
- The Zen of Code Reviews: Deep Digging
- Review the Code… And Everything Else
- Look for the code equivalent of tautologies
- Less magic usually means less maintenance
- Look beyond the changes
- Is the code self-documenting?
- Eschew building semantic structures by cobbling text together
- Conclusion
Before leaping into this new installment in The Zen of Code Reviews series, here is a quick recap of the previous articles:
- Pre-Review Comments and Best Practices focused on techniques to improve a code review when you wear your author hat, i.e. you write the code to be reviewed by your colleagues.
- The Reviewer’s Tale considered the opposite perspective, wearing your reviewer hat; however, it told only half the story.
The Reviewer’s Tale focused on the question “Does the code you are reviewing accurately and completely cover the requirements it allegedly addresses?” It did this by describing techniques to analyze the unit tests provided in the code review, largely ignoring the production code that those unit tests are testing! (If you practice TDD, then you likely are fine with that; if not, you might think it peculiar. I encourage you to go look at that article and see if my arguments make sense to you.) However, in no way was that article advocating that we should ignore production code, just that it should not be the first thing you look at. This article is the natural follow-on to that narrative, by discussing techniques to evaluate the production code itself. In one sense, it is less important than the material covered in the previous article, as it is “just” discussing the implementation details. After all, one could argue, if the unit tests prove that the code substantially covers all the necessary requirements that the code is supposed to cover, does it really matter whether the production code might be a bit scruffy-looking? To which I would respond with an emphatic “Yes!” If the code is too fragile, too inefficient, or just plain too confusing, it could be difficult or impossible to maintain subsequently. Matt Lacey, in his recent blog post 5 Tips On Working With Technical Debt , distilled a lot of what I was going to suggest into this single sentence: “The person who signs off on a review agrees that they will be able to support it in [the] future, should the original author not be available.”
Right: You have been asked to do a code review; the guidelines in this article will make you more effective at being able to sign off and own that code.
Approaching a Code Review
Your goal, then, is clear: question, probe, analyze, poke, and prod to make sure that you, the reviewer, could support the code presented to you for review. From an overall perspective, there are several questions to keep in mind as you begin your task:
Has the author provided an issue/ticket reference? With few exceptions, all code changes should have an associated ticket-even technical debt. If there was not even sufficient cause to justify putting an item on your task board, should the code change even be merited?
With the ticket in hand, your first job as a reviewer is to review that ticket! You need to have the same understanding of the overall issue as the code author had going in. If there are parts that are not clear, ask for clarification (which could perhaps be done as the first volley in your code review feedback).
Next, do an initial pass of scanning the entire code review, akin to skimming the table of contents when you open a book. Browse the list of files so that you have an idea of the scope, including which projects/modules are being changed. Browse the code itself so you see the extent of the changes, perhaps gauging that, though there are many changes, much of it is “noise” due to simple refactoring. As you do this initial pass, the real goal is to answer this: is every change in the code review in support of the given issue/ticket? If it is not clear that it is related, question it!
Also in the initial pass, determine whether the code review is a new code review or a revised code review. (In my experience when there are good code reviews sent out and good feedback returned, it is not uncommon to see a revised code review, incorporating the initial reviewer feedback.) Typically, a revised code review includes all the changes you saw in the last code review-because nothing has been checked in yet-along with a few tweaks here and there. Kudos to a code author for taking the initiative to do a second round, but keep up your diligence as a reviewer: has the author clearly indicated what has changed in the changes? If not, question it! To know what is new in the second code review, you should not have to either (a) remember what you saw in the first code review, or (b) flip back and forth to the original code review. The author should be able to specifically point out what to look at so you do not have to revisit the entire code review when you’ve likely already reviewed 90% of it.
As you then undertake the second pass, an in-depth review of everything, it is your responsibility to make sure that you are clear about what each particular change is actually doing. Remember that you are (hypothetically) going to take over the task of maintaining this code! If you are not clear, question it. A given change might very well be necessary, as part of the ticket, but it is the author’s job to make that plain to you. Look for comments on why things were done rather than what things were done. For example, “Moved all the caching into the execute method as shown” might help explain what you’re looking at, but ultimately you need to know why or how that supports the ticket at hand.
If the code review includes UI changes, perhaps HTML or CSS, it should be mandatory to get an annotated screen shot showing not just how the code with changes now renders on screen but also what changed on screen. Often you will have a screen mockup in the original ticket; that’s certainly necessary–a good starting point–but not sufficient! You need an actual screen shot of what the author’s changes produce. If you have been supplied no screen shot and/or no commentary on the rendering changes, question it! As a simple example, here is a typical CSS change that is typical of code reviews I have been sent (the left side is the original code; the right side is the revised code):

That’s it: no accompanying screen shot; no comments in the file; no review comments attached explaining the what or the why of this change. This is from a fairly substantial project so it is not reasonable to expect that each reviewer would know offhand what elements those CSS classes were referring to. Now look at the same thing again with some pre-review commentary attached by the author:
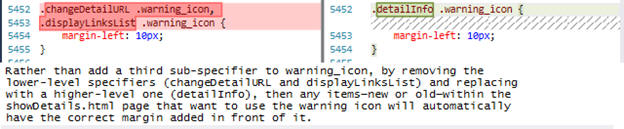
Notice how the text is carefully worded to provide sufficient context for evaluating the code change without requiring the reviewer to study the HTML that the CSS relates to: right here it mentions that the removed specifiers were lower level and the added specifier is higher level. It mentions that the author originally needed to add a third specifier but came up with a better approach, actually reducing the code while making it do more. This code could now be reviewed standalone. The point once again is this: if you have no screen shot and/or no commentary on the rendering changes and/or no code comments, question it!
Review for SOLID Principles
There are many things you might look at when you review code, from simple stylistic issues (consistent indents, always using braces around the target of a conditional even if just a single statement, correct casing for classes & variables, etc.) to code inefficiencies (code duplication, algorithm choices, performance issues) to principles of code design. It would be well-nigh impossible to provide a single, all-encompassing checklist that would meet the needs of all developers and all code bases. Rather, consider this article as being a starting point. This section considers important code design principles and the final section presents ideas on how to think beyond the code review proper to help you maintain a cleaner code base. (Note that some few examples use C# but that is only cosmetic; the principles apply to any language.)
Let’s start with a common set of class design principles referred to by the SOLID acronym, coined by Michael Feathers to be a handy mnemonic for the first five principles of dependency management introduced by “Uncle Bob” in his article The Principles of OOD (object-oriented design). Each letter of that acronym expands into its own acronym:
- S R P – Single Responsibility Principle
- O C P – Open Closed Principle
- L S P – Liskov Substitution Principle
- I S P – Interface Segregation Principle
- D I P – Dependency Inversion Principle
Uncle Bob goes into each of these in detail in the referenced article, so I won’t repeat that here, but to get the most out of this section you should have some familiarity with the SOLID principles. Here we examine how to recognize violations of each principle, the discovery of which would indicate code that could be made cleaner, more robust, or more maintainable.
(Illustrations in this section are from Derick Bailey’s SOLID Development Principles – In Motivational Pictures and reproduced here under terms of CC BY-SA 3.0 US.)
SRP – Single Responsibility Principle

SRP states: A class should have only one reason to change. Where to look? Start with classes that have the most number of methods and dependencies. Class coupling can generally point you to such classes, and you can get the class coupling factor from Visual Studio’s code analysis tools. In VS2015 use Run Code Analysis to see just the items considered suspect by the default analysis rule set, or use Calculate Code Metrics to see the class coupling for every class. Using the former any violations of the default rule set will show up in the standard Errors window as warnings; in this case CA1506: Avoid excessive class coupling is the item to look for. High class coupling is reflected by owning too many dependencies, i.e. instantiating too many concrete objects within a class.
Note that a class having “a single reason to change”:
- …is less restrictive, in a sense, than having a single reason to exist; see Derick Bailey’s excellent discussion of this about a third of the way through his S.O.L.I.D. Software Development, One Step at a Time , wherein he posits that if taken to the extreme, this would mean “you may end up with only one method per class.”
- …is more restrictive than handling a single object or purpose; in Patkos Csaba’s SOLID: Part 1 – The Single Responsibility Principle he presents an example of a seemingly reasonable book class with functions that get the title, get the author, turn the page, and print the page. Dividing along the lines of actors, though, there are two very different actors (book management and data presentation). As it is actors that provide “reasons to change” there are two here, which is non-optimal.
OCP – Open Closed Principle
OCP states: A class should be open for extension but closed for modification. As Dawson Kroeker states in Refactoring Code to Meet SOLID Design Principles – Part 1: “The priority when enforcing OCP is identifying anticipated places of future change. Fixing violations does not give your project an immediate benefit; it is only helpful when new code is added. You want to anticipate those changes and ensure you have a good design that will allow you to make them easily bug-free!”
Obvious places to look for OCP violations include occurrences of switch statements or multiple if-then-else statements. Not all such occurrences are bad, of course: But consider what would happen if you were, at some future date, to add another subtype of the base class you are examining: Or what would happen if the gizmo that your class manipulates currently comes in three flavors and you were to add a fourth. If those scenarios were controlled by switch or if statements in the class, then you are almost guaranteed that the class itself would need to be modified, an indication of a fragile, less maintainable design.
LSP – Liskov Substitution Principle

LSP states: Derived classes must be substitutable for their base classes. In a sense LSP overlaps with OCP, in that the easy to identify violation is a switch or if statement that branches on the subtype of a given class. However, as Dawson Kroeker points out, an active LSP violation will not yet have such a type check in place. So instead, look for subclasses that implement an empty method or a method that throws a NotImplementedException.
Those are the easy LSP violations to spot. However, there are much more subtle ones as well. Uncle Bob’s example, of a rectangle type and a square type deriving from it, has been deemed the canonical example of this. Essentially, you have a Rectangle as a base type, and a Square type that derives from it. You tailor the SetHeight and SetWidth methods for the Square subclass so that each sets both the height and the width; albeit somewhat of a code smell, that makes the Rectangle class usable as a base class for Square. The main issue here is for a user of the Rectangle class, like this CheckRect method:
|
1 2 3 4 5 6 |
public void CheckRect(Rectangle r) { r.SetWidth(5); r.SetHeight(4); Debug.Assert(r.GetWidth() * r.GetHeight()) == 20); } |
That last line seems like a perfectly reasonable assertion for a rectangle: after setting the width and height then the rectangle’s area is the product of the values you specified; but when you pass a square in-perfectly legitimate since Square inherits from Rectangle-setting the width to five also sets the height to five. At that point, its area is 25. Next setting the height to four also sets its width, so its area is now 16. Thus, the assertion will fail! So whenever you are using a class that has derived subtypes, make sure that the code is deliberately oblivious to knowing anything about each subtype and that each subtype works.
ISP – Interface Segregation Principle

ISP states: A client should not be forced to depend on methods it does not use. Look for interfaces with lots of methods and chances are you will find an ISP violation. Such a violation will manifest in one or more of the implementations containing methods solely to satisfy the interface. These will-just like for LSP-be empty methods or methods that throws a NotImplementedException. You might certainly find one or more implementations that use all the methods of the interface. But regardless, if there is at least one implementation that does not, it is an ISP violation. The fix for this is simple: subdivide the single interface into multiple interfaces, then let the clients of the original interface now inherit just those members of the new set of interfaces that they need. This next example is trivial but the principle is evident:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
interface IOriginalInterface { void methodA(); bool methodB(); int methodC(); int methodD(); } class X : IOriginalInterface { public void methodA() { } public bool methodB() { } public int methodC() { } public int methodD() { } } class Y : IOriginalInterface { public void methodA() { throw new NotImplementedException(); } public bool methodB() { } public int methodC() { throw new NotImplementedException(); } public int methodD() { throw new NotImplementedException(); } } class Z : IOriginalInterface { public void methodA() { throw new NotImplementedException(); } public bool methodB() { throw new NotImplementedException(); } public int methodC() { } public int methodD() { throw new NotImplementedException(); } } |
Here you see several client classes that need the IOriginalInterface-but only a subset of the methods in that interface. Revise the code by refining the granularity of that one interface into three separate interfaces, then let the clients implement only the ones they need:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
interface INewInterface1 { void methodA(); int methodD(); } interface INewInterface2 { bool methodB(); } interface INewInterface3 { int methodC(); } class X : INewInterface1, INewInterface2, INewInterface3 { public void methodA() { } public bool methodB() { } public int methodC() { } public int methodD() { } } class Y : INewInterface2 { public bool methodB() { } } class Z : INewInterface3 { public int methodC() { } } |
DIP – Dependency Inversion Principle

DIP states two things: High-level modules should not depend on low-level modules; both should depend on abstractions. Abstractions should not depend on details; rather details should depend on abstractions. In general terms, public methods should have parameters that are interfaces rather than concrete classes. Alternately, you might supply a factory as an argument rather than a concrete class. Either way, you want to eliminate the dependency of the receiving class (the high-level module) having to know about a worker object it will use (the low-level module). You can recognize DIP violations by your public methods accepting concrete types, as well as new objects being created within your class. Both of these directly lead to the inability to write full-coverage unit tests for your class. So if the code you are reviewing is missing wide swathes of unit tests, DIP violation is likely the cause of it!
Review the Code… And Everything Else
This final section presents some useful suggestions for improving not just the code that you have been asked to review, but in following the ripples of those code changes, in order to improve the code base as a whole. This is far from an exhaustive list; in fact, it is just barely a beginning! But it is a reasonable beginning.
Can you get by with less code?
If you can do something in fewer lines of code, it is easier to maintain, easier to comprehend, and easier to test. Instead of this, for example…
|
1 2 3 4 5 6 7 |
var output = new StringBuilder(); for (var i = 0; i < params.Length; i++) { output.Append(params[i].name); if (i < params.Length - 1) { output.Append(","); } } return output.ToString(); |
…suggest the author use this:
|
1 |
return String.Join(",", params.Select(p => p.name); |
Simplification possibilities can be very easy to miss. Even something as straightforward as this…
|
1 |
var user = db.Users.Where(u => u.UserID == userID).Single(); |
…could be simplified further to:
|
1 |
var user = db.Users.Single(u => u.UserID == userID); |
Next, look for repeated chunks of code that could, with a bit of parameterization, be made into a reusable method, reducing code duplication. While you can often find this in the mainline code, in my experience it is even more prevalent in unit test code, where test after test includes the same boilerplate setup.
Finally, could you eliminate a whole method of custom code, and just call something that already exists? That is, are there existing methods (in your code or in the .NET framework) that can do the same thing as a block of code the author has sent you to review? Let’s say an author sent you code that has a home-brewed HTML encoder, not realizing there were a few alternatives already available in .NET. Suggest instead to use HttpUtility.HtmlEncode, or WebUtility.HtmlEncode, or System.Security.SecurityElement.Escape… (you get the idea!).
Look for the code equivalent of tautologies
You would probably not write this from scratch, but it actually did show up in a code review that passed my desk:
|
1 |
return string.Format("{0}", message); |
How did it get there? The code had gone through multiple revisions where this line started out making effective use of String.Format. That line got whittled down bit by bit to having only a single parameter-and nothing else in the string. Obviously, it could be simplified to this:
|
1 |
return message; |
When editing code, in the heat of the moment, such things are easier to slip by than you might think.
Less magic usually means less maintenance
Are there magic strings/numbers present with no explanation? I encountered this one recently:
|
1 |
var overflowCount = 231; |
I was working on the same project but had no clue what that number was for. If using a “magic number” like that, there should at least be a comment on it, but preferably suggest turning it into a named constant that would be self-documenting, e.g.
|
1 |
var overflowCount = MAX_WIDTH_OF_VIEWPORT_IN_STANDARD_BROWSER; |
In general, be on the lookout for magic values that should, at a minimum, be turned into named constants private to the current class. But also consider if the same magic value appears in other classes, in which case it would need a wider visibility.
There are magic numbers, such as that just described. A number is hardly ever self-documenting so that is sufficient reason to replace it with a named constant. There are also magic strings. With a string, of course, it is much more possible that it could be self-documenting, but that still does not satisfy the second criteria for eradicating magic values: maintainability. If the code author uses the same hard-coded string constant in more than one place in the code, suggest replacing it with a named constant. Then, in the future should that value need to change, that guarantees it will change everywhere.
Then there are magic Booleans. Yes, Booleans! You will often see a method that take a Boolean parameter to effect some behavior in a method. Consider this signature, for example:
|
1 |
string ConvertText(string input, bool isCaseSensitive); |
Calling that method would frequently be done like this:
|
1 2 |
ConvertText(inputString, true); ConvertText(inputString, false); |
If you hover over that expression in Visual Studio, you could ask Visual Studio to reveal the parameter name, but why should you have to? Suggest that the author rewrite it with named constants making the intent instantly self-evident:
|
1 2 |
ConvertText(inputString, CASE_SENSITIVE); ConvertText(inputString, NOT_CASE_SENSITIVE); |
Look beyond the changes
In a code review, you’re being asked to evaluate very specific chunks of code. The code review tool typically highlights those changed regions nicely for you so you can see the before and after. To do a thorough job, though, you need to consider if there are there any ripple effects caused by the changes in front of you.
Say, for example, a method name was changed from GetCurrentImage to GetFullImage. Visual Studio itself, of course, will take care of applying that name change to any callers of the method. If you are using Resharper, it will add an additional vital feature, looking for changes in related names (e.g. if you rename an interface from IFoo to IBar it will suggest to also rename the Foo class to the Bar class). However, those tools can only go so far. If you have used that name as the basis for a variable name or a test name, those often need to be changed by hand, e.g. you would probably want to change this…
|
1 2 3 4 |
var thisCurrentImage = GetFullImage(); [Test] void SaveImage_stores_current_image_to_repository() { ...} |
To this…
|
1 2 3 4 |
var thisFullImage = GetFullImage(); [Test] void SaveImage_stores_full_image_to_repository() { ...} |
Beyond the code, It is worth checking whether there are any references to that object name in your API documentation, any “read me” files, or even external documentation. You would be surprised what a quick global search of the code base turns up.
Finally, besides just the name, if a public method has changed behavior in any way, has its documentation been updated to reflect that change?
Is the code self-documenting?
Latest best practices suggest that comments, if not outright evil, are evil’s third cousin twice removed. Yes, there are situations where comments are useful and vital, but they should not be used when a simple name change would suffice. So if a method is called Transmit and has a comment attached “transmits header in XML format”, suggest a simple rename, e.g. TransmitXmlHeader, obviating the need for the comment.
Similarly, are parameters of a new method sufficiently documented? Consider a parameter that specifies a timeout value. If it is called simply timeout, then the associated comment might say, e.g. “timeout for operation x in minutes”. Even better, suggest making the name more enlightening, as in timeoutInMinutes.
Finally, did you come across a clever bit of code in the review that has the look and feel of coming from an external source? Make sure at a minimum that it has a comment attributing the source (a URL or a publication name, etc.).
Eschew building semantic structures by cobbling text together
In my experience, it is very common to see some piece of XML cobbled together as if it were plain text like this:
|
1 2 3 |
var myFooElement = "<Foo Bar='some value>" + " <Nested>data<Nested>" + "</Foo>"; |
Did you notice the two errors there? Since it is just text, you are free to mangle the XML any way you please! If you find such abominations (pardon my strong language) suggest firmly that the author build the XML as XML, completely avoiding such risks. Here is just one of a variety of ways you could do this:
|
1 2 3 4 |
var myFooElement = new XElement("Foo", new XAttribute("Bar", "some value"), new XElement("Nested", "data"))); |
Another very common example is building file paths. If you see instances like any of these…
|
1 2 3 |
var path = root + "\\" + otherPiece + "\\" + finalPiece; var path = string.Format(@"{0}\{1}\{2}", root, otherPiece, finalPiece); var path = $@"{root}\{otherPiece}\{finalPiece}"; |
… than suggest instead that the code should do this:
|
1 |
var path = Path.Combine(root, otherPiece, finalPiece); |
Conclusion
Writing code is challenging. Reviewing code is challenging, too. The tips presented above are just a starting point, but they should help you start thinking about taking a broader perspective when it comes to doing code reviews.
From this article (along with the other articles in my Zen of Code Review series) you can likely discern my message: Code reviews are important. Just as important as writing code itself. At my current company I have been evangelizing all the principles and practices I have been writing about and the effort has definitely shown positive results. My team has been able to step up and produce better code as a group, and individually each of us has become a better code designer/developer.
Reviewing code is more of an art than a science; but, after all, so is writing code. You could say that both are two sides of the same craft, requiring diligent practice to do well. With practice, comes experience. With experience, wisdom. Wherever you are on this never-ending journey to enlightenment, here is hoping that this series has been able to provide a few nuggets to guide you!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments