
Most of us in the industry are aware of the dangers of poor database design yet overlook them in real-world databases. Harmful design flaws often go unnoticed. In some cases, the limitations of the DBMS or the SQL language itself may contribute to the problem. In others, it may be the inexperienced database designers who pay more attention to writing fanciful code but fail to focus on having a good data model.
To put it simply, database design is the process of translating facts about part of the real world into a logical model. This model can then be implemented, and is usually done so with a relational database. While it is true that relational databases have the solid foundation of logic and set-based mathematics, the scientific rigor of the database design process also involves aesthetics and intuition; but it includes, of course, the subjective bias of the designer as well. But how far does this affect the design? In this article, I’ll try to explain five common design errors people make while modelling tables and suggest some guidelines on how to avoid them.
(1) Common Lookup Tables
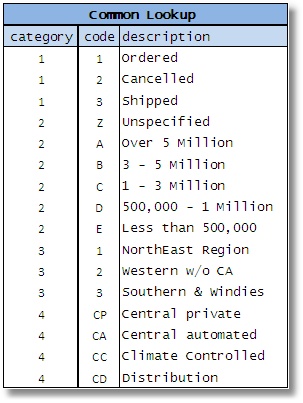
Figure 1
A few years back, Don Peterson wrote an article for SQL Server Central that detailed a common practice of creating a single lookup table for various types of data usually called as code table or an “allowed value table” (AVT). These tables tend to be massive and have a pile of unrelated data. Appropriately enough, Don called these tables Massively Unified Code-Key (MUCK) tables (Peterson, 2006) Though many others have written about it over the years, this name seems to capture most effectively the clumsiness associated with such a structure.
In many cases, the data in these tables are VARCHAR(n) though the real data type of these values can be anything ranging from INTEGER to DATETIME. They are mostly represented in three columns that may take some form of the sample table (Figure 1):
The justification here is that each entity in the example here has a similar set of attributes and therefore it is okay to cram it to a single table. After all, it results in fewer tables, keep the database simpler, right?
During the design process, the database designer may come across several small tables (in the example, these are tables that represent distinct types of entities such as ‘status of orders’, ‘priority of financial assets’, ‘location codes’, ‘type of warehouses’ etc.).
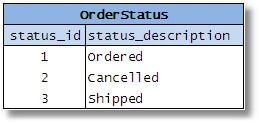
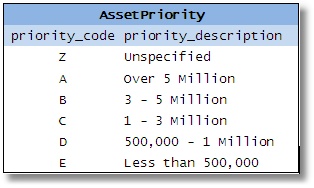
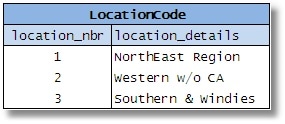

Figures 2-5
He then decides to combine them all because of the similarity of their columns. He assumes that he is eliminating redundant tables and simplifying the database; he will have fewer tables, he’ll save space, improve efficiency etc. People also assume that it reduces the complexity of the SQL required, because a single routine/stored procedure can be written to access any type of data.
So what is wrong with it?
- Firstly, you lose the means to ensure accurate data; constraints. By combining different entities into a single table, you have no declarative means to restrain values of a certain category. There is no easy way to enforce simple foreign key constraints without adding the categoryid in all the referencing keys.
- Secondly, you are forced to represent every data type as a string with this type of generic lookup table. Such intermingling of different types can be a problem, because check constraints cannot be imposed without major code-hacking . In the example we’ve given, if the discount code is CHAR(3) and location_nbr is INT(4), what should the data type of the ‘code’ column be in the Common Lookup table?
- Thirdly, you commit yourself to rigidity and subsequent complexity. You might be tempted to ask, how can such an apparently simple and flexible design be rigid? Well, considering our example of a common lookup table scheme, just imagine that the ‘LocationCode’ table includes another column which might be ‘region’. What about the consequences of adding a status to the ‘DiscountType’ table? Just in order to change a single category, you’ll have to consider making way for all the rows in the table regardless of whether the new column is applicable to them or not. What about complexity? Often the idea of using common lookup tables come from the idea of generalizing entities where by a single table represents a “thing” – pretty much anything.
Contrast this with the fundamental rule that a well-designed table represents a set of facts about entities or relationships of the same kind. The problem with generalizing entities is that a table becomes a pile of unrelated rows: Consequently, you then lose precision of meaning, followed by confusion and, often, unwanted complexity.
The main goal of a DBMS is to enforce the rules that govern how the data is represented and manipulated. Make sure you do not confuse the terms “generalize”, “reuse” etc. in the context of database design to the extent where you have no control over what is being designed. - Fourthly and finally, you are faced with the physical implementation issues. While logical design is considered to be totally separate from physical implementation, in commercial DBMS products like SQL Server, physical implementations can be influenced by logical design, and vice-versa. In large enterprises, such common lookup tables can grow to hundreds of thousands of rows and require heavy physical database tuning. Locking and concurrency issues with such large tables will also have to be controlled. The internal representation of a particular set of row in physical storage can be a determining factor in how efficient the values can be accessed and manipulated by SQL queries.
As a general recommendation, always use separate tables for each logical entity, identifying the appropriate columns with correct types, constraints and references. It is better to write simple routines and procedures to access and manipulate the data in the tables without aiming for “dynamic code”.
Common lookup tables have no place in sensible database design, whether used as a short-term makeshift fix or as a long-term viable solution. While application-enforced integrity is sometimes favored by developers, it remains true that the DBMS must still be the centralized enforcer of all integrity. Because the foremost goal in a given database design is to preserve data integrity and logical correctness, common lookup tables are one of the worst kind of mistakes that one can make..
(2) Check Constraint conundrum
Check Constraints serve several purposes, but cause trouble to designers in two ways:
- They miss declaring appropriate check constraints when it is necessary.
- They are unaware when to use a column level constraints rather than a table with a foreign key constraint.
Constraints in SQL Server can serve many different purposes, including support for domain constraints, column constraints and, to some extent, table constraints. A primary purpose of a database is to preserve data integrity, and well-defined constraints provide an excellent means to control what values are allowed in a column.
So then, should you ever avoid using a check constraint? Well, let’s consider the cases where a referencing table (a table with a foreign key) can be used to restrain the column with a specific set of values.

Figure 6
Here the values for ins_code in the PolicyHolders table can be restricted in two ways. One way would involve the use of a lookup table that holds the allowed values for ins_code. An alternative is to have a check constraint on the PolicyHolders table along the lines of:
|
1 |
CHECK ( ins_code IN ( 'IC', 'FS', 'MC', 'PPO', 'POS', 'HMO' ) ) |
So what is the rule of thumb in choosing the right approach? Old hands in database design look for three specific criteria to govern their choice between a check constraint or a separate table that has a foreign key constraint.
- If the list of values changes over a period of time, you must use a separate table with a foreign key constraint rather than a check constraint.
- If the list of values is larger than 15 or 20, you should consider a separate table.
- If the list of values is shared or reusable, at least used three or more times in the same database, then you have a very strong case to use a separate table.
Note that database design is a mix of art and science and therefore it involves tradeoffs. An experienced designer can make a trade-off, based on an informed judgment of the specific requirements.
(3) Entity-Attribute-Value Table
Ideally a table represents a set of entities, each of which has a set of attributes represented as columns. Sometimes, designers can get caught up in the world of alternative programming “paradigms” and might try to implement them. One such model is called Entity-Attribute-Value ( or in some contexts as object-attribute-model), which is a nickname for a table that has three columns, one for the type of entity it is supposed to represent, another for a parameter or attribute or property of that entity and a third one for the actual value of that property.
Consider the following example of a table that records data about employees:
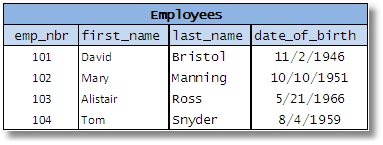
Fig 7
Now, the EAV approach shuffles up the data, in order to represent the attributes as values in one column and the corresponding values of those attributes in another column:
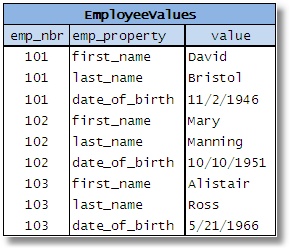
Fig 8
Taking this to the extreme, there is no need for additional tables — all data can be crammed into a single table! The credit to this invention goes to so called “clinical database” designers who decided that when various data elements are unknown, partially known or sparse it is best to use EAV (Nadkarni, 2002). The problem is that many newcomers get seduced into applying this approach in SQL databases and the results are usually chaos. In fact, many people assume that it is a good thing that they do not know the nature of data!
So what are the benefits that are touted for EAV? Well, there are none. Since EAV tables will contain any kind of data, we have to PIVOT the data to a tabular representation, with appropriate columns, in order to make it useful. In many cases, there is middleware or client-side software that does this behind the scenes, thereby providing the illusion to the user that they are dealing with well-designed data.
EAV models have a host of problems.
- Firstly, the massive amount of data is, in itself, essentially unmanageable.
- Secondly, there is no possible way to define the necessary constraints — any potential check constraints will have to include extensive hard-coding for appropriate attribute names. Since a single column holds all possible values, the datatype is usually VARCHAR(n).
- Thirdly, don’t even think about having any useful foreign keys.
- Finally, there is the complexity and awkwardness of queries. Some folks consider it a benefit to be able to jam a variety of data into a single table when necessary — they call it “scalable”. In reality, since EAV mixes up data with metadata, it is lot more difficult to manipulate data even for simple requirements. Consider a simple query to retrieve the employees who are born after 1950. In the traditional model, you’d have:
|
1 2 3 |
SELECT first_name, last_name FROM Employees WHERE date_of_birth > '12/31/1950' ; |
In a EAV model, here is one way to write a comparable query :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT MAX( CASE emp_property WHEN 'first_name' THEN value END ) AS first_name, MAX( CASE emp_property WHEN 'last_name' THEN value END ) AS last_name FROM EmployeeValues WHERE emp_nbr IN ( SELECT emp_nbr FROM EmployeeValues WHERE emp_property = 'date_of_birth' AND CAST( value AS DATETIME ) > '12/31/1950' ) AND emp_property IN ( 'first_name', 'last_name' ) GROUP BY emp_nbr ; |
Listing 1
For those who are handy at Transact-SQL, go ahead, add a few new columns with different data types and try out a few queries and see how much fun it can be!
The solution to the EAV nightmare is simple: Analyze and research the users’ needs and identify the data requirements up-front. A relational database maintains the integrity and consistency of data. It is virtually impossible to make a case for designing such a database without well-defined requirements. Period.
(4) Application Encroachments into DB design
There are several ways that an application can trespass on the field of data management. I’ll briefly explain a couple of ways and suggest some guidelines on how to prevent it.
Enforcing Integrity via applications
Proponents of application based integrity usually argues that constraints negatively impact data access. They also assume selectively applying rules based on the needs of the application is the best route to take.
Let us look at this in detail. Are there any good statistical measurements, comparisons and analyses exist to address the performance difference between the same rules enforced by the DBMS and the application? How effectively can an application enforce data related rules? If the same rules are required by multiple applications, can the duplication of code be avoided? If there is already an integrity enforcement mechanism within the DBMS, why reinvent the wheel?
The solution is simple.
Rely on nothing else to provide completeness and correctness except the database itself. By nothing, I mean neither users nor applications external to the database. While it may be true that current DBMS products may not succeed in enforcing all possible constraints, it is not sensible to let the application or user take over that responsibility.
You may ask why it is bad to rely on the application to enforce data-integrity? Well, if there is only one application per database, then it is not really an issue. But usually, databases act as the central repositories of data and serve several applications. Therefore, rules must be enforced across all these applications. These rules may change as well.
As a general guideline, databases are more than mere data repositories; they are the source of rules associated with that data. Declare integrity constraints in the database where possible, for every rule that should be enforced. Use stored procedures and triggers only where declarative integrity enforcement via keys and constraints isn’t possible. Only application-specific rules need to be implemented via the application.
Application Tail wagging the Database Dog:
There is a growing trend among the developer community to treat the database as being a mere component of the ‘application domain’. Often, tables are added as needed by the application developer and then columns are subsequently slapped in as an afterthought.
This is convenient because it avoids troublesome parts of the design process such as requirements-gathering.. Experience tells us that, in most enterprises, applications come and go, but databases usually stand for a long time. It therefore makes good sense to make the effort to develop a good design based on the rules that are specific to the business segment in context. (Teorey, 1994).
(5) Misusing Data values as Data Elements
Let’s just clarify something before proceeding further: a ‘data value’ here refers to the value of an attribute of an entity; a ‘data element’ refers to an unit of metadata such as a column name or a table name. By misusing data values as data elements I refer to the practice of splitting attribute values of a certain entity and representing it across several columns or tables. Joe Celko calls it exactly that — ‘attribute splitting’ (Celko, 2005).
Consider a table that represents the sales figures of some salesmen that work for a company. Let’s assume that the following design is adopted so as to make it easier to retrieve the data in order to display it:
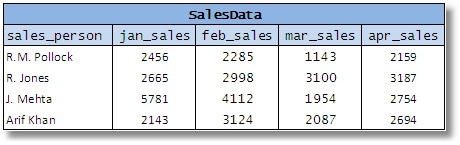
Figure 9
You’ll see here that a single attribute in the business model, the ‘sales amount’, is represented as a series of columns. This makes life harder for almost everyone using such a scheme.
Now, what would make such design undesirable?
- The duplication of constraints is going to cause problems. Any constraints that apply to monthly sales will have to be defined for each individual column.
- Without altering the table, you cannot add the sales for a new month. One poor alternative is to have the columns for all possible monthly sales and use NULLs for the months with no sales.
- And finally, there is the difficulty in expressing relatively simple queries, like comparing sales among sales persons or finding the best monthly sales.
By the way, many people consider this to be a violation first normal form. This is a misunderstanding since there are no multi-valued columns here (Pascal, 2005). For a detailed exposition, please refer to the simple-talk article: Facts and Fallacies about First Normal Form
The ideal way to design this table would be something along the lines of:
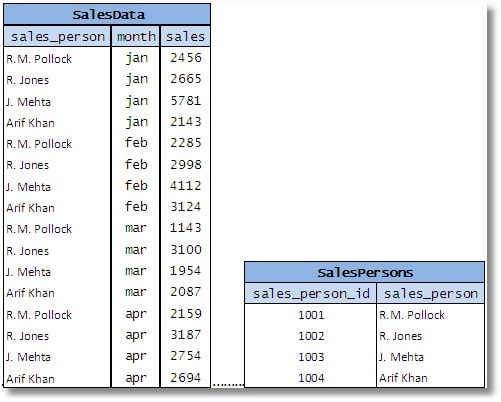
Fig 10
Of course you can have a separate table for the sales persons and then reference it using a foreign key, preferably with a simple surrogate key such as sales_person_id , shown above.
If you are stuck with a table that is designed as Fig 9, you can create a resultset from the code in a few different ways:
1. Use a UNION query:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT sales_person, 'jan' AS "month", jan_sales AS "sales" FROM salesdata UNION ALL SELECT sales_person, 'feb', feb_sales FROM salesdata UNION ALL SELECT sales_person, 'mar', mar_sales FROM salesdata UNION ALL SELECT sales_person, 'apr', apr_sales FROM salesdata ; |
2. Use a JOIN to a derived table with the column names:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT sales_person, m AS "month", CASE m WHEN 'jan' THEN jan_sales WHEN 'feb' THEN feb_sales WHEN 'mar' THEN mar_sales WHEN 'apr' THEN apr_sales END AS sales FROM salesdata CROSS JOIN ( SELECT 'jan' UNION SELECT 'feb' UNION SELECT 'mar' UNION SELECT 'apr' ) months ( m ) ; |
3. Use UNPIVOT:
|
1 2 3 4 5 6 7 |
SELECT sales_person, "month", sales FROM ( SELECT sales_person, jan_sales, feb_sales, mar_sales, apr_sales, may_sales FROM salesdata ) s ( sales_person, jan, feb, mar, apr, may ) UNPIVOT ( sales FOR "month" IN ( jan, feb, mar, apr, may ) ) m ; |
As usual, you will have to test against the underlying tables, and consider such things as the magnitude of the data and existing indexes to make sure which method is the most efficient .
The other variation of this approach is to split the attributes across tables, i.e. using data values as part of the table name itself. This is commonly done by having multiple tables that are similarly structured. Consider the following set of tables:
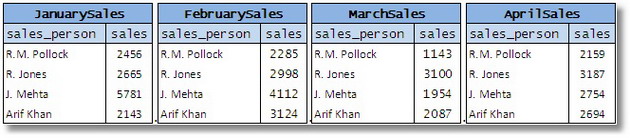
Figure 11
Here, the individual values of the attribute ‘month’ are assigned to each table. This design shares similar shortcomings such as the duplication of constraints and the difficulty in expressing simple queries. To be useful, the tables will have to be UNION-ed to form a single table with an additional column representing the month. It would have been easier to start with a single base table.
We should be careful not to confuse splitting attributes with the logical design principle with table partitioning, a data reorganization process done at the physical level that creates smaller subsets of data from a large table or index in an attempt manage and access them efficiently.
Just as a side note, this problem has been discussed heavily by relational theorists specifically with respect to the limitations it imposes on view updates. Some have identified it as a direct violation of the Information Principle (a relational principle that requires the representation of all data in a database solely as values in a table) and recommended that no two tables in a database should have overlapped meanings. Originally defined as the New Design Principle, this recommendation for each table to have a single meaning or predicate is currently known as the Principle of Orthogonal Design in relational literature (Date & McGoveran, 1995).
Conclusion
It is always worth investing time in modeling a sound database schema. Not only does it provide you with an easily accessible and maintainable schema, but it also saves you from patching up the holes periodically. Often database designers look for shortcuts in an attempt to save time and effort. Regardless of how fancy they look, most kludges are short lived and end up costing more time, effort and expense. A good clean design may require no more than following a few simple rules, and it is the resolve to follow those rules that characterizes genuine database professionals.
References
- Celko, J. (2005). SQL Programming Style. San Francisco, CA: Morgan Kaufman Publishers.
- Date, C. J., & McGoveran, D. (1995). The principle of Orthogonal Design. In C. J. Date, & D. McGoveran, Relational Database Writrings 1991-1994. Addison Wesley.
- Nadkarni, P. M. (2002). An Introduction to EAV systems. National GCRC Meeting. Baltimore, MD.
- Pascal, F. (2005, March). What First Normal Form really means and means not. Retrieved Oct 1, 2009, from Database Debunkings: http://www.dbdebunk.com/page/page/629796.htm
- Peterson, D. (2006, March 24). Lookup Table Madness. Retrieved September 26, 2009, from SQL Server Central: http://www.sqlservercentral.com/articles/Advanced/lookuptablemadness/1464/
- Teorey, T. J. (1994). Database Modeling & Design: The Fundamental Principles. Morgan Kaufmann.
Load comments