
Are you a hardcore C# developer who dreams in CLR? Great, you can skip the rest of this review, that is, unless you’re interested in saving hours and hours of time and effort. Everyone else (and those CLR people who stuck around), I have an interesting piece of software for you to take a look at. It’s a collection of CLR functions for your database server. Hey! Get back over here. Throwing your arms up in the air and screaming “No CLR in my server” is hardly a professional way to act. For crying out loud, hear me out.
Yes, it’s a collection of CLR functions (I like saying that because I know it makes you twitch). Yes, they’re going to run on your database. But the guy who wrote them isn’t nuts or stupid. These are exactly the types of functions that having CLR within the database is supposed to provide you. We’re talking string manipulation, regular expressions, user defined aggregates, date functions, exactly the kind of thing you would want to write CLR functions for. There are also those that I as a DBA would term ‘unfortunate’ functions, like some operating system types of functions that I’ve never been comfortable having in the database server, ever, although, you don’t have to install these OS functions. But, if you’re going to have OS functions running through your T-SQL, better to use something like SQL# rather than trying to make command line calls from T-SQL. Seriously, this is some cool stuff. Let’s talk about it.
Install
The install was a snap. I downloaded the free version from SQLSharp.com. It’s just a T-SQL script zipped up for easy transport. When you open it, it tells you that you need to pick a database to install it to, and remove a comment. That’s it. I tried it out, and it was that simple. I suppose, if I were brave, I would have installed it to the master database so that I’d have all the functions available in any other database on the system, but it’s not something I’d recommend (not without extensive testing). But I didn’t have a virtual I was prepared to destroy (in case things went south), so I created a database called Sharp and used that. This is what SQL# recommends.
The install went off without a hitch. It really was simple. The server I installed it to was still set up with the defaults, out of the box, meaning, I hadn’t enabled or in any way modified the CLR configuration. When I made the decision to perform the install, I didn’t think about this fact. But the install took care of it for me, validated the condition of my server and enabled CLR.
After installing SQL#, you’re running CLR in safe mode. This means it largely operates like all your other stored procedures. You can’t access the internet or stuff like that. So if your security needs are such that this is a concern, worry no more. To get out to the internet, you have modify the security settings to allow for that, intentionally. You can’t do it by accident.
With the software installed, it was time to play.
Use
Believe it or not, I read documentation. I started reading through the SQL# document. The first set of functions are all about using REGEX. I’ll get back to them. I’ve never been a regular expressions fan, although I’m sure I should be. Regardless, I wanted to play. The next section was on string manipulation. Now there’s something I could sink my teeth into. The first function was String_Contains. This is basically a replacement for performing a LIKE operation with wild cards before and after. Great! Here’s my first query:
|
1 2 3 |
SELECT * FROM Person.Address AS a WHERE Sharp.SQL#.string_contains(a.AddressLine1, 'Street') = 1; |
It worked. Right out of the gate. So far, so awesome. Now, if you know me, you know what I did next. That’s right. I took a look at the execution plan:

I really can’t help it. It’s one of the first things I do with any new query or query construct that I see. I wasn’t at all surprised by the plan. I expected a scan of some sort. But here’s the question, how does it compare to using the LIKE operator? Let’s see. Here’s the equivalent query:
|
1 2 3 |
SELECT * FROM Person.Address AS a WHERE a.AddressLine1 LIKE '%Street%'; |
I ran this and generated the execution plan:

Whoops. When reading an execution plan, extra operators are a flag for potential performance issues. We have extra operators at play here. How does the performance measure up?
The SQL# function returned in about 550ms and the LIKE statement returned in about 200ms. That’s a substantial difference.
Before you CLR guys get all up in my face, I realize, this test is not entirely fair. Why, the T-SQL nuts are asking? Because, very simply, we shouldn’t be using CLR to do something we can already do in T-SQL. Besides, the string_contains function is case sensitive. To really match them up, we’d have to modify the collation within the query, like so:
|
1 2 3 4 |
SELECT * FROM Person.Address AS a WHERE a.AddressLine1 LIKE '%Street%' COLLATE Latin1_General_CS_AS; |
However, that doesn’t change the execution plan, the results, or the execution time.
Let’s look at some other string manipulation queries.
Cool. How about this one, String_Cut. It emulates a function available in UNIX called cut and it breaks up values by a delimiter and returns the ones you specify. Still using the Address table, let’s eliminate the street number from the vast majority of our addresses. We’ll take the second word up to the last word in the AddressLine1 column:
|
1 2 3 |
SELECT Sharp.SQL#.string_cut(a.AddressLine1, ' ','2-'), a.AddressLine1 FROM Person.Address AS a; |
Oh sure, you can write T-SQL to get that too, but not as easily, but fine, let’s take only the second and fourth words:
|
1 2 3 |
SELECT Sharp.SQL#.string_cut(a.AddressLine1, ' ','2,4'), a.AddressLine1 FROM Person.Address AS a; |
Why would you want to do this? I haven’t a clue, but try doing it in T-SQL. I know that you could, but that function would be some seriously ugly code. This is quick & simple.
Enough with the strings; How about some maths? Here’s a silly query to measure the distance between two points:
|
1 2 3 4 5 |
SELECT a1.SpatialLocation.STDistance(a2.SpatialLocation) FROM Person.Address AS a1 JOIN Person.Address AS a2 ON a2.AddressID = 2 AND a1.AddressID = 1 |
The return values for spatial queries such as this are in meters. I’d rather see it in miles. I could go and lookup up the conversion rates and code calculations on my own to figure it out. But I’m lazy so:
|
1 2 3 4 5 6 |
SELECT a1.SpatialLocation.STDistance(a2.SpatialLocation), Sharp.SQL#.Math_Convert(a1.SpatialLocation.STDistance(a2.SpatialLocation),'meter','mile') FROM Person.Address AS a1 JOIN Person.Address AS a2 ON a2.AddressID = 2 AND a1.AddressID = 1; |
For the results:
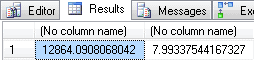
Now that I like. And yes, before you ask, I checked out the execution plan and nothing changed. Performance was identical. The math functions are extensive and involved. I’m impressed with what’s been done here. The only concern it raises is whether or not the developer responsible for this code has done a good job. (Ed.: He has) Then I remember the last time I helped the kids with their math homework and I’m suddenly less concerned.
There are a whole slew of internet functions, download file, all the FTP functions, getting IP addresses from URLs & vice versa, pulling down HTML, etc. They really do cover the gamut of anything you might need to do here. Some of the best functions, such as FTP, are only available with the full version. Also, you have to change the security settings on your sever to allow ALLOW_EXTERNAL_ACCESS for the SQL# Assembly, but that’s not a big deal if you need this type of functionality and very easy to do since SQL# also provides you with a function to take care of it, SQL#_SetSecurity.
Some of the functions are not what you might immediately think of, but are actually very useful. For example, how would like to define a range of dates and a step value and get the dates generated for you? I would. I’m constantly trying to generate different kinds of test data for checking out different things and yes, I write T-SQL code to generate some of it, I use tools like Red Gate SQL Data Generator for others, but anything that helps, I’m in favor of. Here’s this piece of code at work:
|
1 2 3 |
SELECT * FROM Sharp.SQL#.Util_GenerateDateTimeRange('9/6/2011', '9/8/2011', 3, 'hour') ; |
And the results look like this:
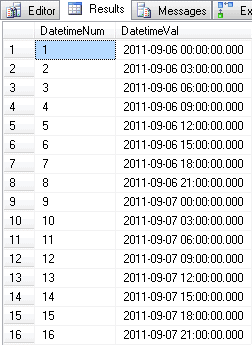
Stepping three hours at a time over the two days. And yes, I hear the T-SQL guru’s, there’s a way to do this with a tally table, but, see above, I’m lazy. If I can call a function, I will.
You can use SQL# to zip and unzip files. You can generate different kinds of hash values. They have the algorithms to determine if a credit card is a valid number for that credit card type (not whether or not it’s a real credit card number, you still have to contact an organization for that). This means you can at least validate the data prior to saving it in the database. It does the same kinds of validation routines for postal codes, check routing numbers and social security numbers. Nice functionality for the lazy among us.
How much work do you do with date values in SQL Server? Lots? Oooh, me. Let’s talk about calculating working days. Generally considered to be Monday-Friday, right? Here’s the classic method from Jeff Moden’s excellent article over on SQL Server Central:
|
1 2 3 4 |
SELECT (DATEDIFF(dd, @StartDate, @EndDate) + 1) -(DATEDIFF(wk, @StartDate, @EndDate) * 2) -(CASE WHEN DATENAME(dw, @StartDate) = 'Sunday' THEN 1 ELSE 0 END) -(CASE WHEN DATENAME(dw, @EndDate) = 'Saturday' THEN 1 ELSE 0 END) |
That’s just the basics. There’s a lot more extensive T-SQL to really start to take into account various holidays for different countries. But what if you’re using SQL#?
|
1 2 3 4 5 6 |
SELECT wo.DueDate, wo.EndDate, Sharp.SQL#.Date_BusinessDays(wo.DueDate, wo.EndDate, 3), wo.WorkOrderID FROM Production.WorkOrder AS wo WHERE wo.EndDate > wo.DueDate ; |
I went ahead and put the whole thing into a query because otherwise it wouldn’t look like anything. And yes, that just excluded Saturday and Sunday and it was all in a single statement. I’m a happy man. You can have it calculate a lot more. Here’s a spreadsheet showing how many business days it can calculate based on things like New Year’s day being on a Monday-Friday or calculating when Memorial day is. It’s great, and my code changes in a single spot, the last value in the function. Also, because it works largely off calculations and not from a list, you don’t have to sweat the list every year. Again, I’m a happy man.
There are just tons and tons of date functions to choose from.
Then there are all kinds of file manipulation functions (available in the paid product) for copying files around and other functions. Would I want to do these things from the database? No, but we all know where we’ve been in situations where we’ve had to. Would I rather use a tool like this than running extended stored procedures? Absolutely!
I can keep going with all the functionality that I got to play with, cool stuff like the ability to export a database to a set of data files (or pick and choose parts of the database) and, with the pay version, generate sets of INSERT statements, or conversion methods that aren’t in the system, or some interesting aggregations such as median or geometric average, or user defined types like hash table… Where to stop is the hard part. Ah, I know. Here’s one more function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @ConsumerKey NVARCHAR(100) = 'w', @ConsumerSecret NVARCHAR(100) = 'x', @AccessToken NVARCHAR(100) = 'y', @AccessTokenSecret NVARCHAR(100) = 'z', @StatusID BIGINT SET @StatusID = SQL#.Twitter_Update(@ConsumerKey, @ConsumerSecret, @AccessToken, @AccessTokenSecret, 'My database server''s in ur twitter stream messin wif ur tweets', NULL, NULL, NULL) ; SELECT @StatusID ; |
Yep, I can tweet from SQL Server thanks to SQL#. In fact, I sent that tweet out.
I can also pick up my twitter stream:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @ConsumerKey NVARCHAR(100) = 'w', @ConsumerSecret NVARCHAR(100) = 'x', @AccessToken NVARCHAR(100) = y', @AccessTokenSecret NVARCHAR(100) = 'z' , @StatusID BIGINT ; SELECT gft.StatusText, gft.Created, gft.ScreenName, gft.UserName FROM SQL#.Twitter_GetFriendsTimeline(@ConsumerKey, @ConsumerSecret, @AccessToken, @AccessTokenSecret, NULL) AS gft ; |
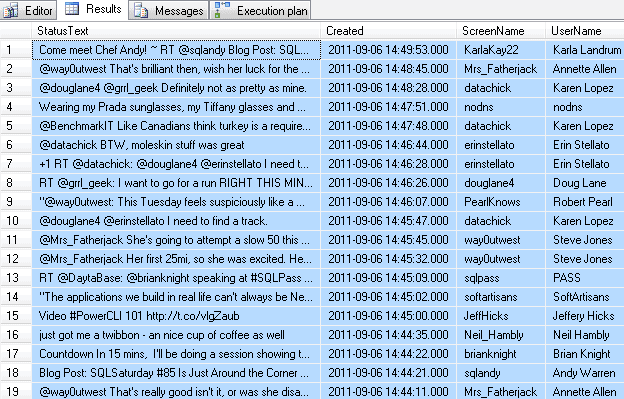
And yeah, I could keep going. That’s a fun toy, but I can imagine ways you could use it. For example, what if, you wanted to collect all the tweets that came through on a particular hash tag or about a particular account? You can get the tweets and put them into tables and then, you can start building reports and stuff. This really could be extremely useful.
To get the Twitter calls up & running was a little work, but that’s because of the Twitter API, not this software. You have to go to Twitter and create a custom application for SQL# to use. It was easy and there’s a set of documentation provided by SQL# on how to do it.
Overall, I’m really impressed with this code. I like the documentation, a lot. That’s saying something. Documentation is usually something you suffer with or suffer from, but I found this extremely useful, accurate, and usually had exactly what I needed when I went to look for it. Every function I tried worked, although not always the first time. I sometimes had to go and look at the examples & read the documentation to make things function correctly. This isn’t the end of the world, but this kind of stuff is never going to be provided by a completely intuitive use set of functions. You’ll have to look things up. Again, that’s not a dig against the product, it’s just a statement of fact.
Summary
Is SQL Sharp the greatest utility to ever be released for SQL Server? Nope. However, it’s good. It’s useful. You’re going to want to be cautious about its use, as you would with any CLR code in your databases, as you would with any third party product you’re putting on your systems. But, there is functionality in here that you can use. It works well. I think the methodology for the use of the code is very well thought out. I’m impressed and interested. I’m going to continue to try to find uses for this code because, remember, I’m lazy. I could go back and spend weeks rebuilding my C# skills and then develop my own CLR routines, but, for all the excellent stuff supported here, I don’t have to. I like that.
Solomon Rutzky, who wrote SQL#, is a Simple-Talk author who wrote the popular article CLR Performance Testing. He has also written extensively for SQL Server Central.
In response to this review, he has written the following, making the suggestion that perhaps SQLsharp has value for DBAs as well as developers, even with the functions that Grant and many DBAs will regard with some suspicion.
I find it hard to express what I believe to be the real benefit of the SQL# project. With over 200 functions to choose from it is daunting knowing where to start looking for which ones might have the most value for you. Clearly the Math, String, Convert, and RegEx functions are going to be the easiest to relate to since most of us do those types of things frequently. But there is, often enough, the lingering question of “why would you want to do ___ in the database” which would apply more so to the File, INET, DB, OS, Twitter stuff.
The basic idea is that I am trying to give people the building blocks for accomplishing their job without needing to rely on developers. Yes, anyone can argue about ideals such as separation of business logic into app code only, but at the end of the day there are thousands / tens of thousands of SQL Server DBAs/developers who have a job to get done. So if something needs to be accomplished, I am trying to facilitate that it can be accomplished.
For example, I came across this one day: An encouraging note to hopeless DBAs. It is an unsolicited forum post by a Full Version customer regarding GZip and FTP in particular. Here is an excerpt:
‘Since the compress and sendftp libraries were already *understood* by the engine, it finally took me 5 lines of code to set up the process while OO coders were (and are) still drawing ERD’s to code the two classes (XMLextractor and ObjectSender).’
I have several customers data-mining the feeds of their customers and some are even allowing their application to interact directly with those customers via xAuth. And I have some customers just posting stuff like system status, etc on their own feed.
One issue I ran into a few years ago was needing to do a nightly data dumb of lookup tables and I looked at using both SSIS and BCP. Both of them had a lot of what I needed but neither had the complete package. I needed to text-qualify only certain fields, it had to be fully dynamic in terms of the tables and their columns/datatypes, etc. So I created the DB_BulkExport proc that has most of the good features of both SSIS (well, the export part) and BCP. I wrote about it here: Exporting and Versioning Lookup Data: A Real-World Use of the CLR
Recently, one of the DBA’s at work need to write a procedure to manage DB backup files (from a 3rd party product) and need to see how old the current ones were. He is using xp_cmdshell to get the list of files. He found out the hard way that xp_cmdshell is not entirely predictable since his test machine is set up with a locale of 24 hr time but most of our machines have a locale using 12 hr time. So his script had to get a lot more complicated to handle both. However, had he been able to use SQL# and File_GetDirectoryListing he would have had the date value in a real DATETIME field to compare (and would not need to be doing text-parsing).
I also just noticed this featured script the other day in the SQLServerCentral.com email: Delete files older than n-days via T-SQL . Again some will argue that you shouldn’t be doing this stuff in the DB but clearly there is a huge need as so many people are doing stuff like this. His script is just over 100 lines long (I removed the comments) whereas with SQL# all of that logic, temp tables, correcting for OS versions, etc could be just a single query along the lines of:
|
1 2 3 |
SELECT SQL#.File_Delete(files.Location + '\' + files.Name) FROM SQL#.File_GetDirectoryListing(@StartingDirectory, @Recursive, @DirectoryNamePattern, @FileNamePattern) files WHERE files.LastWriteTime < (GETDATE() - 3) |
I have one customer using INET_GetWebPages to connect to a secured (via Basic Auth) URL daily to download a zip file to process. I updated INET_GetWebPages so that he was able to not only pass in the Basic Auth userid and password, but he also needed to set custom request header values that the server was requiring.
Recently a customer requested that I add Image manipulation functions to SQL#. This is something I had considered in the past but had no way of gauging the priority until now. So far I have functions to get the properties of the Image, convert it to another format, flip and/or rotate it, and generate a thumbnail from it. I will also be adding functions for Crop and Resize. Why would anyone want or need these? Well, I don’t know what the customer has planned specifically, but here is something I can think of. If you have a VARBINARY(MAX) field with image data, you could enforce size and/or format restrictions on the images. Maybe that can be done by the business layer on the way in, but what if this data is being imported via BCP or what if this is a one-time data-scrub on “legacy” data? One option is to write a .Net console application, write a stored procedure to get all of the images, for each one get the properties, if it needs altering then call the same .Net methods I am implementing, and then update each one via another stored procedure. Generally that update will be handled on a per-row basis. Yes, SQL Server 2008 and beyond allow for a Table-Valued Parameter to make it set-based, but unless you are doing the full streaming method which I suspect most people don’t know about (but it is documented here: Streaming Data Into SQL Server 2008 From an Application ), then it is keeping all of the rows to be updated in memory before ever calling the update procedure. Another approach would be to write a simple query along the lines of:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- convert images to PNG format if not already in PNG format UPDATE tbl SET tbl.ImageData = SQL#.Image_Convert(tbl.ImageData, 'png') FROM SomeTable tbl CROSS APPLY SQL#.Image_GetInfo(tbl.ImageData) info WHERE info.RawFormat <> 'png' -- resize image if larger than ideal size UPDATE tbl SET tbl.ImageData = SQL#.Image_Resize(tbl.ImageData, 800, 600) FROM SomeTable tbl CROSS APPLY SQL#.Image_GetInfo(tbl.ImageData) info WHERE info.Width > 800 OR info.Height > 600 |
The operations took less than 5 minutes to write, are set-based (well, as much as a CROSS APPLY can be), and easy to maintain. Please note that the SQL#.Image functions are currently in development and are not generally available.
Sorry if this note is a bit long, but I wanted to paint a broader picture of how SQL# can help people, including DBAs and not just developers.
Solomon Rutzky,





Load comments