Database Monitoring for Developers
Database monitoring is an essential part of database development and testing because it will reveal problems early and allow you to drill down to the root cause, as well as look for any worrying trends in behavior of the database, when under load. If you are delaying doing this until a database is in production, you're doing it wrong.
Nobody would ever argue that production databases shouldn’t be monitored, because you always need to test your assumptions about the usage of a database. However, if you are constantly checking your monitoring system to work out ‘what went wrong’ then this is a symptom of a missing step in the database development process.
During development you need to test how the database behaves and performs, both for a ‘normal’ workload and when under stress, and use monitoring to identify any serious flaws, bottlenecks, or inefficiencies in the operation of the database and the business processes it supports.
You might shrug, and say that until production, it is impossible to know precisely what pattern of usage to expect, and to optimize for. However, if you neglect scalability and stress testing of your database during development, in a rush to deliver new functionality, you are forcing the production environment to bear the consequences of your risk-taking and leaving your users to provide your testbed and to be your testers. That may be fine for social media, but not for a system supporting a commercial enterprise.
Monitoring production database systems
Production databases should be able to operate happily without being cosseted, as long as they can let you know when things are not to their liking. I once left an extremely elaborate SQL Server database to its own devices for six years, gathering every significant news story from around the world, alone in a deserted server room, reporting news summaries to an internet site. It was still working without stress or incident when we reluctantly switched it off.
This shouldn’t come as a surprise. Databases underpin a large number of embedded systems. Even my Wi-Fi network has a database of sorts (MongoDB). Your browser uses relational databases. They get along somehow without being monitored, but if not, they log sufficiently to indicate stress or the need for extra resources, or if necessary to explain how and why they failed. This makes sense in a typical network that can have thousands of devices on it, even if there will be few as complex as a relational database that is running commercial processes.
From the operational viewpoint, a production system, whatever service it provides, is just another box that should let you know, with a simple message, if it needs attention. These simple messages aren’t just about crises but can be gentle reminders that space is getting a bit low, or the ink is running out. If a network-level system is in place, such as replication or failover, it is likewise checked by an independent alerting system. If it is impossible to fix the issue with a simple intervention, and a check of the logs, then the alert gets escalated to the next support level. If the problem cannot be fixed with standard diagnostics, then you go to the third support level, where an in-depth monitoring tool is used by a database expert. I’ve described this ‘layered’ approach to monitoring database systems in another article, Improving the Quality of your Database Monitoring.
Designing databases that can alert you to problems
A production database must be designed and built with resilience in mind, and to alert its minders when things aren’t right so that problems are avoided rather than solved.
Resilience comes from many design choices but primarily from the use of constraints. An experienced database developer will use database constraints even in places where common sense suggests that what you’re protecting against cannot possibly happen, because surprisingly, it usually does. In addition, the procedural code must be written defensively, check for faults and log when an anomaly such as a constraint violation happens. These errors need to be passed on if they signify that they require action.
This may sound like extra work, but it is, in my experience, harder and more time-consuming in the long run if you develop a database that can’t, metaphorically, say ‘Ouch!’. There is nothing like instant feedback to spur development. If you put straight-forward error-handling and reporting at the heart of the database system that you develop and test, most of the most obvious mistakes and design errors can be fixed in development when and where it is quicker and easier to do so. You are forced to design for resilience.
As well as resilience in the design, and in the way processes are written, a database must be able to report rapidly on the service so that we can identify an anomaly before it becomes a problem. It must be able to warn you promptly of any serious issues, of any serious disruption to the processes that it supports and of any ‘irregular’ activity. This could be warnings of excessively slow processing of shipping notices or orders, the corruption of data, or of anomalous data imports. The classic approach I’ve always used for this, which works well in SQL Server, as well Oracle or PostgreSQL, is to generate log entries in the regular logs, and use emails that report anything unusual that might signify a resource problem, a bug or an intrusion. This allows the database to record stress and to report pain of any sort, but not necessarily the reason for it. That is where a monitoring system comes in, which will reveal the cause of blocking or contention in the database.
This simple system for ‘raising a red flag’ when something goes awry can then be passed on to operations for “Level 1 alerting”, when the system is deployed. It is only at this point that someone will need to dive into the details, look at the logs and monitor the current system with a tool, such as Redgate Monitor, that gives you all the details that you need to fix the problem quickly. With Redgate Monitor, you can tap into the database’s own monitoring of the business processes with custom monitors to get a more complete picture of database behavior.
Monitoring databases in development: what’s required
It is during development that monitoring, including an external tool that can record baselines and allow drill-down to the details, is most important, in my view. It works best in combination with a database application that can detect application-level issues and give an alert from a secure messaging system of some sort.
When an alert is received, then the developers can work out what way to investigate the problem (Level 2) and if it requires a monitoring tool rather than -say- the incident response team, fire extinguisher, generator, or water pump, then we use Level 3 to determine the problem. To investigate a performance bottleneck in a database, or any other cause of declining performance, you need to have baselines. These will provide some idea of trends in CPU usage, memory usage, disk I/O, and network traffic. A monitoring system, like Redgate Monitor, will do this for you.
The development stage is exactly the right time to optimize or re-write slow-running queries, re-design inefficient processes, and if necessary, re-engineer the table entities and their relationships. In a production environment, you are often limited to just index changes and other such tweaks. For Continuous Integration and Continuous Deployment to work, you need to catch database-related issues as early as possible in the development cycle, so that the developers can attend to the weak points in the design, and so avoid introducing errors into production.
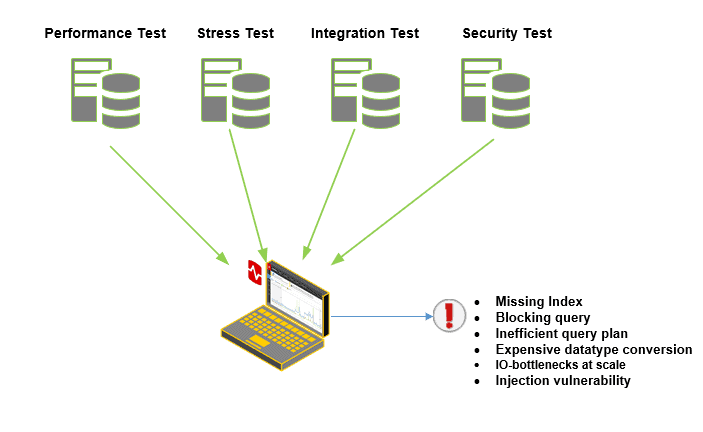
See Testing Databases: What’s Required? for more details of the sort tests we’ll perform in development, while monitoring the database response.
Performance monitoring
To sort out performance issues, you will need to monitor the execution times and frequencies for key queries. So often, performance is impacted by just a few slow-running queries that are frequently executed. These must be identified, because it pays to give these your attention: a slow-running query that doesn’t block other threads, and only runs once a day isn’t a problem worth attention.
The great advantage of attending to this in development is that you can bring to bear the whole gamut of forensics that a monitoring system provides in a controlled test harness, and you can log aspects of database performance without worrying about any potential performance hit. You can simulate extreme load without any guilt or inhibitions.
The usual time to identify potential performance bottlenecks and scalability issues is later in the process during load testing and stress testing because the stress-test harness can be tricky to set up. However, if such testing can be pulled back into development, then you’ll identify earlier on, when they are much easier to fix. Queries can be fine-tuned, indexing strategies changed, and resource allocation modified in the relative freedom of the development environment. You can even replay the stress to ensure that you’ve fixed the problem. It may upset the release schedule, but it prevents bad code or design reaching production. You can also use a monitoring system to get into detail about slow-running queries without worrying about any performance hit from the monitoring system, or about accidental exposure of production data.
Within a test harness, it becomes much easier to use a monitoring system to analyze query execution plans, query duration, and resource usage at the necessary depth. If testing is part of every development cycle, rather than being formalized into part of deployment, then the results can influence team priorities for the next cycle. This prevents potential performance issues from being carried forward to production, where the opportunities for change are very limited.
Monitoring how a database deals with increasing data
Scalability tests provide an excellent opportunity to investigate the growth of table and index sizes, log files, temporary files, and other database objects under increasing volumes of data. With the means to monitor and record how the database scales with increasing size of data, it is easier to pass on the data that is needed for capacity planning and, in particular, for planning the provision of disk space.
Monitoring a database under stress
By using a monitoring system for stress testing it is possible to see how and why a database fails to deal properly with high levels of usage. It is, obviously, much better to deal with any issues before release, and it allows you to set up, and rerun, conditions that you might need to wait years for in a production system.
Stress testing isn’t always popular because the test rig may be tricky or time-consuming to set up. It is difficult to give detailed advice about stress testing because so much depends on the way that a database interacts with its applications under stress conditions. One of the advantages of a formalized application-interface is that the patterns of usage in a production system can be recorded and used in an anonymized form, for a test harness that can simulate the application in development. The test harness that ‘mocks’ the application can simply work via the interface. If your applications have a self-service approach, grabbing data from the base tables, and inserting directly into them, then simulations can be more difficult, but possible by using a trace recorded (and anonymized) from production.
Checking how applications affect the database
The task of checking that processes give correct results is part of a test-driven approach to database development. Most of this work is done with unit and integration testing that will be performed well before a release candidate is ready for testing. At this stage, a monitoring tool in development and test environments is useful to quickly determine how and why a test failed.
In the test phase of the development cycle, you are likely to need to monitor the tests for the integration of the database with its upstream or downstream applications, such as reporting systems, and data feeds. By doing so, it is possible to help identify and resolve issues such as improper transaction handling, unnecessary database round trips, or inefficient data access patterns.
Most of the difficulties of this type of integration test are in setting up the development systems, or mocks, that simulate or reproduce the actual production applications. If connections are via ODBC, we can usually do it using scripts that mimic the behavior of the actual application.
Making vulnerability and penetration tests more visible
Whereas vulnerability and penetration tests can identify data privacy vulnerabilities and potential security gaps, before deploying to production, monitoring can quickly identify the results of actual weakness in the database design, such as excessive denormalization or poor use of dynamic SQL, and it can provide metrics to see how effective a modification can be. By doing so at this stage, before release, it is easier to implement and retest the appropriate security measures, ensuring that sensitive data is adequately protected.
Summary
There must be many database developers who gaze across at the production DBAs as they contentedly look at their graphical database monitoring system, viewing lists of slow-running queries, graphs of resource usage, locking and blocking, wait stats, query plans and the like and think to themselves, “hey that would be useful in development!“. They might still feel twinges of guilt at the memory of causing a release to fail, because of a careless error that could have been quickly spotted with the right tool.
By monitoring databases in both the development and test environments, you can often spot an issue, and fix it, before the release is deployed to production. The ‘fix’ might be to optimize performance, fix a security loophole, or maybe just tweak something that detracts from the overall quality of the database design
Yes, we database developers tend to reach for our collections of esoteric system functions and views but sometimes it pays to look at the broad landscape before you start peering under rocks.
Tools in this post
Redgate Monitor
Real-time multi-platform performance monitoring, with alerts and diagnostics
You may also like
-

Article
PostgreSQL Explain Plans in AWS Aurora
I recently wrote about a project I created on AWS Aurora PostgreSQL where I’m capturing APRS data from a radio. I focused on the ease of use, getting a database, some Lambda Functions, and a few schedulers working together with a web page. It was easy. However, I’d like to focus on a slightly different
-

Article
Monitoring the Application with Redgate Monitor: Website Activity
Using a PowerShell script that collects log data from a web server, plus a Redgate Monitor custom metric, Phil Factor offers a way to check for suspicious website errors and unusual patterns of activity, right alongside your database monitoring.
-
Article
Dynamic Alerting on Processor (CPU) utilization
This article explores dynamic alerting, what it means, why it matters for DBAs, and how it works in Redgate Monitor. Learn how machine learning-driven thresholds increase alert relevance, helping teams focus on real performance issues while saving DBAs time.
-

Webinar
Customer perspectives: Why Redgate Monitor is Unmatched
Hear directly from Chris Yates of Republic Bank on why they switched to Redgate Monitor, and what made it the clear choice over the competition. In this insightful discussion, our panelists shared: What prompted them to leave their previous monitoring solutions. The deciding factors that made Redgate Monitor their top choice. Tips on what
-
Article
Monitoring TempDB Contention using Extended Events and Redgate Monitor
When the tempdb database is heavily used, processes in any database on the instance will be forced to wait, due to contention as the SQL Server engine tries to manage allocation pages in tempdb. Phil Factor shows how to monitor for signs of trouble.





