
In the Oracle community, there is very strong guidance concerning the use of parameterized queries (or ‘bind variables’, as the Oracle community refers to them). Oracle’s Senior Technology Architect, Tom Kyte, states bluntly in his book “If I were to write a book about how to build non-scalable Oracle applications, ‘Don’t Use Bind Variables’ would be the first and last chapter”. Guidance on database application design does not get much clearer than that. As a consequence, the Oracle community has a very strong tradition of encouraging the use of parameterized queries and discouraging the use of dynamic SQL.
What about SQL Server though? The guidance in the SQL Server community is murkier than in Oracle. A handful of articles do encourage the use of parameterized queries. More recently, much has been written on the use of parameterized queries as a way to protect from SQL injection attacks. However, there seem to be very few articles that dig into the performance implications of dynamic SQL versus parameterized queries in a SQL Server environment. Unlike the Oracle community where numerous articles provide a detailed analysis of the performance difference between the two approaches, very few seem to be available on SQL Server.
This article has two purposes. The first is to investigate how significant of a performance difference exists between the use of dynamic SQL and parameterized queries in a SQL Server environment. I will go beyond simply measuring elapsed time to also show the performance difference in the amount of CPU time consumed on the database and the difference in plan cache memory consumed.
The second purpose of this article is to guide the reader through how the analysis was conducted. It will demonstrate some uses of SQL Server dynamic management views (DMVs), and how the information in these views can be used to capture data such that alternative solutions can be compared. By understanding what data is available and how performance can be measured, developers and DBAs can better analyze different choices and understand in detail their performance implications.
What Are Parameterized Queries?
There are two basic ways to write a SQL statement; the first is to explicitly specify the values for each parameter in the WHERE clause, as shown in the statement below:
|
1 2 3 |
SELECT ZipCode, Latitude, Longitude, City, State, County FROM dbo.UsZipCodes WHERE ZipCode = '54911'; |
Listing 1: A simple query
As with every statement it processes, SQL Server will create an execution plan and process the statement. The trouble starts when you submit a second, very similar query to the database like the one shown below:
|
1 2 3 |
SELECT ZipCode, Latitude, Longitude, City, State, County FROM dbo.UsZipCodes WHERE ZipCode = '75243'; |
Listing 2: Another simple query
Although the two statements above vary only by a value in the WHERE clause, they are not an exact character for character match. This means SQL Server must parse this second statement as well.
The second way to write the SQL statement is to replace the values in the WHERE clause with variable placeholders, as shown below:
|
1 2 3 |
SELECT ZipCode, Latitude, Longitude, City, State, County FROM dbo.UsZipCodes WHERE ZipCode = @zip_code; |
Listing 3: A parameterized query
The Simple Parameterization Feature
In cases in which values are specified explicitly, as in Listings 1 and 2, SQL Server invokes a feature known as ‘simple parameterization’. Simple parameterization is designed to reduce the resource cost associated with parsing SQL queries and forming execution plans by automatically parameterizing queries. With simple parameterization, SQL Server actually creates two execution plans for the first query (Listing 1). The first execution plan is a shell plan containing a pointer to the second execution plan. Its primary purpose is to help SQL Server locate the ‘actual’ execution plan, should this exact same query be submitted to the database again. The second execution plan contains the instructions about how to process the query. The following query displays what is contained in SQL Server’s plan cache, and can be used to show how SQL Server has split the execution plan into two pieces.
|
1 2 3 4 5 6 7 8 9 |
SELECT cp.objtype AS PlanType, cp.refcounts AS ReferenceCounts, cp.usecounts AS UseCounts, st. text AS SQLBatch, cp.plan_handle, FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle) AS qp CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle) AS st; |
Listing 4: Query to display SQL Server’s plan cache
If we run DBCCC FREEPROCCACHE to clear the plan cache, and then run only the first query (Listing 1) , here are the results for the plan cache query:

The first row represents the query used to view the plan cache. The second row is the shell execution plan. This is really a pointer the third row, which is a parameterized form of the query created by the simple parameterization feature.
Now, if the second query from above (Listing 2) is run, we will observe that it, too, undergoes simple parameterization. A second shell query is created with the exact text of the second query, but it, too, points to and uses the parameterized execution plan shown in row 3 above. Here are the results after executing the second query:
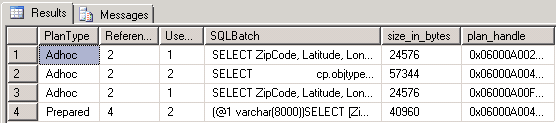
The second row represents the query used to view the plan cache. Rows 1 and 3 are the shell execution plans for the two queries that were executed, and row 4 is the parameterized execution plan, now showing a use count of 2.
While simple parameterization is a feature of SQL Server, relying upon it to parameterize your queries for you is not the best idea. First of all, there are a wide range of statements that SQL Server cannot auto-parameterize. In these cases, SQL Server will have to form a new execution plan each time, which is expensive. Second, as we can see from the above results, simple parameterization still uses some resources on the database server itself. SQL Server has to figure out whether it can auto parameterize the query, and if so, store an additional pointer in the plan cache. Finally, we have said nothing about how the application created these SQL statements; if they were created by string concatenation, they will be vulnerable to SQL injection attacks, and simple parameterization does nothing to protect you from that.
Parameterized Queries versus Stored Procedures
For the reasons just stated, DBAs have long favored the use of stored procedures over SQL embedded in the application. By utilizing a stored procedure and passing parameters to that procedure, the same execution plan can be used over and over by the database, saving load on the database server.
However, many application developers dislike using stored procedures. Application developers tend to be unfamiliar with languages like Transact-SQL and also dislike the extra step of needing to write a stored procedure. The topic of stored procedures versus SQL embedded within the application is hotly debated, and it is not the purpose of this article to restate the arguments for and against each. However, application developers can achieve essentially the same benefits as stored procedures provide by making sure they parameterize their queries.
When a parameterized query is used, SQL Server can maintain just one execution plan in its plan cache and use it over and over again for different values supplied to this statement, just like a stored procedure. From a performance and resource utilization perspective, this approach is much more economical. How much more economical is the focus of this article.
Analysis Methodology
For my investigation into the performance of parameterized queries, I am focusing on four different metrics for my analysis:
- The total elapsed time use to process n queries.
- The total CPU time used by SQL Server to process n queries.
- The total number of plans in SQL Server’s plan cache after processing n queries.
- The total amount of memory used by SQL Server’s plan cache after processing n queries.
I have written a small C# program that will serve as my load generation program. This program will execute the specified query n times against the database. By using the Stopwatch class in the System.Diagnostics namespace, one can measure the amount of elapsed time it takes to run n iterations of the query. Comparing elapsed time values will show what the end user of an application will feel with regards to performance. An elapsed time of 20% higher translates into 20% more waiting on the data access piece and 20% more waiting on the application for the end user.
The DMV dm_exec_sessions contains data on the resources a given session has used since the session started. To view the resource consumption for a particular session, the query below can be used:
|
1 2 3 4 5 6 7 8 |
SELECT cpu_time, memory_usage, reads, writes, logical_reads, FROM sys.dm_exec_cached_plans WHERE session_id = @session_id; |
Listing 5: Query to view the resource consumption for a session
By running this query at different points in time, the resources consumed by a session during a particular interval can be measured. In the C# program that serves as a load generator, the session of interest is obtained by doing a SELECT @@SPID on the connection where queries will be run. Then, on a separate connection (so as not to pollute the resource consumption statistics) the above query is run both before and after the load queries are executed. Values for each are recorded and the difference in these values is the resource usage during the test.
Three DMVs are used to determine how many execution plans are in the plan cache and how much memory they are consuming. They are dm_exec_cached_plans, dm_exec_query_plan, and dm_exec_sql_text. The SQL statement below will return the number of plans and total size of the plan cache.
|
1 2 3 4 5 6 |
SELECT COUNT(1) AS PlanCount, SUM (cp.size_in_bytes) / 1024 AS SizeInKB FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) AS st ; |
Listing 6: Query to return the number of plans and size of the plan cache
Before each test run, DBCC FREEPROCCACHE is called to clear all execution plans from the cache. After the test queries have executed, then the above query is run to capture the plan cache data.
Experiment One: A Most Basic Query
I will start with a very basic query. I have created a table called UsZipCodes that contains a record for every zip code in the United States along with the associated city, state, longitude and latitude. In total, there are 42,741 rows in the table. For both dynamic SQL and parameterized SQL, I will execute a query that selects a single record from the table by querying on the zip code itself. This query will then be repeated 5000 times with a different zip code each time. Executing this query 5000 times will comprise a single test run. To make sure my results are repeatable, I have performed this test 20 times. The table below shows the results for the average of all 20 runs.
| Query Type | Average Elapsed Time | Average Session CPU Time | Number of Plans in Cache | Average Size of Plan Cache |
| Dynamic SQL | 1570 ms | 766 ms | 5001 | 120,000 kb |
| Parameterized Queries | 1055 ms | 233 ms | 1 | 40 kb |
In this example, parameterized queries are shown to run about 33% faster than the dynamic SQL option. A more important and wider performance gap is seen on the amount of CPU time used. The dynamic SQL uses roughly 3.3 times the amount of CPU on the database server as the parameterized query option. On this very simple test, these results point to the fact that dynamic SQL is much less scalable as far as database CPU is concerned. And while the absolute results in this example are just milliseconds, on busy database servers, CPU is almost always at a premium. It is prudent to save CPU wherever one can to make sure that more CPU cycles are available for work that really needs it.
By far the biggest difference is in the size of the plan cache. In this example, SQL Server is using simple parameterization to automatically parameterize the dynamic SQL. Inspecting the plan cache data shows that for dynamic SQL, there are 5000 different shell plans and a single auto-parameterized execution plan. However, all of these shell plans consume a little bit of memory, and over 5000 times, this adds up to a significant amount. In contrast, the memory footprint of the plan cache is minimal when using parameterized queries. The result is that the dynamic SQL example uses significantly more memory that it’s parameterized query counterpart. This additional memory that is devoted to the plan cache cannot be used for the buffer cache to keep pages in memory. In this case, that translates to about 14,000 fewer pages that can be stored in the buffer cache. While this query may be simple, the number of pages wasted adds up quickly.
A More Complex Test: Query with a Join and an Order By
The query used in the example above is about as simple as they come: Retrieve a single result using the primary key, which, in this example, is a clustered key. In this case, minimal CPU time will need to be devoted to other activities like sorting or performing a join operation. Since the query is so simple and the CPU time per execution so small, one may even be tempted to dismiss these results, claiming that the excess CPU time used is insignificant.
The question, therefore, becomes: what happens on a more complex query? For a query that will return multiple rows, has one or more JOIN operations, and has an ORDER BY clause, can we quantify the difference between dynamic SQL and parameterized queries and how significant is this difference? Furthermore, it is worthwhile to examine a case in which simple parameterization is not used?
To measure this, I have a second set of data access routines in my C# program. These will perform the query against the AdventureWorksLT database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT h.SalesOrderID, h.OrderDate, h.SubTotal As OrderSubTotal, p.Name AS ProductName, d.OrderQty, d.ProductID, d.UnitPrice, d.LineTotal FROM SalesLT.SalesOrderHeader h INNER JOIN SalesLT.SalesOrderDetail d ON h.SalesOrderID = d.SalesOrderID INNER JOIN SalesLT.Product p ON d.ProductID = p.ProductID WHERE h.CustomerID = @customer_id AND h.OrderDate > @start_date AND h.OrderDate < @end_date ORDER BY h.SalesOrderID, d.LineTotal; |
Listing 7: More complex query with a JOIN and ORDER BY
Since the AdventureWorksLT contains a small data sample size, I used a data generator to insert data into the primary tables in the database. In my test database, the SalesOrderHeader table contains about 650,000 rows and the SalesOrderDetail table around 8.5 million rows. This larger dataset will provide more realistic test conditions for our test.
For each test run, the query was executed 100 times. A total of 20 test runs each were conducted. The results are shown in the table below.
| Query Type | Average Elapsed Time | Average Session CPU Time | Number of Plans in Cache | Average Size of Plan Cache |
| Dynamic SQL | 61,992 ms | 8842 ms | 100 | 9500 kb |
| Parameterized Queries | 55,293 ms | 2342 ms | 1 | 104 kb |
In this case, the parameterized version of the query has an elapsed time that is 10.8% less than its dynamic SQL counterpart. One may be tempted to argue that the actual difference was only 67 milliseconds per query on average. While that is factually correct, it is still almost 11% slower. Considering that applications run multiple queries per user interface page they display, one must remember that number will likely be multiplied across several queries. Taken across an entire data access layer, 11% slower performance will be much more significant and this will feed directly into the user’s perception of the application.
In the area of CPU time, the savings are even more significant. The dynamic SQL version of the query uses 3.7 times more CPU than the parameterized version. Consider, though, that most databases aren’t processing a single query at a time. Typical applications may have hundreds or even thousands of users of which some percentage will always be hitting the database at a given time. By using almost four times the amount of CPU, applications using dynamic SQL will be placing significantly more stress on their backend database server.
Finally, the plan cache results from the first experiment are also confirmed. In this case, each plan takes up an average of 95 KB of memory, which means each time this query is run with different values, another 95 KB is required in the plan cache. In terms of plan cache memory, the penalty is really two fold. First, more complex queries have larger execution plans because those execution plans require more individual steps to complete. Further, more complex queries are less likely to be auto-parameterized by SQL Server, so each instance of running the query will have not a shell execution plan, but a full copy of the execution plan, using the maximum amount of memory. On busy database servers, it is always important to make efficient use of memory. By using parameterized queries, you ensure the memory footprint of the plan cache is as small as possible, leaving more memory free for other critical tasks.
Conclusion
The results show that on SQL Server, there is a measurable performance impact of using parameterized queries versus dynamic SQL. The difference in performance can be seen in all every aspect of performance measured. By choosing dynamic SQL, an application will see response times that are slower than if parameterized queries are used. This will ultimately be reflected in the response time of the application, perhaps giving the user the impression that application performance is sluggish.
There is an even more significant difference in the use of resources on the database server. In the two examples in this article, the amount of CPU time used on the database server was 3.3 to 3.7 times greater when using dynamic SQL instead of parameterized queries. While these numbers are just examples of what might occur, it is clear that dynamic SQL will place a much higher CPU load on the database server. In most organizations, the database server is already one of the busiest servers. CPU tends to be a scarce and precious resource, and it needs to be treated as such. Once the CPU utilization hits 100%, other processes will have to queue up to wait. This will result in even longer elapsed times for queries to run. And by using dynamic SQL, you will get to 100% utilization a lot faster than by using parameterized queries. Wasteful usage of the CPU always has consequences, and the consequences usually become more dire the more wasteful you are.
The same is true when evaluating the memory utilization of the plan cache. The size of the plan cache is orders of magnitude larger (megabytes versus kilobytes) when using dynamic SQL. Since memory for the plan cache is stolen from the buffer pool, every additional page needed for the plan cache is a page less that can be used to keep data pages cached in memory. By not using parameterized queries, you are effectively reducing the size of the buffer pool, which is a primary driver of performance. If SQL Server cannot find a data page in the buffer pool, it has to go to disk. Going to disk is almost always orders of magnitude slower. Keeping the plan cache as small and compact as possible is important so SQL Server can cache as many data pages as possible.
I would like to make a final point about resource utilization on the database server. Once you reach 100% of resource consumption, it is not easy to add more resources on the database server. If you have a web application, it is a fairly straightforward task to add an additional server or two to the web cluster. Or, you can even swap out servers in the cluster for more powerful machines. Neither of these options will incur downtime for the application since some servers in the cluster will always remain running. However, adding hardware to the database server typically will involve some sort of downtime since the database is just a single host.
This article also showed that while SQL Server contains a feature to auto-parameterize queries (simple parameterization), developers should not rely on this feature and should not expect that auto-parameterization will deliver the same overall performance as properly parameterized queries. This article showed that when simple parameterization was invoked, additional database CPU was required because now SQL Server must figure out if it can auto-parameterize a query and how to do it. Furthermore, while simple parameterization will save space in the plan cache, it still must create an entry for the shell execution plan, and while individually the shell plans don’t take much space, collectively they can. Since it is also difficult to understand all of the rules for when auto-parameterization will and will not be invoked, it is clear that developers are far better off by using parameterized queries explicitly in their applications.
Hopefully, this paper also showed how some basic knowledge of the SQL Server DMVs can be used to gather statistics and perform analysis of different algorithms. By understanding what real-time performance data is collected by SQL Server and how to capture this data, developers and DBAs can work together to gain hard evidence about how one algorithm performs when compared to another. Understanding at a detailed level what drives the performance of one algorithm versus another can only help you produce better software that is more responsive to end users.
References
- Plan Caching in SQL Server 2008, by Greg Low
- Inside Microsoft® SQL Server⢠2005: Query Tuning and Optimization, by Kalen Delaney, S. Agarwal, C. Freedman, A. Machanic, R. Talmage
- Dynamic Management Views and Functions (Transact-SQL), MSDN Documentation
- Expert Oracle Database Architecture, Apress, Second Edition, By Thomas Kyte
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments