

DevOps, Continuous Delivery & Database Lifecycle Management
Culture and Organization
Behaviour Driven Development (BDD) is a term that was coined by Dan North in 2006. It came about as a response to a very specific problem – teaching developers how to think about testing their code.
Test Driven Development (TDD)
For the best part of a decade developers practicing Extreme Programming (XP) and other Agile methods had been using Test Driven Development (TDD) to help design and write their code. The idea is deceptively simple. Before you write any code you write a test that should pass once you have implemented the piece of functionality that it’s designed to test. Once you’ve done that, you can go ahead and write some code – but only just enough to get the test you’ve just written to pass.
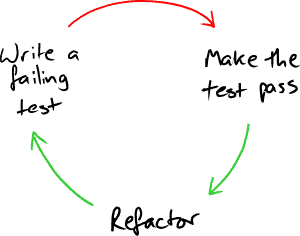
This makes you think about several things in advance:
- How will I know that the code I’m about to write does the right thing?
- How will I interact with the code that I’m about to write
Thinking about what the “right thing” is makes us consider our understanding of the specification. We’ll consider corner cases and error handling. We’ll begin to discover assumptions and contradictions lurking unvoiced in the requirements.
Writing test code that interacts with the software that we haven’t written yet makes us consider its design. Is the interface easy to understand and use? Are the dependencies right? Does the component we’re building make sense?
Once the test is passing (commonly known as “Getting to green”) it is now safe to improve the structure of the code using a technique called refactoring. Refactoring is defined as “improving the design of the code without modifying the externally observable behaviour of the code.” As we make small improvements, we can assure ourselves that we haven’t changed the behaviour of the code by running the tests. The test has become an anchor of how the system should behave.
Then we go on to write the next test. Rinse and repeat.
Behaviour Driven Development
TDD is very simple to describe, but it’s proven hard to teach and hard to learn. Dan was using an early version of JUnit at the time, which required that every test method start with the word test and he found that this seemed to encourage developers to write very low level, technically detailed test code. This led to tests that were hard to read and hard to maintain.
|
1 2 3 |
public void testDataEntry() { // Lots of unreadable, complex test code } |
So, Dan created a tool that looked for methods that contain the word should instead. This simple change encouraged developers to think of themselves as specifying how the code behave. They were still writing tests, but now they were thinking about the desired behaviour, not the detailed implementation. This led to tests that not only anchored the system’s behaviour, but also documented it.
|
1 2 3 |
public void systemShouldNotAllowMoreThan500Characters() { // More focussed, behavioural test code } |
Over the next few years, Dan and Chris Matts realised that this way of specifying behaviour could be utilised by analysts as well as developers. They incorporated the ubiquitous language idea from Eric Evan’s book Domain Driven Design and this evolved into a technique used by the whole team to collaboratively specify how the finished system should behave. Dan’s tool evolved into JBehave, in which the tests were written using a simple Given/When/Then syntax and natural language phrases that incorporated terms from the business domain. BDD was born.
|
1 2 3 |
Given I am on the data entry screen When I submit 501 characters Then a "Too many characters" error is returned |
Agile is not a silver bullet
The development of TDD and BDD was happening during the early years of the millennium, when Agile methods were becoming more popular. One of the major changes that Agile brought was the idea of replacing the long period of up front analysis and design before development began with short iterations that incorporated small amounts of analysis, design, development and testing. The aim was to get feedback from our customers in days rather than months or years and use that to decide what to do next. This iterative and incremental way of developing software was not new, but it was a massive departure from the siloed waterfall processes used in most organisations.
Now, more than 10 years later, Agile methods are in widespread use (with varying degrees of success). There is a general realisation that business requirements change at such a pace that is unrealistic to invest months (or even years) in writing a comprehensive specification before it is handed over to development. There is no shortage of high-profile, failed projects that stand as shining examples of what not to do.
Unfortunately, Agile ways of working have their own pitfalls. Without a rigorous, disciplined approach projects still go wrong. However, by enabling analysts and developers to collaborate on a single, shared view of the system, BDD gives Agile teams a powerful tool to discover uncertainty, manage risk and create a business language executable specification of the system.
How does the database fit in?
Even in organisations that have had success with Agile ways of working, the database is often outside the Agile team. For many reasons, both good and bad, database development is often managed separately from application development leading to the usual mix of misunderstandings, inefficient hand-offs and resource challenges. There have been attempts to change the status quo, but these are regularly thwarted by a combination of business risk, technical debt and a lack of appropriate tooling. These structural challenges are exacerbated by organisational cultures that don’t have a common, shared understanding of “delivered value”. This, all too often, leads to conflict between teams that would be better off working together.
Before diving into specific approaches to applying BDD in the database, I need to introduce a few concepts to give us a shared model to work with.
Testing pyramid
A popular diagram in the Agile world was introduced by Mike Kohn – the testing pyramid.
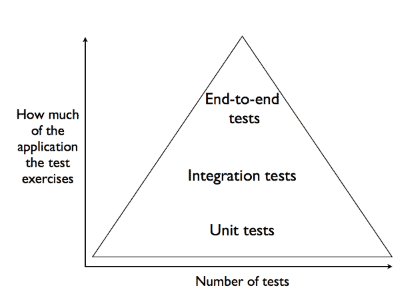
For the moment, ignore the words inside the pyramid and consider only the axes. The x-axis loosely represents the amount of testing done – how much effort is being expended, how many tests are being written and run. The y-axis represents how much of the application each test actually exercises.
This diagram describes a distribution of testing effort that focuses on small, isolated, ‘unit’ tests. It doesn’t say that other tests are less valuable, only that there should be less of them. This is a subtle distinction that is the source of much confusion. Stop for a minute and think about it. If you don’t agree, or think this needs further explanation, please join the discussion on this article.
Database: repository or platform
The “right” way to use a database is a constant source of heated discussion. At one extreme the database is seen as a dumb repository and at the other as the platform on which all business logic is implemented. In reality, most organisations sit somewhere in between these two extremes.
The way you use your databases has a significant impact on your approach to testing. If the database is a dumb repository, then it might be possible to concentrate on isolated ‘unit’ tests of the application with less need to test the database. However, that changes entirely in the presence of complex stored procedures, and you’ll need to expend considerable effort specifying, documenting and verifying the database platform’s required behaviour.
Test doubles
In the application development world there’s a whole taxonomy of terms that are used when trying to isolate parts of the application for testing purposes. The differences between stubs, fakes and mocks are sometimes important, but for the purpose of this discussion the important idea is that we often use specially constructed replacement components called test doubles. Test doubles are used to help us isolate a component that we want to test, and make it simple to simulate contexts that would be hard to create using the real application. Common examples would be simulating error conditions (e.g. permissions, file system, network) or ephemeral occurrences (e.g. date/time specific behaviour, peak loads)
Testing the database
There are several tools that facilitate automated testing of the database, including tSQLt and DBUnit. Irrespective of the tool we use, we’ll want to write clear, focussed tests that describe how we expect it to behave. From the perspective of the larger system, the DB is ‘just another’ component – and we can use techniques developed in other areas of application development to help write maintainable, robust, isolated tests.
The Arrange, Act, Assert pattern
During the Arrange phase of a test we ensure that the database is in a known state. Without a setup phase to ensures that the context of the test is correct, you can end up with flickering tests that sometimes pass and sometimes fail. Database schemas can be complex, so the arrange phase can often become hard to decipher. Keeping this phase understandable, however, is crucial or you will soon spend more time debugging your test than fixing your code.
Rather than fix this complexity, a common alternative is to use a test dataset built from a snapshot of production data or specially constructed test data. To make test writing efficient, many tests then run against the same dataset. This often leads to a maintenance nightmare when, even relatively minor, changes to the schema cause major issues with seemingly unrelated tests. Instead, it is generally better to make each test responsible for creating it’s own data but using patterns such as Data Mother or Data Builder (see later) to manage the complexity.
Another tactic often employed to make the arrange phase simpler, is to run each test within a transaction. This can have benefits, but there are a few pitfalls to be aware of. One is obvious – only code executing within the transaction can see the result of any activity. This limits one’s choices, and makes it hard to test situations where several processes are executing asynchronously.
The next pitfall is that if you have a failing test, the rollback at the end will reset the state of the database. This can make it hard to determine what the actual problem is, leading to prolonged analysis of each failure. When a test fails we want our tests to make it easy to diagnose the problem.
The last pitfall is more subtle. There is a class of errors that only manifests when a transaction commits. Some integrity constraints will only be checked on commit, for example. As Steve Freeman and Nat Pryce say in GOOS “A test that never commits does not fully exercise how the code under test interacts with the database”
The Act phase is typically a single interaction with the system under test, trying to ensure that a single behaviour is as expected. Again the main motivation is that when a failure occurs, it’s as simple as possible to work out what went wrong. If your tests exercise long chains of behaviours then a single small regression can cause many tests to fail, and it can be vanishingly hard to identify the actual culprit.
In the Assert phase we check the resulting state of the database, to ensure that it is as we expected. It may be necessary to check several pieces of data, but we should only check data that is directly connected to the behaviour that we are testing. It is tempting to ‘check everything’, but this makes our tests brittle in the face of future changes of schema or business logic.
Data builder, data mother
If we accept that it is preferable for each test to create its own test data, but that the Arrange phase needs to remain understandable, then we reach for techniques to help manage the complexity.
Data builder is a pattern based upon the observation that there is often a default dataset that will be acceptable for running a test. From test to test, we often change only a few specific data values within the default dataset. For example, a default customer might be a 30 year old, non-smoking female, so our customer data builder will, by default, create this sort of customer for our test and insert it into the relevant database tables. Specific operations on the data builder will allow us to declaratively specify that, for a specific test, the customer should be male or older or a smoker. Any complexities involved in creating a customer will be ‘pushed down’ into the builder, while our Arrange phase will contain very clear instructions about what non-default customer properties are important for the behaviour that this test is exercising.
Data mother, aka object mother, is an extension of this pattern. It takes into account the likelihood that there won’t be just one default customer, but you may regularly need several variations. The data mother provides named versions of the data entity. When dealing with customers, each version might correspond to a persona from your user stories, but it is equally applicable to other entities, such as insurance policies, for example – Version1_Policy, Version2_Policy, Expired_Policy etc.
A further benefit of both these patterns is that they encapsulate the schema. We only ever need to update the code in the data mother/builder to reflect the schema changes – our tests remain unchanged.
Shared, global state
To be able to test a component in isolation we need to be able to control its starting state (in the Arrange phase) and check its end state (in the Assert phase). The simplest sort of component, from a testing perspective, is a stateless component – it simply processes data passed in and returns a result. However, most components are not stateless, and the ability to reliably arrange and assert their state is crucial to effective test design.
Unfortunately it is not always easy to reliably set the state of a component. Apart from the parameters that you might pass to it explicitly, it may also be implicitly dependent on data that it can retrieve from elsewhere in the system. These implicit dependencies might consist of reference data, configuration files, responses from external services or even the date and time of the system clock. Collectively this is known as global data, because it is accessible from anywhere in the system. To compound matters, this data is often used by many components in the system – making it shared data.
Systems with shared, global data are difficult to test reliably. The first challenge is determining exactly which parts of the global state affect the functionality that we are currently testing and in what way. Without this knowledge we cannot define a meaningful Arrange phase. Once we have identified the global state that needs to be set for the test to run reliably, the next challenge is to keep the tests robust when the meaning of shared data changes.
Consider, for example, a string value that is used to hold the location of a configuration file. If the value is set, then the file is read, if not then it isn’t. Other parts of the system use this value to determine whether a configuration has been loaded or not. Later, it is decided to provide an optional default configuration file. A ‘tactical’ decision is made that if the string value is the empty string (“”) then the default configuration file is loaded, but if it is NULL then no file is loaded. Without inspecting every usage of the string value, the team making the change can’t tell if this has an impact elsewhere.
These sort of issues can be overcome by good design and rigorously applied processes, but a more effective solution is to avoid shared, global state wherever possible.
Unfortunately, databases are frequently used as repositories of shared, global state. Many components independently access the same tables, sometimes with very different purposes. A small change in the schema or the seemingly innocuous re-interpretation of a column by the component that notionally ‘owns’ it can both have huge repercussions. For example, I’ve seen ‘unused’ columns, hijacked to quickly store a new piece of data, cause inexplicable errors in downstream reporting processes
Living with the ORM
With the ascendance of object orientation came the need for object persistence. Many techniques were tried, but the ubiquity of the relational database dictated that objects must be stored in relational databases. The Object Relational Mapper (ORM) usually refers to the tool that automates the generation of the data-access layer. In practical terms, that involves programmatically modelling and transforming your application objects into database rows, and vice versa. While this has greatly simplified the job of designing and evolving the application’s object model, it has undoubtedly caused practical issues in the database administration community. More troubling, perhaps, is the philosophical question of whether the code generated by the ORM should be tested, and if so, by whom.
ORMs typically use a schema or namespace of their own, and one that the DBA has little control over. It would be wonderful if this part of the database could be treated as a black box, provided by an external supplier, but this is often not possible. Over time we may come to trust our supplier to “do no evil”, but we’ll still want to dip inside the wrapper to tune the settings so that the ORM coexists peacefully with our own schema.
To be continued…
In this article we explored the origins of BDD and looked at some of the problems that application developers have to deal with to deliver reliable, maintainable software. We also touched upon some of the considerations that arise in database development that pose challenges for testing and test-driven development (TDD) as well as BDD. In the next article we’ll look in more detail at what BDD practically entails, and how it can be used during database development to quickly design robust database systems for every facet of your applications.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments