
The Red Gate website – an ASP.NET site running on SQL Server 2000 – recently underwent a major overhaul. Here, Richard Mitchell and Steven Davidson, the developers on the project, describe how they used Red Gate’s database schema-comparison tool, SQL Compare, as an integral part of their project environment.
They used the tool to keep the development, test and live databases in synch, and to enable effective team development, without the necessity of manually scripting objects and writing update scripts for the source control system. The intent is to provide insight into an effective team development model, based around use of SQL Compare.
The project environment
There were two developers on the project and one tester. The project environment comprised two local development SQL Server databases (one for each developer), one test database (virtual), and the live production database:
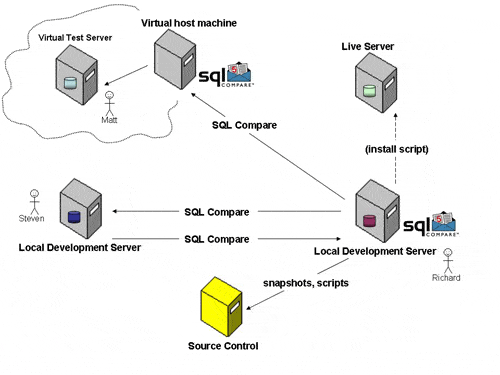
Note that the schema synchronizations were largely driven from a single local development machine (Richard’s server). While there is nothing to prevent you having SQL Compare installed on each machine, it does mean that only a single licence of SQL Compare is required to follow this model, assuming that, from the machine on which it is installed, SQL Compare can tunnel into the test environment.
In our setup, the test database was on a virtual machine. This is a “locked down” environment and the test server could not “see” either the production or local development servers. This meant that we ran a second copy of SQL Compare on the virtual host machine.
The SQL Compare development model
The development model proposed here is only one of many into which SQL Compare can be incorporated. However, it is one we’ve found, based on personal experiences with alternate models, to allow maximum productivity in a small development team, while maintaining a very high degree of reliability.
It can be described as follows:
- Before development begins the live production database is restored to each of the three SQL Server instances (the two local dev instances plus the test instance).
- A baseline schema snapshot is taken of the live database, using SQL Compare, and it is loaded into our Source Control system (Sourcegear Vault).
- Development begins on each of the local development machines.
- When a new build is ready to be rolled out to the test machine, SQL Compare is used to perform a two-way synchronization between the two development databases. So, for example, Richard would push the updated objects in his database over to Steven’s. Having done this, he would then compare Steven’s newly updated database with his own, and pull any different objects back to his own database. At this point, both development databases are up-to-date with all changes and are synchronized.
- A new snapshot of the local dev database is saved into source control
- SQL Compare is used to compare the live database (or the baseline snapshot) with the current local database. The “install script” that would synchronize the two schemas is scripted out and saved into source control.
- SQL Compare on the virtual host machine is used to synchronize the test database with the Richard’s local development database.
- Steps 4 to 7 are iterated until the final build is complete
- When the final build is ready, the live database is restored to the test machine and the final install script is executed on the test machine; final testing then takes place.
- The now-tested install script is run against the production database.
The push-pull synchronization between development machines (step 4) takes a matter of minutes. The synchronization scripts that SQL Compare generates include all required changes to dependent objects – and since there is no manual scripting, it is reliable and error-free. In essence, this is the true benefit of this model.
It should be noted that, since this development model is not driven from a source control system, there is a potential for merge conflicts in step 4. During the synchronization process, if both developers have updated the same database object then there is always a danger that one set of changes could be overwritten. SQL Compare can only tell you that two objects are different, and once synchronization is performed on a particular object, any changes that had been made to the object in the database at the sharp end of the synchronization arrow will be lost.
However, we’d consider merge conflicts to be a rare occurrence in a small development team, and this was not an issue that actually affected us. If there was ever any suspicion that the same object could have been amended by both developers during a given build cycle, then both developers would simply review the SQL Compare diff screen prior to synchronization.
We were able to perform schema synchronization between the local development and the test database (step 7) on a fairly ad-hoc basis. It obviously occurred at major project milestones and deliverables, but aside from that it was carried out “as needed”. During major development phases it might happen once a week; if we were on a bug-fixing run, it might happen several times a day.
If we’ve introduced a severe bug, gone down a dead end for a few days or need to change our approach, the SQL Compare snapshots, saved into source control (steps 2 and 5), provide a useful rollback mechanism. SQL Compare does not currently integrate directly with source control (i.e. SQL Compare schema snapshots are not “object-granular”), so on the odd occasion when we needed help pinpointing where a certain bug may have been introduced, we use a free, publicly-available tool called Scream. This tool is integrated into our source control system and allows us to see the differences between two SQL Compare snapshot files.
Note:
The current plan is that the next version of SQL Compare will integrate directly with source control systems.
When the final install script for the new website database was generated, the process of testing it and then installing it on the live server (steps 9 and 10) was seamless: we were certain that the database we created on the live server exactly mimicked the one we had developed.
SQL Compare development model vs. source control model
We can compare this development model with another common one, whereby individual database objects are scripted in and out of a source control system. When a new object is created, the developer creates a script for it and saves it in source control. As objects are modified, developers manually create an “update script” (a series of command to run SQL files and data inserts scripts) that will ultimately synchronize the live database with their development database.
When done well, the main advantage of the source control-driven model is that is gives you direct object-level version history and labelling. However, as any developer who has used this model will tell you: there are downsides too:
- The process of managing DROP/CREATE versus ALTER processes in source control is notoriously difficult due to the (often complex) object interdependencies.
- It is easy for a developer to forget to add a modified object to source control and/or to modify the update script appropriately.
The latter point, in particular, is a cause of frequent heartache and pain. It is inherently difficult to verify that the final update script is a true reflection of the final database.
These two pain-points simply disappear in the SQL Compare-driven model. All dependent objects are updated appropriately and there is never any doubt that the final update script is a true reflection of the tested database. It is hard to over-estimate the number of development hours that this has saved us.
Of course, if you do need to drive your development from source control, then it is perfectly valid to integrate SQL Compare into the source control model once the final update script is generated. You could run the update script against a staging server and then use SQL Compare to verify that the newly created database is an accurate reflection of the final development database. SQL Compare is versatile in terms of the number of different development models into which it can be incorporated.
Other development techniques
Following are two techniques that could be incorporated in order to further improve this development model.
Making data changes
After making some schema changes, it is often necessary to load in certain data to support those changes. For example, the new download process on the Red Gate website is no longer an immutable series of steps; it is entirely data-driven. Obviously if the supporting data were not inserted, then there would be no download process!
We used SQL Data Compare to generate lookup table scripts and compiled them into a “post update” script that was run after a schema update. Depending on the size of the data class, it’s probably possible to do this by hand.
Of course, taking this a step further, it would be nice if insertion of the necessary data were an integral part of the SQL Compare model.
Pulling the latest schema onto the test machines
In our model, updates were pushed to the virtual test machine from the local development machine. While this afforded a good deal of control over the process, it would be useful for the tester to be able to pull the latest schema file from source control onto the test machine and then use it to synch up their local test database. This is fairly easy to achieve via a batch file on the test machine that would pull the latest binaries from the continuous build environment (the zip file would include the latest snapshot from local development). The binaries would be deployed and then SQL Compare Pro (command line) could be used to synch the test database with the latest snapshot.
Summary
The bottom line for us is the certainty and flexibility that SQL Compare brings to the development process. It allows us the freedom to work in an independent, but co-ordinated fashion, the main reason being that synchronizing each of our local development databases is reduced from a potentially time-consuming and error-prone task to a couple of button clicks.
When we push changes from development to test, we know that the schema they’ll be testing against is exactly the same as the one we developed. If one of us is on a longish development cycle, the other can fix a few bugs, and push the new build, complete with schema changes, over to the test machine in a matter of minutes.
The development model that we’ve outlined here is tried-and-tested and is, we hope, one that will help you use SQL Compare in a highly productive and effective manner. However, it is only one of a number of models into which SQL Compare could be easily incorporated.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments