
A SQL Server Integration Services (SSIS) package can fail for many reasons . A data source might be offline, a server might go down, the network might be unavailable, or countless other problems might arise. Whatever the reason, the end result is the same-your SSIS package stops running.
In some cases, this might not be too big a deal; you can simply restart the package after the problem has been resolved and everything is back to normal. However, if your package is loading terabytes of data or performing numerous other operations, a failure can represent a significant hit on your schedule and resources.
One way to help protect against such a happening is to implement checkpoints in your SSIS package. Checkpoints let you restart a package from the point of failure. For instance, if your package fails after the retrieved data has been staged, you can rerun the package starting at the point of failure without having to retrieve and stage the data again. In other words, the package starts right where it left off. By using checkpoints, you can avoid having to repeat tasks that involve large files or reload or re-aggregate large amounts of data.
How Checkpoints Work
When you configure your SSIS package to use checkpoints, SSIS maintains a record of the control flow executables that have successfully run. In addition, SSIS records the current values of user-defined variables.
SSIS stores the checkpoint information in an XML file whose name and location you specify when you configure your package to use checkpoints. When the package runs, SSIS takes the following steps to implement checkpoints:
- Creates the XML file.
- Records the current values of user-defined variables.
- Records each executable that successfully runs.
- Takes one of the following two actions:
- Saves the file if the package stops running on an executable configured to use checkpoints.
- Deletes the file if the entire package runs successfully.
If you configure a package to use checkpoints and that package fails during execution, SSIS will reference the checkpoint file if you try to rerun the package. SSIS will first retrieve the current variable values as they existed prior to package failure and, based on the last successful executable to run, start running the package where it left off, that is, from the point of failure onward, assuming you’ve addressed the issue that caused the failure in the first place.
Configuring Checkpoints
To implement checkpoints in your package, you must configure several properties at the package level:
- CheckpointFileName: Specifies the full path and filename of your checkpoint file.
- CheckpointUsage: Specifies when to use checkpoints. The property supports the following three options:
- Never: A checkpoint file is not used.
- IfExists: A checkpoint file is used if one exists. This option is the one most commonly used if enabling checkpoints on a file.
- Always: A checkpoint file must always be used. If a file doesn’t exist, the package fails.
- SaveCheckpoints: Specifies whether the package saves checkpoints. Set to True to enable checkpoints on the package.
After you’ve configure these three package properties, you must set the FailPackageOnFailure property to True on each container or task that should participate in the checkpoint process. An executable that is enabled to use checkpoints serves as a starting point should the package fail and you want to rerun it. For example, suppose you set the FailPackageOnFailure property to True on a Data Flow task. If the package fails on that task and you restart the package, the package will start there. However, if the package fails at a task for which the FailPackageOnFailure property is set to False, the XML file is not saved and checkpoints are not used when you restart the package.
You should consider carefully which executables to include in the checkpoint process. For example, a Foreach Loop container can make using checkpoints a challenge. If you configure the container itself to use checkpoints, SSIS has no way of knowing which tasks inside the container have already run at the time of failure. And if you configure the tasks within the container to use checkpoints, variable values are not always recorded properly in the XML file at the time of failure. For that reason, many SSIS developers recommend against using checkpoints for loop iterations.
You must also be careful using checkpoints when running parallel operations in which all operations must succeed or fail as a logical unit, such as when you have parallel data flows that must succeed or fail as a single operation. You could, of course, put everything within a Sequence container and configure the container to use checkpoints, but if the container then represents the bulk of the control flow, you’ve gained little advantage because most of the work will have to be repeated anyway. Only if there are subsequent tasks, and you configure checkpoints on those tasks, do you have anything to gain.
Ideally, if you plan to implement checkpoints in your package, you should take them into account when you design your package. For example, you might want to separate the part of the data flow that stages data from that which loads data so you can use checkpoints more effectively. Let’s look at a simple example to demonstrate how this works.
Checkpoints in Action
To demonstrate how to use checkpoints, I created a basic SSIS package in SQL Server Business Intelligence Development Studio (BIDS). Then I added the following two components:
- OLE DB connection manager. The connection manager establishes a connection with the AdventureWorks2008R2 sample database on a local instance of SQL Server 2008 R2.
- User-defined variable. I created an int variable named number and set the initial value to 1.
After I configured these two components, I added several tasks to the control flow, which are shown in Figure 1. The control flow, in theory, creates the People table, retrieves person data, sets the variable value, loads the person data, and then deletes the table. In reality, the package doesn’t really retrieve or load data, but it contains enough tasks for the package to run successfully and be able to demonstrate how checkpoints work.
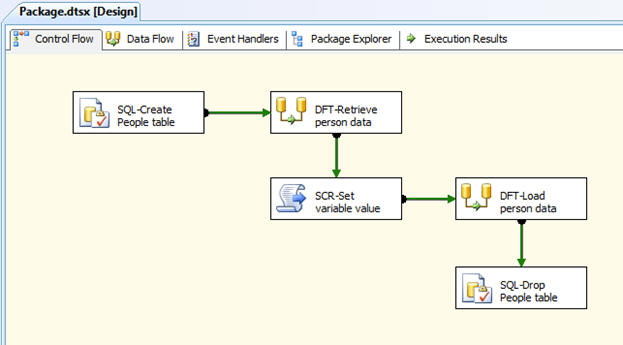
Figure 1: Setting up the control flow in an SSIS package
The first task I added is an Execute SQL task. The task uses the OLE DB connection manager to connect to the AdventureWorks2008R2 database. I added the following Transact-SQL code to the task in order to create the People table:
|
1 2 3 4 5 6 7 8 9 10 |
IF OBJECT_ID('dbo.People') IS NOT NULL DROP TABLE dbo.People GO CREATE TABLE dbo.People ( PersonID INT PRIMARY KEY, FirstName VARCHAR(50) NOT NULL, LastName VARCHAR(50) NOT NULL ) |
The next task in the control flow is a Data Flow task. Although I labeled the task to indicate that it retrieves person data, the task does nothing at all. If this were an actual package, the data flow would load the person data into a staging table or raw files. However, because checkpoints work only at the executable level, it doesn’t matter whether we configure the data flow, just as long as we can control whether the task succeeds or fails when the package runs. More on that later.
Following the Data Flow task, I added a Script task. The task does nothing but modify the value of the number user-defined variable. When I configured the task’s properties, I added number to the Script Task editor as a read/write variable. Then, to the Main method of the script itself, I inserted the following C# line of code:
|
1 |
Dts.Variables["Number"].Value = 2; |
As you can see, the code simply sets the value of the number variable to 2. Although this serves no functional purpose in the current package, it does let me verify whether the current variable value is being properly recorded in the checkpoint file.
After the Script task, I added another Data Flow task that supposedly loads the person data into the People table. Again, this is just a dummy task that takes no action, but it is an executable that can either succeed or fail when the package runs.
The final component I added to the control flow is another Execute SQL task. The task uses the following Transact-SQL code to drop the People table:
|
1 2 |
IF OBJECT_ID('dbo.People') IS NOT NULL DROP TABLE dbo.People |
That’s all there is to the package. It’s simple, does very little, but provides everything we need to test checkpoints. If you were to run the package now, the package should run with no problem and each component should turn to green. So now let’s set up the package to use checkpoints. The first step then is to configure the three package properties described earlier:
- CheckpointFileName: I specified a path and filename for my checkpoint file.
- CheckpointUsage: I selected the IfExists value.
- SaveCheckpoints: I selected the True value.
Next, I set the FailPackageOnFailure property to True for the last three components in the control flow (the Script task, second Data Flow task, and second Execute SQL task). Now, if the package fails on any of these three components, the checkpoint file will be saved and will include a list of all the executables that had run successfully up to the point of failure.
Because I did not configure the first Data Flow task to use checkpoints, checkpoints will not be used if that task fails, and you have to run the package from the beginning. If your data retrieval and staging process includes a significant amount of data, you might consider breaking that component into separate data flows and then implementing checkpoints on the individual components, but you should do this only if you can separate the data into discrete units that do not have to succeed or fail as a whole.
If you were to run the package as we currently have it configured, all the tasks should still successfully execute. So we need to make the package fail on one of the three tasks configured to use checkpoints. The easiest way to do this is to set the ForceExecutionResults property value to Failure on the task we want to fail. (This is a great trick to remember whenever you’re testing your SSIS packages.)
In this case, I configure the property on the second Data Flow task so it will fail. Now when I run the package, the package will stop at the second Data Flow task, as shown in Figure 2. Notice that the first three tasks ran successfully, as I would have expected, and the Data Flow task has failed.
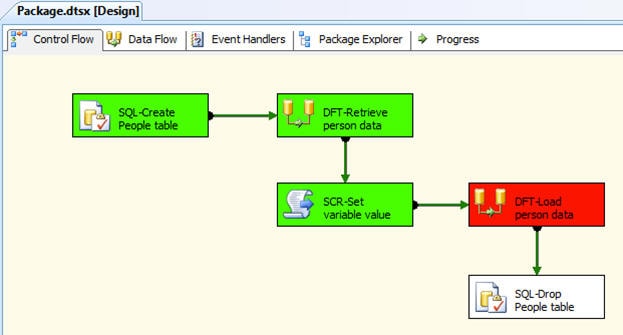
Figure 2: Running an SSIS package configured to fail
Because the package failed at a task configured to use checkpoints, the XML checkpoint file is retained in the designated folder. If you view the file’s content, you should see a set of XML elements and attributes similar to those shown in Figure 3.

Figure 3: Viewing the XML checkpoint file after package failure
Notice first that the file contains a <DTS:Variables> element and embedded within that is a single <DTS:Variable> element. The <DTS:Variable> element describes the number user-defined variable I added to the package when I first created it. One of the elements within the <DTS:Variable> element is <DTS:VariableValue>, and as you can see, the value has been set to 2, which was the current value when the package failed (after the Script task had sent the value to 2). This confirms that SSIS has properly maintained the variable value.
Next in the XML file, you’ll find three <DTS:Container> elements. Each element corresponds to one of the tasks that ran successfully. (The GUID identifies the executable associated with the XML element.)
Because our SSIS package has been configured to use checkpoints, SSIS will reference the XML file if you rerun the package. SSIS will see that the three tasks ran successfully and start at the next task in the control flow.
However, before rerunning the package, you must address the problem that caused the package failure. In this case, that means reconfiguring the ForceExecutionResults property on the second Data Flow task by setting the property value to None, the default value. Now when you rerun the package, it will use the checkpoint file and start where it left off, as shown in Figure 4.
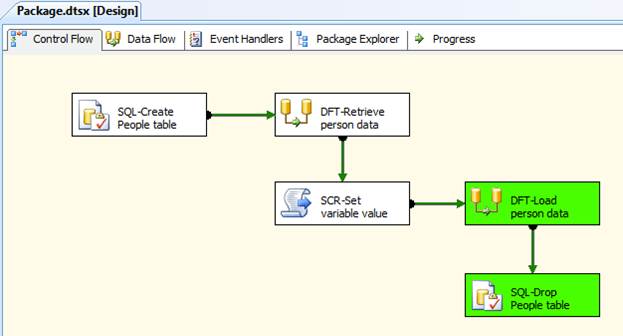
Figure 4: Rerunning an SSIS package that uses checkpoints
As you can see, the first three control flow components do not run because the checkpoint file shows that they have already run. So the package starts running at the second Data Flow task, the task that had originally failed.
Once the package completes running successfully, SSIS deletes the XML checkpoint file. If you were to rerun the package again, SSIS would start at the beginning.
Implementing Checkpoints
Clearly, checkpoints can be a handy tool if you want to avoid having to rerun components that manage large amounts of data. But you have to be careful not to implement them in ways that result in data not being managed correctly. For example, you should be wary implementing checkpoints on a Foreach Loop container or if you want to process multiple components as a unit. And you shouldn’t implement checkpoints unnecessarily. For instance, in our example above, implementing checkpoints on the first Execute SQL task would have provided little benefit. That said, checkpoints can be quite useful when working with large datasets. So consider using them when necessary, but use them wisely.



Load comments