
Exploring Smelly Code
What is Smelly Code?
“Smelly Code” is code in need of refactoring. Kent Beck quotes his grandmother “If it smells bad, change it.” There are many ways that code can smell bad. Most of these have been categorized as code smells with associated refactors that can resolve the problems with the code that gave the foul smell.
This provides another way to identify problems in code and associate specific problems with common solutions.
A Brief Survey of Smells
Some smells are easy to recognize and relatively easy to resolve. Other smells are much more subtle and can be difficult to resolve. Some smells are even controversial and not always accepted as even causing a code problem.
It is rather easy to identify code that smells of “Long Method”. In fact, we have seen how metrics can be applied to automate pinpointing code with this smell. On the controversial side, can code smell of comments? Does having too many comments imply bad code? Sometimes yes!
With meaningful variable names and meaningful method names, there should be no need to have comments explain what your code is doing. Comments should strictly help explain why your code is doing what it is doing. As you look through your code, note the sections that are heavily commented. Chances are, you can eliminate some of these comments by renaming methods or extracting code to create new methods. The original comment may even provide guidance for the new method’s name.
In this article, we will review three of the most common smells found in application code. We will review what the smell looks like, why we care about the smell, and what we can do about it.
Shotgun Surgery
Shotgun Surgery pops up when you have to make changes throughout the code base to implement a single requirement. This may often be caused by “copy and paste” programming. This may also be caused by not properly leveraging inheritance or not recognizing when related classes could have a common base class.
Whatever the cause, there is one common solution. Identify the code that has to be changed. Move this code to a common location, and change every reference to call the new centralized implementation.
What Does It Look Like
A common example might be the steps needed for object initialization. Let’s consider the not so humble connection object. Typically, there are several steps needed to initialize the connection object. These steps are also subject to periodic changes but will most likely be the same throughout the application. Unfortunately, this commonality is not often properly leveraged.
A typical data access implementation may often include code similar to this:
|
1 2 3 4 5 6 7 8 9 10 |
public SqlDataReader GetData() { SqlConnection con = new SqlConnection(ConnectionString); SqlCommand cmd = con.CreateCommand(); con.Open(); cmd.CommandType = CommandType.StoredProcedure; cmd.CommandText = "spSampleStoredProc"; return cmd.ExecuteReader(CommandBehavior.CloseConnection); } |
The first four lines of code will be the same if every “GetData” type method. Shotgun surgery comes into play if we want to change this logic. Suppose you get a new requirement to explicitly set the ConnectionTimeout or the CommandTimeOut or there is a new best practice for initializing these objects. To implement such a new requirement, every “GetData” type method will have to be modified.
This may seem like an obvious mistake that no one would ever make, but it does happen. Most of the time, this problem is much more subtle.
Consider a logging strategy implemented in every class performing logging operations, or any object with multiple steps to initialize. We will also see shotgun surgery rear its head in the examples we review a little later.
Why Do We Care?
If you have ever had to update such code you know how time consuming it can be to make such changes. If you have never had to make such changes, consider yourself lucky.
If takes time to locate every place that needs to be changed. It takes extra testing time to ensure that every places was properly updated, and following such a pattern makes it that much more difficult to write the original code.
What Do We Do About It?
A much better solution is to move the redundant code to a common function and that replace the multiple instances with references to the new function. This is the basis for the Factory pattern.
The example shown earlier could be rewritten as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
private SqlCommand PrepareCommand(string storedProcedureName) { SqlConnection con = new SqlConnection(ConnectionString); SqlCommand cmd = con.CreateCommand(); con.Open(); cmd.CommandType = CommandType.StoredProcedure; cmd.CommandText = storedProcedureName; return cmd; } public SqlDataReader GetData() { SqlCommand cmd = PrepareCommand("spSampleStoredProc"); return cmd.ExecuteReader(CommandBehavior.CloseConnection); } |
The common approach is to use the ExtractMethod refactor to create a new method with the shotgun code and then update every method that duplicated the shotgun code to call the new method
Feature Envy
Feature envy starts smelling when methods in an object use the methods or properties of another object more than its own methods and properties. We say that this method is envious of the features in the other object. This is not always a bad thing. Sometimes, the object is really acting as an adapter to a legacy object, or perhaps the object is implementing a decorator pattern.
These implementations do not imply the feature envy smell. Adapter and decorator are legitimate patterns to solve underlying design problems. Feature Envy is a smell that points to a new design flaw in its own right.
What Does It Look Like?
There are several examples of Feature Envy that are worth exploring. Consider a “Customer” class that exposes a mailing Address property. If the details for the address are stored in an Address object, then the implementation for the mailing address might be similar to this:
|
1 2 3 4 5 6 7 8 9 10 11 |
private Address currentAddress = null; public string MailingAddress() { StringBuilder sb = new StringBuilder (); sb.Append(currentAddress.AddressLine1); sb.Append("\n"); sb.Append(currentAddress.City + ", " + currentAddress.State); sb.Append("\n"); sb.Append(currentAddress.PostalCode); return sb.ToString(); } |
Formatting the mailing address could and should be in the address class. Having this logic in the Customer class makes the main logic in the Customer class harder to follow.
Other examples may include a ShoppingCart object that calculates the price for each Item in the cart instead of delegating that to the Item iteself.
Even more dangerous, instead of a well defined class like Customer being envious of the properties in Address, imagine multiple web pages being envious of the Address details.
A simplistic way to identify potentially envious code is to track any methods in an object that make references to another object above a specified threshold. For example, if a single method in the Logger class accesses more than five properties in the Borrower object, then there is probably a method embedded there that is just waiting to be moved to the Borrower object.
Why Do We Care?
You may look at this code above and not see a problem. You may even be able to write such code without any problems. However, eventually, such coding practices will create a maintenance nightmare. There are two main problems.
Polluting an unsuspecting object with logic that better belongs in another object hides the true purpose of our unsuspecting object. In our earlier examples, the ShoppingCart’s main task is not to calculate the price for every item in the cart. This logic only detracts from the main purpose and violates the cohesion principle. Because our unsuspecting object includes functionality that would be better housed somewhere else, it is not very cohesive. When you are trying to maintain the code, you may have difficulty finding the logic since it is not where you would expect to find it.
There is also the potential problem with duplicated code. If a particular piece of logic is not where it is supposed to be, there is a good chance that it might be repeated in several wrong places. If you ever need to change this functionality, not only will you have to search to find the code, you also have to ensure that you have found everywhere that needs to be updated. Sound familiar? This is one way that Shotgun Surgery starts stinking up our code.
What Do We Do About It?
We rely on the MoveMethod refactor and potential ExtractMethod as well to resolve these types of issues.
The address example above could be rewritten as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class Address { public override string ToString() { StringBuilder sb = new StringBuilder(); sb.Append(AddressLine1); sb.Append("\n"); sb.Append(City + ", " + State); sb.Append("\n"); sb.Append(PostalCode); return sb.ToString(); } . . . } |
And in the Customer class, the MailingAddress property can be reduced to:
|
1 2 3 4 5 |
private Address currentAddress = null; public string MailingAddress() { return currentAddress.ToString() ; } |
Not only does this make the Customer class more highly cohesive and add more responsibility to the Address class, we are also shielded from the details of how the address is stored and how to properly format it. The Address object can now handle the details of formatting the address properly for international addresses or any other future requirements without requiring Customer and any other objects that need to render an address to get bogged down in these details.
Smelly Switches
Smelly switches refer to code using a switch statement to decide which of a series of potential actions to take. If the same switch statement is repeated in multiple places, at the very least we have duplicated code. At the very worse, we have a maintenance nightmare. Not all switch statements are problems, but they are all worth looking into to make sure that a better design is not waiting to come out.
What Does It Look Like?
When you look over your code base and find the same switch statement repeated, you may have code that smells of switch statements on your hands.
Code snippets like this hint that you have a switch smell in your code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
switch (state) { case "SC": { // Process Broker break; } case "AL": { // Process Retailer break; } case "GA": { // Process Supplier break; } case "KY": { // Process Transport break; } } |
Now if you have such a switch statement only once, then it is probably not an issue, but if you have this same, switch statement in multiple places, then you might have more of a problem that needs to be addressed. If the individual case statements are likely to change, refactoring to eliminate the switch statement will definitely pay off in the long run.
Why Do We Care
You may be asking yourself, “What is wrong with this”? Or you may even be thinking “I do this all the time! I have never had any problems with it!” “A switch statement is so much simpler than a collection of if statements!” All of this may be true.
The problem is not comparing if statements with switch statements. The problem lies in the amount of work needed to unwind the business logic embedded in the complex conditionals.
Object oriented purists will point out all that has to change if you add a new state. Consider the problems that can arise with the state specific business logic spread throughout the system. When it is time to add a new state, you will have to search through the code base to find every switch statement, and update them individually. This sounds a little like shotgun surgery again only on a larger scale.
If the switch statement has only a handful of case statements and the case statements are not likely to change, the complexity of the method will be manageable. But as the number of cases statements grow, the complexity can quickly get out of hand and the overhead of making the updates system wide can be not only a maintenance nightmare but also a deployment nightmare.
What Do We Do About It
We can often eliminate these switch statements with an object hierarchy.
For our state specific business logic example, we can build an object hierarchy implementing a strategy pattern. Every method needing state specific logic would have a corresponding method in the object hierarchy. Instead of duplicating the switch statement everywhere, we use a factory to return the appropriate object and then simply call the corresponding method from the returned object.
Our object hierarchy might look similar to this:
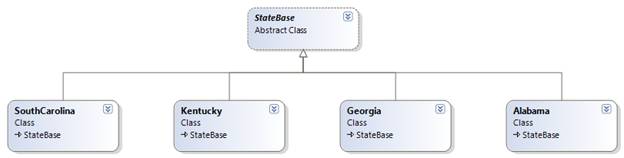
The key thing is for all of our objects to have a common ancestor. The inheritance depth can be to whatever level makes sense for your application. If two states have a common implementation, let them share a common ancestor and put that common implementation in the ancestor class, but there is no need to create a more complicated structure than is necessary.
A method such as this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public double CalculateSalesTax (string state, double price) { switch (state) { case "SC": { return price * SCTAX ; } case "AL": { return price * ALTAX ; } case "GA": { return price * GATAX ; } case "KY": { return price * KYTAX; } } } |
Can be reduced to:
|
1 2 3 4 5 6 |
public double CalculateSalesTax(string state, double price) { StateBase activeState = Factory.CreateState(state); return activeState.CalculateSalesTax(price); } |
This simple method can handle invoking the state specific logic regardless of how many states are supported. Each state object is easy to implement because it has to worry about how to take care of that one state.
The individual state objects can also benefit from inheritance making their implementation even easier. As new states are added, we don’t have to search through the codebase for what needs to be changed. We need to simply implement the new state object. Depending on how the factory is implemented; we may not have to change any existing code, simply deploy a new assembly with the new state object.
Conclusion
Sometimes bad things happen to good code. Even the best code can start to smell if not carefully monitored. Fortunately, we can still intervene and save our code even after it starts to smell.
You can get more information on the basic Refactors here: http://www.refactoring.com/catalog/index.html
A good catalog for the code smells can be found here: http://www.soberit.hut.fi/mmantyla/BadCodeSmellsTaxonomy.htm
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments