
Introduction
As with any high-level language, the data is at the heart of PowerShell. In the case of PowerShell, this boils down to converting external data into PowerShell objects and vice versa. This is the second of a series of articles that shows you how to import almost all of the common data formats you are likely to encounter, and how to export to some of them as well. The first article in the series, PowerShell Data Basics: File-Based Data, covers a variety of text formats, from fixed-width, variable-width, and ragged-right files to CSV, property lists, INI files, and JSON data, and concludes with a treatment of importing and exporting to Excel. Here we concentrate on getting the most from XML.
Accessing XML data in PowerShell
There are two built-in techniques for working with XML data in PowerShell; the XPath approach and the object dot-notation approach. We’ll describe and compare these two approaches, and try them out on some sample XML. For convenience, all the code examples use this sample XML file from MSDN. Figure 1 shows a representation of the schema underlying the file in a concise format (particularly when compared to reading the raw XSD file!), courtesy of Visual Studio’s XML Schema Explorer. From the figure, you’ll notice that the XML file is a catalog that contains a collection of books. Each book has seven characteristics, six of which are child elements and one which is a child attribute.
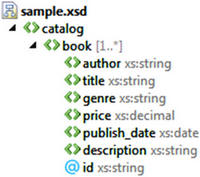
Figure 1 Schema for Microsoft’s sample XML fileo:p>
To load this sample XML file, you can use any of these:
|
$xdoc = new-object System.Xml.XmlDocument $file = resolve-path(“.\sample.xml”) $xdoc.load($file) |
|
[xml] $xdoc = get-content “.\sample.xml” |
|
$xdoc = [xml] (get-content “.\sample.xml”) |
if you would prefer to experiment with immediate XML data rather than load an XML file into an XmlDocument, it is simple to do. Merely define your XML as a string and cast it to XML type as we’ve just done with the Get-Content cmdlet for files. Here’s a portion of the sample XML file with only two books:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$mydoc = [xml] @" <catalog> <book id="bk101""> <author>Gambardella, Matthew</author> <title>XML Developer's Guide</title> <genre>Computer</genre> <price>44.95</price> <publish_date>2000-10-01</publish_date> <description>An in-depth look at creating applications with XML.</description> </book> <book id="bk102""> <author>Ralls, Kim</author> <title>Midnight Rain</title> <genre>Fantasy</genre> <price>5.95</price> <publish_date>2000-12-16</publish_date> <description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description> </book> </catalog>o:p> "@ |
Accessing XML with XPath
With the file loaded into an XmlDocument object, you can then navigate the XML tree with XPath. To select a set of nodes use the SelectNodes method:
|
$xdoc.SelectNodes(“//author”) |
|
#text —– Gambardella, Matthew Ralls, Kim Corets, Eva Corets, Eva Corets, Eva Randall, Cynthia Thurman, Paula Knorr, Stefan Kress, Peter O’Brien, Tim O’Brien, Tim Galos, Mike |
Or use SelectSingleNode to return just one node:
|
$xdoc.SelectSingleNode(“//book[2]”) |
|
id : bk102 author : Ralls, Kim title : Midnight Rain genre : Fantasy price : 5.95 publish_date : 2000-12-16 description : A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world. |
Notice in the first example that there are duplicates. Suppose instead that you want a list of unique authors in the catalog. You might think that something like …
|
1 |
$xdoc.SelectNodes("//author") | select -Unique |
…would work, but it actually returns just the first author’s name. To understand why that failed, you would need to understand more about the structure of XML documents. The first example actually returned a list of text nodes (i.e. not a list of text) and the unique filter is operating on that list, looking for element type uniqueness. Since all the items in the collection are text nodes, and so are all the same element type, all nodes beyond the first are therefore considered to be duplicates. The result is that only the first is returned.
What you are really after is the string value of each author node. From the author node you must first access its text node (its first and only child), then the value of that text node (line A in the next example). Alternately, you can use a slightly shorter expression with the InnerText property (line B). One more variation uses the Select-Xml cmdlet which avoids a method call and so is, in some sense, a more distinctively PowerShell approach (line C). All three lines return the same result.
|
(A) $xdoc.SelectNodes(“//author”) | % { $_.FirstChild.Value } | select -Unique (B) $xdoc.SelectNodes(“//author”) | % { $_.InnerText } | select -Unique (C) $xdoc | Select-Xml “//author” | % { $_.Node.InnerText } | select -Unique |
|
Gambardella, Matthew Ralls, Kim Corets, Eva Randall, Cynthia Thurman, Paula Knorr, Stefan Kress, Peter O’Brien, Tim Galos, Mike |
SelectNodes and SelectSingleNode together give you equivalent functionality to Select-Xml. Both support namespaces, which I have not mentioned yet. The two methods both take an XmlNamespaceManager as an optional second parameter, while the Select-Xml cmdlet takes an optional Namespace parameter that specifies your namespaces in a hash table.
SelectSingleNode returns an XmlNode and SelectNodes returns an XmlNodeList. Select-Xml, on the other hand, returns a SelectXmlInfo object (or an array of them) and its Node property provides access to the underlying node. The example just above illustrates these differences.
Accessing XML as Objects
With the same XmlDocument object from the last section, PowerShell also provides dynamic object support for XML data: This allows you to access XML data as first-class PowerShell objects, requiring neither XPath selector nor familiarity with the details of such things as XML nodes, values or text nodes. Furthermore, you get instant, dynamic Intellisense of your XML schema when you load your XML data! Figure 2 illustrates this for the PowerShell ISE, where you get both selection choices and word completion, just like with PowerShell native tokens. Notice particularly in the bottom expansion that it looks for what you have typed anywhere in the property name, not just starting from the first character: Intellisense would find you a date property here whether it is named published_date or releaseDate or date_of_publication. Note that you have word completion available in PowerShell V2 or V3, and in PowerShell ISE or PowerShell console. But selection choices are only available in PowerShell ISE in V3.
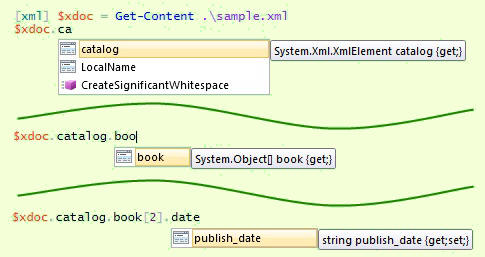
Figure 2 Automatic Intellisense upon loading an XML document
Here are some examples to show that the XML is indeed auto-converted to PowerShell objects:
|
$xdoc |
|
xml catalog — ——- version=”1.0″ catalog |
|
$xdoc.catalog |
|
book —- {book, book, book, book…} |
|
$xdoc.catalog.book | Format-Table -AutoSize |
|
id author title genre price publish_date description — —— —– —– —– ———— ———– bk101 Gambardella, Matthew XML Developer’s Guide Computer 44.95 2000-10-01 An in-depth look … bk102 Ralls, Kim Midnight Rain Fantasy 5.95 2000-12-16 A former architec… bk103 Corets, Eva Maeve Ascendant Fantasy 5.95 2000-11-17 After the collaps… bk104 Corets, Eva Oberon’s Legacy Fantasy 5.95 2001-03-10 In post-apocalyps… bk105 Corets, Eva The Sundered Grail Fantasy 5.95 2001-09-10 The two daughters… bk106 Randall, Cynthia Lover Birds Romance 4.95 2000-09-02 When Carla meets … bk107 Thurman, Paula Splish Splash Romance 4.95 2000-11-02 A deep sea diver … bk108 Knorr, Stefan Creepy Crawlies Horror 4.95 2000-12-06 An anthology of h… bk109 Kress, Peter Paradox Lost Science Fiction 6.95 2000-11-02 After an inadvert… bk110 O’Brien, Tim Microsoft .NET: The Prog… Computer 36.95 2000-12-09 Microsoft’s .NET … bk111 O’Brien, Tim MSXML3: A Comprehensive … Computer 36.95 2000-12-01 The Microsoft MSX… bk112 Galos, Mike Visual Studio 7: A Compr… Computer 49.95 2001-04-16 Microsoft Visual …
|
|
$xdoc.catalog.book[2] |
|
id : bk103 author : Corets, Eva title : Maeve Ascendant genre : Fantasy price : 5.95 publish_date : 2000-11-17 description : After the collapse of a nanotechnology society in England, the young survivors lay the foundation for a new society |
|
$xdoc.catalog.book[5].author |
|
Randall, Cynthia |
|
$xdoc.catalog.book[5].id |
|
bk106 |
Notice that all XML nodes in the document are converted to standard PowerShell properties, whether a node has children (e.g. catalog) or is a leaf node (e.g. price), or whether a leaf node is an element (e.g. author) or an attribute (e.g. id). In particular (as the last two examples above illustrate), element values and attribute values are treated exactly the same with standard “dot” notation.
Comparison of XPath and Object Approaches
Which approach is better to access XML data? Table 1 helps you answer this question. The object approach is usually more concise (e.g. line 3), but not always (line 4). XPath, however, is more expressive, in that it allows you to specify some selectors that are not possible with object notation (line 7). However, PowerShell’s own capabilities can easily fill this gap when using object notation (line 8).
|
# |
Select what… |
XPath |
Object |
|
1 |
Entire catalog |
$xdoc.SelectSingleNode(“/catalog”) — or — ($xdoc | Select-Xml “/catalog”).Node |
$xdoc.catalog |
|
2 |
Book collection |
$xdoc.SelectNodes(“//book”) — or — ($xdoc | Select-Xml “//book”) | % { $_.Node } |
$xdoc.catalog.book |
|
3 |
3rd book |
$xdoc.SelectNodes(“//book”).Item(2) — or — $xdoc.SelectSingleNode(“//book[3]”) |
$xdoc.catalog.book[2] |
|
4 |
Last book |
$xdoc.SelectSingleNode(“//book[last()]”) |
$xdoc.catalog.book[ $xdoc.catalog.book.Length-1] |
|
5 |
Author of |
$xdoc.SelectSingleNode(“//book[6]/author”) .InnerText — or — $xdoc.SelectSingleNode(“(//author)[6]”) .InnerText |
$xdoc.catalog.book[5].author |
|
6 |
Id of |
$xdoc.SelectSingleNode(“//book[6]/@id”).Value — or — $xdoc.SelectSingleNode(“//book[6]”) .GetAttribute(“id”) |
$xdoc.catalog.book[5].id — or — $xdoc.catalog.book[5].GetAttribute(“id”) |
|
7 |
Price of book following book written by Kress |
$xdoc.SelectSingleNode( “//book[contains(author, ‘Kress’)]/ following-sibling::book/price”) — or — $xdoc.SelectSingleNode( “//book[preceding-sibling::book[ contains(author, ‘Kress’)]]/price”) |
NA |
|
8 |
Books over $40 |
$xdoc.SelectNodes(“//book[price > 40]”) |
$xdoc.catalog.book | ? { [decimal]$_.price -gt 40 } |
|
9 |
Unique authors |
$xdoc | Select-Xml “//author” | % { $_.Node.InnerText } | select -Unique |
$xdoc.catalog.book | select -Unique |
Table 1 Comparing XPath and object selector approaches for XML access.
Modifying or Creating XML Data
Given an appreciation of XML selectors from the previous sections, modifying an XML document is quite straightforward because XML selectors (either XPath or object) are L-values, i.e. you can write to them as well as read from them! Thus either of these will modify the author of the 6th book:
|
1 2 |
$xdoc.SelectSingleNode("//book[6]/author").InnerText = 'jones' $xdoc.catalog.book[5].author = 'smith' |
Quite often, you might have an existing XML file where you want to change one or node values. You’d probably want to read the file, modify the data, and save the file back to the same name. You have seen the first two steps; the third step is done with the Save method on the XmlDocument. Putting these all together, then, yields this basic code:
|
1 2 3 4 |
[xml] $xdoc = get-content ".\sample-new.xml" $xdoc.catalog.book[5].author = 'audubon, j.' $xdoc.catalog.book[5].title = 'The Birds of America' $xdoc.Save(".\sample-new.xml") |
That code runs fine-except most of the time it will appear to have failed! This simple bit of code illustrates a seemingly minor but important PowerShell notion; ignorance of this has led to many blog posts claiming it is a bug in PowerShell. The problem is that your working directory and your PowerShell location are not the same thing. The above code reads the file just fine, it modifies the data just fine, but it does not necessarily save the new file where you expect it to. Get-Content, being a PowerShell cmdlet, sees a file path relative to the PowerShell location. The XmlDocument.Save method, on the other hand, sees a file path relative to the PowerShell process’ working directory because that method call is outside of PowerShell. If you have not executed Set-Location (or its alias cd) in your current PowerShell session, both point to the same directory. To confirm this, execute these two statements:
|
1 2 |
Get-Location # displays PowerShell location [Environment]::CurrentDirectory # displays working directory |
The safest approach, then, is to use absolute paths to avoid this issue altogether. See Alex Angelopoulos’ article Why the PowerShell Working Directory and the PowerShell Location Aren’t One in the Same for more.
Adding XML Data
Adding new nodes to your XML document takes just a bit more work than modifying the value of an existing node. One approach I like is from Tobias Weltner’s blog entry Write, Add and Change XML Data: take an existing node of the type that you wish to create, make a copy of that node and modify the copy with your new data, and finally insert the copied node into your XML as a sibling of the original. Applying that to our book catalog example, this bit of code creates a new book node and adds it to the end of the collection:
|
1 2 3 4 5 |
$book = $xdoc.catalog.book[0].Clone() $book.author = 'Dickens, Charles' $book.title = 'The Old Curiousity Shop' # etc. with remaining properties. . . [Void] $xdoc.catalog.AppendChild($book) |
If you wish to add the new book at a different location, say after the 3rd book, use InsertAfter instead of AppendChild:
|
1 |
[Void]$xdoc.catalog.InsertAfter($book,$xdoc.catalog.book[2]) |
(The name of the method InsertAfter belies the fact that it does not just add nodes; it can move nodes, too! The method checks to see whether the node you are asking to add is already in the document. If so, it moves it to the new location you specify. Thus, when you do want to copy nodes, you must start with the Clone method as illustrated above.)
For further exploration on manipulating XML data with .NET methods, see Process XML Data Using the DOM Model on MSDN.
Using XML for Object Serialization
PowerShell provides an easy way to persist objects by using Export-Clixml to serialize any object and store it in an XML file and Import-Clixml to restore the object from XML. With XML, unlike most other serialization techniques, object integrity is preserved: upon restoring an object from XML all properties are properly typed as is the parent object itself, so all methods on the original object are available on the regenerated object as well. To use Export-Clixml, simply pipe any object collection to it and specify a destination file. Here is a simple example showing that the output from Get-ChildItem, a collection of FileSystemInfo objects, is regenerated:
|
Get-ChildItem c:\usr\tmp | Export-Clixml c:\usr\tmp\files.xml $fileListing = Import-Clixml c:\usr\tmp\files.xml Write-Output $fileListing |
|
Mode LastWriteTime Length Name —- ————- —— —- d—- 10/2/2012 6:25 PM <DIR> fitnesse d—- 11/23/2010 8:15 AM <DIR> Sandcastle d—- 11/16/2011 10:07 PM <DIR> SvnSandbox -a— 10/7/2012 7:36 PM 152066 filelist.xml -a— 10/8/2012 3:27 PM 86772 files.xml -a— 10/8/2012 1:57 PM 4349 sample-new.xml -a— 10/6/2012 3:42 PM 4550 sample.xml
|
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments