
If we want to predict how well a query will perform as a result of adding a new index on the table, we need to wait while the index is created before we can test it. On larger tables, the creation of the index can take a significant amount of time and if you are trying a number of alternative indexing strategies, the wait can become very tedious. Furthermore, it is a common frustration to find that, after waiting for many minutes for the creation of the index, you realize that it is not using the index when you go to look at the query plan.
So wouldn’t it be nice if we could try a hypothetical index just to test if the index really will be useful for the query. That is possible, but not straightforward; The reason that the technique exists is that it is used by the DTA (Database Tuning Advisor) to recommend a missing index. In this article I’ll present you some undocumented commands that are used to do it.
Creating a hypothetical index
There is a special syntax of the CREATE INDEX command that allows us to create a hypothetical index. This is an index that creates the metadata of the index on sysindexes and a statistic associated to the index, but does not create the index itself.
Suppose we have the following query from AdventureWorks2012 database:
|
1 2 3 |
SELECT SalesOrderID, OrderDate, Status, TerritoryID FROM Sales.SalesOrderHeader WHERE OrderDate = '20050701' |
If we want to create a hypothetical index on SalesOrderHeader table we could run:
|
1 |
CREATE INDEX ixOrderDate ON Sales.SalesOrderHeader (OrderDate) WITH STATISTICS_ONLY = -1 |
The relational index option STATISTICS_ONLY = -1, which is undocumented, means that the index itself will not be created, but only the statistic associated with the index. This index be neither considered nor used by the query optimizer unless you run a query in AUTOPILOT mode.
DBCC AUTOPILOT and AUTOPILOT MODE
There is command called “SET AUTOPILOT ON” used to enable support to hypothetical indexes, and this is used with other DBCC command called “DBCC AUTOPILOT“.
First let’s see them working together and then I’ll give you more details about it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT dbid = DB_ID(), objectid = object_id, indid = index_id FROM sys.indexes WHERE object_id = OBJECT_ID('Sales.SalesOrderHeader') AND is_hypothetical = 1 /* Results: |dbid |objectid |indid | |8 |1266103551 |15 | */ -- Use typeId 0 to enable a specifc index on AutoPilot mode DBCC AUTOPILOT(0, 8, 1266103551, 15) GO SET AUTOPILOT ON GO SELECT SalesOrderID, OrderDate, Status, TerritoryID FROM Sales.SalesOrderHeader WHERE OrderDate = '20050701' GO SET AUTOPILOT OFF |
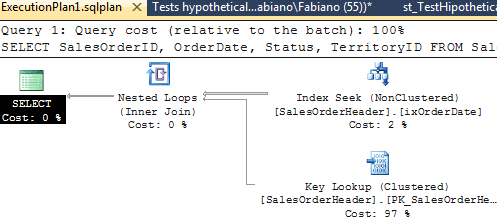
When running on autopilot mode, SQL Server doesn’t execute the query but it returns an estimated execution plan that considers all indexes enabled by DBCC AUTOPILOT command, including the hypothetical ones.
DBCC AUTOPILOT
There are a few things you could do with this command, first let’s find out what the syntax is. We can find out the syntax of all undocumented commands by using the trace flag 2588 and then running DBCC HELP to see:
|
1 2 |
DBCC TRACEON (2588) DBCC HELP('AUTOPILOT') |
|
1 |
DBCC AUTOPILOT (typeid [, dbid [, {maxQueryCost | tabid [, indid [, pages [, flag [, rowcounts]]]]} ]]) |
Making AUTOPILOT easier to use
The parameters that you have to use are not straightforward. This means that, if you are working with a query with lots of tables, it can get boring to write all the DBCC AUTOPILOT commands and this might discourage you from using it. Because of this, I’ve created a procedure to make it a little easier to use.
Originally I created this procedure after answering a student’s question about how to make it easier to use hypothetical indexes on SQL Server. So I thought you may like it.
Unfortunately it relies on a CLR stored procedure to SET the AUTOPILOT, but if you don’t mind to use it in a develop environment (which is something normal to do) then you can use it, following is the CLR code, and if you are interested you can download the project code here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
-- CLR Proc /* using System; using System.Data; using System.Data.SqlClient; using System.Data.SqlTypes; using Microsoft.SqlServer.Server; public partial class StoredProcedures { [Microsoft.SqlServer.Server.SqlProcedure] public static void CLR_GetAutoPilotShowPlan ( SqlString SQL, out SqlXml PlanXML ) { //Prep connection SqlConnection cn = new SqlConnection("Context Connection = True"); //Set command texts SqlCommand cmd_SetAutoPilotOn = new SqlCommand("SET AUTOPILOT ON", cn); SqlCommand cmd_SetAutoPilotOff = new SqlCommand("SET AUTOPILOT OFF", cn); SqlCommand cmd_input = new SqlCommand(SQL.ToString(), cn); if (cn.State != ConnectionState.Open) { cn.Open(); } //Run AutoPilot On cmd_SetAutoPilotOn.ExecuteNonQuery(); //Run input SQL SqlDataAdapter da = new SqlDataAdapter(); DataSet ds = new DataSet(); da.SelectCommand = cmd_input; ds.Tables.Add(new DataTable("Results")); ds.Tables[0].BeginLoadData(); da.Fill(ds, "Results"); ds.Tables[0].EndLoadData(); //Run AutoPilot Off cmd_SetAutoPilotOff.ExecuteNonQuery(); if (cn.State != ConnectionState.Closed) { cn.Close(); } //Package XML as output System.Xml.XmlDocument xmlDoc = new System.Xml.XmlDocument(); //XML is in 1st Col of 1st Row of 1st Table xmlDoc.InnerXml = ds.Tables[0].Rows[0][0].ToString(); System.Xml.XmlNodeReader xnr = new System.Xml.XmlNodeReader(xmlDoc); PlanXML = new SqlXml(xnr); } }; */ |
And following is the code to compile it on SQL Server and to create another procedure to simulate the hypothetical indexes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
-- Enabling CLR sp_configure 'clr enabled', 1 GO RECONFIGURE GO -- Publishing Assembly IF EXISTS(SELECT * FROM sys.assemblies WHERE name = 'CLR_ProjectAutoPilot') BEGIN IF OBJECT_ID('st_CLR_GetAutoPilotShowPlan') IS NOT NULL DROP PROC st_CLR_GetAutoPilotShowPlan DROP ASSEMBLY CLR_ProjectAutoPilot END GO CREATE ASSEMBLY CLR_ProjectAutoPilot FROM 'C:\Fabiano\ ProjectAutoPilot\ProjectAutoPilot\bin\Release\ProjectAutoPilot.dll' WITH PERMISSION_SET = SAFE GO CREATE PROCEDURE st_CLR_GetAutoPilotShowPlan (@Query NVarChar(MAX), @ShowPlan XML OUTPUT) AS EXTERNAL NAME CLR_ProjectAutoPilot.StoredProcedures.CLR_GetAutoPilotShowPlan GO IF OBJECT_ID('st_TestHipotheticalIndexes', 'p') IS NOT NULL DROP PROC dbo.st_TestHipotheticalIndexes GO CREATE PROCEDURE dbo.st_TestHipotheticalIndexes (@SQLIndex NVarChar(MAX), @Query NVarChar(MAX)) AS BEGIN SET NOCOUNT ON; BEGIN TRY BEGIN TRAN DECLARE @CreateIndexCommand NVarChar(MAX), @IndexName NVarChar(MAX), @TableName NVarChar(MAX), @SQLIndexTMP NVarChar(MAX), @SQLDropIndex NVarChar(MAX), @SQLDbccAutoPilot NVarChar(MAX), @i Int, @QuantityIndex Int, @Xml XML IF SubString(@SQLIndex, LEN(@SQLIndex), 1) <> ';' BEGIN RAISERROR ('Last character in the index should be ;', -- Message text. 16, -- Severity. 1 -- State. ); END SET @SQLDropIndex = ''; SET @QuantityIndex = LEN(@SQLIndex) - LEN(REPLACE(@SQLIndex, ';', '')) SELECT @SQLIndexTMP = SUBSTRING(@SQLIndex, 0, CharIndex(';', @SQLIndex)) SET @i = 0 WHILE @i < @QuantityIndex BEGIN SET @SQLIndexTMP = SUBSTRING(@SQLIndex, 0, CharIndex(';', @SQLIndex)) SET @CreateIndexCommand = SUBSTRING(@SQLIndexTMP, 0, CharIndex(' ON ',@SQLIndexTMP)) SET @IndexName = REVERSE(SubString(REVERSE(@CreateIndexCommand), 0, CharIndex(' ', REVERSE(@CreateIndexCommand)))) SET @TableName = SUBSTRING(REPLACE(@SQLIndexTMP, @CreateIndexCommand + ' ON ', ''), 0, CharIndex(' ', REPLACE(@SQLIndexTMP, @CreateIndexCommand + ' ON ', ''))) SET @SQLIndex = REPLACE(@SQLIndex, @SQLIndexTMP + ';', '') --SELECT @SQLIndex, @SQLIndexTMP, @CreateIndexCommand, @TableName, @IndexName -- Creating hypotetical index IF CharIndex('WITH STATISTICS_ONLY =', @SQLIndexTMP) = 0 BEGIN SET @SQLIndexTMP = @SQLIndexTMP + ' WITH STATISTICS_ONLY = -1' END -- PRINT @SQLIndexTMP EXEC (@SQLIndexTMP) -- Creating query to drop the hypotetical index SELECT @SQLDropIndex = @SQLDropIndex + 'DROP INDEX ' + @TableName + '.' + @IndexName + '; ' -- PRINT @SQLDropIndex -- Executing DBCC AUTOPILOT SET @SQLDbccAutoPilot = 'DBCC AUTOPILOT (0, ' + CONVERT(VarChar, DB_ID()) + ', '+ CONVERT(VarChar, OBJECT_ID(@TableName),0) + ', ' + CONVERT(VarChar, INDEXPROPERTY(OBJECT_ID(@TableName), @IndexName, 'IndexID')) + ')' EXEC (@SQLDbccAutoPilot) --PRINT @SQLDbccAutoPilot SET @i = @i + 1 END -- Executing Query DECLARE @PlanXML xml EXEC st_CLR_GetAutoPilotShowPlan @Query = @Query, @ShowPlan = @PlanXML OUT SELECT @PlanXML -- Droping the indexes EXEC (@SQLDropIndex) COMMIT TRAN END TRY BEGIN CATCH ROLLBACK TRAN -- Execute error retrieval routine. SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_SEVERITY() AS ErrorSeverity, ERROR_STATE() AS ErrorState, ERROR_PROCEDURE() AS ErrorProcedure, ERROR_LINE() AS ErrorLine, ERROR_MESSAGE() AS ErrorMessage; END CATCH; END GO |
The stored procedure st_TestHipotheticalIndexes expects two input parameters:
- @SQLIndex: Here you should specify the command to create the index that you want to try (the hypothetical indexes), if you want to try more than one index, just call it separating many “create index” commands by a semicolon. For instance:
|
1 |
@SQLIndex = 'CREATE INDEX ix_12 ON Products (Unitprice, CategoryID, SupplierID) INCLUDE(ProductName);CREATE INDEX ix_Quantity ON Order_Details (Quantity);', |
- @Query: Here you should write the query you want to try.
Here is a sample of how to call it:
|
1 2 |
EXEC dbo.st_TestHipotheticalIndexes @SQLIndex = 'CREATE INDEX ix ON Order_Details(Quantity);', @Query = 'SELECT * FROM Order_Details WHERE Quantity < 1' |
The results of the query above is an XML datatype with the query plan considering the suggested index:
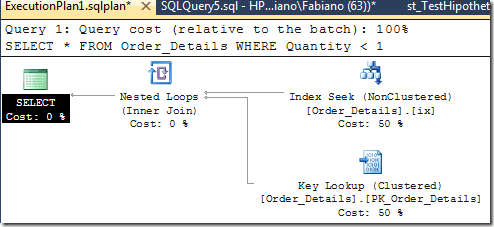
Another sample:
|
1 2 |
-- Sample 2 EXEC dbo.st_TestHipotheticalIndexes @SQLIndex = 'CREATE INDEX ix_12 ON Products (Unitprice, CategoryID, SupplierID) INCLUDE(ProductName);CREATE INDEX ix_Quantity ON Order_Details (Quantity);', @Query = 'SELECT p.ProductName, p.UnitPrice, s.CompanyName, s.Country, od.quantity FROM Products as P INNER JOIN Suppliers as S ON P.SupplierID = S.SupplierID INNER JOIN order_details as od ON p.productID = od.productid WHERE P.CategoryID in (1,2,3) AND P.Unitprice < 20 AND S.Country = ''uk'' AND od.Quantity < 90' |
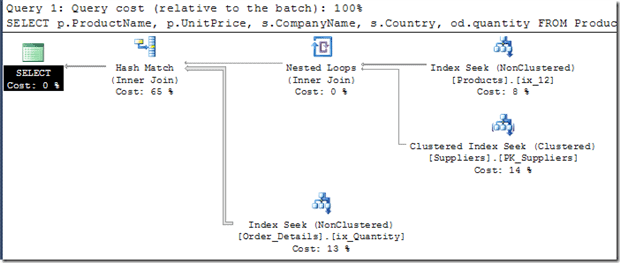
Now it is easier to try out the effect of various indexes. Let me know what do you think and please don’t mind the clumsy code in the procedure to get the tablename, indexname.
Conclusion
There is a lot of mystery about these undocumented features, but I’m sure this will be enough to get you started with doing tests using Hypothetical indexes. I am sure I don’t need to tell you not to use this is in production environment do I? This is undocumented stuff, so nobody can guarantee what it is really doing, and the side-effects unless Microsoft chooses to make it officially public and documented.
That’s all folks.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments