
|
1 2 3 |
--To stop all paths/channels for MySQL version 8.0.23 or less STOP SLAVE; |
|
1 2 3 |
--To stop all paths/channels for MySQL version 8.0.23 or greater STOP REPLICA; |
If you wish to only stop a specific channel, the FOR CHANNEL statement is used:
|
1 2 3 4 5 6 7 |
--To stop a specific path/channel for MySQL version 8.0.23 or greater STOP REPLICA FOR CHANNEL “source_server1”; STOP REPLICA FOR CHANNEL “source_server2”; STOP REPLICA FOR CHANNEL “source_server3”; |
|
1 2 3 4 5 6 7 |
--To stop a specific path/channel for MySQL version 8.0.23 or less STOP SLAVE FOR CHANNEL “source_server1”; STOP SLAVE FOR CHANNEL “source_server2”; STOP SLAVE FOR CHANNEL “source_server3”; |
RESETTING THE MULTI-SOURCE REPLICATION PROCESS
Resetting the multi-source replication process involves restoring the replication setup to a known state, typically after encountering issues or when you need to start the replication process from scratch. To reset the multi-source replica servers, the RESET SLAVE/REPLICA statement is used. This allows us to reset all the channels.
|
1 2 3 |
--To reset all paths/channels for MySQL version 8.0.23 or less RESET SLAVE; |
|
1 2 3 |
--To reset all paths/channels for MySQL version 8.0.23 or greater RESET REPLICA; |
If your intention is only to reset a specific channel, the FOR CHANNEL statement is used:
|
1 2 3 4 5 6 7 |
--To reset a specific path/channel for MySQL version 8.0.23 or less RESET SLAVE FOR CHANNEL “source_server1”; RESET SLAVE FOR CHANNEL “source_server2”; RESET SLAVE FOR CHANNEL “source_server3”; |
|
1 2 3 4 5 6 7 |
--To reset a specific path/channel for MySQL version 8.0.23 or greater RESET REPLICA FOR CHANNEL “source_server1”; RESET REPLICA FOR CHANNEL “source_server2”; RESET REPLICA FOR CHANNEL “source_server3”; |
The RESET REPLICA statement only allows the replica clear its relay log, and forget its replication position but does not change any replication parameters. If you wish to clear all the replication parameters, use the following command:
|
1 2 3 4 |
--To reset all replication parameters -- for MySQL version 8.0.23 or greater RESET REPLICA ALL; |
|
1 2 3 |
--To reset all replication parameters for MySQL version 8.0.23 or less RESET SLAVE ALL; |
BENEFITS OF MULTI-SOURCE REPLICATION
MySQL’s multi-source replication is useful for many applications, such as:
- Real-time updates from multiple databases can be seamlessly received by the replica server.
- Data can be efficiently transmitted to the replica server through multiple routes.
- It is well-suited for data warehousing purposes, facilitating the consolidation of data from various sources.
- Processing power is optimally utilized, resulting in improved efficiency.
- Multiple data sources can be replicated without the need for automatic conflict resolution, allowing for flexibility in handling conflicts at the application level.
- Database size is minimized, avoiding unnecessary duplication of data across multiple replica servers.
CONCLUSION
Multi-source replication means that a replica server can have more than one source server. This offers a powerful and flexible solution for efficiently consolidating data from multiple sources onto a single replica server. By enabling real-time updates, allowing data transmission through multiple paths, and facilitating data warehousing, it optimizes processing power and reduces database bloat. While it requires application-level conflict resolution, the benefits of multi-source replication make it a valuable tool for achieving centralized data management and synchronization. With multi-source replication, MySQL empowers organizations to effectively handle diverse data sources and enhance their overall data replication strategy.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments