
This article describes the syntax of SQL Server’s ALTER TABLE statement. It continues the theme of my previous article SQL Server CREATE TABLE syntax diagrams which provides an introduction to the use of syntax railroad-diagrams for SQL.
The ALTER TABLE statement has much in common with the CREATE TABLE syntax, especially the column_definition, column_constraint, computed_column_definition, and table_constraint definitions. We’ll include them here as well to prevent the need to flip to and fro between the two articles.
The full PDFs for the syntax diagrams are supplied so that they can be printed out to any size. The versions in the articles are just thumbnails, and can also be clicked on for better viewing.
- ALTER TABLE overview
- ALTER TABLE column
- ALTER TABLE miscellaneous
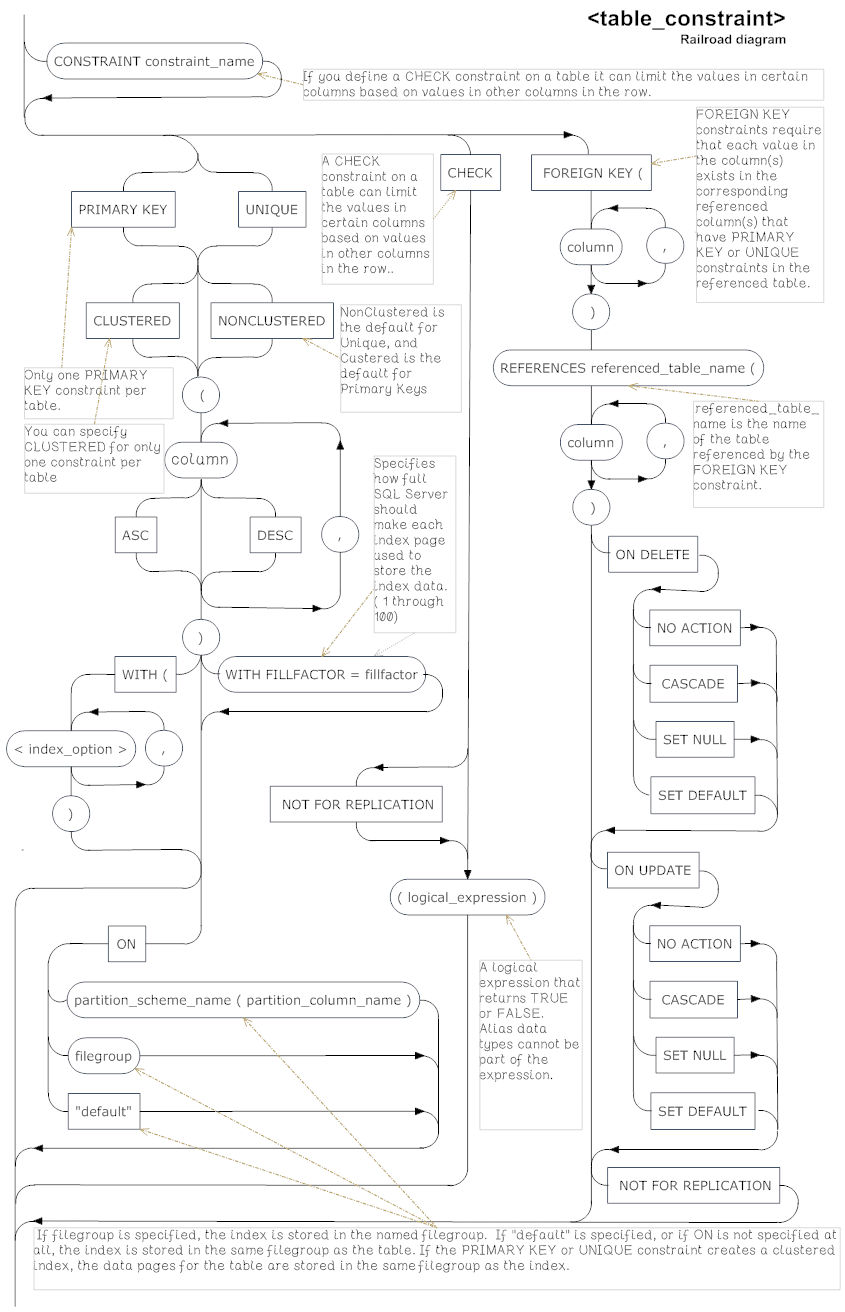
- Table Constraint
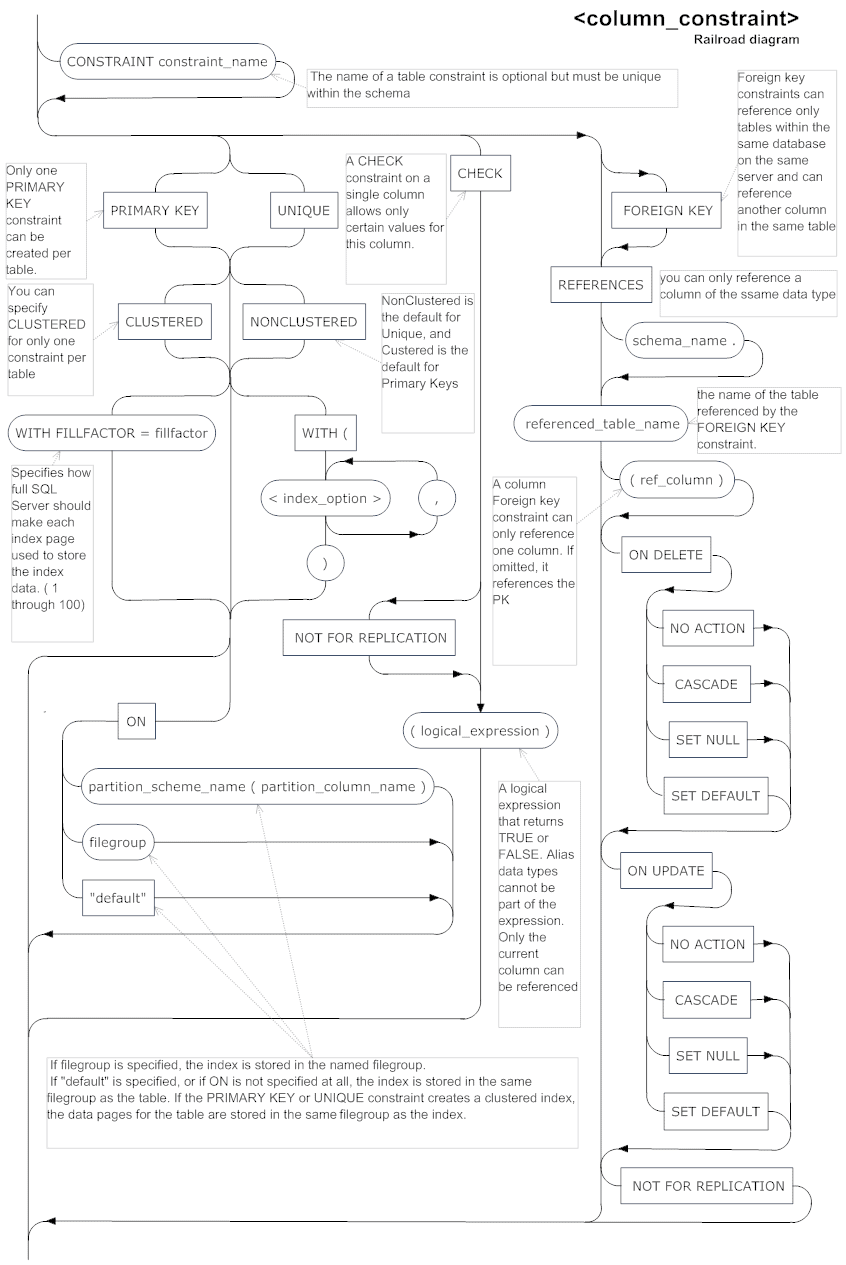
- Column Constraint
- Computed Column Definition
- Column Definition
ALTER TABLE overview syntax
The ALTER TABLE DLL statement allows you to
- ALTER a column by changing its data type, size , collation, NULLity, and so on.
- ADD one or more columns or constraints
- DROP a constraint or column
- ENABLE or DISABLE a trigger, constraint, change tracking, or filetable namespace
- Either CHECK or NOCHECK (disable or enable) a constraint
- SWITCH a partition to a different table
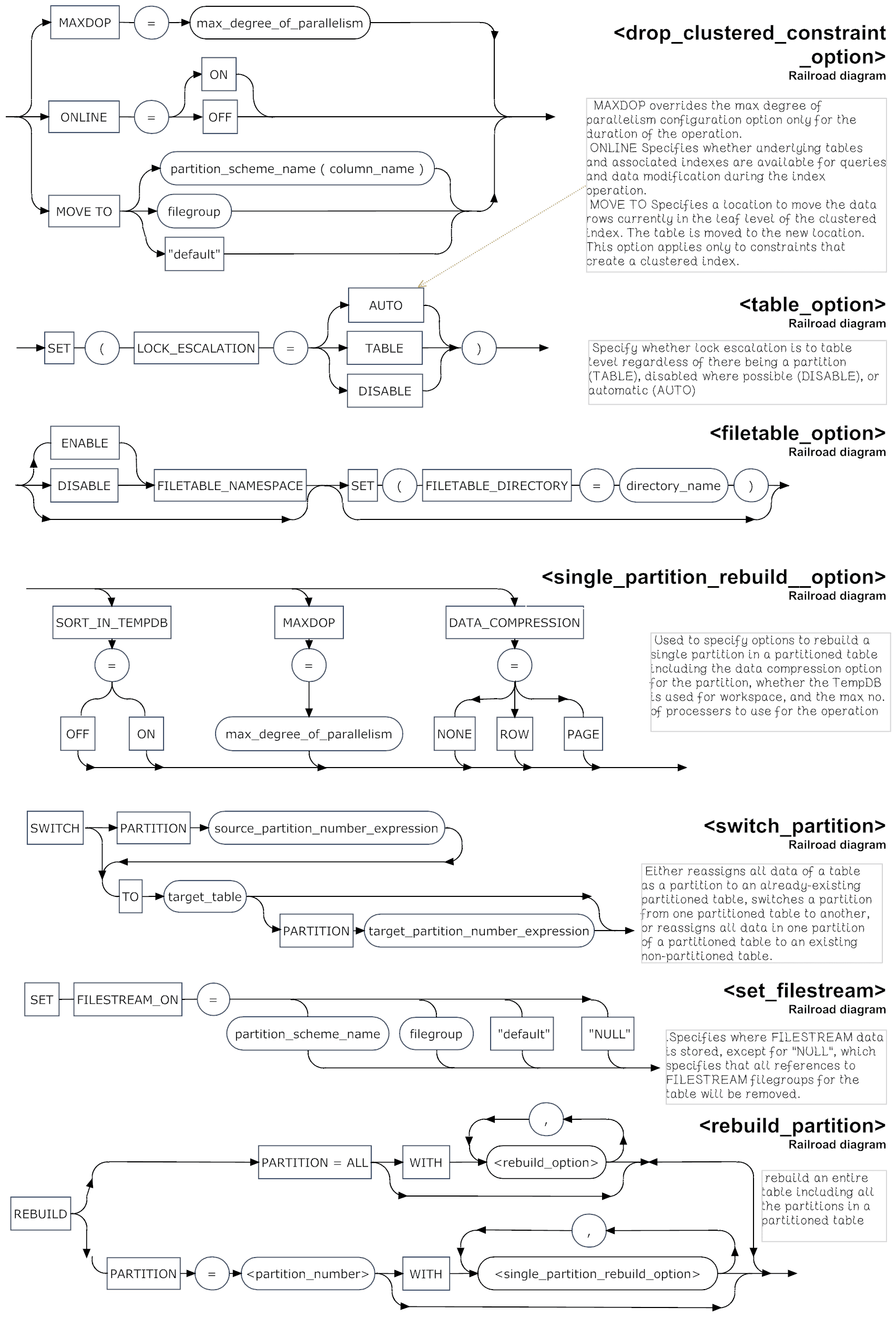
- SET filestream on, the filetable directory, or lock escalation to either ‘auto’ or ‘table’, or disable it
- REBUILD a partition to change the compression
We can summarise this in the following Railroad diagram. (See here for an explanation of the syntax)
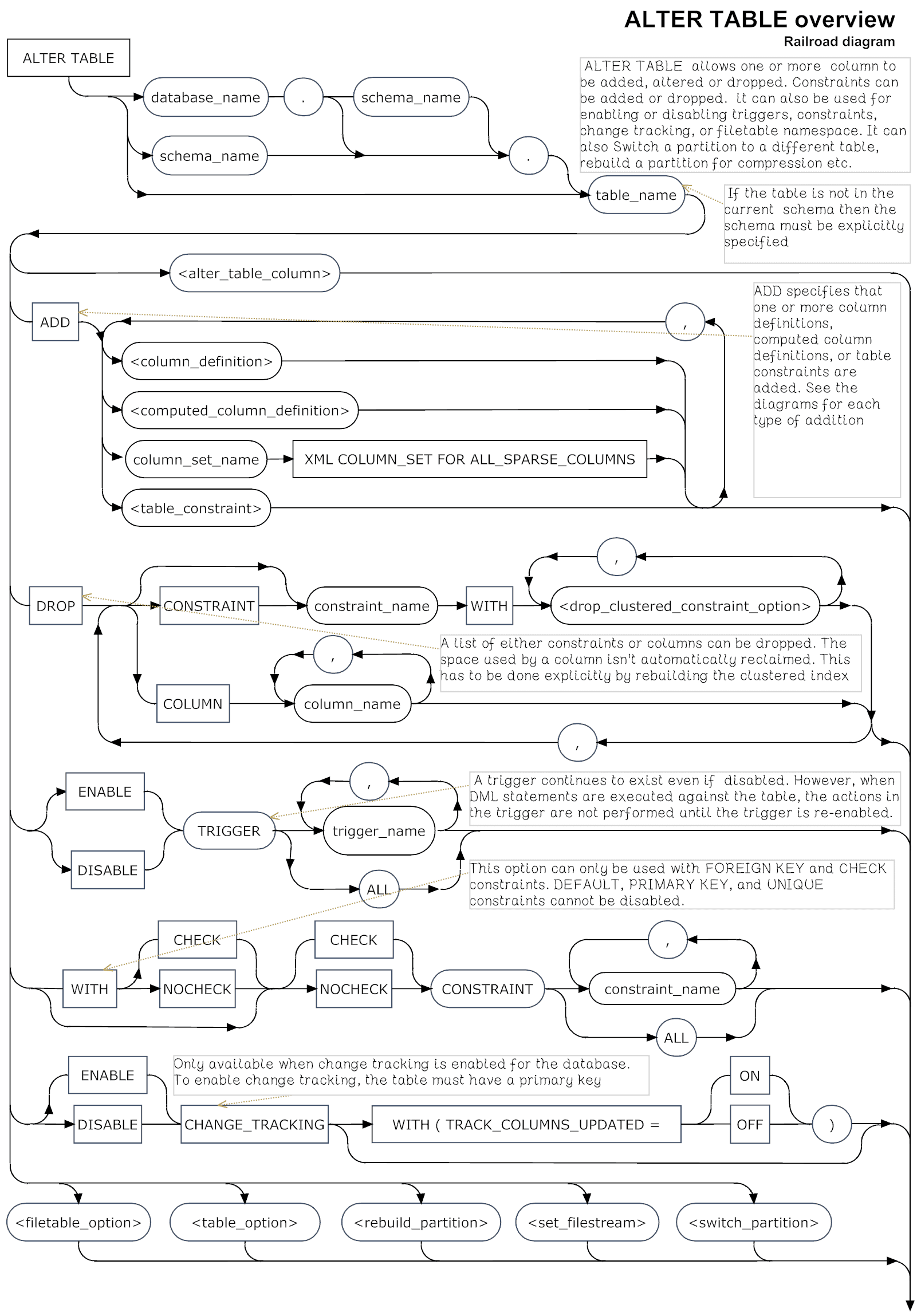
Most of these operations are straight-forward but others will have repercussions. These repercussions can be for data, views, indexes, constraints, statistics or calculated columns.
Data modification is one common repercussion. The ALTER COLUMN, in particular, could easily require changes to data if the table contains any rows. This starts immediately, requires a schema-modify lock on the table and the changes are logged recoverable. This can cause problems in a working database, particularly when a column is added or dropped in a large table. The rollout of a database refactoring to production can be painful in a database of any serious size. If, for example, you wish to add a column to a large and important table, then every other process that needs to access that table will be blocked for the duration of the modification. Other ALTER operations on large tables, such as changing the clustered index, can take a long time.
In some cases it is just too difficult to do the operation, and so some types of modifications are forbidden. There is, for example, no RENAME keyword because the mopping-up exercise in finding and changing all references to the column is just too complicated. (you have to do things the hard way with sp_rename).
This means that there are some rather complicated rules about what you can alter in a column or constraint. Many of these rules are common-sense, but other rules for altering a component of a table are rather difficult to follow, and so I can only give a brief summary.
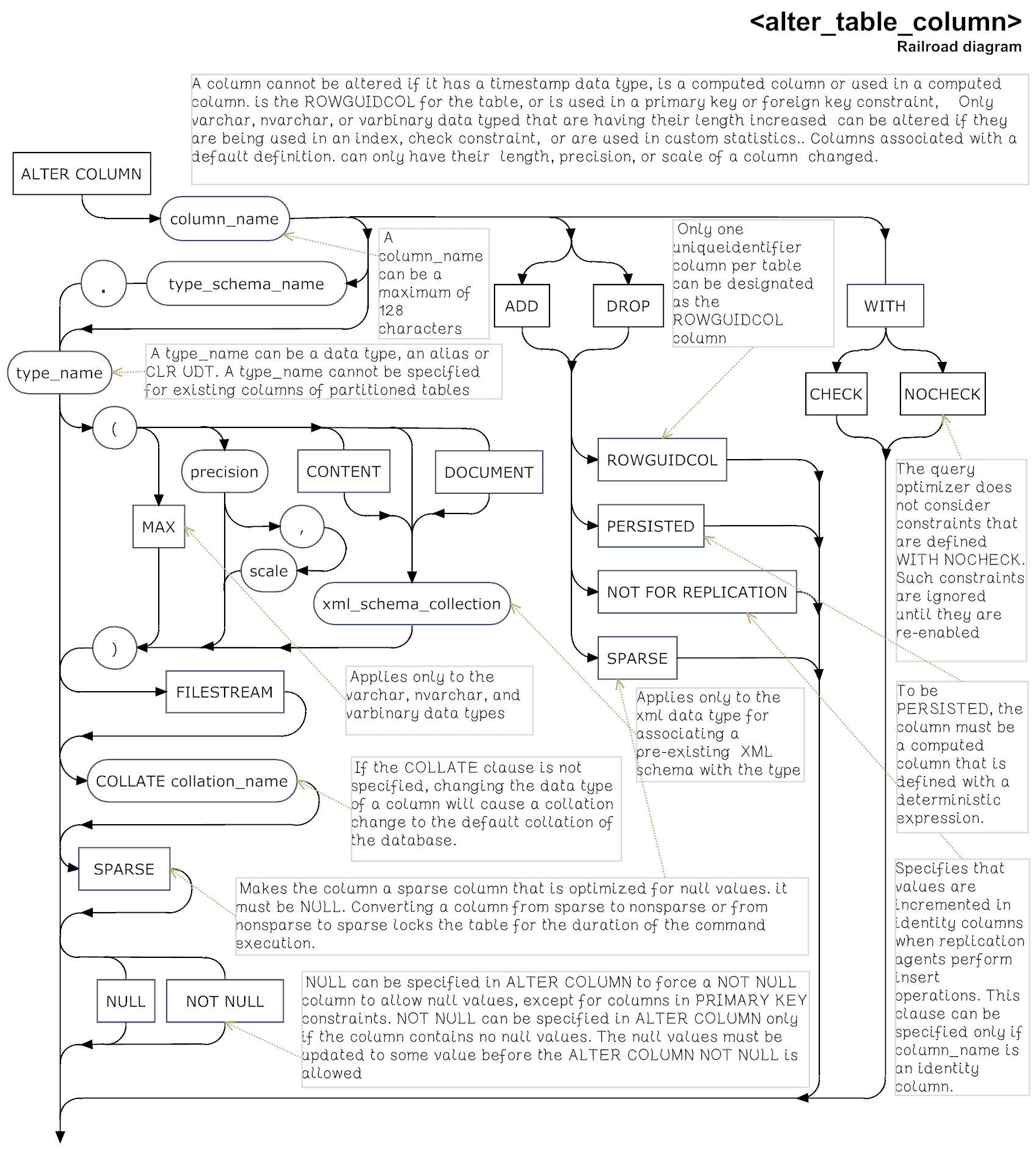
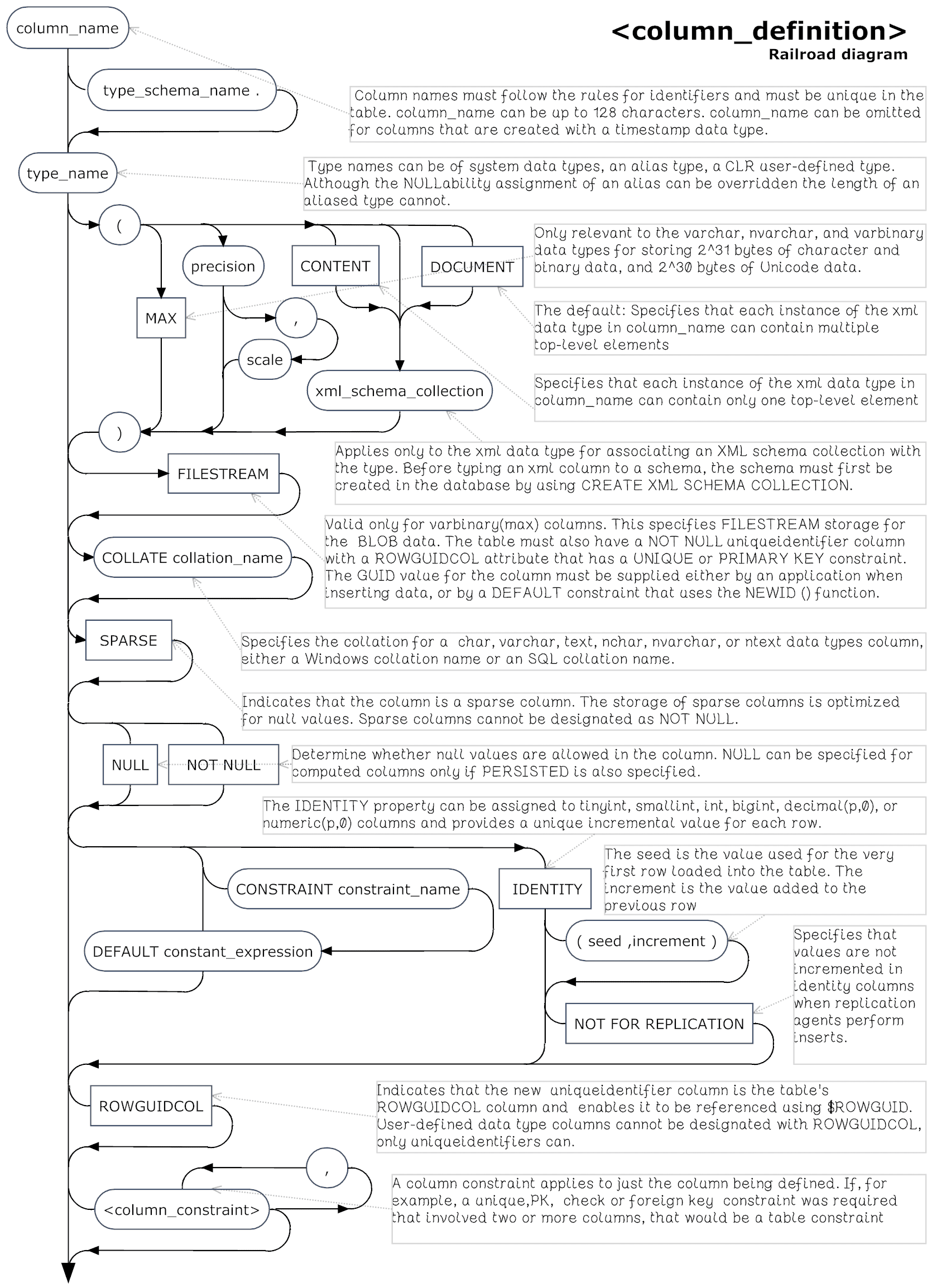
If a column participates in a schema-bound view, you cannot change that column. You can’t alter a column if it has a timestamp data type, is a computed column or used in a computed column, is the ROWGUIDCOL for the table, or is used in a primary key or foreign key constraint. Only varchar, nvarchar, or varbinary data types that are having their length increasedcan be altered if they are being used in an index, check constraint, or are used in custom statistics. Columns that are associated with a default definition can only have theirlength, precision, or scale of a columnchanged. The data type of a column in a partitioned table can’t be altered.
If you change the length, precision, or scale of a column with the ALTER COLUMN phrase, and data already exists in the column, the new size must be sufficient to hold the largest data item in the column. Although you can alter the length of a column if it is involved in an index, a primary key or foreign key constraint, or explicit statistics, you can’t change its type. If the column is part of a PRIMARY KEY constraint then only a varchar, nvarchar, or varbinary column can be altered in size.
You are allowed to drop a column as long as there are no existing indexes, table constraints, defaults or views using that column. It can’t be dropped if it is bound to a rule. When you drop a column, any associated automatic statistics are dropped at the same time. Indexes can’t be dropped directly, but they are dropped automatically if they are associated with a constraint that is then dropped. When you are dropping a constraint that involves a clustered index, you can avoid disruption to other processes if you specify the ONLINE-ON option (enterprise edition only) so that the necessary rebuild does not block queries and modifications to the underlying data and associated non-clustered indexes. Before doing so, make sure that the index is enabled.
The problems with NULL and NOT NULL
It is important to specify explicitly the nullability (NULL or NOT NULL) of a column. Never rely on a default. Changing the nullability (whether the column accepts nulls) of a column can cause frustration. If the table has rows, then you can only change from NULL to NOT NULL if you specify a DEFAULT value. If you are dealing with a computed column, then you can make it NOT NULL only if it is PERSISTED.
When you use the ADD COLUMN phrase, the problem is what do with existing rows in the table. If your column is NULL,then it is filled with NULLs, even if there is a default, since NULL is a valid value. You need to add the WITH VALUES phrase to the default to fill the column with particular values. Otherwise, if your column is NOT NULL, you have to include a default constraint and the value in the default constraint is then used. If you neglect to add the default constraint, then the operation will fail.
Alter Table Column syntax
Disabling constraints
By using the NOCHECK keyword with a newly-added or re-enabled FOREIGN KEY or CHECK constraint as, for example, in…
|
1 |
ALTER TABLE tableReferencing WITH NOCHECK CONSTRAINT FK_References |
… the constraint is disabled so that the data in the table is not validated against it. Although this might help in rare cases, the query optimizer does not consider any constraints that are defined WITH NOCHECK since they are flagged as ‘is_not_trusted’, so queries are likely to run slower They have to be enabled by a subsequent ALTER TABLE statement.
The default setting for new constraints is WITH CHECK, but WITH NOCHECK is assumed for re-enabled constraints unless you explicitly add WITH CHECK. Although it is useful for bulk import of data to temporarily disable constraints, these must be re-enabled after the operation. If you do not want, for some reason, to verify new CHECK or FOREIGN KEY constraints against existing data, use WITH NOCHECK. However, the WITH NOCHECK does not affect later data updates which will fail if the inserted data does not comply with the constraint. The safest approach is to check all data before a constraint is altered and always specify WITH CHECK, but if you use WITH NOCHECK, then fix all potential non-compliant data, perhaps check with …
|
1 |
DBCC CHECKCONSTRAINTS (Table_name) |
…in order to test that the data meets the conditions of the constraint, or the referential integity in the case of a foreign key, the and enable all constraints with …
|
1 |
ALTER TABLE table_name WITH CHECK CHECK CONSTRAINT ALL |
to allow SQL Server to check the validity of the constraint and flag it as ‘trusted’
Alter Table Components syntax/span>
The Column Definition syntax
Column Constraint syntax
Computed Column Definition
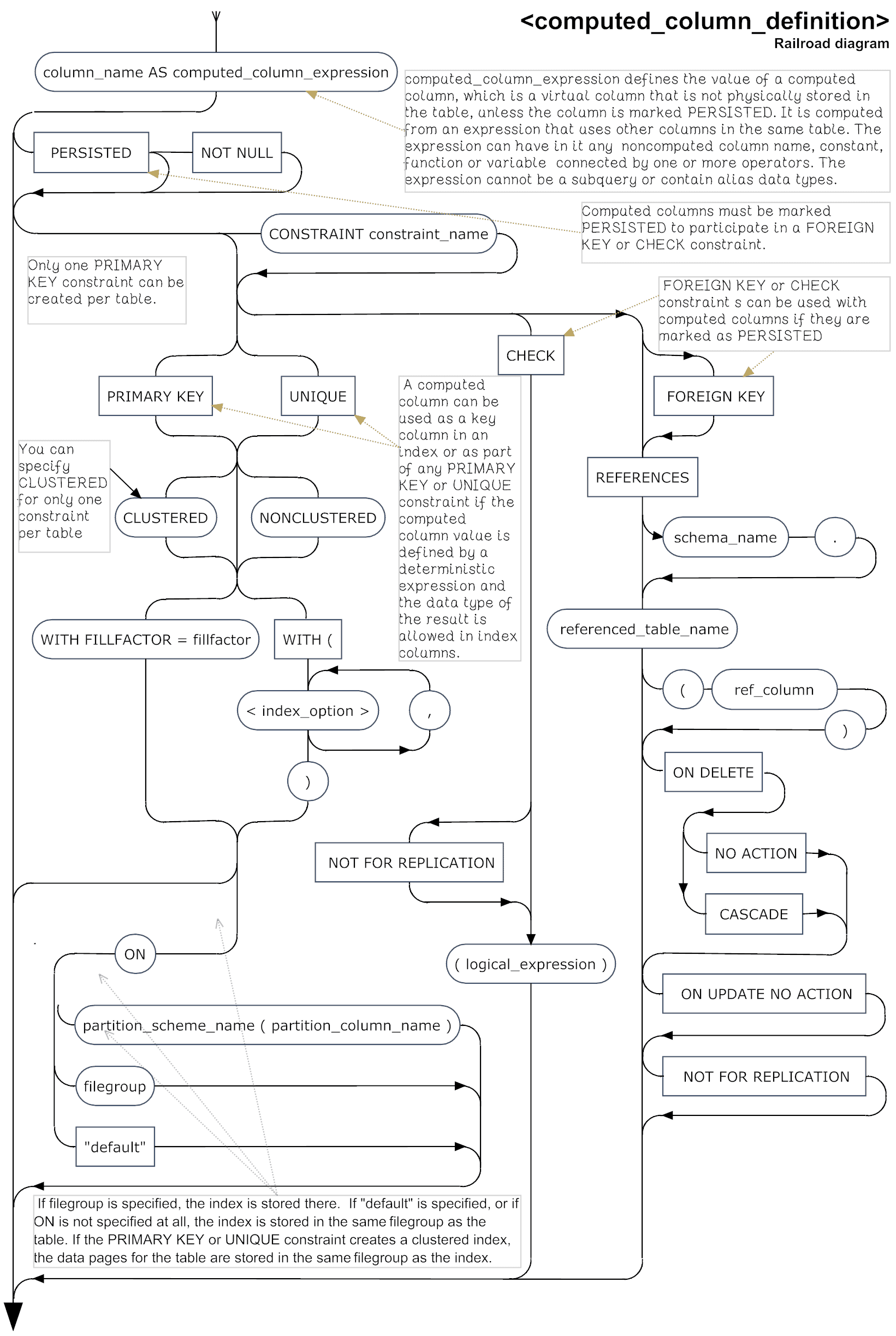
Table Constraint
Conclusions
Because the ALTER TABLE is used for so many different purposes, it is difficult to produce a clear overview, especially since SQL Server has produced a number of extensions that are occasionally rather clumsy for the purposes of managing compression, filestreams and partitions. Even so, I found that producing these diagrams helped my understanding of the ALTER TABLE syntax and I often refer to them. I very much hope you’ll find them as useful.
I don’t believe that even the casual user of relational databases should entirely avoid using SQL for doing DDL in favour of using a GUI. The moment I find myself going ‘off-piste’ with altering tables, I find that it is usually easier and safer to work with the syntax diagrams and use TSQL rather than to have to rely on using SSMS to alter tables, or to reverse-engineer the syntax from the examples provided; especially if you have SQL Prompt as well as a spirit guide.
I’d like to keep this set of diagrams updated, so please let us know if you spot any errors and I’ll do my best to fix them.
Acknowledgements
Many thanks to the pioneers of the railroad diagram. Also the MSDN ALTER TABLE page from where the explanatory quotes within the diagrams were taken and adapted.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments