
Language Integrated Query, or LINQ, is a powerful and versatile new technology from Microsoft. It’s one of those technologies-like regular expressions, object-oriented programming, XML, or even Visual Studio-that take some effort to comprehend but once you grok it, you will wonder how you ever got along without it. LINQ comes in several main flavors-LINQ to SQL, LINQ to XML, LINQ to DataSet, and LINQ to Objects-and a whole variety of lesser known ones, too. Here, you will read about one such variant, LINQ to XSD (also from Microsoft), and how it compares and contrasts to LINQ to XML and LINQ to Objects.
But let me take a step back for a moment and introduce the other main facet of discussion, the TreeView component. In a sense, this is part 3 of my recently published two–part series on the QueryPicker WinForm control. In those prior articles, I discussed a plug-and-play component for .NET applications that provided a repository of SQL Server, Oracle, and MySql meta-queries. Depending on the database type your main application points to, the QueryPicker displays a different subset of meta-queries from its library. The group of meta-queries populates a TreeView control, allowing your user to walk the tree to select a particular meta-query template from a particular category.
One of the more interesting parts of this whole proposition was how to manage what is effectively a mini-database of meta-query templates and map just the right ones to the TreeView control. Note that the user is free to switch database types (e.g. move from SQL Server to MySql) whereupon the TreeView must be refreshed with a new, appropriate set of meta-query templates. I chose to store the meta-query library in a single XML file for simplicity.
XML, of course, represents its data in a tree so you might assume that it is then trivial to map it to a TreeView. That would be true if the trees were isomorphic but I wanted a more general, uncoupled solution: it is poor design to have your UI depend on your data structure or vice versa. I wanted a design that would allow mapping an arbitrary XML tree onto a TreeView, so that if the XML structure changes later, the mapping is the only component that would need to be adjusted to match.
Mapping XML to a TreeView
Figure 1 describes the syntax of the XML library structure used by the QueryPicker control (a useful enough illustration that it bears repeating from my initial article). The root node of this XML is ArrayOfQuery. It has children of type Query, each representing a single meta-query template.
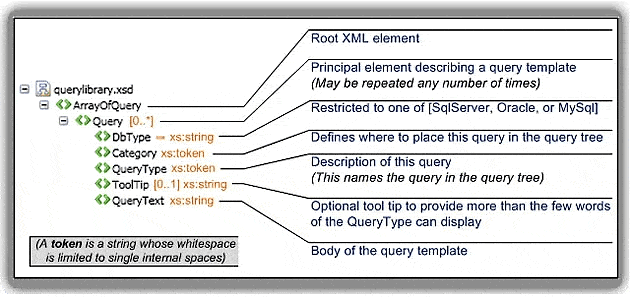
Figure 1 – Meta-Query Schema
The XML Schema for the query template library file consists of a simple array of queries, where each query contains 4 or 5 elements. The notations describe how these elements are used.
For comparison purposes, Figure 2 shows a pseudo-schema for my TreeView structure (i.e. what the schema would look like if the TreeView was also an XML container, though of course it is not).

Figure 2 – TreeView Pseudo-Schema
If the TreeView was an XML container, this is what the schema would look like.
By comparing Figure 1 with Figure 2 you can immediately see that, for example, the Category and Query nodes are switched between the input (XML) and the output (TreeView) in the translation: in the XML, the Category is a child of the Query while in the TreeView, the Query is a child of the Category. That is:
|
/ArrayofQuery/Query/Category |
> |
/Prompt/Category |
|
/ArrayofQuery/Query |
> |
/Prompt/Category/Query |
Figure 3 takes you from the concept to the concrete, illustrating an actual XML instance and TreeView and showing how they relate. Though all sub-nodes of the XML Query node are consumed by the QueryPicker, the TreeView portion of it only uses 3 of the 4; the remaining one – the body of the query itself in the QueryText element – only comes into play when the user selects a particular entry in the TreeView.
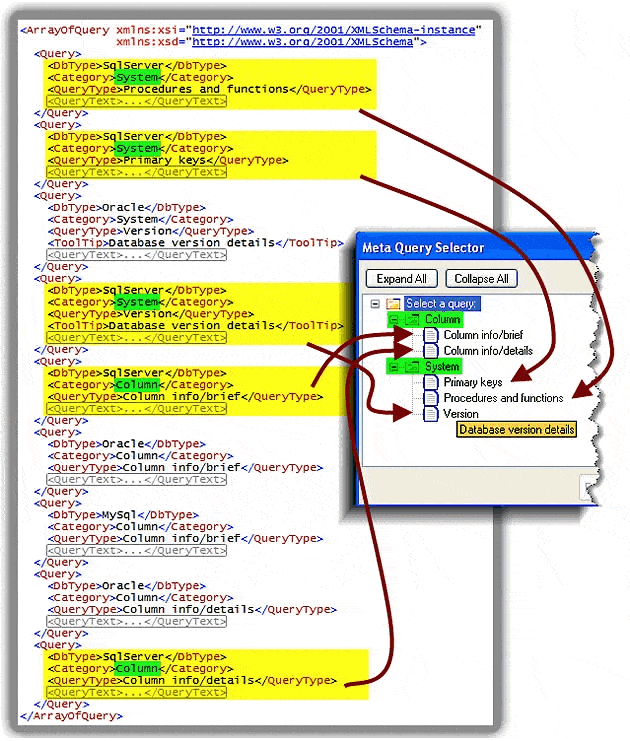
Figure 3 – Mapping XML to a TreeView
This XML is a subset of the full meta-query library, reduced only to fit neatly into the illustration. The SQL Server meta-queries (highlighted in yellow) appear in the TreeView when that database type is selected. The categories from the XML (highlighted in green) determine the categories in the TreeView. Finally, when a tooltip is associated with an entry in the XML (e.g. the Version query) it finds its way to a realized tooltip in the TreeView.
Here is what happens in Figure 3, in slow motion:
- The code first selects all Query nodes based on the current database type (SQL Server is used as an example in the figure); those with a different DbType are ignored.
- Next, it accumulates, sorts, and places all the categories from the selected nodes into second-level nodes in the TreeView.
- It generates third-level nodes, in sorted order, using the title of each query (QueryType nodes).
- It associates a tooltip with each third-level node where the originating Query node has one (ToolTip nodes).
The TreeView and Functional Programming
A TreeView control is conceptually simple to understand as soon as you see one (as in Figure 3). The TreeView API page includes examples to get you started in case you have not worked with it before. Other useful references include the TreeNode API page and the TreeView Overview.
In brief, a TreeView contains a top-level collection of TreeNodes, each of which may contain further collections of TreeNodes. To create a TreeNode, use one of the several forms of its overloaded constructor. Of interest (in this specific example) is the constructor with this signature:
|
1 2 3 4 5 |
TreeNode( string text, int imageIndex, int selectedImageIndex, TreeNode[] children) |
*The QueryPicker uses four such icons: a plain folder to represent categories and a plain text file icon to represent queries, both for non-active nodes. There’s also a corresponding highlighted folder icon and highlighted text file icon for the active node.
The text parameter is the displayed value of the node. The imageIndex specifies an index into an image table (which you need to build ahead of time) containing an icon appropriate for the TreeNode that you’re creating*. The selectedImageIndex is also an index into the image table, referencing an icon to replace the former one whenever this particular TreeNode is active (i.e. selected by the user). The image table is stored in a standard ImageList component. Once you instantiate an ImageList, you simply add images to its collection and they are referenced, starting from zero, in the order you enter them.
The code for the TreeView also needs a second variant of the TreeNode constructor; this variant does not exist, so I had to create it. This is done very simply with this code:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
internal class TreeNodeWithTip : TreeNode { public TreeNodeWithTip( string text, int imageIndex, int selectedImageIndex, string tooltip) : base(text, imageIndex, selectedImageIndex) { this.ToolTipText = tooltip; } } |
As you can see, this TreeNodeWithTip variation subclasses the original TreeNode class. It does almost nothing, but what it does is important: it provides a constructor signature that has a tooltip argument! Its constructor calls an existing constructor of the base class, and then executes its single line of code to initialize the tooltip value. Thus, you can now say in one line of code…
|
1 |
treeNode = new TreeNodeWithTip("Version", 0, 1, "Database version details"); |
… what would have taken two:
|
1 2 |
treeNode = new TreeNode("Version", 0, 1); treeNode.ToolTipText = "Database version details"; |
Being able to accomplish this in one line makes it much more suitable for blending into LINQ code using functional programming. Wikipedia has a good overview of functional programming, stating that it is a paradigm “…that treats computation as the evaluation of mathematical functions and avoids state and mutable data.” Perhaps more succinctly, it “emphasizes the evaluation of expressions, rather than execution of commands“[1]. For further reading I highly recommend an article by Slava Akhmechet [2]. But since I am sure you’d prefer to just see it and move on to the topic at hand, here is a trivial example comparing imperative-style and functional-style programming within the confines of C#:
|
1 2 3 4 5 6 7 8 |
IMPERATIVE PROGRAMMING STYLE var myString = "foobar"; var newString1 = myString.Replace("foo", "fudg"); var newString2 = newString1.Replace("bar", "sicle"); var upperString = newString2.ToUpper(); FUNCTIONAL PROGRAMMING STYLE var myString = "foobar".Replace("foo", "fudg").Replace("bar", "sicle").ToUpper(); |
LINQ naturally follows this paradigm. I have borrowed some of the example code in this section from Microsoft’s LINQ: .NET Language-Integrated Query page and I have put the examples into the excellent LINQPad[3] utility, which uses the custom Dump() method used in the last line of each of the code samples below.
The next couple of examples use this names array:
|
1 2 |
string[] names = { "Burke", "Connor", "Frank", "Everett", "Albert", "George", "Harris", "David" }; |
Here is the most basic of LINQ queries (note the use of the functional programming paradigm); the output is a sorted list of elements, where each element is just an item from the names array (Figure 4, left side):
|
1 2 3 4 |
var query = from item in names orderby item select item; query.Dump(); |
The next example builds on this with query continuation, a vital concept when building up to the query needed for the TreeView. The output is, again, a list of elements, but here each element is a more complex structure, containing a length and a collection of zero or more names (Figure 4, right side):
|
1 2 3 4 5 6 |
var query = from item in names orderby item group item by item.Length into lengthGroups orderby lengthGroups.Key descending select lengthGroups; query.Dump(); |
This query effectively creates a two-level structure. The select clause – the final clause in the LINQ query – defines the top level (the lengthGroups). Working backwards through the query; at the second level, the lengthGroup elements are sorted by the length of each collected group in descending order. This second level (defined by the group…by) fills each lengthGroup with individual names, and the names within each lengthGroup are sorted in ascending order (the default on the first orderby clause).
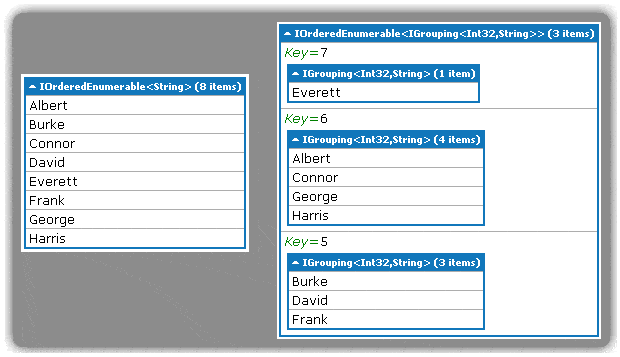
Figure 4 – LINQPad Output for a Simple Selection and a Complex Selection
The output on the left shows the result of selecting a simple element (in this case a name). The results on the right illustrate selecting a complex element, where each element contains a key field that represents the length of all the names in its collection.
Developing “LINQ to TreeView”
“LINQ to TreeView” is not technically an accurate designation, but it succinctly gives you the idea of the next step. Figure 5 illustrates all the techniques just covered being applied in practice, using a slightly simplified version of the actual PopulateQuerySelectionList method. This annotated code populates the TreeView from the XML library (which has been loaded into a collection).
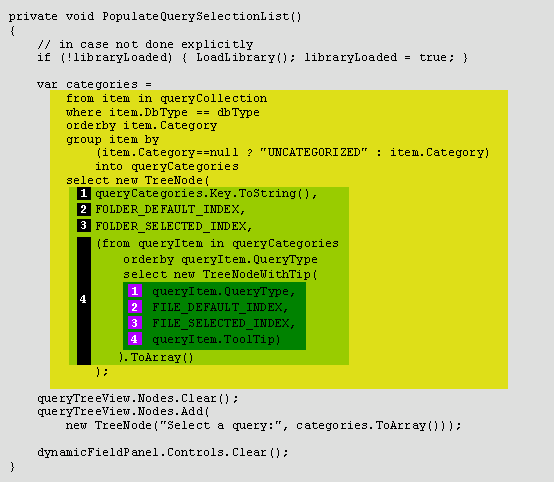
Figure 5 – Code to Populate the TreeView
The TreeView is populated at the bottom by the Add method, passing in the collection built by the doubly-nested LINQ construction in yellow. The light green box shows the category-building TreeNode code, while the dark green box shows the leaf-building TreeNode code.
The yellow box does almost all the work in a single statement – there’s that functional programming paradigm in action! I could have gone further and removed the local categories variable to make it even more purely functional programming, but the existing arrangement of code presents the best compromise between clarity and functional style. The code in the yellow box has the same LINQ usage that you saw earlier:
from…orderby…group by…into…select
It uses one additional LINQ clause, the where clause, to filter the library down to a subset relevant to the current database type. The select clause for this LINQ expression is represented by the outer, light green box. Just as in the previous example, it is selecting what was just grouped – in this case, query categories. However, it morphs each category into a TreeNode using the TreeNode constructor presented earlier. The four arguments of the constructor are labeled with numbers highlighted in black. The displayed value of the TreeNode (the first argument) is the key field of the queryCategory (i.e. the name of the category). The second and third arguments are image indices for intermediate nodes, also as discussed earlier. The fourth argument is an array of child TreeNodes.
A second-level LINQ expression (the dark green box) builds each child TreeNode. Here, the new TreeNode constructor is crucial: it instantiates a TreeNode with a tool tip in a single statement. The four arguments to this constructor (in violet) are, in order, the name of the individual query (from the QueryType field of the queryItem), the standard pair of image indices for leaf nodes, and the tool tip. The collection of TreeNodes built with this second-level LINQ expression results in an IEnumerable collection of TreeNodes. The outer TreeNode constructor needs an array, though, so the ToArray method functionally does the conversion.
The couple of lines of code below the yellow box do the leftover (yet crucial) step of realizing the entire tree. First, it empties the node collection of the TreeView, then it adds en masse the TreeNodes that have just been built. Here also, the TreeView Add method is looking for an array, so the ToArray method is doubly necessary.
Inside the QueryCollection
In the last section I glossed over how the XML representing the query library transformed into the queryCollection used by the LINQ construction. I first approached this problem by reading the XML library into an explicitly defined (and therefore strongly-typed) collection of Query objects. Here is the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
Serializable] public class Query { public ConnectionStringManager.DBTypes DbType { get; set; } public string Category { get; set; } public string QueryType { get; set; } public string ToolTip { get; set; } public string QueryText { get; set; } public Query() { /* empty */ } public Query( ConnectionStringManager.DBTypes dbType, string category, string queryType, string toolTip, string queryText) { DbType = dbType; Category = category; QueryType = queryType; ToolTip = toolTip; QueryText = queryText; } } public class QueryCollection : Collection<Query> { /* empty */ } public void LoadLibrary() { TextReader reader =new StreamReader(fileName); XmlSerializer serializer = new XmlSerializer(typeof(QueryCollection)); queryCollection = (QueryCollection) serializer.Deserialize(reader); . . . |
The LINQ to Objects paradigm in Figure 5 directly utilizes the side effect output of this LoadLibrary method (i.e. populating the queryCollection). You will find this implementation in the LinqToObjectDemo project supplied with this article. [4]
LINQ to XML
LINQ to Objects is an excellent choice for this whole conversion process – assuming you already have some objects in hand. In this case however, I am actually starting with XML, so why not use LINQ to XML?
LINQ to XML has the advantage of a smaller footprint; you do not define the Query or the QueryCollection, you just access the XML elements directly. Here is the PopulateQuerySelectionList method retrofitted to handle LINQ to XML:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
private void PopulateQuerySelectionList() // LINQ to XML { . . . var categories = from item in rootNode.Elements("Query") where item.Element("DbType").Value == dbType.ToString() orderby item.Element("Category").Value group item by (item.Element("Category").Value == null ? "UNCATEGORIZED" : item.Element("Category").Value) into queryCategories select new TreeNode( queryCategories.Key.ToString(), FOLDER_DEFAULT_INDEX, FOLDER_SELECTED_INDEX, (from queryItem in queryCategories orderby queryItem.Element("QueryType").Value select new TreeNodeWithTip( queryItem.Element("QueryType").Value, FILE_DEFAULT_INDEX, FILE_SELECTED_INDEX, queryItem.Element("ToolTip") == null ? null : queryItem.Element("ToolTip").Value)) .ToArray() ); . . . } |
Here, instead of accessing the queryCollection (an in-memory collection of objects), you access the XML via the Elements accessor of the rootNode. Compare the method shown here to the LINQ to Objects implementation in Figure 5. If you’re interested, you will find this implementation in the LinqToXmlDemo project supplied with this article. [4]
The important disadvantage of LINQ to XML, though, is the lack of strongly-typed objects. Whenever you need something from the XML you must access its Value property as a string then convert it to the appropriate type. To minimize awkwardness of the code here I brought everything to the common ground of strings. Note, for example, the dbType being converted to a string highlighted in line 7 of the code above.
You could argue that a better way to do that would be to take the Value of the Element from the XML, then convert it to the type of dbType (via Enum.Parse). That would certainly work, but it is also more verbose. So even though I aimed for brevity in the code shown here, you will find that this version is still more awkward and verbose then the comparable LINQ to Objects version from Figure 5.
LINQ to XSD
So what if there was a way to have the strong-typing of LINQ to Objects with the ease-of-developing of LINQ to XML? Enter LINQ to XSD. This LINQ paradigm is not part of the .NET framework by default, but is instead an experimental Microsoft technology that seems to be stalled in an Alpha release stage. First, take a look at the same method from a LINQ to XSD perspective:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
private void PopulateQuerySelectionList() // LINQ to XSD { . . . var categories = from item in rootNode.Query where item.DbType == dbType.ToString() orderby item.Category group item by (item.Category == null ? "UNCATEGORIZED" : item.Category) into queryCategories select new TreeNode( queryCategories.Key.ToString(), FOLDER_DEFAULT_INDEX, FOLDER_SELECTED_INDEX, (from queryItem in queryCategories orderby queryItem.QueryType select new TreeNodeWithTip( queryItem.QueryType, FILE_DEFAULT_INDEX, FILE_SELECTED_INDEX, queryItem.ToolTip)) .ToArray()); . . . } |
Notice the strong-typing and the brevity, comparable to the LINQ to Objects version. The single weakness is in the where predicate; here the code operates on dbType whose type is both custom and enumerated. Unfortunately for this exposition, all the data in my XML library are string types (with the exception of this one dbType field) so you are not able to see in this example that LINQ to XSD does understand types other than strings. It does not, however, understand custom types, which is why this code needs to convert the custom type of dbType to the common denominator of string. Other than that one field, the code is just as concise and strongly-typed as the LINQ to Objects approach. As before, you will find this implementation in the LinqToXsdDemo project supplied with this article. [4]
It’s quite illuminating to compare the code differences between LINQ to Objects, LINQ to XML, and LINQ to XSD The files to review are QueryPickerWithObjects.cs, QueryPickerWithXML.cs, and QueryPickerWithXSD.cs in their respective projects accompanying this article. However, it is challenging to see the subtle differences between the three files that way, and so I have distilled all the code differences into Table 1. This gives you a much more palatable three-way comparison, where you can immediately see:
- LINQ to Objects needs much more code (the LoadLibrary method, and the supplemental Query and QueryCollection classes).
- LINQ to Objects and LINQ to XSD are strongly typed (with the partial exception of dbType for LINQ to XSD, as discussed earlier).
- LINQ to XML uses generic objects, with all elements untyped (i.e. using just string names).
|
LINQ to Objects |
LINQ to XML |
LINQ to XSD |
|
using System.Xml.Serialization; |
using System.Xml.Linq; |
none |
|
private |
Private |
Private |
|
private void |
private void |
private void |
|
public void LoadLibrary() |
public void LoadLibrary() |
public void LoadLibrary() |
|
private void |
private void |
private void |
|
public class Query public class QueryCollection : Collection<Query> |
none |
none |
Table 1 – Three LINQ paradigms side-by-side
Table 1 does not include the body of the PopulateQuerySelectionList method because it would make the table too wide. You’ve seen this method for all three variations earlier in the article but I still think it is valuable to see them side-by-side, so I squeezed them to fit in the admittedly-awkward and hard-to-read Figure 6. But it’s better than nothing (and you can click on it for a closer look).
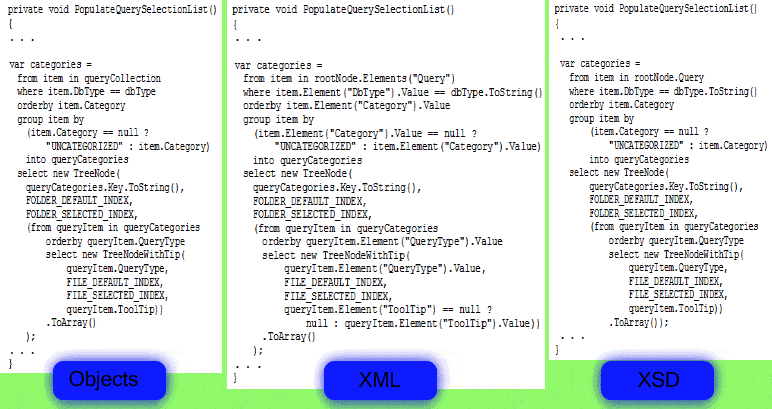
Figure 6 – Three LINQ paradigms for the PopulateQuerySelectionList Method. Click on the image for an enlarged view.
Using LINQ to XSD
LINQ to XSD does not need the additional coding to define a Query and a QueryCollection, as LINQ to Objects did. What it requires instead is an XML Schema file that describes the data-typing of the XML file, and any serious XML application should already have something that defines what is valid. This may be in one of several forms: Document Type Definition (DTD), XML Schema, Schematron, RelaxNG, or CAM template, among others. Since XML Schema is the most prevalent form today, you most likely already have the XSD file that you need to power LINQ to XSD.
Earlier, Figure 3 showed a sample of the XML for the meta-query library, while Figure 1 gave a graphical representation of the corresponding XSD file. Here is the text version with all of the elements that become strongly-typed .NET entities highlighted:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
<xsd:schema xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:xsd="http://www.w3.org/2001/XMLSchema" attributeFormDefault="unqualified" elementFormDefault="qualified"> <xs:element id="SPAN" style="COLOR: green">ArrayOfQuery"> <xs:complexType> <xs:sequence> <xs:element minOccurs="0" maxOccurs="unbounded" id="SPAN" style="COLOR: green">Query"> <xs:complexType> <xs:sequence> <xs:element minOccurs="1" maxOccurs="1" id="SPAN" style="COLOR: green">DbType"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="SqlServer" /> <xs:enumeration value="Oracle" /> <xs:enumeration value="MySql" /> </xs:restriction> </xs:simpleType> </xs:element> <xs:element id="SPAN" style="COLOR: green">Category" minOccurs="1" maxOccurs="1" type="xs:token" /> <xs:element id="SPAN" style="COLOR: green">QueryType" minOccurs="1" maxOccurs="1" type="xs:token" /> <xs:element id="SPAN" style="COLOR: green">ToolTip" minOccurs="0" maxOccurs="1" type="xs:string" /> <xs:element id="SPAN" style="COLOR: green">QueryText" minOccurs="1" maxOccurs="1" type="xs:string" /> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xsd:schema> |
The power of LINQ to XSD is in the work that it does automatically, similar to the visual designer in Visual Studio. In the latter you drag controls onto the designer surface and Visual Studio generates the supporting code automatically. With LINQ to XSD, it’s even simpler. You create a LINQ to XSD project (available in console, window, or library flavors), add your XSD file, and specify the build action for the XSD file as LinqToXsdSchema in its properties pane. Compile your project and you will get an auto-generated source file (LinqToXsdSource.cs) safely tucked away in your obj directory. It’s compiled at the same time, so the objects represented in your schema are instantly available for you to consume. Figure 7 uses .NET Reflector to expose the interface generated from the above schema.
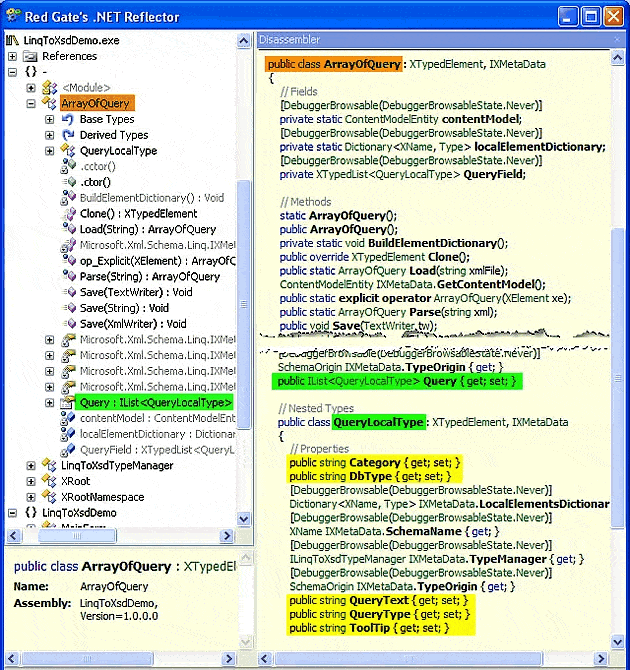
Figure 7 – The Guts of LINQ to XSD
This peek under the hood highlights the exposed, public elements that are automatically generated when you compile.
And, for completeness, Figure 8 shows that there is quite a bit going on under the hood in the generated code. You will find the ArrayofQuery class (highlighted in orange in Figure 7) on the right side of Figure 8, along with the key QueryLocalType, which provides the vital accessors.
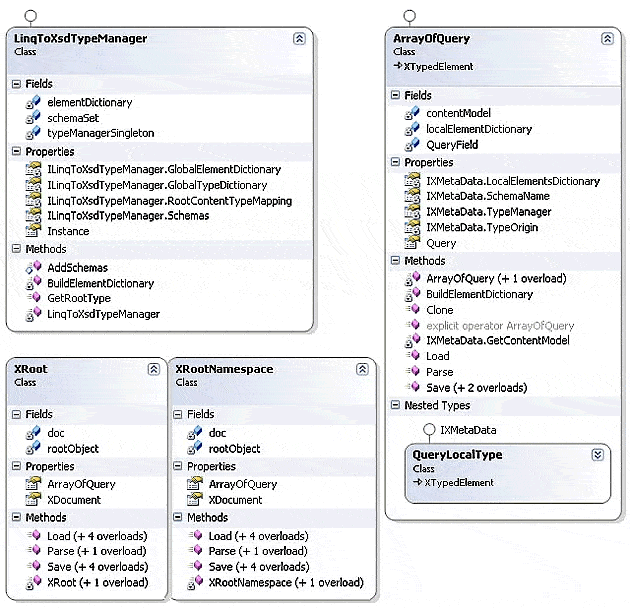
Figure 8 – A Class Diagram of the Generated LINQ to XSD Support Code
LINQ to XSD is, as I’ve mentioned, still in an Alpha release state. As recently as June of this year, Microsoft XML Team’s WebLog announced its availability on Codeplex, but if you follow the link the project is an inexplicably empty shell! If you can live with this rather odd red flag, then LINQ to XSD can be a powerful tool in your arsenal. Download the installer and then take a look at this step-by-step tutorial to get you up to speed.
Summary
Mapping XML to a TreeView component can be done simply and easily with LINQ. Although both are tree-structured, the mapping may be arbitrarily different between the two, requiring appropriate LINQ construction to bridge the gap. Table 2 summarizes the strengths and weaknesses of the three LINQ paradigms in this context.
|
Characteristic |
LINQ to Objects |
LINQ to XML |
LINQ to XSD |
|
Strongly typed (and thus compile-time checking) |
Yes |
No |
Yes |
|
No explicit container coding needed |
No |
Yes |
Yes |
|
No code needed for slurping XML |
No |
Yes |
Yes |
|
Easier to read |
Yes |
No |
Yes |
|
.NET support |
Released |
Released |
Alpha stage |
|
.NET requirement |
2.0 |
3.5 |
3.5 |
Table 2 – Weighing the Benefits of LINQ Variations
I have demonstrated that, when working with XML, these three LINQ paradigms may be used interchangeably; which you choose is largely a matter of personal preference. My thinking on the matter, which may certainly differ from yours, is:
LINQ to Objects vs. LINQ to XML: I believe that strong-typing produces easier-to-maintain code. LINQ to Objects offers strong typing, though at the cost of manually coding a container/collection. Furthermore, converting XML data to a collection of some sort requires just a few lines of code, so in any situation where you could apply LINQ to XML, you could also apply LINQ to Objects. Thus, between LINQ to Objects and LINQ to XML I will always choose the former.
LINQ to Objects vs. LINQ to XSD: LINQ to XSD is also strongly-typed, and is superior to LINQ to Objects in that, though it still requires extra code, its extra code is generated automatically, making it quite elegant. Though I have not exercised LINQ to XSD enough to give it an unqualified endorsement, it certainly performed well for my application. My only hesitation with it is that it is not an officially released product, so you can’t count on support or further development.
References
[1] Frequently Asked Questions for comp.lang.functional, November 2002
[2] Functional Programming For The Rest of Us, Slava Akhmechet, 19 June 2006
[3] LINQPad is a LINQ and C# IDE to evaluate expressions, statements, or entire programs directly in its sandbox. It includes powerful output visualization, particularly useful with LINQ (as shown, for example, in Figure 4).
[4] Three demo applications accompany this article contained within a single Visual Studio solution, providing source code as well as the compiled executables (in each project’s bin/Debug directory). You need only rename each name.executable file to name.exe and you can run them right out of the box.
[5] LINQBridge provides a bridging DLL to allow LINQ to Objects to work with the .NET 2.0 framework.
Load comments