
The PATINDEX function is a treasure, and it is the obvious way in SQL Server to locate text in strings. It uses the same wildcard pattern as the LIKE operator, works as fast, but gives back more information. It is closest in functionality to CHARINDEX. People worry that it does not allow a full RegEx, but that is missing the point. It will do useful string searching, as I’ll show you, and it is optimized for performance in a database. A RegEx search performs a different service and is slower at doing those routine jobs that PATINDEX is intended for.
It is great for quick checks on your data. Here, we do an elementary check on a stored IP address.
|
1 2 |
SELECT PATINDEX ('%.%.%.%','23.245.6.49');--returns with the index of the first dot, or 0 if there aren't three in the string SELECT PATINDEX ('%.%.%.%','23.245.6,49');--returns 0 |
So here, the % ‘wildcard’ character has a special meaning, which is ‘any number of any character’. BOL puts this as ‘Any string of zero or more characters.’ For some reason, most developers seem to think that there is a rule that you can only use them at the start and/or end of a pattern. Not true. You can use them anywhere, as many as you like, but not adjacent as all but the first are ignored. The meaning ‘One of any character’ is denoted by the underscore wildcard character, ‘_’. So what does the IP check we have shown you comprise? Nothing more than counting that there are three dots in the string. We can do more but it gets rather more complicated.
Note that, because we are just testing for existence, and aren’t going to extract it, we could also use LIKE
|
1 2 3 4 5 6 7 8 |
SELECT case WHEN '23.245.6.49' LIKE '%.%.%.%' THEN 1 ELSE 0 END; /*What if you want to specify the % character instead of using it in its wildcard meaning? Simple. Do this [%] like here.*/ SELECT PATINDEX ('%[%]%','You have scored 90% in your exam'); /*and the same applies to the other wildcard characters*/ SELECT PATINDEX ( '%[_][%][[]%', 'You have scored 90% in your exam and shouted "D_%[]!"'); /* |
Here is another simple example of its use
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--Strip out everything from a string that is'nt Alphabetic chars DECLARE @String VARCHAR(50),@where INT --put in some sample text SELECT @String=' " well, this is a surprise!" said Gertie. "Is it?" ' SELECT @where= PATINDEX ('%[^A-Z]%',@String COLLATE Latin1_General_CI_AI ) WHILE @where>0 --not executed if no characters to remove BEGIN SELECT @String=STUFF(@string,@where,1,'')--remove trhe character SELECT @where=PATINDEX ('%[^A-Z]%',@String COLLATE Latin1_General_CI_AI ) END SELECT @string --wellthisisasurprisesaidGertieIsit |
Here are a few other more practical examples of using the ‘%’ wildcard.
|
1 2 3 |
/*Select a list of all objects in the current database whose name begins with 'sp' and ends with 'table' (case insensitive)*/ SELECT name FROM sys.objects WHERE PATINDEX('sp%Table',NAME COLLATE Latin1_General_CI_AI)>0; |
|
1 2 3 |
/*Select all objects (not tables!) in the current database which have the following three words FROM WHERE and ORDER in that order with or without gaps in between*/ SELECT name FROM sys.Objects WHERE PATINDEX ('%FROM%WHERE%AND%',object_definition(object_ID))>0; |
|
1 2 3 4 5 6 7 |
/*List all LATIN collations that are case and accent insensitive (ignoring case) */ SELECT name,description FROM fn_helpcollations() WHERE PATINDEX ('latin%case-insensitive%accent-insensitive%', [description] COLLATE Latin1_General_CI_AI)>0; /* you'll notice that we need to use the COLLATE keyword to enforce the type of search. It may not make a difference if your database is already set to a suitable collation, but then database collation can change! This becomes more important if we specify the range of allowable characters. */ |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/* We can specify the range of characters to look for by listing them between angle-brackets. For example, in our IP search, we can do an obvious improvement by making sure there are at least one number before the dots! */ SELECT PATINDEX ('%[0-9].%[0-9].%[0-9].%','278.2.6.49');--returns with the index of the number before the first dot or 0 if there aren't three in the string SELECT PATINDEX ('%[0-9].%[0-9].%[0-9].%','278.A.6.49');--returns 0 /*Nice, but you can do it with the LIKE command. Where PATINDEX scores is where you need to extract the information. We can easily pick up a number embedded in other characters if we were lucky to be given the task of picking up three-digit numbers from a string, (or zero if there aren't any) that is ridiculously easy and can be done inline within a SQL query */ DECLARE @SampleString VARCHAR(255) SELECT @SampleString=' the current valve weight is not 56 mg as before, but 067 milligrams'; SELECT SUBSTRING( @SampleString+'000 ',--put the default on the end PATINDEX('%[^0-9][0-9][0-9][0-9][^0-9]%',@SampleString+'000 ')+1, 3); --three characters -- 067 |
See what we’ve done? We’ve added a default at the end so that we don’t have to cope with passing back a 0 from the PATINDEX when it hits a string without the correctly formatted number in it. We look for the transition between a character that isn’t numeric, to one that is. Then we look for three valid consecutive numbers followed by a character that isn’t a number.
The same technique can be used where you want to trim off whitespace before or after a string. You might think that RTRIM and LTRIM do this but they are slightly broken, in that they only trim off the space character. What about linebreaks or tabs?
|
1 2 3 4 5 6 7 8 9 10 |
Declare @PaddedString VARCHAR(255), @MatchPattern VARCHAR(20) SELECT @PaddedString=' Basically we just want this ', @Matchpattern='%[^' + CHAR(0)+'- ]%'; /* This match pattern looks for the first occurrence in the string of a character that isn't a control character. You'll need to specify a binary sort-order to be certain that this works, so we use the COLLATE clause to specify that we want a binary collation that understands that control characters range from 0 to 32 (space character) We'd normally want to add all the other space characters such as non-break space.*/ --now this will find the index of the start of the string SELECT PATINDEX(@Matchpattern,@PaddedString collate SQL_Latin1_General_CP850_Bin); |
We’ll now show how we can use this to implement a proper Left-Trim function
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
-- does a particular procedure exist IF EXISTS ( SELECT 1 FROM information_schema.Routines WHERE ROUTINE_NAME = 'LeftTrim'--name of procedure AND ROUTINE_TYPE = 'FUNCTION'--for a function --'FUNCTION' AND ROUTINE_SCHEMA = 'DBO' ) SET NOEXEC ON GO -- if the routine exists this stub creation stem is parsed but not executed CREATE FUNCTION LeftTrim (@String VARCHAR(MAX)) RETURNS VARCHAR(MAX) AS BEGIN RETURN 'created, but not implemented yet.'--just anything will do END GO SET NOEXEC OFF -- the following section will be always executed GO ALTER FUNCTION LeftTrim (@String VARCHAR(MAX)) RETURNS VARCHAR(MAX) /** summary: > This function returns a string with all leading white space removed. It is similar to the LTRIM functions in most current computer languages. Author: Phil Factor date: 28 Jun 2014 example: - code: select dbo.LeftTrim(CHAR(13)+CHAR(10)+' 678ABC') - code: Select dbo.LeftTrim(' left-Trim This') returns: > Input string without leading white-space **/ AS BEGIN RETURN STUFF(' '+@string,1,PATINDEX('%[^'+CHAR(0)+'- '+CHAR(160)+']%',' '+@string+'!' collate SQL_Latin1_General_CP850_Bin)-1,'') END GO --now do some quick assertion tests to make sure nothing is broken IF dbo.LeftTrim(' This is left-trimmed') <> 'This is left-trimmed' RAISERROR ('failed first test',16,1) IF dbo.LeftTrim('') <> '' RAISERROR ('failed Second test',16,1) IF dbo.LeftTrim(' ') <> '' RAISERROR ('failed Third test',16,1) IF NOT dbo.LeftTrim(NULL) IS NULL RAISERROR ('failed Fourth test',16,1) IF dbo.LeftTrim(CHAR(0)+' '+CHAR(160)+'Does this work?')<>'Does this work?' RAISERROR ('failed fifth test',16,1) /* And we can also easily then use this to create a function that really trims a string.*/ |
Let’s try something a bit trickier, and closer to a real chore. Let’s find a UK postcode. (apologies to all other nations who are reading this)
The validation rules are that the length must be between 6 and 8 characters of which one is a space. This divides the three-character local code to the right of the space from the sorting-office code to the left of the space. The local characters are always a numeric character followed by two alphabetic characters. The Sorting Office code the left of the gap, can be between 2 and 4 characters and the first character must be alpha.
Before you get too excited, I must point out the the postcode validation is more complex. We can’t use it because PATINDEX uses only wildcards and hasn’t the OR expression or the iterators. We can do quite well though..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT PATINDEX('[A-Z][A-Z0-9]% [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]','CB4 0WZ'); --0 if invalid. >0, 1 if valid /*This needs some explanation. the '[' and ']' brackets enclose a list of characters. you can list them, without commas, or specify a range. Here, in the last two expressions, we have done both. [ABD-HJLNP-UW-Z] is a shorthand for [ABDEFGHJLNPQRSTUWXYZ]. This looks laborious, but works speedily, since SQL Server works hard to optimize LIKE and PATINDEX This does everything but validate that the sorting office code is between two and four characters. If you were determined to do this, you'd need to run three checks*/ -- '[A-Z][A-Z0-9] [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]' -- '[A-Z][A-Z0-9]_ [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]' -- '[A-Z][A-Z0-9]__ [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]' --Which, if we just wanted to check the validity, we can do in a number of ways Select case WHEN 'CB4 0WZ' like '[A-Z][A-Z0-9] [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]' or 'CB4 0WZ' like '[A-Z][A-Z0-9]_ [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]' or 'CB4 0WZ' like '[A-Z][A-Z0-9]__ [0-9][ABD-HJLNP-UW-Z][ABD-HJLNP-UW-Z]' then 1 else 0 end; --With 2008, we can do this SELECT MAX(PATINDEX([matched],'CB4 0WZ')) FROM (VALUES ('[A-Z][A-Z0-9] [0-9][A-Z][A-Z]') ,('[A-Z][A-Z0-9]_ [0-9][A-Z][A-Z]') ,('[A-Z][A-Z0-9]__ [0-9][A-Z][A-Z]')) AS f([Matched]); --0 if invalid. >0, 1 if valid |
What if you wanted to do the more common chore of extracting the postcode from an address-line and putting it in its own field? This is where you have to stop using LIKE as it won’t cut the mustard. If you are of a nervous disposition in your SQL-writing please turn away now.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Select stuff([address],start+1,length-start-fromend,''), Substring([address],start,length-start-fromend) from (--we have a derived table with the results we need for the chopping SELECT MAX(PATINDEX([matched],[address])) as start, MAX(PATINDEX([ReverseMatch],reverse([address]+' ')))-1 as fromEnd, len([address]+'|') as [length], [Address] FROM (VALUES--first the forward match, then the reverse match ('% [A-Z][A-Z0-9] [0-9][A-Z][A-Z]%', '%[A-Z][A-Z][0-9] [A-Z0-9][A-Z] %' ) ,('% [A-Z][A-Z0-9][A-Z0-9] [0-9][A-Z][A-Z]%', '%[A-Z][A-Z][0-9] [A-Z0-9][A-Z0-9][A-Z] %') ,('% [A-Z][A-Z0-9][A-Z0-9][A-Z0-9] [0-9][A-Z][A-Z]%', '%[A-Z][A-Z][0-9] [A-Z0-9][A-Z0-9][A-Z0-9][A-Z] %')) AS f([Matched],ReverseMatch) cross join --normally this would be a big table, of course (select 'Simple Talk Publications, Newnham House, Cambridge Business Park, Cambridge, CB10 7EC' union all Select '20 Milton Street, Inverness SWB7 7EC' ) as g([Address]) group by [address] having MAX(PATINDEX([matched],[address]))>0) work; --and this technique allows you to process a huge table. It is surprisingly fast. --first we create our sample table... Create table [Addresses] (Address_ID int identity primary key, [Address] varchar(200) not null, [alteredAddress] Varchar(200) null, Postcode varchar(12)); |
…and then we’ll populate it with 100,000 rows via SQL Data Generator (we’ll use a RegEx to fill the address column in).
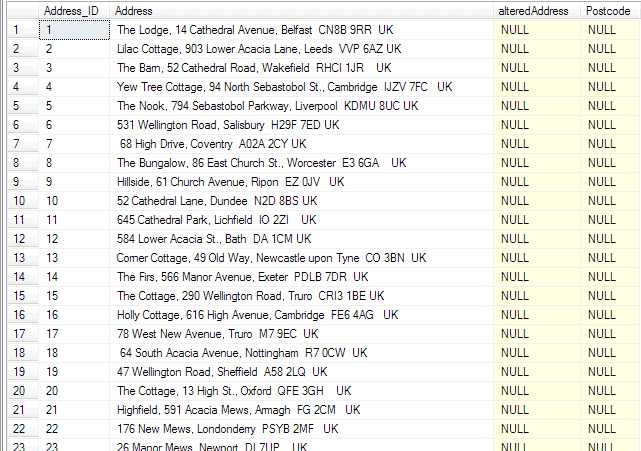
Hopefully, I’ll remember to put it in the downloads at the bottom of the article for the other SQLDG freaks. Then we are going to pull out the postcode information, place the modified address without the postcode in a second column, and put the extracted postcode into its own column so we can subsequently do lightning searches based on postcode. This whole messy process runs in five seconds on my test machine. If you did a neat cursor-based process, it would take minutes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Update Addresses Set alteredAddress=[modified], Postcode=[extracted] from Addresses inner join (Select Address_ID,--the address ID --the modified address without the postcode (if there was one!) stuff([address],start,length-start-fromend+2,'') as [modified], --the postcode itself Substring([address],start,length-start-fromend+2) as [extracted] from (--we have a derived table with the results we need for the chopping --process to save having to calculate it more than once SELECT MAX(PATINDEX([matched],[address])) as start, MAX(PATINDEX([ReverseMatch],reverse([address]+' '))-1) as fromEnd, len([address]+'|')-1 as [length], [Address] as [address], min(Address_ID) as address_ID FROM (VALUES--first the forward match, then the reverse match ('% [A-Z][A-Z0-9] [0-9][A-Z][A-Z]%', '%[A-Z][A-Z][0-9] [A-Z0-9][A-Z] %' ) ,('% [A-Z][A-Z0-9][A-Z0-9] [0-9][A-Z][A-Z]%', '%[A-Z][A-Z][0-9] [A-Z0-9][A-Z0-9][A-Z] %') ,('% [A-Z][A-Z0-9][A-Z0-9][A-Z0-9] [0-9][A-Z][A-Z]%', '%[A-Z][A-Z][0-9] [A-Z0-9][A-Z0-9][A-Z0-9][A-Z] %')) AS f([Matched],ReverseMatch) cross join addresses group by [address] having MAX(PATINDEX([matched],[address]))>0) work) alteredData on AlteredData.Address_ID=Addresses.Address_ID; |
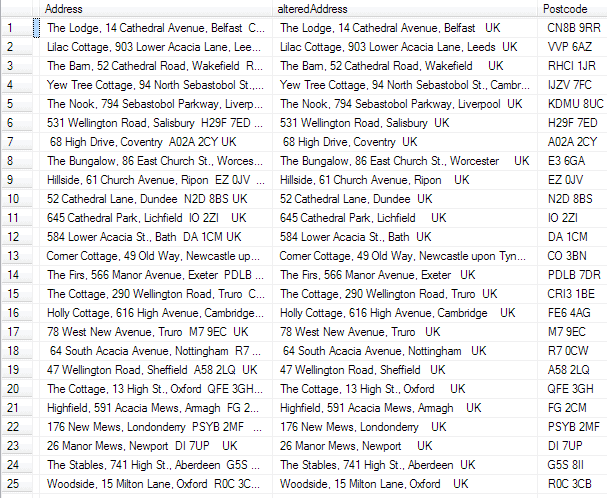
So here’s a puzzle to end off with. You have a field with an email address somewhere in it, and you need to extract it. Here’s one way of pulling it out. It looks a bit complicated, but it is fast.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT CASE WHEN AtIndex=0 THEN '' --no email found ELSE RIGHT(head, PATINDEX('% %', REVERSE(head) + ' ') - 1) + LEFT(tail + ' ', PATINDEX('% %', tail + ' ')) END EmailAddress FROM (SELECT RIGHT(EmbeddedEmail, [len] - AtIndex) AS tail, LEFT(EmbeddedEmail, AtIndex) AS head, AtIndex FROM (SELECT PATINDEX('%[A-Z0-9-]@[A-Z0-9-]%', EmbeddedEmail+' ') AS AtIndex, LEN(EmbeddedEmail+'|')-1 AS [len], embeddedEmail FROM ( SELECT 'The Imperial Oil Company Phil.Factor@ImpOil.com 123 Main St' ) AS ListOfCompanies (EmbeddedEmail) )f )g; /* EmailAddress ------------------------- Phil.Factor@ImpOil.com */ |
What are we doing here? The principle is simple. We look for the embedded ‘@’ sign, and then run a check forwards to get the end of the string containing the ‘@’ character. Then we reverse the start of the string and look for the beginning. When we have these, it is just a simple matter of assembling the email address. The SQL looks laborious, but looks can deceive, so it always pays to test it out. Let’s test it out by recreating our addresses table, and stocking the address column with an additional email record.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Create table [EmailAddresses] (Address_ID int identity primary key, [Address] varchar(200) not null, email Varchar(50)) /* now we stock it with 100,000 records with an address column with an embedded email address. Next we extract the email address. How long does it take? 6 seconds for 100,000 rows. */ Update EmailAddresses Set email=emailAddress from EmailAddresses inner join (SELECT CASE WHEN AtIndex=0 THEN '' --no email found ELSE RIGHT(head, PATINDEX('% %', REVERSE(head) + ' ') - 1) + LEFT(tail + ' ', PATINDEX('% %', tail + ' ')) END AS emailAddress, Address_ID FROM (SELECT RIGHT(Address, [len] - AtIndex) AS tail, LEFT(Address, AtIndex) AS head, AtIndex,Address_ID FROM (SELECT PATINDEX('%[A-Z0-9-]@[A-Z0-9-]%', Address+' ') AS AtIndex, LEN(Address+'|')-1 AS [len], Address, address_ID FROM EmailAddresses )f )g )emails ON emails.address_ID=EmailAddresses.Address_ID; |
So there we have it. In summary, when using PATINDEX:
- Specify the collation if you use character ranges
- If a problem seems tricky, see if you can detect transitions between character types
- Use the angle brackets to ‘escape’ wildcard characters.
- Think of the % wildcard as meaning ‘any number of any character’, or ‘Any string of zero or more characters.’
- Remember that you can specify the wildcard parameter as a column as well as a literal or variable.
- You can use cross joins to do multiple searches to simulate the
ORcondition of RegExes. - Experiment wildly when you get a spare minute. Occasionally, you’ll be surprised.



Load comments