
Using Stored Procedures as an Ap
It is not a trivial matter to build the sort of multi-tier, web application that every corporation seems to want. It is too easy to end up with a morass of extremely complicated code that is difficult to get working correctly even with extensive testing, and it can furthermore be quite challenging to maintain it in production.
T-SQL Stored Procedures (SPs), along with some views and functions, are a useful way to encapsulate and implement most of an application’s business logic, especially that which retrieves the underlying data from the tables (master or transaction), and/or updates it. This is useful because:
- It allows the database developer to work fairly independently of the application developers.
- It means that the application developers could concentrate their efforts on getting the best possible user-interface without needing to understand the relational design of the base tables within the database.
- It provides a logical abstraction of the database that could be ‘mocked up’ to assist with testing.
- It allows a much more robust security regime for the database that reduces the likelihood that SQL Injection can occur.
I will describe two basic templates that can be used for many commonly-seen forms and web pages, which can then be elaborated as required.
Occasionally in this article I will refer to an application that my company recently and successfully developed using this approach, along with the reasons why it was successful. Without going too far into the details, I can say that in my 7+ years of experience with this company, this application ranks within the top three or four in complexity among all of those I’ve been intimately involved with. It was the culmination of refining the approach I will describe, and it was successful because it was delivered with minimum staffing, on-time and within budget. While it has not been in production long enough yet to fully assess customer satisfaction levels, initial reception has been promising and that is no mean feat considering it was designed to replace a legacy system that had been in use for over twenty years.
Now that I’ve established those rather lofty expectations, let’s start by explaining the basic idea within a common business requirement.
The Header/Details Form Pattern
I’ll start by describing, as an example, a relatively simple but common business document, an invoice, after which I’ll flesh out the T=SQL that would implement its’ functionality.
There are two parts to an invoice: header and details.
In the invoice’s header, you’ll normally find at least the following information
- An invoice number, which is often the primary key in the underlying table and is usually system-generated.
- The invoice date.
- The customer to which the invoice will be sent.
- That customer’s billing details.
There may also be other sundry information that you may think of as being part of an invoice’s footer, because they appear at the end of the physical document once printed. In reality, these are stored with the header. This does not include the invoice total, which is derived by summing the details.
In the invoice’s details, there will be:
- A line number, or some other way of sequencing the detail lines of the invoice and which uniquely identifies each detail line as unique.
- An item code (the product description would normally be retrieved by joining the item code back to the item table).
- Quantity of the item.
- Price of the item (unit price).
- Extended price, or the product of quantity and price which, being derived from them, need not be actually included in the table.
Here is an example of a typical User-interface form that could be designed to create/maintain an invoice.
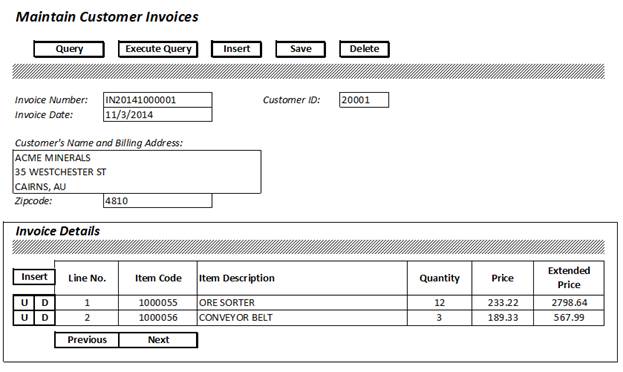
There are several buttons on this form, each of which represent an action that the user can take. This form would initially be in “query mode,” meaning that the user enters the filtering criteria that are required to retrieve the unique invoice record and then presses ‘Execute Query’. The ‘Query‘ button returns the form to the ‘query mode’. Alternatively, the ‘Insert‘ button may be used to create a new invoice, with the invoice number being auto-generated upon clicking ‘Save‘. We’ve also offered our user the means to ‘Delete‘ an invoice
In the ‘Invoice Details’ section, users have the options to update or delete an existing row (U and D buttons), or insert a new row, all through the action buttons provided. Most modern web applications will replace the buttons with cute icons, with context-sensitive help text that appears as you hover the mouse over them, but the concept remains the same.
The shaded patterns on the form represent text-panels where error messages may be displayed, so you see one panel below the action buttons, for errors that occur when processing the header, and also one above the grid for errors on actions on the details.
Let’s also mention the basic business rules for using the form.
- In order to query (retrieve) an invoice, that invoice’s number must be supplied.
- To create a new invoice, the customer ID must be entered before pressing the ‘Insert’ button, so that the existing customer details can be used to populate the relevant default values on the form.
- The invoice number for a newly-created invoice is generated when it is first saved. The format is “IN” plus the year of the invoice, plus a running number that must be unique.
- The user may change the billing information (e.g., the customer name, address, etc.) with those changes to be applied to the single invoice only.
Implementing Form Actions through SPs
We can develop two Stored Procedures (SPs) that will together support the functionality of this form. The first is implemented to perform all of the allowable form actions (buttons) for the header record, including a cascade delete of the details/header if that is required. The second, somewhat simpler, SP is developed to support maintenance of the details. Even though the ‘details’ SP is simpler, it will follow the same template or pattern as for the header SP. We will discuss the differences later.
The design of the SPs is intended to insulate those who are developing the forms from needing to know about the details of the physical implementation of the data in the relational tables.
This will allow DBAs to set access rights to allow only execute privileges on SPs, giving access to the data indirectly via ownership chaining, without having to assign rights to insert, update, delete, etc. directly against the tables (or views). This effectively prevents almost all possibility of SQL Injection attacks.
So far, other than my rather vague statement that the SPs “implement each of the form’s actions,” I haven’t mentioned precisely what the SPs will actually do. This should become clear as we review the template in the next section, but one thing that I’ll mention right now is that the SPs must return something.
For our invoices form, the header SP should return three tables:
- What I will call the “ReturnErrors” table, which delivers results from audits performed in the SP.
- A table consisting of zero or one row with columns of data that represent the header information, and any additional derived data based on that.
- A third table that consists of the invoice details, with columns that are consistent with the data appearing in the details grid.
If you are using .Net as your development environment, you can make that front-end code retrieve data from all three of the tables mentioned above (or more if needed). I will not go into the details on how this is done, because I’m not a .Net developer. Suffice it to say that a dataset or OdbcDataReader will store all tables returned by a stored procedure in one action.
An Invoice Header SP Template
Below we have a template that can be used generically for any “header” type set of actions such as defined for our form, created specifically to maintain our invoice header. There’s a few comments interspersed with the code to help you follow along and a more detailed description at the end.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 |
CREATE PROCEDURE [dbo].[Maintain_Invoice_Header] -- ============================================================================= -- Author: Dwain.C -- Create date: 15-Nov-2014 -- Description: This is a template for an SP that maintains the header of an -- invoice document. /* Comment blocks */ are explanations of the -- sections of the template and should be removed in a customized -- version of the template. -- ============================================================================= ( /******************************************************************************* ** Parameters Section ** Which includes: - An @action variable that corresponds to form actions (buttons), along with any other parameters such as the user that is performing the action, which could be used to maintain a record of the person performing the change. - The filtering criteria (in this case @InvoiceNo), which could be more than one form field, in which case either parameter must return a unique result. - The data values (form fields) which will be updated on that action. Note that this includes @InvoiceNo, which is required on save (if the invoice exists) and delete. After the @action variable, default values for all parameters are defaulted to NULL, because the SP will validate (audit) that appropriate values are provided on each specific action. It is a best practice to call this SP using specified parameter names rather than assuming that the positional placement won't change. Note that data parameters (including @InvoiceNo) should be identical to the data types for the underlying table's columns, so that when you publish the SP's call signature the developers know how that data is stored in the front-end code. *******************************************************************************/ -- @action=0 Query, =1 Insert, =2 Update/save, =3 Delete @action TINYINT ,@InvoiceNo VARCHAR(20) = NULL ,@InvoiceDate DATE = NULL ,@CustomerID VARCHAR(20) = NULL ,@CustomerName VARCHAR(100) = NULL ,@CustomerAddr1 VARCHAR(100) = NULL ,@CustomerAddr2 VARCHAR(100) = NULL ,@CustomerZipcode VARCHAR(10) = NULL ) AS BEGIN; SET NOCOUNT ON; /******************************************************************************* *** Declarations Section *** This includes some local control variables (@Error_Code and @Error_Message will always be among them) and a table variable that is identical in format to the underlying table we are maintaining, but without the PRIMARY KEY, FOREIGN KEYS (or other constraints), which allows NULL values in any column. Note that for a table that has lots of columns, it is a good practice to use SQL Server Management Studio (SSMS) to script the CREATE TABLE statement and then edit that result down for the table variable to ensure that column data types are consistent. *******************************************************************************/ DECLARE @Error_Code INT = 0 ,@Error_Message VARCHAR(MAX) ,@NextInvoiceNo BIGINT ,@InvoicePrefix VARCHAR(5); DECLARE @Invoice TABLE ( InvoiceNo VARCHAR(20) NULL ,InvoiceDate DATE NULL ,CustomerID VARCHAR(20) NULL ,CustomerName VARCHAR(100) NULL ,CustomerAddr1 VARCHAR(100) NULL ,CustomerAddr2 VARCHAR(100) NULL ,CustomerZipcode VARCHAR(10) NULL ); /******************************************************************************* *** Parameters Cleansing Section *** Convert blank values to NULL, transform any other values to something appropriate for the @action, etc. *******************************************************************************/ -- Cleanse/transform the input parameters SELECT @action = CASE WHEN @action IN (0, 1, 2, 3) THEN @action ELSE -1 END -- Convert blanks passed to parameters to NULL -- in case the developers didn't ,@InvoiceNo = NULLIF(@InvoiceNo, '') ,@CustomerID = NULLIF(@CustomerID, '') ,@CustomerName = NULLIF(@CustomerName, '') ,@CustomerAddr1 = NULLIF(@CustomerAddr1, '') ,@CustomerAddr2 = NULLIF(@CustomerAddr2, '') ,@CustomerZipcode = NULLIF(@CustomerZipcode, ''); /******************************************************************************* *** Parameters Auditing Section *** Parameters auditing generally occur in these three parts in this sequence: 1. Control audits: These audits are performed to make sure that appropriate parameters are passed to the SP on the specific actions. Generally in a production application you would not see these messages returned to the form, because they represent cases where the developer did not call the SP correctly (so should be corrected during forms testing). 2. Simple data audits: Includes things like making sure required values (NOT NULL in the database table) are provided, consistency checks between data elements, i.e., anything that does not require a validation against the database. Another example is auditing a data element against the CHECK constraint for the underlying column. 3. Complex data audits: These are any audits requiring validating that a specified parameter is valid based on existing rows in other table. For example, making sure FOREIGN KEY constraints are met. It may be necessary in some cases to perform audits of typs 3 mixed in with audits of type 2 when it is necessary to do several validations in a specific sequence. That is permissible, but generally when possible the sequence should be adhered to. Always check that @Error_Code still equals zero before you perform the next audit. This is especially important for complex audits to avoid multiple retrievals from the database (keeps the performance up). When commenting any particular audit, specify what the data should be, i.e., the opposite information from what the code audit performs (what the data should not be). This adds clarity. *******************************************************************************/ /******************************************************************************* *** Perform Type 1 (Control) audits *******************************************************************************/ -- After cleansing, @action should be 0,1,2,3 IF @Error_Code = 0 AND @action NOT IN (0, 1, 2, 3) SELECT @Error_Code = 1; -- @InvoiceNo required on query or delete IF @Error_Code = 0 AND @action IN (0, 3) AND @InvoiceNo IS NULL SELECT @Error_Code = 2; -- @InvoiceNo not allowed on insert (generated on save) IF @Error_Code = 0 AND @action = 1 AND @InvoiceNo IS NOT NULL SELECT @Error_Code = 3; -- @CustomerID is required on insert IF @Error_Code = 0 AND @action = 1 AND @CustomerID IS NULL SELECT @Error_Code = 4; /******************************************************************************* *** Perform Type 2 (Simple Data) audits *******************************************************************************/ -- Validate required (NOT NULL) fields on update/save IF @Error_Code = 0 AND @action = 2 AND @InvoiceDate IS NULL SELECT @Error_Code = 5; ELSE IF @Error_Code = 0 AND @action = 2 AND @CustomerID IS NULL SELECT @Error_Code = 6; ELSE IF @Error_Code = 0 AND @action = 2 AND @CustomerName IS NULL SELECT @Error_Code = 7; ELSE IF @Error_Code = 0 AND @action = 2 AND @CustomerAddr1 IS NULL SELECT @Error_Code = 8; ELSE IF @Error_Code = 0 AND @action = 2 AND @CustomerZipcode IS NULL SELECT @Error_Code = 9; /******************************************************************************* *** Perform Type 3 (Complex Data) audits *******************************************************************************/ -- Check that the invoice exists IF @Error_Code = 0 AND @InvoiceNo IS NOT NULL AND NOT EXISTS ( SELECT 1 FROM dbo.Invoices WHERE InvoiceNo = @InvoiceNo ) SELECT @Error_Code = 10; -- Confirm foreign key constraints before saving IF @Error_Code = 0 AND @CustomerID IS NOT NULL AND NOT EXISTS ( SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID ) SELECT @Error_Code = 11; /******************************************************************************* *** Actions Section *** This section processes each possible action the user can specify by a button push on the form. Only process actions if @Error_Code = 0. Note that the Insert @action does not really put any data into the underlying table. All it does is populate default values for each column for display on the form. The invoice number is not generated until a save action occurs. *******************************************************************************/ -- Perform the Query @action (=0) IF @Error_Code = 0 AND @action = 0 -- Store query results in the table variable INSERT INTO @Invoice ( InvoiceNo, InvoiceDate, CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode ) SELECT InvoiceNo, InvoiceDate, CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode FROM dbo.Invoices WHERE InvoiceNo = @InvoiceNo; -- Perform the Insert @action (=1) IF @Error_Code = 0 AND @action = 1 -- Store default values in the table variable INSERT INTO @Invoice ( InvoiceNo, InvoiceDate, CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode ) SELECT NULL, GETDATE(), CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode FROM dbo.Customers WHERE CustomerID = @CustomerID; -- Perform the update (and actual Insert) and delete @actions (=2 and 3) IF @Error_Code = 0 AND @action IN (2, 3) BEGIN /******************************************************************************* *** Additional Explanation for the Actions Section *** Below is the code that actually updates the underlying tables. Always wrap this in a TRANSACTION with appropriate error handling using TRY/CATCH. MERGE (available in SQL 2008 onwards), is quite useful to minimize the number of actual SQL statements you need to write to maintain the underlying table. The Counters table (or a SEQUENCE if you're using SQL 2012) generates the next available invoice number when @InvoiceNo is NULL on save (basically on an INSERT to the underlying table). The UPDLOCK hint locks that row of the table until the TRANSACTION completes, to avoid duplicate invoice numbers. *******************************************************************************/ BEGIN TRANSACTION T1; BEGIN TRY; IF @InvoiceNo IS NULL -- Generate the next invoice number here UPDATE dbo.Counters WITH(UPDLOCK) SET @NextInvoiceNo = CurrentValue = CurrentValue + 1 ,@InvoicePrefix = IDPrefix WHERE CounterID = 'Invoices'; -- Cascade delete of the details IF @action = 3 DELETE FROM dbo.Invoice_Details WHERE InvoiceNo = @InvoiceNo; -- And now perform the save/delete (t=target table, s=source table) MERGE dbo.Invoices t USING ( SELECT InvoiceNo = ISNULL(@InvoiceNo, @InvoicePrefix + CAST(YEAR(@InvoiceDate) AS CHAR(4))+ CAST(@NextInvoiceNo AS VARCHAR(20))) ,InvoiceDate = @InvoiceDate ,CustomerID = @CustomerID ,CustomerName = @CustomerName ,CustomerAddr1 = @CustomerAddr1 ,CustomerAddr2 = @CustomerAddr2 ,CustomerZipcode = @CustomerZipcode ) s ON s.InvoiceNo = t.InvoiceNo WHEN MATCHED AND @action = 3 THEN DELETE WHEN MATCHED AND @action = 2 THEN UPDATE SET InvoiceNo = s.InvoiceNo ,InvoiceDate = s.InvoiceDate ,CustomerID = s.CustomerID ,CustomerName = s.CustomerName ,CustomerAddr1 = s.CustomerAddr1 ,CustomerAddr2 = s.CustomerAddr2 ,CustomerZipcode = s.CustomerZipcode WHEN NOT MATCHED THEN INSERT ( InvoiceNo, InvoiceDate, CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode ) VALUES ( s.InvoiceNo, s.InvoiceDate, s.CustomerID, s.CustomerName ,s.CustomerAddr1, s.CustomerAddr2, s.CustomerZipcode ) -- Use OUTPUT to capture the updated results -- Note that on DELETE, all of these values will be NULL OUTPUT INSERTED.InvoiceNo, INSERTED.InvoiceDate, INSERTED.CustomerID ,INSERTED.CustomerName, INSERTED.CustomerAddr1 ,INSERTED.CustomerAddr2, INSERTED.CustomerZipcode INTO @Invoice; END TRY BEGIN CATCH; -- Some basic error handling SELECT @Error_Code = ERROR_NUMBER() ,@Error_Message = ERROR_MESSAGE(); PRINT 'Merge to Invoices table'; -- Useful information for debugging PRINT 'ERROR_NUMBER() '+ CAST(ERROR_NUMBER() AS VARCHAR(10)); PRINT 'ERROR_SEVERITY() '+ CAST(ERROR_SEVERITY() AS VARCHAR(10)); PRINT 'ERROR_STATE() '+ CAST(ERROR_STATE() AS VARCHAR(10)); PRINT 'ERROR_PROCEDURE() '+CAST(ERROR_PROCEDURE() AS VARCHAR(8000)); PRINT 'ERROR_LINE() '+ CAST(ERROR_LINE() AS VARCHAR(100)); PRINT 'ERROR_MESSAGE() '+ CAST(ERROR_MESSAGE() AS VARCHAR(8000)); PRINT 'XACT_STATE() '+ CAST(XACT_STATE() AS VARCHAR(5)); END CATCH; IF @Error_Code <> 0 OR XACT_STATE() = -1 ROLLBACK TRANSACTION T1; ELSE IF @Error_Code = 0 AND XACT_STATE() = 1 COMMIT TRANSACTION T1; END; /******************************************************************************* *** Returned Tables Section *** The table names you can reference in the front-end code. In this case: 1. ReturnErrors - an error message suitable for display on the form 2. InvoiceHeader - All columns needed to refresh all form fields in the invoice header. 3. InvoiceDetails - All columns needed to refresh all fields in the grid showing the invoice details. *******************************************************************************/ -- This SP returns 3 tables to the front end: -- ReturnErrors -- InvoiceHeader -- InvoiceHeader -- ReturnErrors: whether the action was successful WITH ReturnErrors (ErrorCode, ErrorMessage) AS ( SELECT 0, 'Requested Operation Successful' -- Audit failures UNION ALL SELECT 1, 'Invalid action specified' UNION ALL SELECT 2, 'Invoice number is required for this action' UNION ALL SELECT 3, 'Invoice number is not allowed for this action' UNION ALL SELECT 4, 'Customer ID is required for this action' UNION ALL SELECT 5, 'Not saved - Invoice date is required' UNION ALL SELECT 6, 'Not saved - Customer ID is required' UNION ALL SELECT 7, 'Not saved - Customer name is required' UNION ALL SELECT 8, 'Not saved - Customer address is required' UNION ALL SELECT 9, 'Not saved - Customer zipcode is required' UNION ALL SELECT 10, 'Specified invoice number does not exist' UNION ALL SELECT 11, 'Specified customer ID does not exist' UNION ALL -- For this case @Error_Code contains a SQL error (e.g., deadlock) SELECT @Error_Code, @Error_Message WHERE @Error_Code NOT BETWEEN 0 AND 11 -- End of the BETWEEN range must correspond to the number of audit -- failure error messages above ) SELECT ErrorCode, RequestedAction=@action, ErrorMessage FROM ReturnErrors ReturnErrors WHERE @Error_Code = ErrorCode; -- InvoiceHeader: Return the invoice header or -- nothing if there's an error or when action is to delete SELECT InvoiceNo, InvoiceDate, CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode FROM @Invoice InvoiceHeader WHERE @Error_Code = 0 AND @action <> 3; -- InvoiceDetails Return the invoice details -- InvoiceLineNo is for display in the grid SELECT InvoiceNo, LineItem, InvoiceLineNo, ItemNo, ItemDescription ,Quantity, Price, ExtendedPrice FROM ( SELECT InvoiceNo, LineItem ,InvoiceLineNo = ROW_NUMBER() OVER (ORDER BY LineItem) ,a.ItemNo ,ItemDescription = b.ItemDesc ,Quantity, Price ,ExtendedPrice FROM dbo.Invoice_Details a JOIN dbo.Items b ON a.ItemNo = b.ItemNo WHERE InvoiceNo = ISNULL(@InvoiceNo, @InvoicePrefix + CAST(YEAR(@InvoiceDate) AS CHAR(4)) + CAST(@NextInvoiceNo AS VARCHAR(20))) ) InvoiceDetails WHERE @Error_Code = 0; END; |
Let’s now describe the relevant components of our SP template:
1. The parameters passed to the SP consist of an @action variable (required) and “optional” parameters for each column in the header table. Some will not really be optional, but required based on the action that is being performed (validated in the SP).
2. There’s a section to define some local variables and also a table variable that has the same columns as our header table, but no primary key. The attribute on the primary key column (all columns in fact) must allow NULL values.
3. There’s a section to cleanse the input parameters. Mainly this consists of setting blank values to NULL, in case the forms developers weren’t particularly thorough in passing NULLs when it makes sense to do so.
4. The auditing section, which consists of three parts:
a. A section that makes sure the SP was called correctly. These errors should never appear when testing the form (where @Error_Code IN (1, 2, 3, 4)).
b. A section that performs any audits on the data passed in, which should be done in the form instead. These are audits that do not require a check against a database table. For example, making sure that required data is supplied, data range checks (such as what might be done by a CHECK constraint on a table column), etc. These are where @Error_Code IN (5, 6, 7, 8, 9).
c. A final section that performs any audits against other tables in the database. This normally consists of audits to enforce FOREIGN KEY constraints. Often, other more complex business rules may also be enforced in this section. For example, suppose you had different types of invoices for different customer types. You may have an audit here that determines first the customer’s type and then that the invoice type is valid for that customer. These are where @Error_Code IN (10,11).
5. Then there is the “actions” section, also broken into three parts:
a. For @action=0 (query), we simply retrieve the row from the underlying table into our table variable.
b. For @action=1 (insert), we define all the defaults we’ll return to the form for display (we can call this a stub header).
c. For @action IN (2,3) (save and delete) we have to define the most complex part of the processing:
i. Begin a transaction. The next steps may, depending on the action, modify multiple tables, so you’d want all of those to complete successfully. Or if one of the steps fails, do a ROLLBACK to ensure that none of them completed.
ii. Start a TRY/CATCH block, to deal with any errors during the actual data processing (e.g., a deadlock).
iii. Allocate the next invoice number from the Counters table. In SQL 2012 or later, you may prefer to use a SEQUENCE for this. We use the UPDLOCK hint on the table to make sure no one else can allocate a sequence number until our transaction completes.
iv. Delete the details when the action is ‘delete‘.
v. Do a MERGE that separately handles the update/delete actions (based on @action) and does an insert of the newly created invoice number on insert.
vi. Note how the MERGE dumps the results using an OUTPUT clause into our table variable, including a row of NULL values in the event a delete occurred (we’ll remove that later).
vii. In the CATCH block, we have some generic error handling that is useful when we run the SP in SQL Server Management Studio and need to know more about any errors it generates (displayed in the Messages pane).
viii. Then we COMMIT or ROLLBACK the transaction, depending if we had an error or not.
6. Finally, we return the three tables that we discussed above. Naming each table something relevant is one way of retrieving the tables using .Net.
a. ReturnErrors containing an error code and error message in one row, the latter of which can be displayed directly on our form.
b. InvoiceHeader containing one row to use to refresh the form’s fields for the header. Note that if the ErrorCode column of the ReturnErrors table is not zero (or if this was a delete), no row is returned.
c. InvoiceDetails contains all the details for this invoice. Again, no rows are returned for the case of the ErrorCode being non-zero or for a delete action. Note that two line numbers are returned: LineItem (the table-specific line item for an invoice detail record) and InvoiceLineNo (a sequential row number used for display purposes only in the form’s grid).
Notice also how we perform the audits only until one of them fails (IF @Error_Code = 0 AND …) and do not perform the actions unless all audits pass. We have omitted the invoice total, which would be simple enough to add as a calculated column to the header table as the sum of the details.
We’ll show some results of testing for this SP in the next section.
Some Test Data and Initial Testing Scripts for the Header SP
Thanks to the wonders of deferred name resolution, we could have already created the above SP without the underlying tables being present. You can run the script below to create the tables which we will use to demonstrate the actions of the header SP.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
CREATE TABLE dbo.Counters ( CounterID VARCHAR(10) NOT NULL ,CurrentValue BIGINT NOT NULL ,IDPrefix VARCHAR(5) NOT NULL ,PRIMARY KEY (CounterID) ); -- Seed the Counters table (defines the current invoice number) INSERT INTO dbo.Counters (CounterID, CurrentValue, IDPrefix) SELECT 'Invoices', 1000001, 'IN'; CREATE TABLE dbo.Customers ( CustomerID VARCHAR(20) NOT NULL ,CustomerName VARCHAR(100) NOT NULL ,CustomerAddr1 VARCHAR(100) NOT NULL ,CustomerAddr2 VARCHAR(100) NULL ,CustomerZipcode VARCHAR(10) NOT NULL PRIMARY KEY (CustomerID) ); -- Seed the Customers table INSERT INTO dbo.Customers ( CustomerID, CustomerName, CustomerAddr1, CustomerAddr2, CustomerZipcode ) SELECT '20001', 'ACME MINERALS', '35 WESTCHESTER ST', 'CAIRNS, AU', '4810' UNION ALL SELECT '20002', 'ACE CHEMICALS', '22 BROAD AVE', 'CAIRNS, AU', '4810'; CREATE TABLE dbo.Items ( ItemNo VARCHAR(20) NOT NULL ,ItemDesc VARCHAR(100) NOT NULL ,ItemPrice MONEY NOT NULL PRIMARY KEY (ItemNo) ); -- Seed the Items table INSERT INTO dbo.Items (ItemNo, ItemDesc, ItemPrice) SELECT '1000055', 'ORE SORTER', 233.22 UNION ALL SELECT '1000056', 'CONVEYER BELT', 189.33 UNION ALL SELECT '1000057', 'LATHE', 1032.22 UNION ALL SELECT '1000058', 'MURIATIC ACID', 31.11 UNION ALL SELECT '1000059', 'FULMINATE OF MERCURY', 212.23; CREATE TABLE dbo.Invoices ( InvoiceNo VARCHAR(20) NOT NULL ,InvoiceDate DATE NOT NULL ,CustomerID VARCHAR(20) NOT NULL ,CustomerName VARCHAR(100) NOT NULL ,CustomerAddr1 VARCHAR(100) NOT NULL ,CustomerAddr2 VARCHAR(100) NULL ,CustomerZipcode VARCHAR(10) NOT NULL ,PRIMARY KEY (InvoiceNo) ,CONSTRAINT inv_fk1 FOREIGN KEY (CustomerID) REFERENCES dbo.Customers (CustomerID) ); -- Seed the Invoices table INSERT INTO dbo.Invoices ( InvoiceNo, InvoiceDate, CustomerID, CustomerName ,CustomerAddr1, CustomerAddr2, CustomerZipcode ) SELECT 'IN20141000001', '2014-11-03', '20001', 'ACME MINERALS', '35 WESTCHESTER ST' ,'CAIRNS, AU', '4810'; CREATE TABLE dbo.Invoice_Details ( InvoiceNo VARCHAR(20) NOT NULL ,LineItem BIGINT IDENTITY ,ItemNo VARCHAR(20) NOT NULL ,Quantity INT NOT NULL ,Price MONEY NOT NULL ,ExtendedPrice AS (Quantity * Price) ,PRIMARY KEY (InvoiceNo, LineItem) ,CONSTRAINT invd_fk1 FOREIGN KEY (InvoiceNo) REFERENCES dbo.Invoices (InvoiceNo) ,CONSTRAINT invd_fk2 FOREIGN KEY (ItemNo) REFERENCES dbo.Items (ItemNo) ); -- Seed the Invoice Details table INSERT INTO dbo.Invoice_Details (InvoiceNo, ItemNo, Quantity, Price) SELECT 'IN20141000001', '1000055', 12, 233.22 UNION ALL SELECT 'IN20141000001', '1000056', 3, 189.33; /* GO DROP PROCEDURE dbo.Maintain_Invoice_Header; DROP PROCEDURE dbo.Maintain_Invoice_Details; DROP TABLE dbo.Invoice_Details; DROP TABLE dbo.Invoices; DROP TABLE dbo.Items; DROP TABLE dbo.Customers; DROP TABLE dbo.Counters; */ |
Note that while you may take exception to some of my chosen data types, and the simplifications that I made regarding prices appearing on price lists and selling units of measure, please indulge me as we’re not here today to demonstrate how best to structure such data.
The DROPs are provided as a ‘teardown’ code to help you clean up your sandbox once all is said and done.
Let’s now look at some test scripts and their results.
|
1 2 3 4 |
-- Query an invoice that doesn't exist EXEC dbo.Maintain_Invoice_Header @action = 0 ,@InvoiceNo = 'IN20141000002'; |
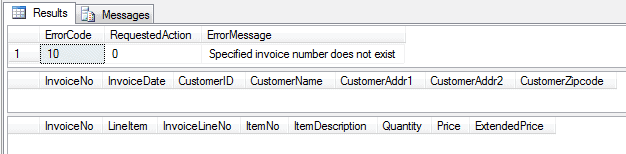
|
1 2 3 4 |
-- Query an existing invoice EXEC dbo.Maintain_Invoice_Header @action = 0 ,@InvoiceNo = 'IN20141000001'; |
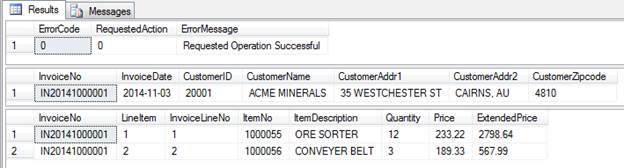
|
1 2 3 4 |
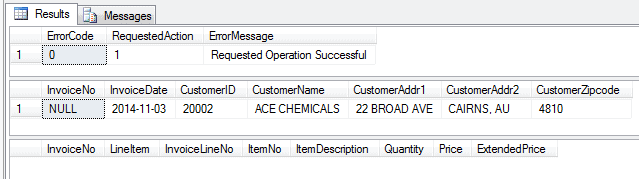
-- Insert mode: specify a Customer ID that doesn't exist EXEC dbo.Maintain_Invoice_Header @action = 1 ,@CustomerID = '20003'; |
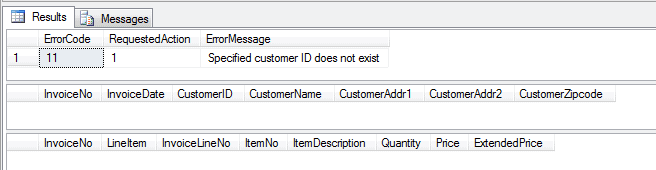
|
1 2 3 4 |
-- Insert mode: specify a Customer ID that does exist EXEC dbo.Maintain_Invoice_Header @action = 1 ,@CustomerID = '20002'; |
|
1 2 3 4 5 6 7 8 9 10 |
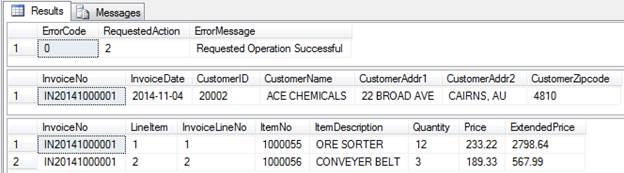
-- Update the invoice date for an existing invoice EXEC dbo.Maintain_Invoice_Header @action = 2 ,@InvoiceNo = 'IN20141000001' ,@InvoiceDate = '2014-11-04' ,@CustomerID = '20002' ,@CustomerName = 'ACE CHEMICALS' ,@CustomerAddr1 = '22 BROAD AVE' ,@CustomerAddr2 = 'CAIRNS, AU' ,@CustomerZipcode = '4810'; |
|
1 2 3 4 5 6 7 8 9 10 |
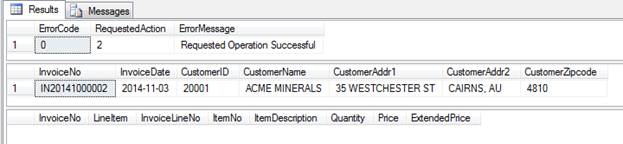
-- Save a new invoice date for the specified customer EXEC dbo.Maintain_Invoice_Header @action = 2 ,@InvoiceNo = NULL ,@InvoiceDate = '2014-11-03' ,@CustomerID = '20001' ,@CustomerName = 'ACME MINERALS' ,@CustomerAddr1 = '35 WESTCHESTER ST' ,@CustomerAddr2 = 'CAIRNS, AU' ,@CustomerZipcode = '4810'; |
|
1 2 3 4 5 6 7 8 9 10 |
-- Delete an existing invoice (and its details) EXEC dbo.Maintain_Invoice_Header @action = 3 ,@InvoiceNo = 'IN20141000001' ,@InvoiceDate = NULL ,@CustomerID = NULL ,@CustomerName = NULL ,@CustomerAddr1 = NULL ,@CustomerAddr2 = NULL ,@CustomerZipcode = NULL; |
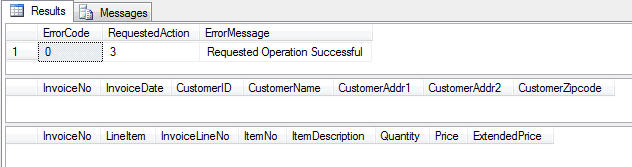
We’ll leave it to our interested readers to verify that all audit rules trigger the correct error messages when an audit fails.
An Invoice Details SP Template and some Test Scripts
As noted earlier, the Invoice details SP is much simpler than for the header. However it is still based on a trimmed-down version of the header SP’s template.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 |
CREATE PROCEDURE dbo.Maintain_Invoice_Details -- ============================================================================= -- Author: Dwain.C -- Create date: 15-Nov-2014 -- Description: This is a template for an SP that maintains the details of an -- invoice document. /* Comment blocks */ are explanations of the -- sections of the template and should be removed in a customized -- version of the template. -- ============================================================================= ( /******************************************************************************* ** Parameters Section ** Which includes: - An @action variable that corresponds to form actions (buttons), along with any other parameters such as the user that is performing the action, which could be used to maintain a record of the person performing the change. - The data values (form fields) which will be updated on that action. Note that this includes @InvoiceNo, which is required on all actions. After the @action variable, default values for all parameters are defaulted to NULL, because the SP will validate (audit) that appropriate values are provided on each specific action. It is a best practice to call this SP using specified parameter names rather than assuming that the positional placement won't change. Note that data parameters (including @InvoiceNo) should be identical to the data types for the underlying table's columns, so that when you publish the SP's call signature the developers know how that data is stored in the front-end code. *******************************************************************************/ @action TINYINT -- =2 Insert/update, =3 Delete ,@InvoiceNo VARCHAR(20) -- If @LineItem IS NULL then insert on @action=2 ,@LineItem BIGINT = NULL ,@ItemNo VARCHAR(20) = NULL ,@Quantity INT = NULL -- If @Price IS NULL then get the price from the Items table ,@Price MONEY = NULL ) AS BEGIN; SET NOCOUNT ON; /******************************************************************************* *** Declarations Section *** This includes some local control variables (@Error_Code and @Error_Message will always be among them). *******************************************************************************/ DECLARE @Error_Code INT = 0 ,@Error_Message VARCHAR(MAX); /******************************************************************************* *** Parameters Cleansing Section *** Convert blank values to NULL, transform any other values to something appropriate for the @action, etc. *******************************************************************************/ -- Cleanse/transform the input parameters SELECT @action = CASE WHEN @action IN (2, 3) THEN @action ELSE -1 END ,@InvoiceNo = NULLIF(@InvoiceNo, '') ,@ItemNo = NULLIF(@ItemNo, ''); /******************************************************************************* *** Parameters Auditing Section *** Parameters auditing generally occur in these three parts in this sequence: 1. Control audits: These audits are performed to make sure that appropriate parameters are passed to the SP on the specific actions. Generally in a production application you would not see these messages returned to the form, because they represent cases where the developer did not call the SP correctly (so should be corrected during forms testing). 2. Simple data audits: Includes things like making sure required values (NOT NULL in the database table) are provided, consistency checks between data elements, i.e., anything that does not require a validation against the database. Another example is auditing a data element against the CHECK constraint for the underlying column. 3. Complex data audits: These are any audits requiring validating that a specified parameter is valid based on existing rows in other table. For example, making sure FOREIGN KEY constraints are met. It may be necessary in some cases to perform audits of typs 3 mixed in with audits of type 2 when it is necessary to do several validations in a specific sequence. That is permissible, but generally when possible the sequence should be adhered to. Always check that @Error_Code still equals zero before you perform the next audit. This is especially important for complex audits to avoid multiple retrievals from the database (keeps the performance up). When commenting any particular audit, specify what the data should be, i.e., the opposite information from what the code audit performs (what the data should not be). This adds clarity. *******************************************************************************/ /******************************************************************************* *** Perform Type 1 (Control) audits *******************************************************************************/ -- After cleansing, @action should be 2,3 IF @Error_Code = 0 AND @action NOT IN (2, 3) SELECT @Error_Code = 1; -- @InvoiceNo required on all actions IF @Error_Code = 0 AND @InvoiceNo IS NULL SELECT @Error_Code = 2; -- @LineItem is required on delete, optional on Insert/Update IF @Error_Code = 0 AND @action = 3 AND @LineItem IS NULL SELECT @Error_Code = 3; /******************************************************************************* *** Perform Type 2 (Simple Data) audits *******************************************************************************/ -- Validate required (NOT NULL) fields on update/save IF @Error_Code = 0 AND @action = 2 AND @ItemNo IS NULL SELECT @Error_Code = 4; ELSE IF @Error_Code = 0 AND @action = 2 AND @Quantity IS NULL SELECT @Error_Code = 5; -- And maybe do some other data range or validity checks ELSE IF @Error_Code = 0 AND @action = 2 AND @Quantity <=0 SELECT @Error_Code = 6; /******************************************************************************* *** Perform Type 3 (Complex Data) audits *******************************************************************************/ -- Check that the invoice exists IF @Error_Code = 0 AND @InvoiceNo IS NOT NULL AND NOT EXISTS ( SELECT 1 FROM dbo.Invoices WHERE InvoiceNo = @InvoiceNo ) SELECT @Error_Code = 7; -- Check that the line number (if specified) exists IF @Error_Code = 0 AND @LineItem IS NOT NULL AND NOT EXISTS ( SELECT 1 FROM dbo.Invoice_Details WHERE InvoiceNo = @InvoiceNo AND LineItem = @LineItem ) SELECT @Error_Code = 8; -- Confirm foreign key constraints before proceeding IF @Error_Code = 0 AND @action = 2 AND @ItemNo IS NOT NULL AND NOT EXISTS ( SELECT 1 FROM dbo.Items WHERE ItemNo = @ItemNo ) SELECT @Error_Code = 9; /******************************************************************************* *** Actions Section *** This section processes each possible action the user can specify by a button push on the form. Only process actions if @Error_Code = 0. *******************************************************************************/ -- If no errors, then process each action IF @Error_Code = 0 BEGIN BEGIN TRANSACTION T1; BEGIN TRY; -- And now perform the insert/update/delete MERGE dbo.Invoice_Details t USING ( SELECT InvoiceNo = @InvoiceNo ,LineItem = @LineItem ,ItemNo = @ItemNo ,Quantity = @Quantity ,Price = ISNULL(@Price, ItemPrice) -- Ensure at least one row returned to support delete FROM (SELECT 1) a (n) LEFT JOIN dbo.Items b ON ItemNo = @ItemNo ) s ON s.InvoiceNo = t.InvoiceNo AND s.LineItem = t.LineItem WHEN MATCHED AND @action = 3 THEN DELETE WHEN MATCHED AND @action = 2 THEN UPDATE SET InvoiceNo = s.InvoiceNo ,ItemNo = s.ItemNo ,Quantity = s.Quantity ,Price = s.Price WHEN NOT MATCHED THEN INSERT ( InvoiceNo, ItemNo, Quantity, Price ) VALUES ( s.InvoiceNo, s.ItemNo, s.Quantity, s.Price ); END TRY BEGIN CATCH; -- Some basic error handling SELECT @Error_Code = ERROR_NUMBER(), @Error_Message = ERROR_MESSAGE(); PRINT 'Merge to Invoice details table'; -- Useful information for debugging PRINT 'ERROR_NUMBER()' + CAST(ERROR_NUMBER() AS VARCHAR(10)); PRINT 'ERROR_SEVERITY()' + CAST(ERROR_SEVERITY() AS VARCHAR(10)); PRINT 'ERROR_STATE()' + CAST(ERROR_STATE() AS VARCHAR(10)); PRINT 'ERROR_PROCEDURE() ' + CAST(ERROR_PROCEDURE() AS VARCHAR(8000)); PRINT 'ERROR_LINE() ' + CAST(ERROR_LINE() AS VARCHAR(100)); PRINT 'ERROR_MESSAGE() ' + CAST(ERROR_MESSAGE() AS VARCHAR(8000)); PRINT 'XACT_STATE() ' + CAST(XACT_STATE() AS VARCHAR(5)); END CATCH; IF @Error_Code <> 0 OR XACT_STATE() = -1 ROLLBACK TRANSACTION T1; ELSE IF @Error_Code = 0 AND XACT_STATE() = 1 COMMIT TRANSACTION T1; END; /******************************************************************************* *** Returned Tables Section *** The table names you can reference in the front-end code. In this case: 1. ReturnErrors - an error message suitable for display on the form *******************************************************************************/ -- SP Returns 1 table to the front end: -- ReturnErrors -- ReturnErrors: whether the action was successful WITH ReturnErrors (ErrorCode, ErrorMessage) AS ( SELECT 0, 'Requested Operation Successful' -- Audit failures UNION ALL SELECT 1, 'Invalid action specified' UNION ALL SELECT 2, 'Invoice number is required for this action' UNION ALL SELECT 3, 'Line item is required for this action' UNION ALL SELECT 4, 'Not saved - Item number is required' UNION ALL SELECT 5, 'Not saved - Quantity is required' UNION ALL SELECT 6, 'Not saved - Quantity must be greater than zero' UNION ALL SELECT 7, 'Specified invoice number does not exist' UNION ALL SELECT 8, 'Specified line item does not exist' UNION ALL SELECT 9, 'Specified item number does not exist' UNION ALL -- For this case @Error_Code contains a SQL error (e.g., deadlock) SELECT @Error_Code, @Error_Message WHERE @Error_Code NOT BETWEEN 0 AND 9 -- End of the BETWEEN range must correspond to the number of audit -- failure error messages above ) SELECT ErrorCode, RequestedAction=@action, ErrorMessage FROM ReturnErrors ReturnErrors WHERE @Error_Code = ErrorCode; END; |
You may notice that, even though there is only one MERGE statement within the TRY/CATCH block (i.e., no other MERGE, INSERT, UPDATE or DELETE statements), we’ve still included the TRANSACTION in our template because there could very well be more statements if required by the business logic.
The main difference between the details and header template, is that the details template only returns the one table (ReturnErrors) for use by the front end application. Also it is not necessary to use a table variable to store the details in. After the details SP is executed, the form simply re-executes the header SP in search mode to recapture any changes to the details (and possibly the header record itself). The forms developer must then refresh this information to the fields in the form.
Now let’s test the available actions for the details (from running the test scripts above we now only have invoice number: IN20141000002 available).
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Insert a row to our existing invoice EXEC dbo.Maintain_Invoice_Details @action = 2 ,@InvoiceNo = 'IN20141000002' ,@LineItem = NULL ,@ItemNo = '1000058' ,@Quantity = 2 ,@Price = 32.22 -- override price SELECT * FROM dbo.Invoice_Details; |
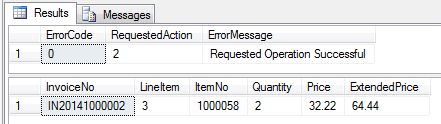
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Insert another row to our existing invoice EXEC dbo.Maintain_Invoice_Details @action = 2 ,@InvoiceNo = 'IN20141000002' ,@LineItem = NULL ,@ItemNo = '1000059' ,@Quantity = 4 ,@Price = NULL -- default price SELECT * FROM dbo.Invoice_Details; |
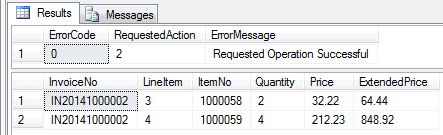
Notice how in each case we’re selecting all of the rows in our invoice details table to see the effect. The forms developer would simply rerun the header SP in query mode for the invoice, then pick up the results returned for the details table and refresh that into the grid.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- Update price and quantity on LineItem=3 EXEC dbo.Maintain_Invoice_Details @action = 2 ,@InvoiceNo = 'IN20141000002' ,@LineItem = 3 ,@ItemNo = '1000058' ,@Quantity = 8 ,@Price = 30.24 -- Then query that invoice EXEC dbo.Maintain_Invoice_Header @action = 0 ,@InvoiceNo = 'IN20141000002'; |
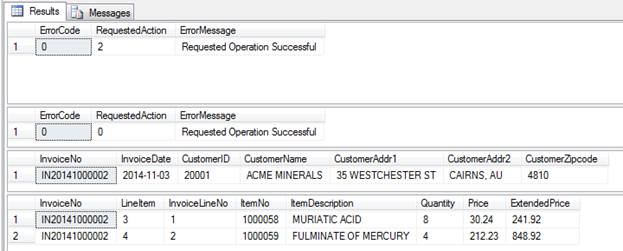
The first results pane shows the results from calling the details SP. The remaining three represent the results from rerunning the query against the header record.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- Delete LineItem=4 EXEC dbo.Maintain_Invoice_Details @action = 3 ,@InvoiceNo = 'IN20141000002' ,@LineItem = 4 ,@ItemNo = NULL ,@Quantity = NULL ,@Price = NULL -- Then query that invoice EXEC dbo.Maintain_Invoice_Header @action = 0 ,@InvoiceNo = 'IN20141000002'; |
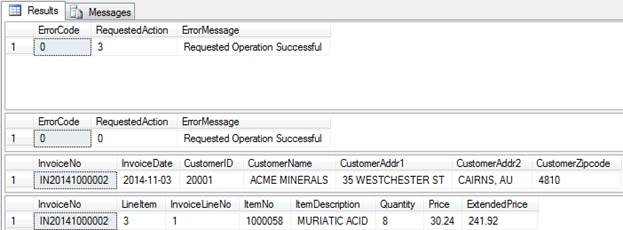
Business Logic Left to the Presentation Layer
The forms developers will still need to implement some specific business logic in the presentation layer where certain actions should be enabled or disabled. For example:
- Enabling/disabling buttons at various points in the process wherever it makes sense to do so: For example, the Save button should probably only be enabled once an invoice has been retrieved (or the Insert stub is displayed).
- Any role-enabled functionality probably requires some work by the forms developer to operate the form correctly. For example, suppose there are two types of users that can access the form: normal and super-users. Perhaps only super-users are allowed to delete an invoice. The SP should perform this audit, but a more user-friendly forms behavior is to simply disable the Delete button if the user is not a super user.
- Normally, once customer ID is selected and the Insert button pressed, you don’t want the user changing the customer ID, so making that field display-only probably makes sense.
- After the user performs the Execute Query action for an invoice and that returns an invoice successufully , you’ll want to make the Invoice number field display-only, because it makes no sense to change the invoice number since they are being auto-generated by the header SP.
It is also possible to use the SP itself to flag when some or all of these specific conditions apply. This can be done by adding additional columns to the ReturnErrors table’s results and then using these as control flags in the front-end code.
If you will follow the strict advice of your DBAs and limit developers’ direct access to tables and views, you’ll need to take one more step. For cases where forms populate a lot of dropdown lists, you can write cover FUNCTIONs that return the needed results. We tend to use schema-bound, in-line Table Valued Functions for best performance.
Some of the Benefits of the Steps Described Above
The table below summarizes some of the additional benefits to using this approach.
|
No. |
Development Phase |
Benefit and Remarks |
|
1 |
Analysis and Design |
A simple event-driven model that is the same can be developed for each form based upon the actions to be delivered by the SPs and the user actions (buttons) expected on each form. |
|
2 |
A skilled SQL Developer should probably be able to translate a requirements specification directly into audits required for a particular form, without the need for an intermediate program specification. |
|
|
3 |
Coding and Unit Testing |
Forms developers are freed from having to understand the complex business logic underlying the application and can focus on forms behavior and usability improvements. |
|
4 |
Only essential logic needs to be coded into the SPs on the first pass. Incremental development of the SPs can add the rest. |
|
|
5 |
Miscellaneous Testing |
As the SQL Developer writes test scripts, they can be saved as part of the SP documentation, thus allowing any testing team capable of white-box testing to generate many variants on the calling parameters to the SP to ensure defect-free behavior of the SPs. |
|
6 |
Once forms-development has progressed to the point that they are calling the SPs correctly, using SQL Profiler to trap the SQL generated by the form can allow the creation of multi-step scripts so that complex transactions can be executed repeatedly. We’ve used this successfully to generate hundreds of test transactions, within a SQL WHILE loop by simply varying some of the input parameters or assigning random values to them. |
|
|
7 |
Documentation |
Documentation of the SPs need only be minimal:
|
|
8 |
Performance |
Because SPs are compiled and executed as a block of SQL code, they tend to be a little better performing than making multiple database connections and executing individual queries. |
|
9 |
Eliminating round trips from application to the database. It is especially crucial to minimize trips from the client, to the application tier and then to the database because of the latency inherent in such a trip. It is also beneficial in reducing the round trips from the application server to the database server, as each time you make a connection and then close it, it generates latency. |
|
|
10 |
Maintainability |
Deployment effort was significantly reduced in cases where a fix involved only a change to one of the SPs. That can be done as an incremental deployment with no need to ask all users to log out while the web application itself is deployed. |
|
11 |
Security |
Through proper controls within the SP, you can avoid issues with SQL Injection. |
Some additional information on point #6. There are automated testing tools that allow complex transactions to be scripted through an application’s forms. However, these tend to be expensive, and do not eliminate the requirement for some scripting. In our case, scripting in SQL is probably a much more widely known skill than writing scripts for an automated testing tool.
Managing the Development Process
One of the primary roles of a project manager is to select the right team to execute the project. This is most certainly true when selecting the person for the role that we’re calling the SQL Developer. That is the person that will construct the SPs that enable this method to work.
Some very specific skills are required. This person must have:
- A deep technical expertise in the dialect of SQL being used, specifically a wide breadth of knowledge of SQL and high-performance code patterns.
- The knowledge to translate a logical data model into the physical implementation, and the skills to create all of the necessary SQL objects (tables, views, etc.).
- The ability to develop and test quickly, and deliver reasonably defect-free SPs to support at least three or four developers who will be working on the forms.
- The ability to make logical decisions on what to include, or what can reasonably be excluded, in the initial SP implementations, because it may be necessary to develop the SPs incrementally so as to stay ahead of the development team.
- The ability to translate (possibly) an incomplete or unclear requirements specification into firm audit rules to be implemented in the SP.
- The thoroughness to document the SPs so that the developers can use them during forms-development.
I have found that this documentation need only be sufficient to serve its purpose: the SP’s call signature, the errors returned and the columns returned in each of the SPs tables, along with some test scripts that can be run to verify that the SP is actually working. This thoroughness must extend to the data types for the parameters being passed to the SP, because these should be identical to the column data types in the underlying tables. Providing information to the developers on which of the audits are “simple data audits,” and thus should be performed within the form’s logic is also useful.
In reality of course, the code should also be well-written and commented, to improve troubleshooting, maintenance and the incremental development effort that will go into making the SPs fully functional. The idea to “Make it Work, Make it Fast and then Make it Pretty” comes into play here, however to avoid Donald Knuth’s statement that “Premature optimization is the root of all evil,” my recommendation is to leverage best-practices and high-performance code patterns to make it “fast enough” at the outset. For more information on what Knuth’s quote does not mean, read this article by SQL MVP Gail Shaw: Premature Optimization.
It is probably not sufficient to “temporarily divert” a .Net developer to be the SQL Developer, because unless they are very senior they’ll probably fall short in one or more of the areas mentioned above.
The project manager must plan to give the SQL Developer a head start on the development team. Probably at least a week should suffice. After that head start, developers can be scheduled to begin working on visual forms design tasks. By the time that is complete, there should be sufficiently functional SPs available to begin making the forms work.
For estimation purposes, you can expect that initial development of an SP like the one above for headers should be ready in about 0.5 – 1.0 man-day including documentation. Details SPs should be ready in just a few hours. Note that this is the basic effort to get them ready for the developer to start. The overall effort is probably double that to make them fully functional and defect-free, and more complex forms and business requirements may take some additional time.
As the SQL Developer completes his work, it is a good idea to turn over his test scripts to a testing team for some “white box” testing across different scenarios.
The SQL Developer should also maintain a “to-do” list of outstanding, uncompleted items, which can be reviewed periodically and prioritized for implementation. The project manager should help to prioritize the list, based on progress by the forms-development team. First priority for the SQL Developer, of course, will always be to fix any issues identified by the forms-development or testing teams, so that his effort is not blocking progress of the forms-development.
While not specifically discussed in this article, SPs (or views) can also be part of the job of the SQL Developer for reports delivery. Once again, because reporting requirements may involve complex SQL (and require high-performance), the SQL Developer may be better suited to the task than reports developers.
You may be thinking that it is impossible for one SQL Developer to stay sufficiently ahead of a three-person forms-development team, but I can assure you that it is not impossible because it was done in our reference project with time to spare.
Reflections and Final Commentary
There were a few variants that came up in our development project, which were relatively easy to handle:
- Some forms had multiple query criteria, each of which would return a unique row of the underlying table; usually the header table. This was handled by using a dynamic search stored procedure as recommended by SQL MVP Gail Shaw in her SQL-in-the-Wild blog: Catch all queries.
- Some of the forms actually had multiple secondary (details) tables, where one grid may be visible at a time and the user was allowed to switch between the grids. That’s another case of some special logic built into the form, but, for that case, the header SP returned more than three tables.
- Using SQL Profiler and white-box testing, it was possible to ensure than every audit that should be done in the form, even if done redundantly in the SP, did not invoke a call to the SP. The overhead of redundancy in the SP tends to be pretty minimal from a performance perspective, so long as it is limited to audits that don’t check against the database.
- When bugs did show themselves in the SPs, because they were well-written, organized and always followed the same template, the bugs were usually identified and fixed within about fifteen minutes.
- As we were testing, none of the forms transactions seemed to respond in an inordinate amount of time (to me that means more than three seconds). So basically the performance of the resulting forms was at least acceptable, even when the update actions might hit five or more different tables. and we confirmed this with the user during User Acceptance Testing,
- In our application, we were careful to include inserted by/date/time and updated by/date/time on every single record in every header and detail table. All this was handled within the MERGE statements, and the only requirement imposed on the forms developers was to pass into the SP the login name of the user of the form.
I seriously recommend you try this approach because of the benefits we found to the development of our reference application. It would not have been possible to deliver that level of business logic complexity within the timeframe that we did without using this approach.
Naturally during the initial week after Go Live, some issues were identified. We were able to rapidly deploy modifications to the business logic by deployment of a single SP. Regardless of whether this was to correct a bug or improve how the application was able to deliver results to the users, the users’ satisfaction with how quickly those changes could be implemented was frequently communicated to us. In this case, the users’ business was very time-critical, so deployments of the entire web application requiring locking the users out for a period of time needed to be avoided as much as possible. The first application deployment after Go Live was not required until after the first week of use.
During that week of Go Live, we also were intensely focused on performance. The users we were observing were accessing the application over their Intranet, and most form actions were responding instantaneously, with just a few of the more complex search operations taking one to two seconds. While you would not expect remote users of the application to get quite those same performance results, most of the business is conducted at the Go Live site, so our expectations are that performance of the application will meet their needs.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments