
I have been working with SSRS since its initial release in 2004 and have written about it extensively over the years, mostly favorably. Despite its myriad shortcomings, obtuse errors and required hacks to make it work the way I want, it’s always somehow managed to tackle any business reporting requirement that I’ve thrown at it.
Recently, I worked on a SSRS project where the customer wanted to consolidate over 1000 reports, from two existing SQL Server 2008 R2 Enterprise SSRS deployments, into a single SQL Server 2016 ReportServer database, and then deploy that database to a new 2-node production cluster. We would use a scale out deployment to attach two Report Server Web Portal front ends, one per node, to the clustered ReportServer database. The idea was that should one node go “belly up”, the database instance containing the ReportServer database would failover and be available on the secondary node, and the remaining Report Server Web Portal, also on the secondary node, would continue to render the reports that drove their retail business.
Sounds straightforward? It was, until I realized the new production cluster would have SQL Server 2016 Standard Edition, not Enterprise Edition. It required a bit of creativity, but this article describes my solution, its merits and drawbacks.
Scaling Out SSRS
The ability to “scale out” SSRS to multiple frontend Web servers, so that one or more report server instances can share a single report server database, has always been an Enterprise Edition feature, and remains so in SQL Server 2016.
When I first joined the project, I confess that “separation of duties” meant that I was blissfully unaware of the need for my solution to work on Standard Edition. The customer was busily building the new production cluster, using Cluster Shared Volumes on Windows Server 2016. In the meantime, I was working in the Staging environment, merging reports from the two existing SQL Server 2008 R2 Enterprise SSRS deployments into a single SQL Server 2016 ReportServer database, on the Staging Server. This Staging Server had Developer Edition, which is unbounded feature-wise.
Merging reports from two ReportServer databases
I won’t cover how I merged the reports into a single ReportServer database and prepared it for migration to SQL Server 2016. For more information, please review the following link on using RS.EXE to migrate objects from one SSRS instance to another https://msdn.microsoft.com/en-us/library/dn531017.aspx.
Having vetted the new ReportServer database, I had to migrate it to the production cluster and my plan had been to use the scale out deployment native to SSRS Enterprise.
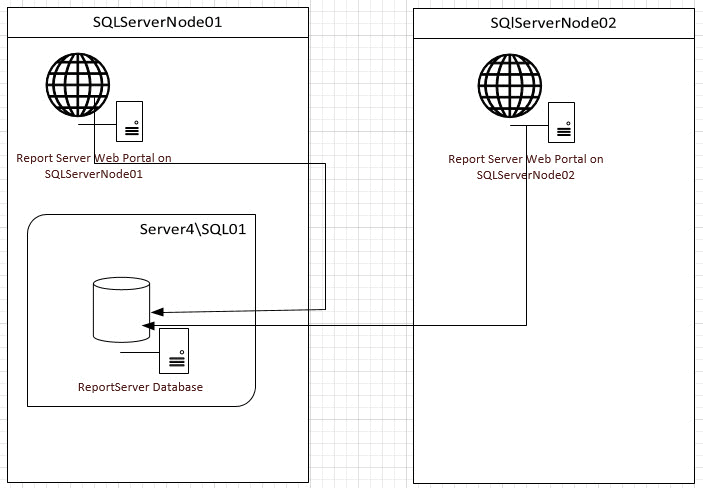
Figure 1 – Scaling out SSRS, Enterprise solution.
Here, we have two cluster nodes (SQLServerNode01 and SQLServerMode02), and one SQL Server instance (Server4\SQL01). In this Enterprise solution, the single ReportServer database is on a clustered instance so can failover to either node, and the two SSRS Web Portal front end applications are configured to connect to that single ReportServer database, providing the “scale out” capability that Enterprise Edition offers. No matter which node is active, or otherwise available, Reporting Services can render the reports via the same URL, which would use the clusters virtual name, in this case Server4, thus: http://Server4/Reports.
It was then that I discovered that the 2-node cluster was only to have SQL Server 2016 Standard Edition, with SP1. In Standard Edition, scale out deployments are not allowed so only one node could serve as the Report Server Web Portal that connected to the ReportServer database. While the database itself could failover from node to node, the Web Portal would not be available in the event that SQlServerNode01 went completely offline. My immediate response was to call the customer in panic and explain that we could not connect to a single ReportServer database from two different Web front end nodes. He explained back in large dollar signs the exact cost to implement Enterprise Edition on these two 32-core nodes.
One gulp later, and with my back against the drawing board, we agreed upon a new possible solution. My proposed SSRS Standard Edition scale out architecture would look as shown in Figure 2.
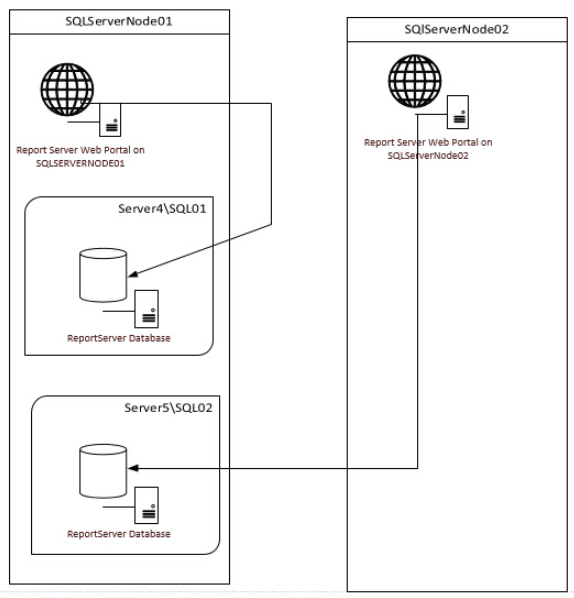
Figure 2 – Scaling out SSRS, The Rodney Landrum Standard Solution
Now, we have two cluster nodes (SQLServerNode01 and SQLServerMode02), and two SQL Server instances (Server4\SQL01 and Server5\SQL02). The theory was that we restore same ReportServer and ReportServerTempDB database on both instances on the cluster, and configure SSRS on each node. In theory (this quickly became my favorite qualifier), this would allow the SSRS Web Portal front ends on SQLServerNode1 and SQLServerNode2 to run independently, dividing the load between the two nodes. When failover occurred, it should still be possible to access reports from either Web Portal, using the cluster virtual name like http://Server4/Reports, without any other changes, regardless of which node “owned” the SQL Server instance where the ReportServer databases resided.
I could see some potential challenges, of course. This solution would require double deployment of new and modified reports and some additional logic to enable or disable subscriptions, controlled by SQL Agent depending on which SQL Server instance was “active”. It would also require query logic that could compare the two databases to ensure they were in sync.
However, it should work! In theory. Happily, on this occasion, theory and practice were closely aligned. It did not take long to implement and test this solution, and to my amazement every step went flawlessly. I give due credit to Microsoft for the obvious effort they have put in to improving the customer experience with these latest releases.
The following steps describe all that is required to complete the solution of deploying Reporting Services on two nodes of a multi-instance failover cluster using two identical ReportServer databases that housed all of the customer’s reports.
Restore Prepared ReportServer and ReportServerTempDB Databases on Primary
I had prepared a single ReportServer database, on a separate SQL Server 2016 Staging server called SQLTest01, into which I merged the reports from two different Reporting Services deployments. However, in other circumstances, I could just as easily have performed all of the prep work using the ReportServer database on the source SQL Server 2008 R2 instance. All you need to do is to back up the ReportServer and ReportServerTempDB databases from the source server and restore them on both on each of the SQL Server 2016 instances, on the cluster.
It is important to ensure the database names stay the same as they were on the source system because these names, especially for ReportServerTempDB, are actually hard coded in many or the stored procedures, when SSRS is configured. This is another advantage of restoring the ReportServer databases in two separate instances, because it is not possible to have the same databases by name on the same instance, and renaming the ReportServerTempDB database on the same instance would require updating all of the stored procedures that reference that database by name.
Figure 1 shows the databases restored to the two SQL Server 2016 cluster instances on Server4\SL01 and Server5\SQL02.
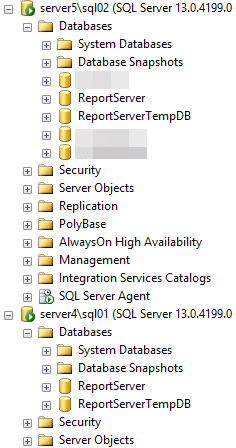
Figure 3 – The restored ReportServer and ReportServerTempDB files.
At this point, the databases are not initialized, as they will need to be before we can access them from the SSRS Web applications. They are simply identical copies of the source databases.
To ensure that we are able to use any encrypted data in the restored ReportServer databases, we also need to back up the encryption key on the source SSRS instance, in my case SQLTest01 where the ReportServer database was staged. Using Reporting Services Configuration Manager, connect to the source instance where you are copying the database from, and on the Encryption Keys tab click the Backup button, as shown in Figure 4. Provide the file location and password to create the encryption key file (a .snk file); we’ll also need these later in order to restore the key, when we configure Reporting Services on the new cluster instances.
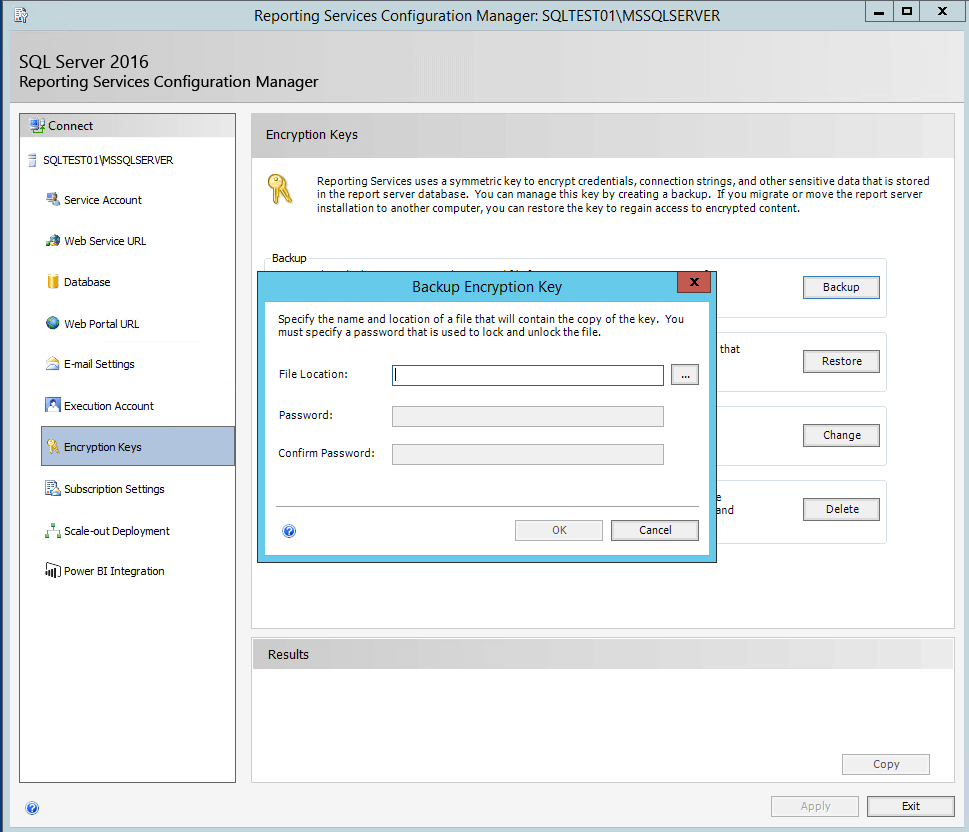
Figure 4 – Backing up the encryption key from the source
The next step is to configure the first SSRS instance (database and web portal) on the primary node
Configuring SSRS on Primary Node
This step assumes that we are logged on to the primary node (SQLServerNode01) and SRRS has already been installed on this node has not as yet been configured. We will eventually install SSRS on the SQLServerNode02, assuming that has not already been completed. For now, we will only configure Reporting Services for one of the first node.
Remove any existing database server keys
Before pointing the Reporting Services instance to the restored ReportServer database (on Server4\SQL01), it is key, no pun intended, to remove any previous server encryption keys that were initialized for the database. Since this database came from another system, in my case SQLTest01, I needed to remove the one row in the Keys table in the restored database prior to moving on to the next step of changing the ReportServer database connection. The row can be seen in Figure 5.
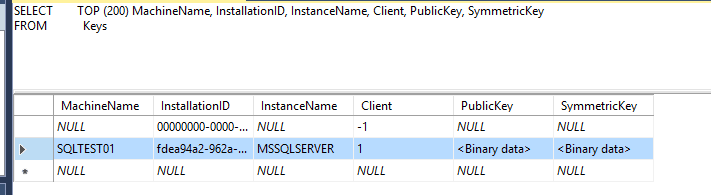
Figure 5 – Deleting the former machine from the Keys table in the ReportServer database.
I chose to simply right-click the Keys table and select “Edit Top 200 Rows“, highlight the row with SQLTEST01 as the MachineName and press the Delete key
Configure SSRS
Next, open Reporting Services Configuration Manager and connect to the instance that you will configure. You will need to configure several items at this stage, like Web Service URL, Web Portal URL, Email Settings, and more, as Figure 4 shows. However, our main concern is with the Database tab, where we need to point this instance at the newly-restored ReportServer database. You will note that I am actually connected to SQLServerNode01\SQL01. I would recommend using the same Windows service account that you did on the original SSRS source instance, but this is not required.
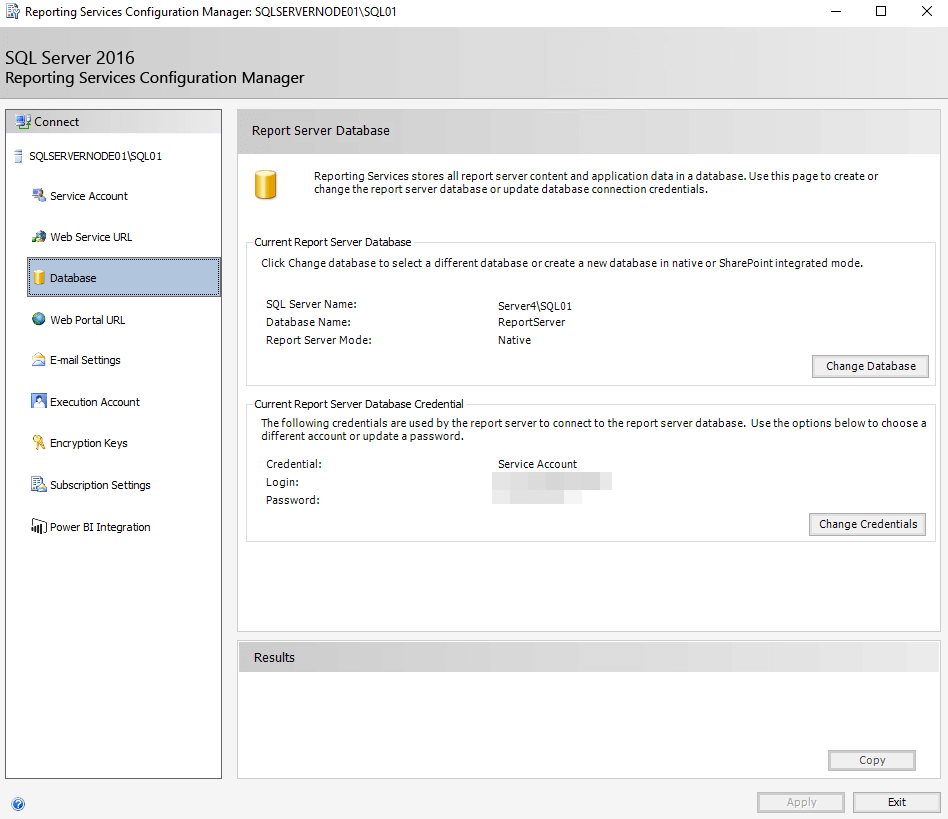
Figure 6 – Pointing to the freshly restored ReportServer database
Now, all that is required is to click on Change Database, navigate to the ReportServer database on the Server4\SQL01 cluster instance (it does not matter which node the instance is currently active on) and click apply. After a few moments you should have successful results in the Results tab.
Next, we need to restore the original source-system encryption key that we backed up in the previous section, simply by navigating to the Encryption keys tab, while still connected to the SQL01 instance in Reporting Services Configuration Manager, and clicking Restore. You will be prompted for the key location and password and after entering this information and clicking “OK” you should have a fully functional SQL Server 2016 Report Server instance running on the primary node, as you can verify by connecting to the Portal, http://Server4/Reports, in my case. Figure 7 shows the Web Portal.
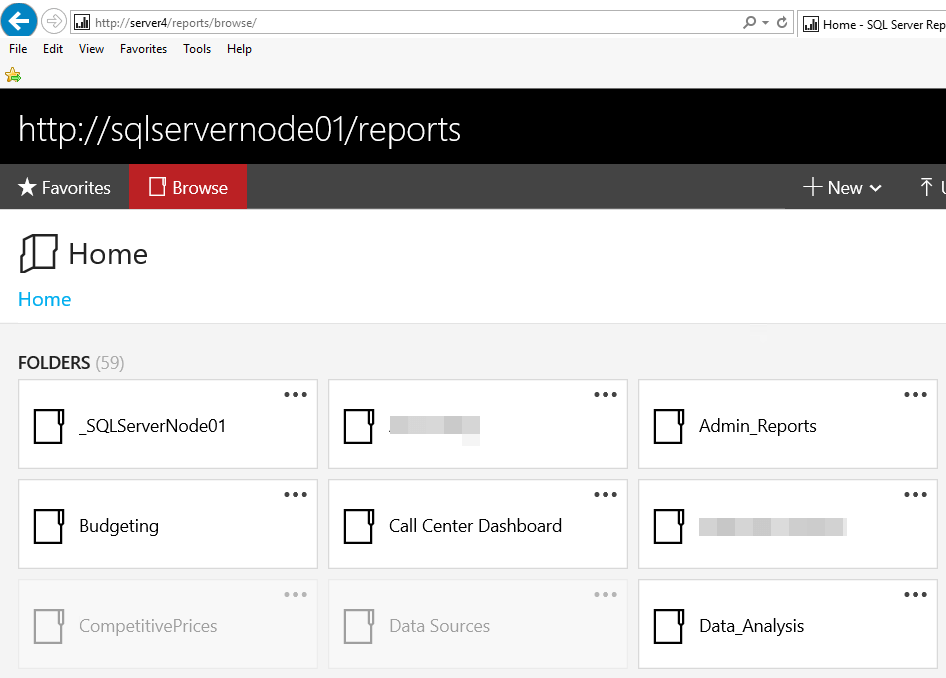
Figure 7 – Reporting Services Portal on Primary Node ReportServer Database
Note that even though I connected to Server4/Reports, which uses the cluster virtual name, the URL actually resolves to SQLServerNode01/reports. This is a key concept because when we configure SSRS on SQLServerNode02 to use the second ReportServer database that we restored on Server5\SQL02, we can standardize on Server4 as the virtual name, regardless of the node name.
A failover of Server4\SQL01 to SQLServerNode02 will still use Server4/Reports as the SSRS Portal connection, but will actually divert the URL to SQLServerNode02 and we will thus begin using the reports from the Server5\SQL02 ReportServer database that contains the identical folder structure, data sources and reports as the ReportServer database on SQL01.
For a sanity check, in each ReportServer database I did create two distinct folders called _SQLServerNode01 and _SQLServerNode02 so that I could see which report server database I was connected to at any given time. You can see the folders in Figures 7.
Enabling and disabling report subscriptions
Subscriptions for the reports will be restored with the ReportServer database and you will be able to see these via SQL Server Agent in SQL Server Management Studio. It is best to go ahead and disable all of the subscriptions until you are 100% in production. Figure 8 shows the disabled report subscriptions under SQL Agent.
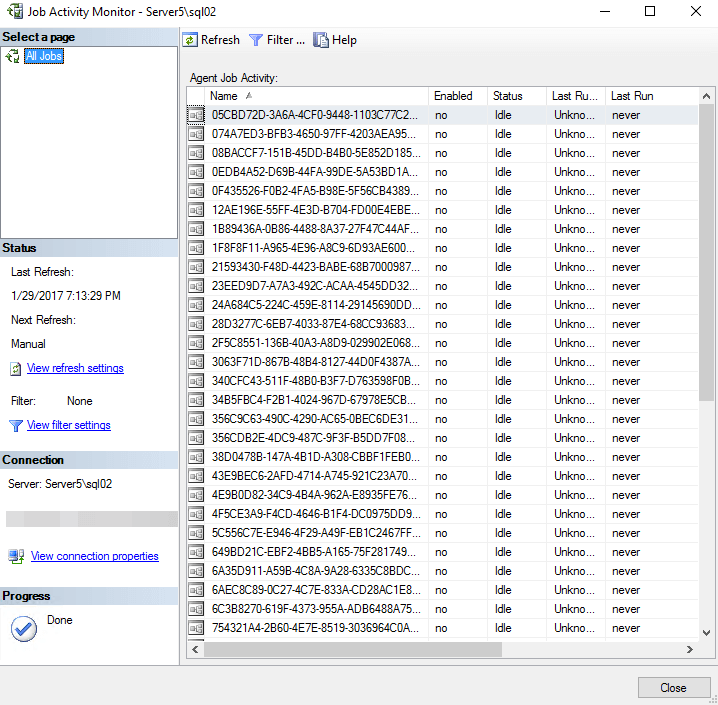
Figure 8 – Disabled report subscriptions on the new cluster
It will be easy to programmatically control the enabling of the subscriptions depending on the active, or owner, node of each SQL Server instance. I plan on using the output of the following query to determine which instance should have enabled subscriptions based the value of is_current_owner.
|
1 |
SELECT * FROM sys.dm_os_cluster_nodes |
|
NodeName |
status |
status_description |
is_current_owner |
|
SQLSERVERNODE02 |
0 |
up |
0 |
|
SQLSERVERNODE01 |
0 |
up |
1 |
In my proposed solution, I will drive the logic using the owner node for Server4\SQL01 but, of course I will need to recognize the owner node of Server5\SQL02 as well because I do not want the same subscriptions running on both SQL Server instances. I will provide the subscriptions logic job in a future article.
Install and Configure SSRS on Secondary Node
If SSRS is not installed on the secondary cluster node, as was the case for me, a couple of extra steps are required. Logged onto the secondary node, SQLServerNode02 in my case, you can run Setup.exe from the installation media, with one caveat: since this is a cluster, SQL Server will check to see if there is already an instance running in the cluster and if so the installation will fail with an “Existing clustered or cluster-prepared instance” error and you will need to exit the installation. To get around this issue all you have to do is run Setup.exe from the command line and bypass the check:
|
1 |
Setup.exe /SkipRules=StandaloneInstall_HasClusteredOrPreparedInstanceCheck /Action=Install |
This will initiate the install without the cluster instance check and will allow you to continue with the Reporting Services installation. This step assumes that you are familiar with installing a new Reporting Services native installation. If not, please refer to this link: https://msdn.microsoft.com/en-us/library/ms143711.aspx. Just remember that you will only need the “Reporting Services – Native” option and nothing else such as the Database Engine Services, and so on.
For the installation, I chose to install a new SSRS instance as opposed to adding features to existing instance. If I choose to add features to an existing instance this too would fail and you would be warned that the instance (SQL01 or SQL02) already exists and cannot be created. I created a new SSRS instance called SQL03. Only select “Reporting Services – Native” from the list of features in the installation steps, ensuring that you choose “Install Only” in the Native Mode options.
Once SSRS is installed on SQLServerNode02, you can run Reporting Services Configuration Manager on that node and connect to the new SSSRS instance, as Figure 9 shows.
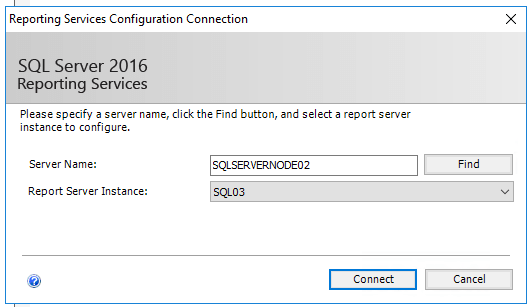
Figure 9 – Connecting to Secondary SSRS instance SQL03 on SQLServerNode02
I will follow the same steps that I did for SQL01 previously, with the only difference being to point to the ReportServer database that was restored to Server5\SQL02, as shown in Figure 10.
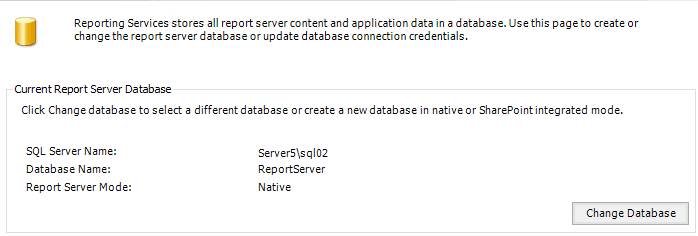
Figure 10 – Pointing to the Secondary ReportServer database on Server5\SQL02.
I will also restore the same encryption key backup file that I did for SQL01. The Web Portal URL will be http://SQLServerNode02/reports as you can see in Figure 11.
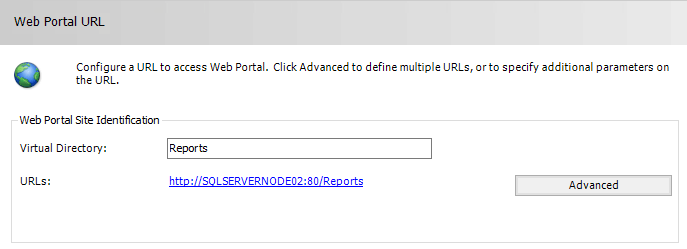
Figure 11 – Web Portal URL on SQLServerNode02
Once everything is successfully configured, I can open the Web Portal on SQLServerNode02 directly and verify that the same reports are there, remembering that as of now the two ReportServer databases should contain identical data. You should see all of the same folders and reports. All of the encrypted content like saved passwords for data sources will have been maintained thanks to restoring the encryption keys. This is easily verified by running several reports.
Testing Failover
At this point, it is safe to fail Server4\SQL01 on SQLServerNode01 over to SQLServerNode02, using Failover Cluster Manager. If you are unfamiliar with this task, please refer to the following link: https://technet.microsoft.com/en-us/library/cc754577(v=ws.11).aspx.
The Web Portal on SQLServerNode02 has already been configured to accept connections with the only difference being that it is using the ReportServer database from Server5\SQL02, which is still present on SQLServerNode01. The beautiful part of this solution is that, assuming the ReportServer databases are kept synchronous, this failover will be invisible to the users, as they will still use the URL http://Server4/Reports.
The cluster services will take care of updating DNS to redirect to the new primary node; The SSRS Web application, which are not cluster aware, will just come along for the ride. Figure 12 shows the Portal connected to Server5\SQL02 ReportServer database. You can also see the identifying _SQLServerNode02 folder that I use for verification.
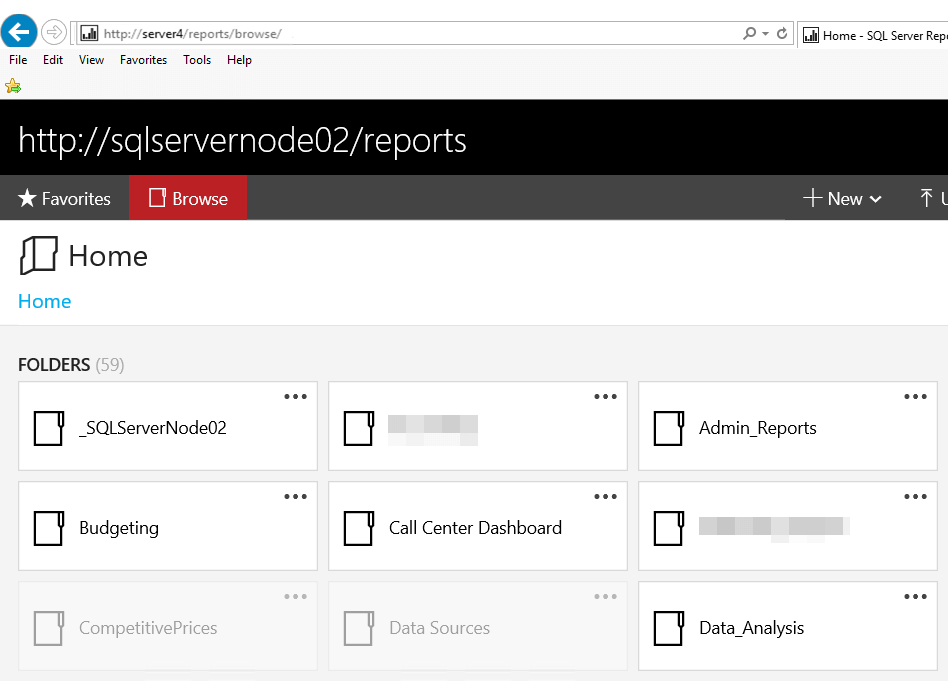
Figure 12 – Portal display connected to SQLServerNode02 with same virtual URL
Keeping the ReportServer databases in sync
From time to time, it would be worthwhile to do a sanity check on the two databases to ensure they are indeed being kept in sync. To do this, I registered both SQL Server instances in Registered Server in SSMS and ran the query below against both ReportServer databases using the multi-query capabilities of SSMS. If you would like to learn more about this feature, please refer to this link: https://msdn.microsoft.com/en-us/library/bb964743.aspx.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT DISTINCT CASE WHEN cat.Type = 1 THEN 'Folder' WHEN cat.Type = 2 THEN 'Report' WHEN cat.Type = 3 THEN 'File' WHEN cat.Type = 4 THEN 'Linked Report' WHEN cat.Type = 5 THEN 'Datasource' WHEN cat.Type = 6 THEN 'Model' WHEN cat.Type = 7 THEN 'ReportPart' WHEN cat.Type = 8 THEN 'Shared Dataset' ELSE 'Not Known' END AS ItemType , COUNT(DISTINCT cat.ItemID) AS CountReportExec FROM Catalog cat GROUP BY CASE WHEN cat.Type = 1 THEN 'Folder' WHEN cat.Type = 2 THEN 'Report' WHEN cat.Type = 3 THEN 'File' WHEN cat.Type = 4 THEN 'Linked Report' WHEN cat.Type = 5 THEN 'Datasource' WHEN cat.Type = 6 THEN 'Model' WHEN cat.Type = 7 THEN 'ReportPart' WHEN cat.Type = 8 THEN 'Shared Dataset' ELSE 'Not Known' END; |
The results in Figure 13 tell me that I have one more report on Server5\SQL02 than I do on Server4\SQL01 and 4 more “Not Known” items. It looks like I have some work to do to hunt down these differences, which I will be doing for the next installment of this solution.
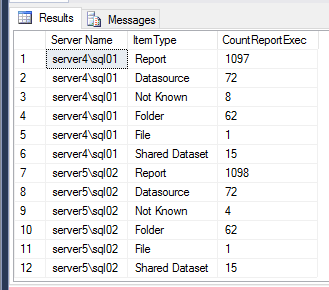
Figure 13 – Running code to find differences in both ReportServer databases simultaneously
Summary and Next Steps
This solution for scaling out SSRS on SQL Server Standard Edition, at first a theory, has proven in a very short time to be practical and tested alternative to Enterprise Edition’s scale out feature, despite some additional administration and automation required.
I have a bit more work to do for subscriptions and report synchronization over the next couple of weeks. The next installment will show how to build a scheduled job to check report synchronization and alert the DevOps team with details of any discrepancies so that they can deploy missing reports. I plan to include the ModifiedDate field as well to find objects that exist in both databases but may have a newer version of the report deployed.
I will also add logic to enable and disable subscription based on the primary node. It is well worth the minimal effort required.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments