
Introduction
Reflection is one of the great marvels of modern programming environments. Being able to store meta data about our code, and retrieve it at run time, opens up a world of possibilities. Many developers and software designers have embraced reflection and sing its praises, but reflection is not without its critics.
Here we will explore some of the criticism of reflection, debunk some of the myths around its usage, and explore the benefits through some practical applications.
What’s Wrong With Reflection
There are various complaints and cautionary warnings against using reflection. Some of these are valid risks that we need to be aware of; others are wild tales based on early-adopters not understanding what they were using. Some are valid only in certain circumstances, or valid in all but special cases. Here we will explore some of these complaints. You should always be wary of a technology that is new or not well understood, but do not let that stand in the way of making appropriate use of technology.
Performance
Everyone knows that reflection is slow. The web is full of well meaning warnings that one should not use Reflection if you care about performance. Retrieving the meta-data slows your application down: One is often reading advice that, If you care about performance, you should never use reflection.
This is a legitimate concern that should be taken seriously, but this is not a carte blanche reason not to ever use Reflection.
While you should always worry about performance, you should not let performance worries keep you from making appropriate use of new technology. Do your own timing studies in your own environment. If there are performance issues, there are ways to minimize the performance impact.
The DotNet framework itself uses reflection extensively. Reflection is being used whether we intend to or not. Take a look at the details in the Machine.Config file. Almost all that you see is providing details to open an Assembly and load a Type with Reflection to make the framework itself work. The DotNet framework is all about Reflection.
If performance worries still nag you, there are tweaks that you can make in your own code to improve performance.
If you are going to make repeated calls to the Properties of an object, cache the Properties in a Hash Table. Reference the hash table instead of repeated calls to GetProperty or GetProperties. The same is true for Methods, Types and Assemblies.
Get comfortable with the BindingFlags enumeration. Always specify BindingFlags. Never use the IgnoreCase flag. Limit the searches to Public. Limit the searches to Static or Instance as appropriate.
Don’t just assume that performance will suffer. Embrace Reflection, but test it. There are various profiling tools, such as Red Gate’s Ants Profiler. Use them to identify the true cause of a performance problem. If Reflection is the right tool, don’t ignore it simply because someone told you that it will be slow. If it turns out be too slow for you, there are ways to optimize its usage.
Security
Reflection, it is said, poses an unacceptable security risk. The essence of most designs that leverage Reflection also incorporate the process of dynamically discovering new code and executing it. This opens up a risk that malicious code will be executing and compromising the entire system.
In the modern world of Malware and security threats, we are all concerned about security. The risk with Reflection is that malicious code may be substituted for your own code. Many reflective designs do, indeed, rely on loading new assemblies, discovering new types, and running discovered methods and properties on these new types. While this may lead many to steer clear of a reflective solution, don’t run scared.
An intruder would need to physically place malicious code where your reflective code can find it. While this is not impossible, a good defense in depth design can mitigate this risk. Properly configured firewalls with processing servers behind the firewalls will help. Intrusion detection will alert administrators to servers that are being targeted, and properly patched servers will help eliminate known vulnerabilities.
Code Access Security, properly configured, can also limit the access that reflective code has. With Code Access Security, individual assemblies can run with fewer rights than the user running the assembly.
This article is not about configuring security settings but rather to assure you that there are counter measures to any security concern that you may have.
Confusion
Reflective code, so one hears, is very hard to follow. Developers new to the project will have difficulty learning the ropes. Anything that steepens the learning curve jeopardizes project time lines and should be avoided. If only a select group of developers can understand the reflective code then the project is overly dependent on this select group, and is doomed to fail.
This is also not a very legitimate concern. If every design decision is based on what the least experienced programmer can readily understand, our designs will be severely limited. Reflective code can, and should, be isolated. Daily development should not be modifying this code. Daily development should use the reflective methods to simplify daily development tasks.
We want our code to be easy to follow, and Reflective code is not always the most intuitive code to understand at first glance. Without a doubt the hard-coded option is easier to follow than the reflective version
|
Hard Coded |
Reflective |
|
1 2 3 4 5 6 7 |
public void MapData(IEmployee first, IEmployee second) { second.FirstName = first.FirstName; second.Address = first.Address; second.BranchLocation = first.BranchLocation; . . . } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public static void MapData(object sourceObject, object targetObject) { object[] value = new object[1]; object[] param = new object[0]; foreach (PropertyInfo propertyInfo in sourceObject.GetType().GetProperties()) { PropertyInfo targetPropertyInfo = targetObject.GetType(). GetProperty(propertyInfo.Name); if (targetPropertyInfo.CanWrite) { value[0] = propertyInfo.GetValue(sourceObject, BindingFlags.Public, null, null, null); targetPropertyInfo.SetValue (targetObject, value,null); } } } |
Anyone can look at the hard-coded version and immediately tell what is going on. The reflective version will probably take a senior developer a second look to figure out.
However, the hard-coded version is tedious code. Depending on the number of properties being mapped, more and more errors are likely to be introduced. In the long run, this results in more code that has to be hand written.
While the reflective code may be hard to follow, it does not need to be referenced very often to be useful.
With the hard-coded implementation, you have to write a similar method for every type that you want to map. This is a tedious proposition indeed! With the reflective implementation, this one method can handle the process of mapping any object in your system.
For the observant reader, this is far from the most optimized implementation for the reflective version. We will go over the reflective version in more detail later and discuss various ways to optimize.
Why Use Reflection?
Developer Performance
As mentioned earlier, the hard coded version is often tedious, and tedious code is often error-prone.
You can well imagine the potential for introducing bugs by having to iterate through, and explicitly set, each property in an object. This can quickly get out of hand. Bugs from assigning the wrong value to the wrong property are easy to introduce and difficult to track down.
It is much easier to write a single line of code to handle the mapping and then move on to more important tasks such as implementing business logic and meeting deadlines.
A call like DataMapper.CopyTo (data, ui) is easy to understand and quick to write. As long as the property names match and are of the same types, you don’t have to worry about missing any assignments. As a developer, you implement a series of rather simple properties to handle validation, and you don’t have to get bogged down in the details of the mapping logic.
Stability / Consistency
Not everyone will get reflective code right the first time, but this is the beauty of consistency. If the implementation that everyone is using is inefficient or has a logic problem, you have only to correct it in one place. If there are multiple hard coded implementations, some will, no doubt, be done as efficiently as possible. Some will, to be sure, be free from all logic problems, but at least some implementations will have problems that will need to be addressed.
Reflective code is much easier to reuse. If the code is widely reused, then we have fewer places to correct when there is a problem found.
This consistency improves the overall stability of the system.
Practical Applications
Tweaking Performance
Performance is always a concern. There are some simple steps that we can take to eke the best performance out of our reflective code.
Whenever you make a Reflection call, make it count. Cache the output so that it can be reused. Calls to GetProperty, LoadAssembly or GetType are expensive. If there is any chance that you are going to need a method or a property more than once, store the return value so that you can use it later without having to make the call again.
This is also an example where multi threading can give you the perception of performance improvement. This proves to be a nice option for batch application and for business / data servers. This does not provide any benefit for the web UI, but can be very beneficial for a traditional windows application.
CopyTo
CopyTo is the reflective MapData that we saw earlier. Let’s discuss some strategies to get the basic method ready for prime-time. As we stated earlier, we don’t want to throw away the return value of the GetProperty call. We also want to avoid calling GetProperty altogether when we are truly interested in every property.
We start by checking to see if our collection of properties has already been loaded into a hash table. If they have, then we use this previously-loaded list. If not, we go ahead and load the details into the hash table. This will allow us to avoid the GetProperty calls altogether. If we are copying from one object to another of the same type, we dramatically reduce the number of reflection calls. If we call this method multiple times with the same set of objects, we reduce the reflective even more.
Our caching logic could look similar to this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
private Hashtable properties; private Hashtable Properties { get { if (properties == null) properties = new Hashtable(); return properties; } } private void LoadProperties(object targetObject, Type targetType) { if (properties[targetType.FullName] != null) { List<PropertyInfo> propertyList = new List<PropertyInfo>(); PropertyInfo[] objectProperties = targetType.GetProperties(BindingFlags.Public); foreach (PropertyInfo currentProperty in objectProperties) { propertyList.Add(currentProperty); } properties[targetObject] = propertyList; } } |
Here we first check to see if the Hash table already has a list of properties for our object. If it does then we have nothing to do. If not, we load the properties into a generic list to be added to the hash table.
Our optimized CopyTo function can now be rewritten as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
public void CopyTo(object sourceObject, object targetObject) { object[] value = new object[1]; Type sourceType = sourceObject.GetType(); Type targetType = targetObject.GetType(); LoadProperties(sourceObject, sourceType); LoadProperties(targetObject, targetType); List<PropertyInfo> sourcePoperties = Properties[sourceType.FullName] as List<PropertyInfo>; List<PropertyInfo> targetProperties = Properties[targetType.FullName] as List<PropertyInfo>; foreach (PropertyInfo sourceProperty in sourcePoperties) { PropertyInfo targetPropertyInfo = targetProperties. Find(delegate(PropertyInfo prop) { return prop.Name == sourceProperty.Name ; }); if (sourceProperty.CanRead) { if (targetPropertyInfo.CanWrite) { value[0] = sourceProperty.GetValue(sourceObject, BindingFlags.Public, null, null, null); targetPropertyInfo.SetValue (targetObject, value, null); } } } } |
The biggest change we have here is in the calls to the LoadProperties method. If the properties are already loaded, this will have no effect. If they are not, this method will load the properties for us. Once our properties are loaded into the hash table, we can safely pull them out of the generic list instead of making repeated calls to GetProperties or GetProperty.
Once we have our two properties, we make sure that the source can be read and that the target can be written to. Now we simply “get” the value from the source and “set” the value on the target.
MapDataToBusinessEntityCollection
MapDataToBusinessEntityCollection is a generic Reflective method. We pass in the data-type for the objects to be mapped as a generic parameter along with a data reader. We use reflection to find the properties in this type and we use the meta data in the DataReader to find the fields.
Whenever we find a field from the data reader that has a matching writable property in the generic type, we pull the value from the DataReader and assign it to a newly created object. Regardless of how many properties are in T, this method will map every property that has a matching field in the DataReader. Any properties that are not in the DataReader will be unmapped. Any fields in the data reader that do not have a matching property will be ignored. The validation logic is handled in the implementation of the properties in T.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
public static List<T> MapDataToBusinessEntityCollection<T> (IDataReader dr) where T : new() { Type businessEntityType = typeof (T); List<T> entitys = new List<T>(); Hashtable hashtable = new Hashtable(); PropertyInfo[] properties = businessEntityType.GetProperties(); foreach (PropertyInfo info in properties) { hashtable[info.Name.ToUpper()] = info; } while (dr.Read()) { T newObject = new T(); for (int index = 0; index < dr.FieldCount; index++) { PropertyInfo info = (PropertyInfo) hashtable[dr.GetName(index).ToUpper()]; if ((info != null) && info.CanWrite) { info.SetValue(newObject, dr.GetValue(index), null); } } entitys.Add(newObject); } dr.Close(); return entitys; } |
Timing Studies
To evaluate the performance implications of this approach, I set up a test-bed to perform my own timing studies. An ounce of testing is worth a pound of speculation.
In my test-bed, I defined an object to encapsulate the Employee table in the NorthWinds database. I loaded this table with 100,000 records and timed how long it took to retrieve records using various methods.
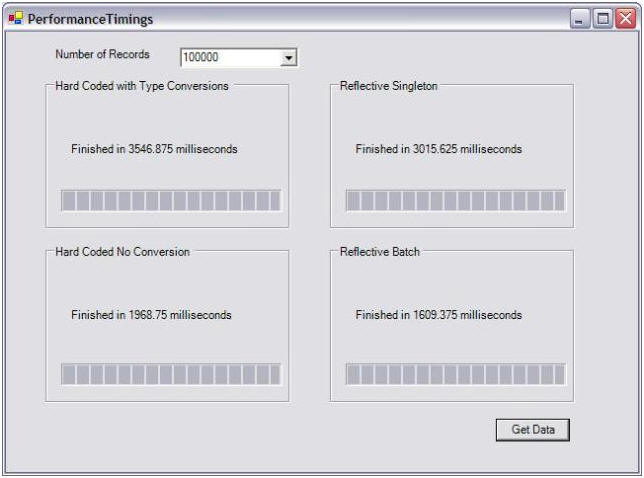
Hardcoded, is this case, is the worse way you can write a Hard-coded implementation, but it is also an approach that I have commonly seen followed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
private void HardCoded() { System.DateTime start = DateTime.Now; System.Data.IDataReader dr = GetData(recordCount); while (dr.Read()) { CustomTypes.Employees newEmployee = new CustomTypes.Employees(); newEmployee.Address = dr["Address"].ToString(); newEmployee.BirthDate = DateTime.Parse(dr["BirthDate"].ToString()); newEmployee.City = dr["City"].ToString(); newEmployee.Country = dr["Country"].ToString(); newEmployee.EmployeeID = Int32.Parse(dr["EmployeeID"].ToString()); newEmployee.Extension = dr["Extension"].ToString(); newEmployee.FirstName = dr["FirstName"].ToString(); newEmployee.HireDate = DateTime.Parse(dr["HireDate"].ToString()); newEmployee.LastName = dr["LastName"].ToString(); newEmployee.PostalCode = dr["PostalCode"].ToString(); newEmployee.Region = dr["Region"].ToString(); newEmployee.ReportsTo = Int32.Parse(dr["ReportsTo"].ToString()); newEmployee.Title = dr["Title"].ToString(); newEmployee.TitleOfCourtesy = dr["TitleOfCourtesy"].ToString(); pgbHardCodedConversion.Increment(1); } dr.Close(); System.DateTime stop = DateTime.Now; System.TimeSpan ts = new TimeSpan(stop.Ticks - start.Ticks); lblHardCodedConvertedTime.Text = "Finished in " + ts.TotalMilliseconds + " milliseconds"; } |
This has several obvious problems, but since it has to be re coded for every data reader, it will often be done poorly.
Reflective Singleton is the same method outlined above, but without caching the PropertyInfo objects. Comparing the Reflective Singleton and the ReflectiveBatch shows the benefits of caching the PropertyInfo objects. I believe this to be a dramatic improvement.
Hard-Coded without Conversion is the same as the HardCoded implementation but skips the extra ToString and parsing operations which should never be performed anyway.
So why is the Reflective Batch implementation faster than the hard-coded version? Indexing into the DataReader by Name is also a slow operation. The Reflective implementation avoids this costly lookup.
Undoubtedly, caching the indexes into the DataReader will change the results. More properties in the test object will change the results, and there are probably more optimizations that could be done to the hard-coded implementation.
All of this reinforces the need to test in your own environment. Test for yourself. You may be surprised that a reflective solution probably will not ruin performance, and it will shorten your time to market.
Conclusion
Do not shy away from Reflection or any other technology just because of warnings that you hear. Always verify that the warnings apply to your project. Often times, they will not.
If you are worried about performance concerns, don’t blindly follow someone else’s opinion. Test it with your own application.
Above all don’t be afraid to learn something new!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments