
Let’s start by defining a subset and why you would require a data subset?
When dealing with the development, testing and releasing of new versions of an existing production database, developers like to use their existing production data. In doing so, the development team will be hit with the difficulties of managing and accommodating the large amount of storage used by a typical production database. It’s not a new problem because the practical storage capacity has grown over the years in line with our ingenuity in finding ways of using it.
To deal with using production data for testing, we generally want to reduce its size by extracting a subset of the entities from a ‘production’ database, anonymized and with referential integrity intact. We then deliver this subset to the various development environments.
Without this, some aspects of testing must be left to staging, where the security regime can be rendered sufficient to allow it to be done without data anonymization on a restored backup.
Testing or development are not the only reasons for wanting to copy just part of the data of a database. As well as extracting a representative subset of the entire database, one might want to extract just a part of a database that you wish to use. This data extraction process, used for specific purposes such as analysis, reporting, or integration with other systems, has much in common with sub-setting in that the entities that are part of the subset must be extracted with all their properties intact so that queries will produce the same result as in the original database.
Subsetting: the Good, the Bad and the Ugly
Database subsetting is the name given to the extraction process. It isn’t a new concept. It refers to the process of extracting and using a subset or portion of the data from a database for the purposes of development, the objective being to have sufficient data to test or develop the database.
This smaller and more manageable dataset must still retain the essential characteristics of the full database so that SQL Queries, including aggregate queries, will return results that are correct for that subset and the distribution of data is similar to the full-sized database. Subsetting assumes that it is possible to extract from the database tables a subset of the data that preserves all the entities to be included in that subset, together with their relationships.
Subsetting would seem, at first glance, to be a simple and reasonable thing to do. After all, a slice of pizza tastes very much like the full pizza, doesn’t it? However, these are the most obvious snags:
- Maintaining referential integrity (RI) – For a subset to be useful, it must maintain referential integrity with all relationships between tables are preserved intact. If a value of one attribute (column) of a relation (table) references a value of another attribute (either in the same or a different relation), then the referenced value must exist. Subsetting may involve careful selection and extraction to avoid breaking these relationships, especially when there are circular references or hierarchies. It must be possible to define rules on how to deal with these.
- Not all relationships are ‘properly defined’ – if all the foreign key references are properly defined in the RDBMS, then subsetting can work well based on metadata. However, relationships that are defined by proprietary datatypes and applications that are not part of the database can present great difficulties. Worse things happen when a table source that isn’t a table is part of the Directed Acyclic Graph (DAG) formed by the foreign key relationships. The complexity of a relation is often hidden behind views and table-valued functions, and these cannot support referential integrity constraints. No subsetter can reverse-engineer this sort of relationship without help.
- Dealing with Circular references – if a chain of relationships includes circular references, then the subsetting process must be instructed how to deal with this.
- Protecting sensitive or personally identifiable information (PII) – this must not be in the subset when used outside staging or production. The data must be anonymized.
- Maintaining the correct distribution – the subset should adequately represent the distribution of data in the original database. If the subset is not representative, then testing and development activities may suggest queries, algorithms, or indexing strategies that are inappropriate in the full database.
- Handling enumerations – tables that are used as enumerations, such as countries, currencies, or part-lists, need to be copied in full because it can easily become impossible to add an entity if a relation doesn’t exist in the subset, such as when adding a customer from Uzbekistan, when ‘Uzbekistan’ isn’t in the ‘subsetted’ enumeration table.
- The process should, where possible, be repeatable and automated – to reflect changes in the metadata and data in the current database version. This strongly suggests that the process should be automated, possibly as a callback, using persistent configuration data
- Importing the subset – the ‘deliverable’ of database subsetting can be a ‘target’ working database or it can be a reusable set of data files for bulk import. The whole point of generating a subset of a database is the large volume of data, so even the subset may be large. Care must be therefore taken to reduce the time taken for the data import by using the features of the RDBMS for bulk import.
- Logical integrity of the data may not be represented fully by the database’s relational constraints – there could be relationships that are obvious to the application but not defined formally within the database. This will mean that when the application is tested, the data subletting cannot be fully automated without these extra relationships being defined in the subsetter’s configuration data. Another way of looking at the problem is there will be two or more acyclic graphs defined in the database, logically disconnected, but accessed by the application as if there was only one DAG. If you don’t spell it out, the expected data won’t be there in the subset.
Implementing data-reduction strategies
There are various strategies we can use to overcome these difficulties. Most commonly, we can develop a “subsetting script” alongside the actual database, evolving with the two together. Even before the first release, you can prepare the script, using generated data in the database to test it. This will ensure that we discover all the snags, such as hierarchies, views, and enumerations as they appear, and understand how to work around them. Because the sensitive and personal data will have been identified early in the development process, it’s much easier to anonymize it and be confident you’ve not missed any of it. The scripting approach to subsetting isn’t generally seen as ideal because it is often suspected of being a distraction from development work, but I’ve seen it done very effectively.
To avoid scripting, there are many tools on the market for database subsetting, some produced by the publishers of the RDBMSs and others by third parties. Automated tools can assist in the extraction and maintenance of database subsets, help streamline the process, and reduce the risk of errors, but few tools claim to be able to work without some extra knowledge of the database beyond the metadata. Subsetting tools can be effective as long as the users are aware that the database might need to be altered to add missing foreign key constraints or the tool might need quite a lot of extra ‘configuration’.
Create a subset of the entities represented by the database
Most subsetters that are integrated into the development process, whether tools or scripts, need to be able to assess the distribution of data and be aware of the location of data that must be anonymized. They determine the subset by starting with a named table, often called a ‘parent table’. Usually, but not always, this will have no foreign key references to it. This table will represent an entity that has foreign key references to other tables that can be followed from relation to relation as a network. This isn’t strictly a tree structure: the relational model allows for more flexibility, and cycles (non-tree structures) can exist These cycles can form connected components such as a subgraph in which each pair of keys is connected to each other possibly via a path, or a relationship across multiple rows of the table.
This ‘net’ catches all the relations that are associated with each entity, like fish being hauled into a trawler. However, most databases will have several such trawls using different nets (DAGs), all seemingly independent. This can happen when some relationships are not reflected by foreign key constraints. It will also happen if more than one ‘domain’ is being represented within the database. If this is the case, then it is going to be difficult to do any meaningful subsetting without a mass of configuration information. Because real-life databases will inevitably reflect the human frailties of the developers and users of them, subsetter applications will rarely be able to establish a perfect subset without extra configuration.
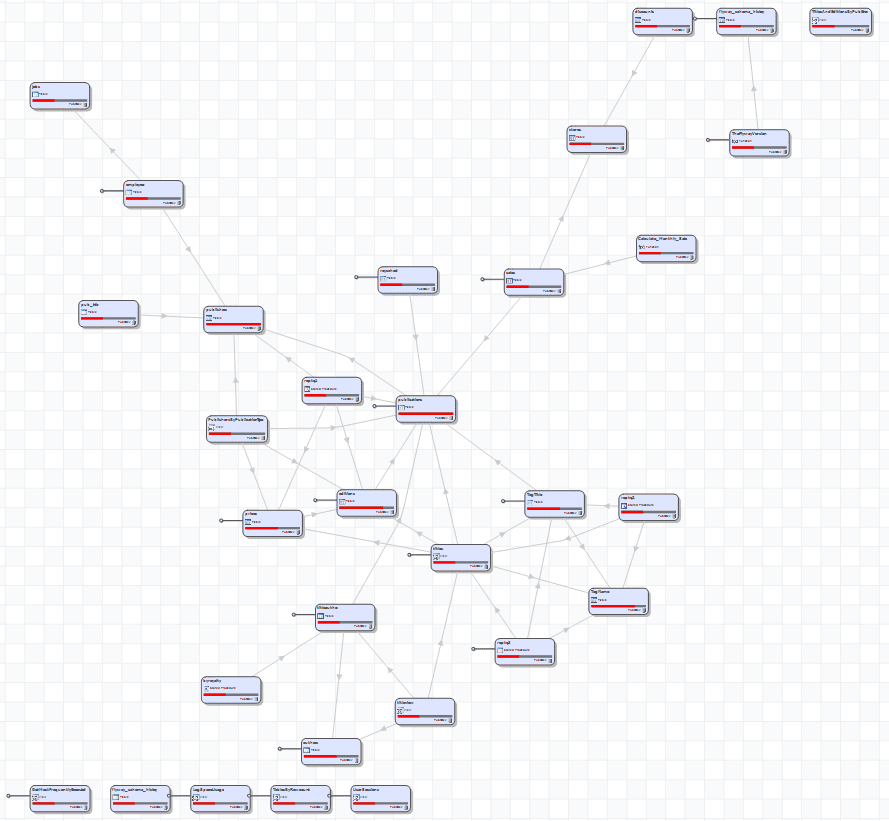
A network map of the extended sample Pubs database
Having worked out the ‘network’ of relationships, the subsetter can extract the entities, complete with their associated data. Starting with the key fields of the parent table that are selected for the subset, this is done using queries that uniquely select the key fields in the target table that are referenced by the source table. The routine navigates the network, picking the referenced key fields of each node in turn. Once all the key fields are harvested, then the relevant rows can be extracted, anonymized where necessary, and exported.
Omitting unused data from the test data.
To reduce the size of a database, it is often a better strategy to choose to extract all the data from each table that is relevant for the entities that are required. Tools aren’t much use for assessing what is relevant, but it is a good start to check out tables that aren’t referenced by a foreign key constraint. They may be parent tables but could be unimportant.
Many large databases are like an adolescent’s untidy bedroom. You know where the junk is hiding and that it has absolutely no relevance to the functioning of the child, but it is hard to devise a process to detect it all. For example, data about events that have only historical interest aren’t particularly relevant to day-to-day usage because they don’t cause a critical failure that compromises the service, However, they can cause problems for reporting applications that aim at detecting historical trends, and they can trigger failures for testing. .
A database can be transformed from the obese to the svelte by leaving out the archived, historic, logged or hoarded. Has a data retention policy been neglected? A script can be written that transfers only the relevant data, a bit like moving the adolescent to a different bedroom. This can prove to be a more effective and immediate method of slimming down a database than any subsetting process.
Data generation: an alternative data strategy
I’ve worked for banks, financial services organizations, and government departments where a request for a subset of live data is doomed. They don’t buy the argument that if you mask the personal data, the data is fine for development work. They stare at you, shake their heads, and mutter about such things as inference attacks. It was much easier to postpone the tests that required that full data until Staging. We survived by becoming competent in the art of data generation. The data distribution statistics of the real data can be exported to help with this, along with any other aggregated data that you need to improve verisimilitude.
The preparation of generated datasets is essential anyway in development before the first release. There is no production data. Instead of using production data in subsequent releases, the team gets the habit of developing the data generation techniques hand-in-hand with the database. It sounds more difficult than using production data but then you can leave your laptop absent-mindedly on the train without the panic of costing your employer a punitive fine for a data breach.
Conclusion
Subsetting databases can be a useful way of providing test data, but the process isn’t guaranteed to work reliably without adding configuration data to assist the process, and it doesn’t avoid the potential issues of using production data. It is a tool in a database developer’s workshop, along with data generation and data obfuscation. Before embarking on a subsetting process, it is useful to sit back and assess how you’ll provide these extra configuration details, as well as considering alternative possible strategies for fixing the problem.
Although Subsetting, Data generation, and Anonymization are often presented as different tasks, they all have to come to grips with the model of the relationships between tables, understand the constraints. In some cases, the extraction of data must come to grips with all three processes, especially where data must be anonymized or pseudonymized. Whenever you are faced with such tasks, it can be a very educational experience that can make errors in the entity-relationship model of the database embarrassingly obvious.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments