
With the introduction of handheld devices that support features such as GPS and maps, the need to store spatial data in a relational database is greater than ever. Spatial data identifies the locations and boundaries on Earth. Database systems such as IBM, DB2, and Oracle have been supporting spatial data for some time. Microsoft added support in SQL Server 2008, with the introduction of native spatial data types to represent spatial objects. At the same time, Microsoft added the functionality necessary to access and index spatial data, enable cost-based optimizations, and support operations such as the intersection of two spatial objects.
SQL Server’s spatial data type allows us to store spatial objects and make them available to an application. SQL Server supports two spatial data types:
- Geometry: Stores the X and Y coordinates that represents lines, points, or polygons.
- Geography: Stores the latitude and longitude coordinates that represent lines, points, or polygons.
If you like to get more details regarding the spatial data types, please read my last article, “Introduction to SQL Server Spatial Data”, which gives you the basics about the two data types.
With the implementation of the spatial data types, SQL Server 2008 offered a slightly different indexing infrastructure. It also introduced an extension to the query processor that allows the optimizer to make better cost-based decisions when choosing an index. In this article we will look at the spatial index and how it helps with query optimization.
Spatial Indexes
Database systems such as IBM, DB2 and Oracle follow their own methodologies for spatial indexing. The methodologies can include R-tree and its variants, Quadtree, or uniform grid. SQL Server also follows its own methodology, and that’s what we’ll focus on in this article.
SQL 2008 Spatial Indexing
As you’re probably aware, the standard index in SQL Server uses a B+ tree structure, which is a variation of the B-tree index. B-tree is nothing but a data structure that keeps data sorted to support search operations, sequential access, and data modifications such as inserts and deletes.
A B-tree index contains at least two levels: the root and the leaf. The root is the top most node and can have child nodes. If there are no child nodes, then the tree is called a Null tree. If there are child nodes, they can be either leaf nodes or intermediate nodes. A leaf node is the bottom part of the tree. Intermediate levels can exist between the root and leaf levels. The difference between a B-tree index and a B+ tree index is that all records are stored only at the leaf level for B+ tree, whereas in a B-tree we can store both keys and data in the intermediate nodes.
SQL Server spatial indexes are built on top of the B+ tree structure, which allows the indexes to use that structure and its access methods. The spatial indexes also use the fundamental principles of XML indexing. XML indexing was introduced in SQL Server 2005 and supports two basic types of indexes: primary and secondary. The primary XML index is a B+ tree that essentially contains one row for each node in the XML instance.
So how does SQL Server implement the spatial index? As already mentioned, SQL Server starts with a B+ tree structure, which organizes data into a linear fashion. Because of this, the indexes must have a way to represent the two-dimensional spatial information as linear data. For this, SQL Server uses a process referred to as the hierarchical uniform decomposition of space. When the index is created, the database engine decomposes, or refactors, the space into a collection of axes aligned along a four-level grid hierarchy. Figure 1 provides an overview of what this process looks like.
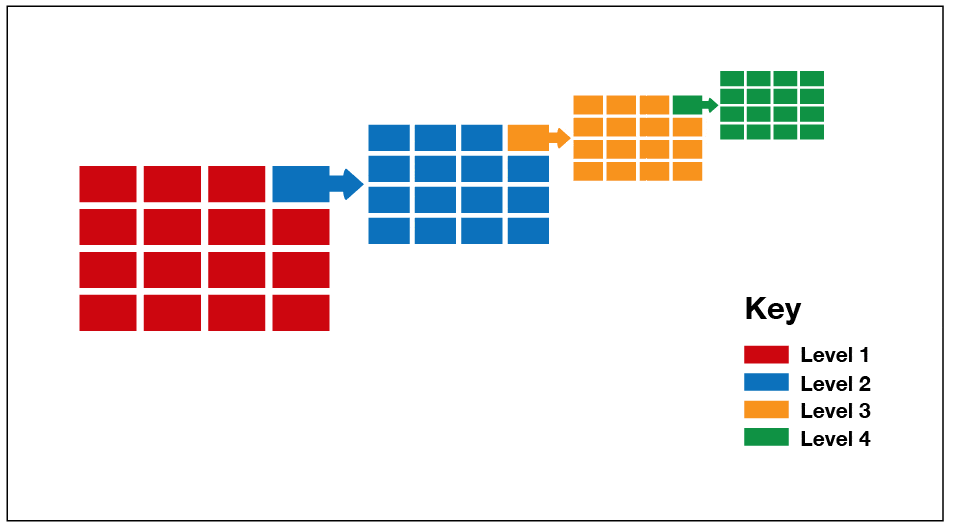
Figure 1: The hierarchical uniform decomposition of space.
The four levels of the grid hierarchy are referred to as level 1, level 2, level 3, and level 4, as shown in Figure 1. Level 1 is the top level. Each level below takes one section of the previous level and divides into another grid. The number of cells in each level is the same for each axis. For example, if the Y-axis contains four cells, the X-axis will contain four cells, giving us a 4×4 grid. The advantage of using a four-level grid hierarchy (multilevel hierarchy) is that it is more flexible than a simple grid because the index is based on a layered grid, rather than a single layer of cells. The multilevel division and grid settings index the entire geoid, thus providing the flexibility necessary for geometric objects.
SQL Server uses a variation of the Hilbert space-filling curve algorithm to number the grids in a linear fashion. The linear approach is important because the indexes implement a B+ tree structure. The indexes use the linear ordering for spatial locality in the index. (For more information about the Hilbert space-filling curve algorithm and its implementation, see the article “Querying Multi-dimensional Data Indexed Using the Hilbert Space-Filling Curve.”)
SQL Server uses the hierarchical uniform decomposition of space method before reading the data is read in the spatial index. The advantage of using this method is that it addresses the limitations of fixed spatial decomposition systems.
Understanding the Spatial Index
An important consideration when working with spatial indexes is grid density-the total number of cells in each grid, as determined by the number of cells along each axis. For example, a 4×4 grid would contain 16 cells, so that would be its density. If a space is decomposed into four levels of 4×4 grids, it produces 65,536 cells on the fourth level. This lets us better control how the decomposition should take place. By specifying different grid densities, we can fine-tune the index based on the objects in the spatial column.
SQL Server supports three levels of grid density: LOW, MEDIUM, and HIGH. The following table shows the grid divisions and the number of cells they support:
|
Index Configuration |
Number of Cells |
Grid Formation |
|
LOW |
16 |
4×4 |
|
MEDIUM |
64 |
8×8 |
|
HIGH |
256 |
16×16 |
Figure2: Grid Density
You can set an index’s grid density or use the default value. The default is based on the compatibility level configured for the SQL Server instance. If the compatibility level is 100 or lower, the default index configuration is MEDIUM. If the compatibility level is 110 or higher, then the default configuration is an auto grid scheme. When it is auto-grid, the tessellation level it uses is eight. This is useful when you have to create a spatial index and you do not know what kind of spatial queries will be performed.
If the compatibility level is set at 100 or below, we can view the grid densities for each level by querying the sys.spatial_index_tessellations catalog view. For example, the following query returns details about the spatial indexes defined on one of my databases:
|
1 2 3 4 5 6 7 |
Select object_id, level_1_grid,level_1_grid_desc, level_2_grid,level_2_grid_desc, level_3_grid,level_3_grid_desc, cells_per_object fromsys.spatial_index_tessellations |
Figure 3 shows the results returned by the query.

Figure3: Retrieving information about the spatial indexes defined in a database
As we can see from the above figure, the results include details about each level’s grid density. In this case, there are two indexes configured with a MEDIUM density and three indexes configured with a HIGH density. We read previously about the three grid divisions LOW, MEDIUM and HIGH. The level_1_grid, level_2_grid, and level_3_grid values show the number of cells. In this particular query I’m returning only three levels because, in this case, the fourth level contains only NULL values.
Creating a Spatial Index
Now that you have some background information on the spatial index, let’s look at one in action. First we need to create a test table that contains a column configured with a spatial data type. The following CREATE TABLE statement defines a table that includes a geometry column and a column configured as the primary key:
|
1 2 3 4 5 |
CREATETABLE dbo.tbSpatialTable ( idint primary key, geometry_colgeometry ); |
Once we’ve created the table, we can create a spatial index on the geometry column. The following CREATE SPATIAL INDEX statement creates an index that contains three levels:
|
1 2 3 4 5 6 7 |
CREATE SPATIALINDEX si_tbSpatialTable__geometry_col ON dbo.tbSpatialTable(geometry_col) WITH ( BOUNDING_BOX= (xmin=-20, ymin=50, xmax=-19, ymax=51), GRIDS= ( LEVEL_3= HIGH, LEVEL_2 = HIGH ) ); |
As we can see, the statement defines only levels 2 and 3, both with HIGH grid densities. Level 1 and level 4 will take the default grid density. The statement also defines the bounding box, which specifies a finite space for the decomposition. We’ll be discussing the bounding box shortly.
SQL Server 2012 has added support for the auto grid spatial index, available for both the geography and geometry data types. An auto grid uses eight levels instead of the usual four levels. The advantage of using an auto grid is that when creating an index we can get good index support without studying the queries that will run against the table. In addition, you do not need to add a GRIDS clause to your CREATE SPATIAL INDEX statement because the database engine determines the best strategy to use to maximize performance.
To create an index that uses an auto grid, you must add a USING clause to the CREATE SPATIAL INDEX statement. If you’re creating the index on a geometry column, define the clause with the GEOMETRY_AUTO_GRID option. If creating the index on a geography column, use the GEOGRAPHY_AUTO_GRID option.
The following example creates a spatial index that uses an auto grid on a geometry column:
|
1 2 3 4 5 6 7 |
CREATE SPATIALINDEX si_tbSpatialTable__geometry_col ON dbo.tbSpatialTable(geometry_col) USING GEOMETRY_AUTO_GRID WITH ( BOUNDING_BOX= (xmin=-20, ymin=50, xmax=-19, ymax=51) ); |
Notice that the statement includes no GRIDS clause, but does include USING clause, which specifies the GEOMETRY_AUTO_GRID option. The next example is similar to the last, except that it includes a CELLS_PER_OBJECT clause:
|
1 2 3 4 5 6 7 8 |
CREATE SPATIALINDEX si_tbSpatialTable__geometry_col ON dbo.tbSpatialTable(geometry_col) USING GEOMETRY_AUTO_GRID WITH ( BOUNDING_BOX= (xmin=-20, ymin=50, xmax=-19, ymax=51), CELLS_PER_OBJECT= 16 ); |
The CELLS_PER_OBJECT clause limits the extent of tessellation of each object. We’ll cover this clause in more detail later in the article.
The Bounding Box
The system table sys.spatial_Index_Tessellation also stores other values regarding the index that has already been created. The following query returns more details about the spatial indexes.
|
1 2 3 4 5 6 |
Select object_id,tessellation_scheme, bounding_box_xmin,bounding_box_ymin, bounding_box_xmax,bounding_box_ymax, cells_per_object fromsys.spatial_index_tessellations |

Figure4 : Bounding box values
In Figure 4, you’ll notice that the results include a number of columns in addition to what we’ve discussed. Let’s take a look at what they mean and how we can manipulate their values.
Geometric data sits on a plane that can be infinite. However, a spatial index requires a finite space for decomposition. As a result, we must define the index boundaries to make it finite. We do this when creating the index by specifying the minimum and maximum values for the X-axis and Y-axis. For that, we use the BOUNDING_BOX clause.
If you refer back to the previous CREATE INDEX statement, you’ll see that the BOUNDING_BOX clause defines the minimum and maximum values of the X and Y coordinates. SQL Server does not provide default values for the BOUNDING_BOX clause, so when you include this clause, you must provide all four values. Also keep in mind that clause applies only to the Geometry data type, not the Geography data type.
So how do you define the BOUNDING_BOX clause if you want to map the whole world? In this case, the X-axis describes the longitude, and the Y-axis describes the latitude. To cover the entire world, use the following values:
xmin=-180ymin=-90xmax=180ymax=90
The following CREATE INDEX statement demonstrates how to use these values:
|
1 2 3 4 5 6 |
CREATE SPATIALINDEX si_tbSpatialTable__geometry_col ON dbo.tbSpatialTable(geometry_col) WITH ( BOUNDING_BOX= (xmin=-180, ymin=-90, xmax=180, ymax=90) ); |
Cells per Object Option
If you refer back to Figure 4, you’ll see that the last column in the results is CELLS_PER_OBJECT. The column refers to an option in the spatial index definition that determines the number of tessellation cells that can be used for each object. The option’s value can be any integer between 1 and 8192. Keep in mind, however, that if the value is too high, the index can grow very large, resulting in performance issues.
To specify the CELLS_PER_OBJECT value, you include the option in your CREATE INDEX statement. If you don’t include it, SQL Server provides the following default values, specific to each grid type:
- GEOMETRY_GRID – 16
- GEOMETRY_AUTO_GRID – 16
- GEOGRAPHY_GRID – 16
- GEOGRAPHY_AUTO_GRID – 12
Keep in mind that tessellation will not occur at lower levels if the Level-1 count reaches or exceeds the limit set by the CELLS_PER_OBJECT option. We’ll cover the tessellation process in more detail shortly, but first, let’s look at how you define the CELLS_PER_OBJECT option with a CREATE INDEX statement:
|
1 2 3 4 5 6 7 8 |
CREATE SPATIALINDEX si_tbSpatialTable__geometry_col ON dbo.tbSpatialTable(geometry_col) WITH ( BOUNDING_BOX= (xmin=-20, ymin=50, xmax=-19, ymax=51), GRIDS= ( LEVEL_3= HIGH, LEVEL_2 = HIGH ), CELLS_PER_OBJECT= 16 ); |
All we’ve done here is set the CELLS_PER_OBJECT option to 16. For more details about this option, refer to the TechNet topic “CREATE SPATIAL INDEX.”
Restriction/Pre-Requisites on Spatial Index
Before we get into the tessellation process, it’s worth nothing that SQL Server places a number of restrictions on spatial indexes:
- A spatial index can be created only on the
geometryorgeographydata type. - The table on which the spatial index is created must be configured with a clustered primary key constraint.
- Once a spatial index is created, the primary key constraint cannot be modified.
- The index key records cannot have a maximum size greater than 895 bytes.
- A spatial index cannot be created on an indexed view.
Tessellation Process
Tessellation refers to the process SQL Server uses to fit a spatial object into the grid hierarchy of a spatial index. In this way, the object is associated with the grid cells that it touches. SQL Server supports geometry and geography tessellation schemes.
When data is inserted into a table with a spatial index, the tessellation process is carried out by a table-valued function from the query processor layer that maps the data to the grid cells. SQL Server calls this function when inserting the data and when querying the data.
The tessellation output is saved in the form of <cell, primary key> pairs, which is persisted in the B+ tree index structure. SQL Sever uses using a top-down, breadth first traverse algorithm to implement the tessellation process, which follows the following three rules:
- Covering rule
- Cells-per-object rule
- Deepest-cell rule
Now let us look at these three rules in detail.
Covering Rule
If an object covers a cell completely, that cell is considered to be covered by the object and is not tessellated any further. At that point, the cell is counted and recorded in the index. Figure 5 shows a covered object as it represented on level 1 and level 2. On level 2, the object covers one cell completely but only part of the cells that surround it.
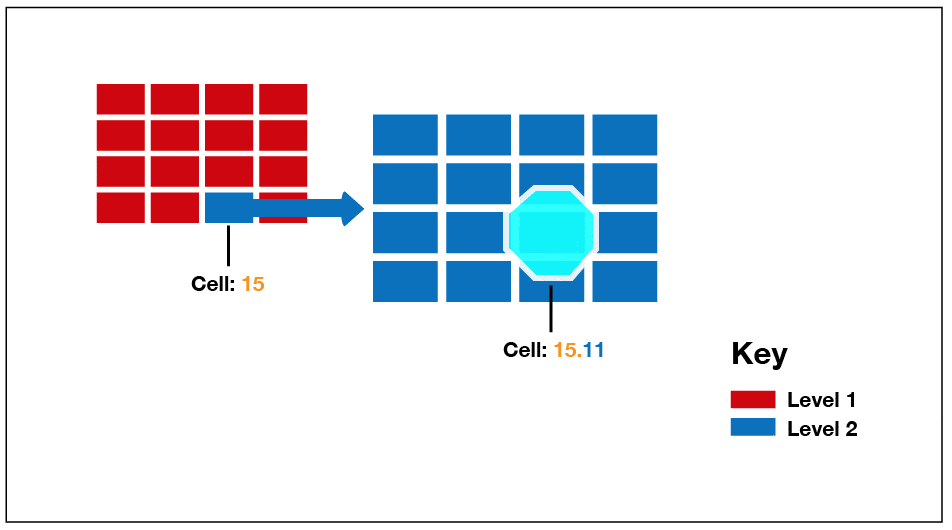
Figure 5: Covering a cell on level 2
The main advantage of using the covering rule is that it simplifies the tessellation process simple and reduces the amount of data that needs to be stored in the index. The rule applies at all levels of the grid.
Cells-Per-Object Rule
The extent to which tessellation occurs depends on the cells-per-object limit cells-per-object value when the index is created. As noted earlier, the default value is 16. This limit defines the maximum number of cells the tessellation process can count per object.
So how does this work? Suppose you have a small triangle-shaped polygon. This triangle fits completely on cell 3 of level 1. Since the cell covers the polygon completely, the object is tessellated at level 2. If the cells-per-object limit is greater than 8, the object can be tessellated into nine level-2 cells. If the cells-per-object limit is less than or equal to eight, then cell 3 of level 1 will not be tessellated, but counted and recorded.
Deepest-Cell Rule
Tessellation creates a cell-hierarchy relationship between the grid levels, based on the fact that every lower-cell belongs to the cell above it. That is, a level-4 cell belongs to a level-3 cell, a level-3 cell belongs to a level-2 cell, and a level-2 cell belongs to a level-1 cell.
This knowledge of cell hierarchy is built into the query processor and is known as the deepest-cell rule. The advantage of using this deepest-cell rule is that there is no need to store all this information in the index. The index needs to store only the deepest level cell.
In Figure 6, you can see a small polygon in a spatial index with a cells-per-object limit of 16. For a small polygon like this, the limit will not be reached. Therefore, tessellation occurs only until level 3. By applying the deepest-cell rule, the tessellation counts only the cells touched, covered, or partially covered cells, so the information stored in the index would be from the level 3 cells.
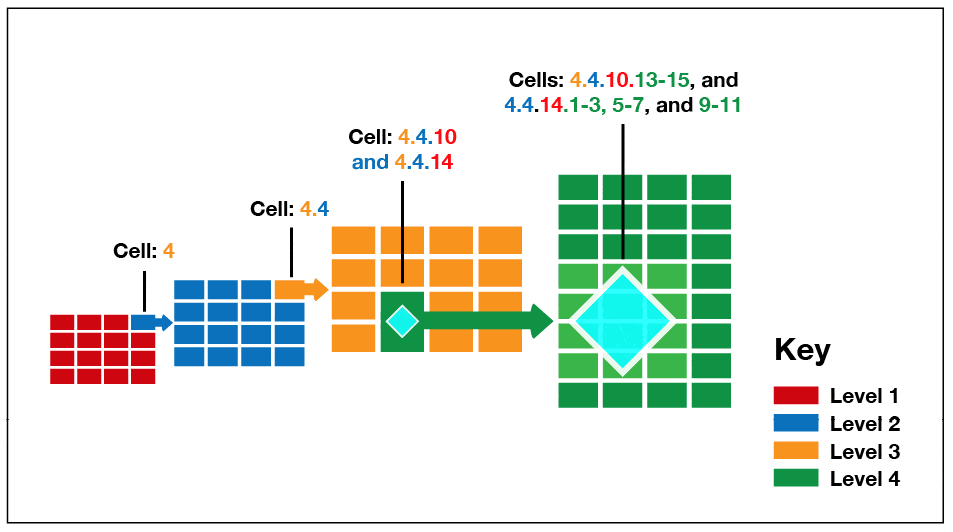
Figure 6: Applying the deepest-cell rule to a spatial object
As already noted, tessellation occurs twice: once when inserting the data and later with querying the data. Figure 7 shows the execution plan generating when inserting data into a table with a spatial index.

Figure 7: Execution plan showing the tessellation process for an insert operation
As you can see, the execution plan references the GeodeticTessellation table-valued function. This is the tessellation process.
Execution Plan
Until now, we’ve discussed only how to create spatial indexes and how they work. Now let’s look at how a spatial index impacts an execution plan.
Let’s start by create a table that contains US zip code geospatial information, as shown in the following T-SQL script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE [dbo].[ZipCodes]( [Country][varchar](2)NULL, [ZipCode][varchar](5)NOT NULL, [City][varchar](200)NULL, [STATE][varchar](50)NULL, [StateAbbreviation][varchar](2)NULL, [County][varchar](50)NULL, [Latitude][decimal](8, 5)NOT NULL, [Longitude][decimal](8, 5)NOT NULL, [GeogCol1][geography] NULL, CONSTRAINT [PK_ZipCode]PRIMARY KEY CLUSTERED ( [ZipCode]ASC, [Longitude]ASC )WITH (PAD_INDEX= OFF,STATISTICS_NORECOMPUTE =OFF, IGNORE_DUP_KEY= OFF,ALLOW_ROW_LOCKS = ON,ALLOW_PAGE_LOCKS = ON)ON [PRIMARY] ) ON[PRIMARY] TEXTIMAGE_ON [PRIMARY] GO |
We’ve defined the ZipCodes column as a clustered primary key. We won’t be creating a spatial index until after we’ve run our first query.
Next, we need to populate our table. On my system, I imported data from the US.txt file. The file contains about 43,000 rows. I used Bulk insert to import the data into the table that I just created.
Please check the PopulateTable.sql as reference on how to populate data.
Once the data is loaded, we can run the following query to return zip codes between 5 to 30 kilometers from the zip code 07011:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Set statistics time on GO SELECT h.* FROM zipcodes g JOIN zipcodes hon g.zipcode<> h.zipcode AND g.zipcode= '07011' AND h.zipcode<> '07011' WHERE g.GeogCol1.STDistance(h.GeogCol1)>=(5* 1000) AND g.GeogCol1.STDistance(h.GeogCol1)<=(30 * 1000) GO Set statistics time off GO |
When we run the query in SQL Server Management Studio (SSMS) with the execution plan included, we can see which index the query engine uses. Because there is only one index on the table, the engine will do a clustered index scan and clustered index seek. Figure 8 shows the execution plan after I ran the statement on my system.
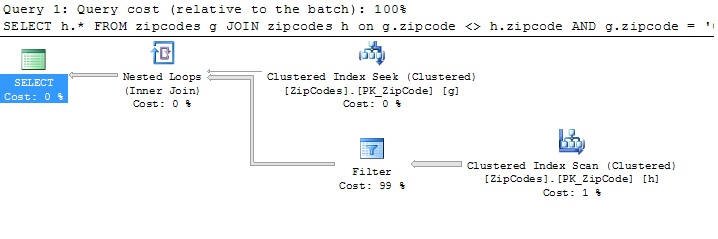
Figure 8: Running the query with only a clustered index defined on the table
The query engine performed one seek operation and one scan operation, and took 4.8 seconds to run the query on my system.
If we look at the stats returned, we can see that the CPU time on my system was 2106ms and the total time taken was 2435ms.
|
1 2 3 4 |
SQL Server Execution Times: CPU time = 2106 ms, elapsed time = 2435 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. |
Now let’s create a spatial index (using default values) on the GeoCol1 column:
|
1 2 |
CREATE SPATIAL INDEX SIndx_SpatialTable_geography_col1 ON zipcodes(GeogCol1); |
Next, we’ll run the same query again. Because we created the spatial index, we might see a different execution plan. Notice that I said might be different. If the optimizer thinks that using the clustered index is more cost efficient, the query engine will not use the spatial index. Figure 9 shows the execution plan after I ran the query.
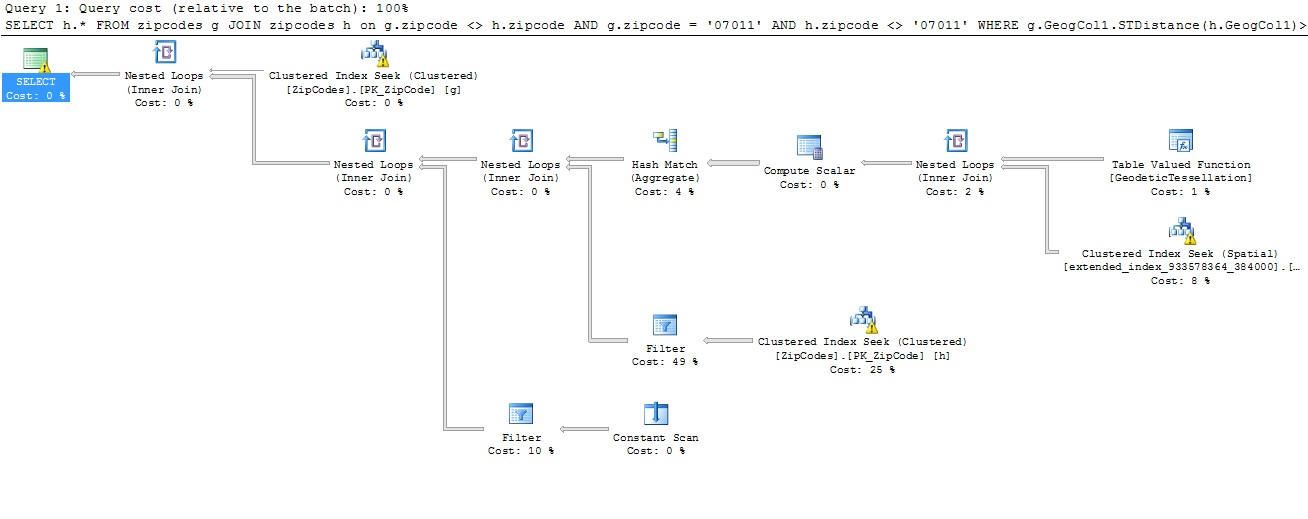
Figure 9: Running the query with a spatial index defined on the table
Notice that a clustered index seek (spatial) in one of the nodes along with the table valued function (Geodetictessellation). This shows that the spatial index was used. As noted earlier, when the query engine uses a spatial index, tessellation occurs.
Now let us take a look at how efficiently the query ran when using the spatial index. Even though the plan is bigger, the execution was much more efficient.
|
1 2 3 4 |
SQL Server Execution Times: CPU time = 156 ms, elapsed time = 343 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. |
The CPU time is just 156 ms, and the elapsed time is just 343 ms. This shows that the index usage increased the performance of the query by quite a large margin.
In some cases, using a spatial index can decrease performance. In other cases, the spatial index is not used even though it exists and could help with the performance. The optimizer chooses which plan to use based on the cost, using information such a cardinality to decide. At times the optimizer can make a bad choice. In such cases, we can always use an optimizer hint within our query:
|
1 2 3 4 5 6 7 8 9 |
SELECT h.* FROM zipcodes as g JOIN zipcodes h with(Index(SIndx_SpatialTable_geography_col1)) on g.zipcode<> h.zipcode AND g.zipcode= '07011' AND h.zipcode<> '07011' WHERE g.GeogCol1.STDistance(h.GeogCol1)>=(5* 1000) AND g.GeogCol1.STDistance(h.GeogCol1)<=(30 * 1000) GO |
We’ve included the optimizer hint as part of our join condition. The hint tells the optimizer to use the spatial index. However, in this case, we won’t see any gains in performance because the query engine is already using the spatial index. But what happens if we force the index usage on the first table? Well, it ran for 30 minutes on my system and still did not complete executing.
Conclusion
With so many location-aware devices in the market, managing spatial data has become very important, especially when it come to making sure our queries run as efficiently as possible.
In this article we explored how SQL Server (version 2008 and up) uses B+ tree indexing to boost the performance of queries that access spatial data. We gained several insights into how spatial indexes work and how to use them efficiently.
Acknowledgements
A big thanks to Johan (@alzdba) for going through my article, and to Rob Sheldon for his editing work.
References
- http://blogs.msdn.com/b/isaac/archive/2008/08/29/is-my-spatial-index-being-used.aspx
- http://blogs.lessthandot.com/index.php/DataMgmt/DataDesign/sql-server-2008-proximity-search-with-th
- http://technet.microsoft.com/en-us/library/bb964712%28v=sql.105%29.aspx
- http://msdn.microsoft.com/en-us/library/bb895332.aspx
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments