
When faced with having to import data directly into SQL Server from a client application, you have a number of choices. You can use bulk copy (bcp), insert the data with a series of INSERT statements, use a parameterized prepared statement from the client, or call a stored procedure with the data passed as a parameter. From that stored procedure, you’ll probably want to insert the data into a table by using statements that insert several rows at a time.
I wanted to find the best way to import data into SQL Server, so I decided to experiment with a couple of different data load methods to compare the results. I had to address some questions to make sure the experiments would produce the quickest times. What’s the best way to use statements that insert several rows at a time, and how many rows should I try to pass at a time? For performance, should they be wrapped in explicit transactions or should I use auto-commit? How do I pass the parameters to the stored procedure? Which is the best, and fastest, approach?
In this article I’ll describe how I experimented and adjusted my methods to find the best way to insert a million of rows of data into SQL Server.
The background
The more data you’re dealing with, the more important it is to find the quickest way to import large quantities of data.
Last year, I participated in an Extract, Transform, Load (ETL) project. My task was to load data from a large comma-delimited file. This file had 220,000 rows, each of which had 840 delimited values and it had to be turned into 70 million rows for a target table. In all, about 184 million rows had to be processed. This file type was the largest in the project. The ETL project task was to create a payment projection for a period of 70 to 100 years. A line in the file consisted of an object identifier and its payments for decades.
The sizes of other file types were 30 times smaller, and we successfully used Informatica PowerCenter 9 to parse, validate, transform, and load the files into a staging table in SQL Server. Once the files were loaded, we were able to run sophisticated queries to calculate statistics and then load them into relational tables.
After developing a prototype based on Informatica, we decided to use PowerCenter 9 for workflow control and supplemented this with SQL Server stored procedures for parsing, validating and inserting the data. We wanted to reduce the time spent on the loading process (16 hours), and by using stored procedures, we could now calculate some statistics with incrementing counters in the loop. Also, we were able to implement a business rule which stated that the number of values in a file line was a variable between 840 (12 months * 70 years) and 1200 (12 months * 100 years). The first prototype powered by Informatica had 840 fixed mappings (Informatica objects). By using stored procedures with a parameter, we were able to insert variable numbers of values from each row as required.
First steps
I started evolving my solution by loading data into a staging table that had two columns: row number and delimited text. The target table had a heap structure with seven columns without indexes or constraints. I then created a procedure that built a loop that parsed the data and inserted it into the target table. The following pseudo code describes it.
while … begin
get parsed data into variables @c1,@c2…@c7
insert into TargetTable(c1,c2,..c7) values(@c1,@c2…@c7);
for explicit transaction control, each 10,000 inserts were wrapped into transaction
end
This first approach to the problem doubled the speed of the prototype powered by Informatica, but we were itching to make it fast, so we set up parallel loading. We were going to split the staging data into two parts and process each part in parallel. We had enough server resources for two parallel processes, so we just needed to add two parameters in a procedure to assign the starting row and the ending row of the staging table, and implement parallel calls of procedures in the Informatica workflow.
Before implementing parallel loading we wanted to find a simple way to speed up the INSERT performance of our procedure, something small that made a big difference – multiple rows insert. Instead of calling a single row insert, I sent five rows in the one statement. This change reduced execution time by 40%, which meant hours in my case. The changed pseudo code was:
while … begin
get parsed data into variables @c1_1,@c1_2, @c1_3,…@c5_6, @c5_7,
insert into TargetTable(c1,c2,..,c7)
values(@c1_1,@c1_2…@c1_7),
(@c2_1,@c2_2…@c2_7),
(@c3_1,@c3_2…@c3_7),
(@c4_1,@c4_2…@c4_7),
(@c5_1,@c5_2…@c5_7);
for explicit transaction control, every 2000 inserts were wrapped into a transaction
end
After implementing multiple rows insert and parallelization, the full time of loading and processing the file was reduced to two hours and forty-five minutes. The total time included all the ETL operations, loading a staging table, statistics calculation and index creation. We engaged two parallel processes and it consumed about 60% of the server resources, so users could still load files of other types at the same time.
I was intrigued by the multiple rows insert method of loading data, and wondered whether I could have improved the performance by doing it a different way. Later, I had time to investigate the pros and cons of this method and compared multiple rows insert with other data load methods: the single row insert, bulk copy performance (bcp) and procedure with TVP (table value parameter).
Testing environment description
To compare data-load methods, I chose a common example of a client program loading data. The client applications were written with C# .Net 4. The database platform was SQL Server 2008 R2. The database and the client applications were placed on the same personal computer (Lenovo ThinkCentre M90, Windows XP).
Comparing single row insert verses multiple rows insert
The feature, Inserting Multiple Rows Using a Single INSERT...SELECT VALUES statement, appeared in MS SQL Server 2008.
An example of inserting multiple rows:
Insert into t2(c1,c2) values(1,’A’),(2,’B’),(3,’C’);
which is equivalent to
insert into t2(c1,c2) select 1,’A’ union all select 2,’B’ union all select 3,’C’;
which was valid in previous versions.
To investigate the performance difference between the single row insert and multiple rows insert, I created a program which dynamically formed an INSERT statement for a given number of rows. I ran a set of tests wrapping 1, 2,5, 10, 25, 50, 100, 200, 500, 1000 rows in a single INSERT statement, trying to determine the number of rows in one INSERT...SELECT VALUES statement that should be used to get the best performance.
The test program loaded one million rows into the target table using a prepared parameterized INSERT statement and explicit transaction control. Every 10,000 statements were wrapped in a transaction.
The target table had the following structure:
|
1 2 3 4 |
CREATE TABLE [dbo].[t2]( [c1] [int] NULL, [c2] [varchar](10) NULL ) |
The test results are presented in Image 1 and Image 2.
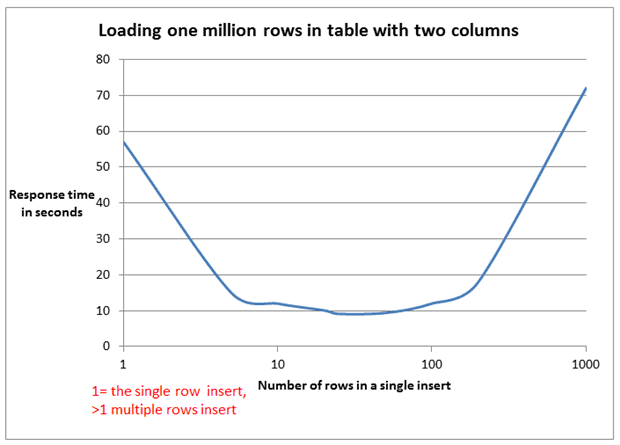
Image 1
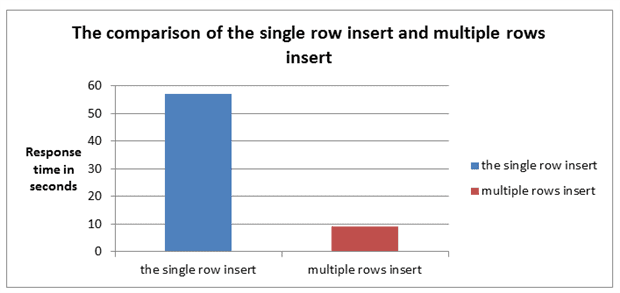
Image 2
In the experiment where the only variable was the number of rows per INSERT statement (Image 1), we see that the best performing number of rows was 25 per INSERT statement, which loaded one million rows in 9 seconds. In contrast, single row insert took 57 seconds to load one million rows.
Number of columns and multiple rows insert
To investigate the influence the number of columns has on performance, I made an additional set of tests for tables with seven, ten and 23 columns. I ran tests wrapping one, two, five, ten, 25, 50, and 100 rows in a single insert statement (abandoning the 500 and 1000 row tests). During every test, I loaded a million rows into a table. I varied the number of columns while keeping the length in bytes of the rows constant.
Tables had the structure:
|
Table Name |
Column Number |
Structure |
|
t2 |
2 |
C1 int, C2 varchar(10) |
|
t7 |
7 |
U1 uniqueidentifier, U2 uniqueidentifier, I1 int, I2 int, d1 datetime, I3 int, I4 int |
|
t10 |
10 |
t7 structure plus 3 varchar(200) columns |
|
t23 |
23 |
t7 structure plus 15 varchar(40) |
Table 1
The test results are presented in Image 3 and Image 4.
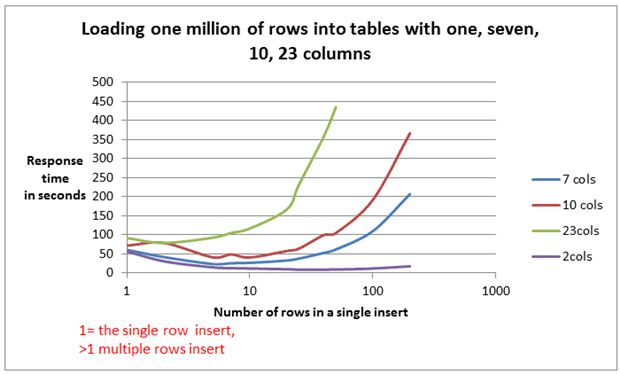
Image 3
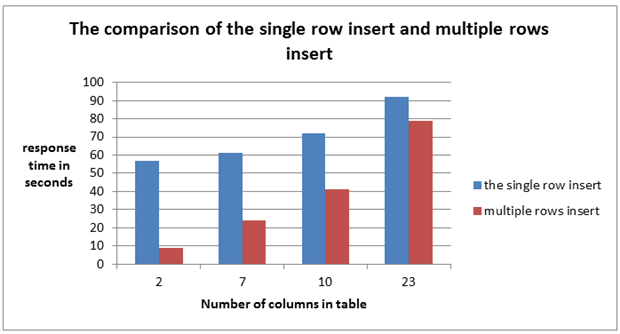
Image 4
As you can see, the difference between the single row insert and multiple rows insert response times decreased as the number of columns increased. With 23 columns, the best result shown by multiple rows insert was almost the same as the single row insert. The speed difference is shown on Image 5.
Speed difference is calculated by dividing the single row insert results (57 seconds in the case of a two-column table) by the multiple rows result (9 seconds in the case of a two-column table). In this example, the multiple rows insert operation was more than 6 times faster than the single row insert operation.
See Table 2 for the full results.
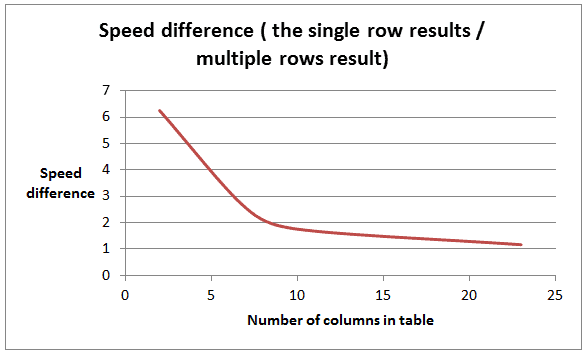
Image 5
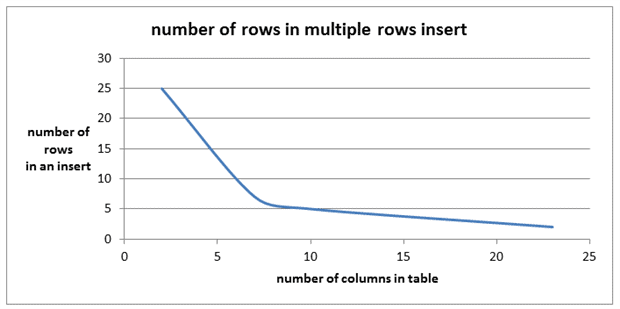
Image 6
In the case with the 23 columns table, inserting only 2 rows in a single statement brought the most performance improvement. No other performance improvement was evident.
|
Number of columns in a table |
2 |
7 |
10 |
23 |
|
Speed difference (single row results /multiple rows result) |
6.25 |
2.56 |
1.75 |
1.16 |
|
the single row results in seconds |
57 |
61 |
72 |
92 |
|
multiple rows insert results in seconds |
9.125 |
23.8 |
41 |
79 |
|
Number of rows in an insert |
25 |
5 |
5 |
2 |
Table 2
It looks like the number of columns in a table was a limitation for this type of insert optimization.
Problem analysis
The results of the previous tests raised questions: “How do we explain the performance degradation in the case of columns number growth?” and “How do we minimize this effect?”
I selected three factors that I believe affected response time and tried to investigate their influence on the result.
|
Factor |
Suggested Influence |
|
Round trips |
A statement invocation on server takes time. The more rows are wrapped into a single |
|
Number of parameters in a statement |
Parameter binding, sending and parsing takes time. The more parameters we use the more time is spent on binding and parsing on server side. |
|
Insert operation time |
Clear time of insert without time spent in sending, binding and parsing parameters. The more rows are wrapped into a single |
Table 3
My idea was to understand how much time we spent sending, binding and parsing data and how long the INSERT operation took.
I used a trick to gauge how long the INSERT operation took. I created a copy of the program that sent the same data to the server but did not execute the INSERT statements. I wanted to compare the results shown by program that sent data and executed INSERT statements with the results of the program that just sent data.
For comparison, I took the results of the first test with a two column table. The results of both programs are presented in Image 7. To calculate the INSERT operation time, I subtracted the results of the program without INSERT from the program executing INSERT.
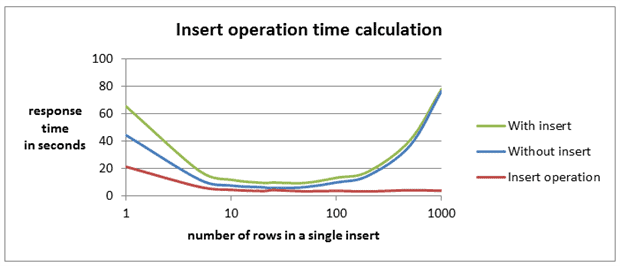
Image 7
Through multiple rows optimization, the INSERT operation time was reduced from 21 seconds to three seconds, and there was no degradation. When a single INSERT contained more than 100 rows, the results of a program with INSERT and without INSERT became very similar. Both programs spent a lot of time in sending, binding and parsing data.
The best result for multiple rows insert was 9 seconds (25 rows per insert), and only 4 seconds were spent inserting data. During the test with the single row insert, the total time was 56 seconds, 21 of which were spent executing INSERT and 24 seconds on sending and binding.
When increasing the number of rows in a single statement from one to 1000, the sum of round trips and parameter binding time decreased, but with 100 rows in a single INSERT it began to increase. To insert 100 rows in one statement I used 200 parameters. It’s likely that the positive effect of decreasing the round trip time was negated by the parameter binding and parsing. In my testing environment, the number of parameters in a statement should be between 100 and 200. When the number of parameters was above 200, serious response time degradation was observed. The program without INSERT shows that this effect relates not only to multiple rows insert, but to any statement with parameters including stored procedures.
In my test programs the number of parameters was the main limitation. The most significant amount of time was spent on parameter processing.
Problem minimization
To minimize the influence of the number of parameters, I decided to try and use parameters more efficiently.
I took the case which had shown the worst result: the table with 23 columns (t23). I put all the 23 values into one string variable where every field had a fixed length. Instead of sending 23 parameters for each row I sent one in the form of string. I repeated a set of tests wrapping one, two, five, 10, 25, 50, 100 rows in a single INSERT statement. To get certain column value during execution of INSERT I used substring operator, I called this method “sub stringed multiple insert”.
The INSERT statement for three rows in a single statement looked like this:
Table structure:
U1 uniqueidentifier, U2 uniqueidentifier,I1 int, I2 int, d1 datetime, I3 int, I4 int, 15 columns varchar(40);
Step A. Put 23 values in to a string variable for every row using concatenation (“+”)
Declare @s1 varchar(..)= [column 1] value + … [column 23] value;
Declare @s2 varchar(..)= [column 1] value + … [column 23] value;
Declare @s3 varchar(..) = [column 1] value + … [column 23] value;
Step B. Insert data using substring.
Insert into t23(c1,c2,..c23) values
(substring(@s1,1,32), substring(@s1,33,32), …. substring(@s1,xx,40) ), –1st row
(substring(@s2,33,32), substring(@s2,33,32), …. substring(@s2,xx,40) ),– 2nd row
(substring(@s3,33,32), substring(@s3,33,32), …. substring(@s3,xx,40) ),– 2nd row
Using “sub stringed multiple insert” I managed to reduce the multiple rows insert results from 79 seconds to 37 seconds for the table with 23 columns.
The results produced by the single row insert, multiple rows insert and “sub stringed multiple insert” for tables with a different number of columns are presented on Image 8.
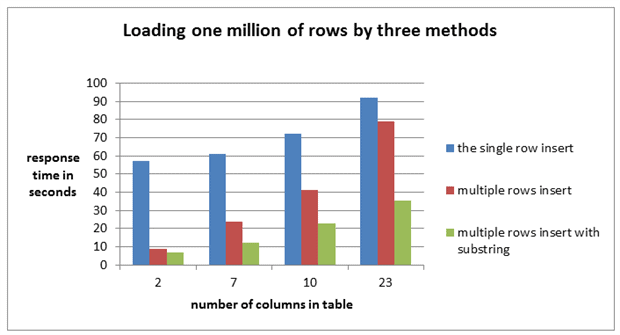
Image 8
“Sub stringed multiple insert” supported my hypothesis about the main limitation. After minimizing the number of parameters, the result was improved in spite of spending additional CPU resources to perform substring operation.
Comparison of multiple insert method with bcp, TVP procedure and single row insert
Finally, I decided to compare multiple rows insert with other data load methods. I used bcp utility, the procedure with INSERT from TVP, the single row insert and “sub stringed multiple insert”. I completed two sets of tests. In the first set, I loaded one million rows, in the second one, 10 million. I took the tables with different numbers of columns which I had used in the previous tests. In these tests, I wanted to define the influence of the number of columns on insert speed for all the methods. The results of the tests are shown in Image 9 and Image 10.
Tables had the same structure as before.
In the tests, I filled character columns completely according to its full size.
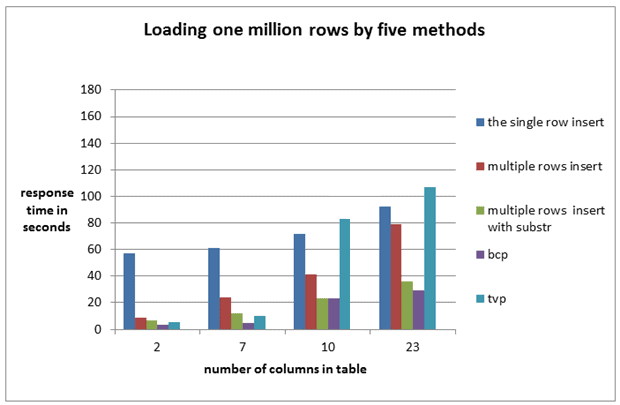
Image 9
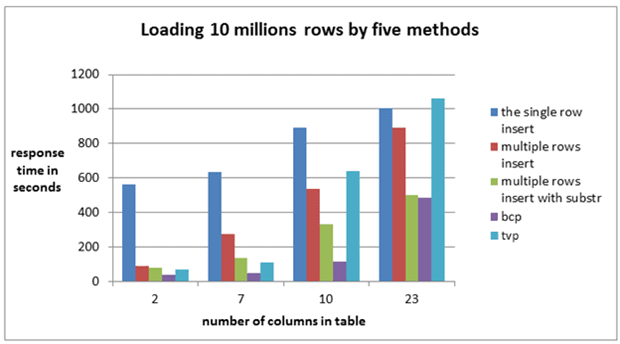
Image 10
All the methods suffered from increasing the number of columns.
The length (in bytes) of each row for the table with ten columns was equal to the twenty-three column table. Performance for the twenty-three column table was significantly longer.
Bulk copy utility (bcp) was the fastest data load method and “Sub stringed multiple rows insert” was a close second. Multiple rows insert was faster than the single row insert and faster than TVP in two of the four cases.
Conclusion
In order to minimize execution time when you are loading data, it is better to insert several rows at once using INSERT... VALUES. Even by inserting two rows in a single statement you can reduce the execution time over single row insert.
For the single row and multiple row insert, good performance is possible only if you use explicit transactions. Wrap 1000-5000 statements into a transaction. Don’t use auto-commit!
Even though you can have 1000 rows in a single INSERT... VALUES statement, doesn’t mean you should. I got the best results with a relatively small number of rows in a single INSERT: two, five, seven and 25 rows worked best.
The more columns you have in a table, the lower the effectiveness of INSERT optimization . With 23 columns, the advantage almost vanished. This was due to the fact that the time spent parameter binding and parsing dwarfed any saving in inserting several rows in one statement. Be careful using parameterized statements with a large number of parameters (more > 100), not just with multiple rows insert, but with all the statement types including stored procedures. Such is the slowness of parameter binding that it was quicker to put all the values for one row into one delimited string and sending it in one parameter instead of several. This, combined with multiple rows and using the substring function to get values back, could improve data load speed.
Now that I’ve completed 45 different experiments, here’s what I’ve learned: The fastest method to load data into SQL Server is bcp, with “sub stringed multiple rows insert” as a close second; multiple row insert consistently outperformed single row insert; and the number of columns involved in the insertion of a table was a serious limitation for all the methods.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments