
Calculating Values within a Rolling Window in SQL
Any time that you need to combine values across several rows in SQL, the problem can be challenging, particularly when it comes to performance. We will focus upon the rolling twelve-month totals problem, but our methods can be applied to any time window (e.g., 3 months) or to averages and other aggregations across those time windows as well.
A rolling total for a month is the total for that month plus the previous months within the time window, or NULL if you don’t have the values for all the previous months within the time window .
In previous versions of SQL Server, you had to jump through a few hoops to come up with a method that performs well, but SQL 2012 offers some new features that make it simpler. In either case, there are several valid solutions. Which is fastest and most efficient? We’ll try to answer this question in this article.
We will be working in SQL 2012. If you would like to follow along, you can use the Sample Queries.sql resource you’ll find attached.
Data Setup and Statement of the Business Problem
Often times you’ll find yourself with many transactions within a month, but in our case we’ll assume you’ve already grouped your transactions for each month. We’ll assign our PRIMARY KEY to a DATE data type, and include some values over which we want to accumulate rolling twelve month totals.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE #RollingTotalsExample ( [Date] DATE PRIMARY KEY ,[Value] INT ); INSERT INTO #RollingTotalsExample SELECT '2011-01-01',626 UNION ALL SELECT '2011-02-01',231 UNION ALL SELECT '2011-03-01',572 UNION ALL SELECT '2011-04-01',775 UNION ALL SELECT '2011-05-01',660 UNION ALL SELECT '2011-06-01',662 UNION ALL SELECT '2011-07-01',541 UNION ALL SELECT '2011-08-01',849 UNION ALL SELECT '2011-09-01',632 UNION ALL SELECT '2011-10-01',906 UNION ALL SELECT '2011-11-01',961 UNION ALL SELECT '2011-12-01',361 UNION ALL SELECT '2012-01-01',461 UNION ALL SELECT '2012-02-01',928 UNION ALL SELECT '2012-03-01',855 UNION ALL SELECT '2012-04-01',605 UNION ALL SELECT '2012-05-01',83 UNION ALL SELECT '2012-06-01',44 UNION ALL SELECT '2012-07-01',382 UNION ALL SELECT '2012-08-01',862 UNION ALL SELECT '2012-09-01',549 UNION ALL SELECT '2012-10-01',632 UNION ALL SELECT '2012-11-01',2 UNION ALL SELECT '2012-12-01',26; SELECT * FROM #RollingTotalsExample; |
Since a valid, rolling twelve month total can’t occur until you have at least twelve months of data in your set, we seek to generate a NULL value for our rolling total column for the first 11 rows in the returned results. It is only in the 12th month of 2011 that we will have twelve months of data in which to calculate the rolling total. With our sample data, we can calculate that total as 7776 (or we can run the query below if manual calculations aren’t your thing).
|
1 2 3 |
SELECT SUM(Value) FROM #RollingTotalsExample WHERE [Date] <= '2011-12-01'; |
Calculating a rolling twelve month total is akin to calculating a running total from all prior rows, with just a few calculation tricks we’ll show a little later on.
Solutions That Work in SQL Server 2005 Onwards
Solution #1: Using A Tally Table
Hopefully you’ll know what a Tally table is, but to make a long story short it is simply a table that has one integer column that is a sequential number from 1 to n, n being the number of rows you need. Since we know that each monthly row in our test table must be summed into exactly 12 other rows (ignoring end points), perhaps we can use a simple zero-based Tally table to do this. Let’s give it a try.
|
1 2 3 4 5 6 7 8 9 10 |
WITH Tally (n) AS ( SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 ) SELECT [Date], Value, n, GroupingDate=DATEADD(month, n, [Date]) FROM #RollingTotalsExample a CROSS APPLY Tally b WHERE [Date] = '2011-01-01'; |
This query returns 12 rows where the GroupingDate column represents the period we want to sum the 2011-01-01 row into. It is then a relatively simple matter to create the sum over the grouping like this.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
WITH Tally (n) AS ( SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 ) SELECT GroupingDate=DATEADD(month, n, [Date]) ,Value=MAX(CASE n WHEN 0 THEN a.Value END) ,Rolling12Months=SUM(Value) FROM #RollingTotalsExample a CROSS APPLY Tally b GROUP BY DATEADD(month, n, [Date]) ORDER BY DATEADD(month, n, [Date]); |
When we examine the results of this query, we find that there are a couple of issues:
- The first 11 rows do not show
NULLas we’d like. - The last 11 rows represent dates that are outside of our data range, namely they are later than 2012-12-01.
The first issue can be taken care of with a ROW_NUMBER(), while the second issue is resolved with a HAVING clause. Since we must reference our GroupingDate column in multiple places, we’ll put that calculation into a CROSS APPLY so we only need to do it once.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
-- Rolling twelve month totals using a Tally table WITH Tally (n) AS ( SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 ) SELECT GroupingDate ,Value=MAX(CASE n WHEN 0 THEN a.Value END) ,Rolling12Months=CASE WHEN ROW_NUMBER() OVER (ORDER BY GroupingDate) < 12 THEN NULL ELSE SUM(Value) END FROM #RollingTotalsExample a CROSS APPLY Tally b CROSS APPLY ( SELECT GroupingDate=DATEADD(month, n, [Date]) ) c GROUP BY GroupingDate HAVING GroupingDate <= MAX([Date]) ORDER BY GroupingDate; |
For reference and comparison against later queries, here are the final (correct) results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
GroupingDate Value Rolling12Months 2011-01-01 626 NULL 2011-02-01 231 NULL 2011-03-01 572 NULL 2011-04-01 775 NULL 2011-05-01 660 NULL 2011-06-01 662 NULL 2011-07-01 541 NULL 2011-08-01 849 NULL 2011-09-01 632 NULL 2011-10-01 906 NULL 2011-11-01 961 NULL 2011-12-01 361 7776 2012-01-01 461 7611 2012-02-01 928 8308 2012-03-01 855 8591 2012-04-01 605 8421 2012-05-01 83 7844 2012-06-01 44 7226 2012-07-01 382 7067 2012-08-01 862 7080 2012-09-01 549 6997 2012-10-01 632 6723 2012-11-01 2 5764 2012-12-01 26 5429 |
Solution #2: A More Traditional Approach
Even though the first solution is able to do a single Index scan of our table, our suspicions are that using a Tally table may not be the optimal way to solve this problem. This is mainly because of the second issue we saw, specifically the extra rows that were generated with dates past the end point of our input data set. Let’s look at a couple of more traditional approaches, the first being an INNER JOIN.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- Rolling twelve month total by using INNER JOIN SELECT a.[Date] ,Value=MAX(CASE WHEN a.[Date] = b.[Date] THEN a.Value END) ,Rolling12Months=CASE WHEN ROW_NUMBER() OVER (ORDER BY a.[Date]) < 12 THEN NULL ELSE SUM(b.Value) END FROM #RollingTotalsExample a JOIN #RollingTotalsExample b ON b.[Date] BETWEEN DATEADD(month, -11, a.[Date]) AND a.[Date] GROUP BY a.[Date] ORDER BY a.[Date]; |
Clearly the above is a much simpler query than our solution using a Tally table, but still suffers from the first issue of having to force NULLs into the first 11 rows by using ROW_NUMBER(). A quick check of the execution plan indicates that it is making full use of the clustered index that is available (one scan and one seek). We can get away with using a BETWEEN on our dates because we’re looking at closed end points (normal best practice is to use >= start point and < end point).
I’ve never liked queries that JOIN a table onto itself; so we are still left wondering how well this will perform because of what I’d classify as a semi-triangular join, which as the linked article points out is simply SQL Row-by-Agonizing-Row (RBAR) in disguise.
If you haven’t already guessed from the other articles I’ve written, I love the CROSS APPLY construct in SQL. So let’s see if we can do something similar to the INNER JOIN approach to get to our twelve month rolling totals.
Solution #3: Using TOP and CROSS APPLY
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- Rolling twelve month total by using CROSS APPLY TOP SELECT a.[Date] ,a.Value ,Rolling12Months=CASE WHEN ROW_NUMBER() OVER (ORDER BY a.[Date]) < 12 THEN NULL ELSE a.Value + b.Value END FROM #RollingTotalsExample a CROSS APPLY ( SELECT Value=SUM(Value) FROM ( SELECT TOP 11 b.[Date], Value FROM #RollingTotalsExample b WHERE b.[Date] < a.[Date] ORDER BY b.[Date] DESC ) b ) b ORDER BY a.[Date]; |
Here we calculate the sum of the prior 11 rows in the CROSS APPLY, then add this to the current row. Examination of the query plan for this solution compared to the INNER JOIN method shows some differences, so it is possible the performance characteristics will also be different. Unfortunately we still had to NULL out the first 11 rows with our ROW_NUMBER() as before, but you should convince yourself that the final results are the same.
Solution #4: Using a Correlated Sub-query
From the prior method, we can extract the summed Value result from within the CROSS APPLY and put it into a correlated sub-query instead.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- Rolling twelve month total by using a correlated sub-query SELECT a.[Date] ,a.Value ,Rolling12Months= CASE WHEN ROW_NUMBER() OVER (ORDER BY a.[Date]) < 12 THEN NULL ELSE a.Value + ( SELECT Value=SUM(Value) FROM ( SELECT TOP 11 b.[Date], Value FROM #RollingTotalsExample b WHERE b.[Date] < a.[Date] ORDER BY b.[Date] DESC ) b ) END FROM #RollingTotalsExample a ORDER BY a.[Date]; |
This also produces a slight different query plan so we’ll be interested to see how its performance results compare to other solutions proposed so far.
So much for traditional solutions, and my apologies if I happened to overlook one of your favorites, but feel free to code it up and add it to the performance test harness we’ll present later to see how it fares.
Solution #5: Using a Quirky Update
If you’ve never heard of the Quirky Update (QU) and how it can be applied to problems such as running totals, I strongly recommend you have a read of this outstanding article by SQL MVP Jeff Moden, entitled Solving the Running Total and Ordinal Rank Problems.
Before we continue, we should note that there are those that insist the QU method represents an undocumented behavior of SQL Server and so is not to be trusted. We can say that the syntax is clearly described by the MS Books On Line entry for the UPDATE statement for SQL versions 2005, 2008 and 2012. In fact it goes back further than that. I have successfully used it in SQL Server 2000 but it was inherited from Sybase and was in the first SQL Server version ever released. To the naysayers I’ll say that the “undocumented” behavior is at least consistent across all versions and there is probably little reason to suspect that it will be deprecated or change in future versions of MS SQL. Consider yourself warned!
If you ever consider using a QU to solve any problem, you need to take careful note of the many rules that apply (also included in the referenced article by Jeff). The main ones, which I’ve handled in this query, can be summarized as:
- The table must have a clustered index that indicates the ordering of the source rows by the period as you wish it to be traversed.
- The table must have a column into which you can place the aggregated running total.
- When you perform the update, you need to lock the table using the
TABLOCKXquery hint to make sure nobody else gets in anyINSERTs,DELETEs orUPDATEs before you’re through. - You must prevent SQL from trying to parallelize the query using the
OPTION (MAXDOP 1)hint.
Since a rolling twelve month average is simply a running total in disguise, we can add a column to our table and apply a QU query to do our calculation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
-- Performing a Quirky Update to get our running twelve month totals ALTER TABLE #RollingTotalsExample ADD Rolling12Months INT NULL; -- Change these assignments on DECLARE to a separate statement for SQL 2005 DECLARE @Lag1 INT = 0 ,@Lag2 INT = 0 ,@Lag3 INT = 0 ,@Lag4 INT = 0 ,@Lag5 INT = 0 ,@Lag6 INT = 0 ,@Lag7 INT = 0 ,@Lag8 INT = 0 ,@Lag9 INT = 0 ,@Lag10 INT = 0 ,@Lag11 INT = 0 ,@Lag12 INT = 0 ,@rt INT = 0 ,@rn INT = NULL; UPDATE #RollingTotalsExample WITH(TABLOCKX) SET @rt = @rt + Value - @Lag12 ,@rn = CASE WHEN @rn IS NULL THEN 1 ELSE @rn + 1 END ,Rolling12Months = CASE WHEN @rn > 11 THEN @rt END ,@Lag12 = @Lag11 ,@Lag11 = @Lag10 ,@Lag10 = @Lag9 ,@Lag9 = @Lag8 ,@Lag8 = @Lag7 ,@Lag7 = @Lag6 ,@Lag6 = @Lag5 ,@Lag5 = @Lag4 ,@Lag4 = @Lag3 ,@Lag3 = @Lag2 ,@Lag2 = @Lag1 ,@Lag1 = Value OPTION (MAXDOP 1); SELECT * FROM #RollingTotalsExample; |
I must confess that this does look a little messy, with all of the variables you need to DECLARE. Basically what we are doing is to keep track of the last twelve (lagging) values, in order to remove the 12th one (where the Rolling12Months column is assigned) from what is otherwise a QU running total as described in Jeff’s article. We have high hopes for its speed given that it is known to be the fastest method for solving the running totals problem.
Once again, you should convince yourself that the results are consistent with prior solutions, and yes this solution still behaves the same in SQL 2012. If you’re with me so far, you may also be asking yourself “what happens if I need to calculate multiple running twelve month totals across different partitions?” This is relatively simple for all the other solutions presented but does propose a bit of a challenge using the QU. The answer to this can be found in the attached resource file: Quirky Update Partitioned.sql.
SQL 2012 Solutions
Until now, everything we have done will work in SQL 2008. The only thing we’ve done that is not supported in SQL 2005 is the initializations of the variables we DECLAREd in the QU approach. Now let’s see what new features SQL 2012 has that can be applied to this problem.
Solution #6: Using a Window Frame
Our first SQL 2012 solution (#6) shows how to use a window frame that starts 11 rows prior to the current row, up through the current row to SUM our desired results.
|
1 2 3 4 5 6 |
-- Rolling twelve months totals using SQL 2012 and a window frame SELECT [Date], Value ,Rolling12Months=CASE WHEN ROW_NUMBER() OVER (ORDER BY [Date]) > 11 THEN SUM(Value) OVER (ORDER BY [Date] ROWS BETWEEN 11 PRECEDING AND CURRENT ROW) END FROM #MyTable; |
We still need to handle the NULLs for the first 11 rows specially, but otherwise this solution is quite neat and concise.
Solution #7: Using the LAG Analytic Function
SQL 2012 also offers a new analytic function: LAG, which can be used to solve this problem. LAG returns information from a prior row, offset by the number passed as its second argument. The main benefit seems to be that there’s no need for special handling on the initial 11 rows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- Rolling twelve months totals using SQL 2012 and multiple LAGs SELECT [Date], Value ,Rolling12Months=Value + LAG(Value, 1) OVER (ORDER BY [Date]) + LAG(Value, 2) OVER (ORDER BY [Date]) + LAG(Value, 3) OVER (ORDER BY [Date]) + LAG(Value, 4) OVER (ORDER BY [Date]) + LAG(Value, 5) OVER (ORDER BY [Date]) + LAG(Value, 6) OVER (ORDER BY [Date]) + LAG(Value, 7) OVER (ORDER BY [Date]) + LAG(Value, 8) OVER (ORDER BY [Date]) + LAG(Value, 9) OVER (ORDER BY [Date]) + LAG(Value, 10) OVER (ORDER BY [Date]) + LAG(Value, 11) OVER (ORDER BY [Date]) FROM #MyTable; |
Once again, the returned results are the same but the query plan is quite different than for the prior SQL 2012 solution; however we’re not particularly optimistic that this approach will yield a reasonably performing alternative because of the number of “look-backs” needed to make it work.
Performance Comparison of the Methods
The real test to see how multiple solutions perform is to check actual execution times in a quiescent server using a test harness with many rows. Our test harness is shown, along with how Solution #1 and #2 have been modified (refer to comments in the code) to:
-
Insert the results into a temp table, to avoid the elapsed time impact of returning the rows to SQL Server Management Studio’s results grid.
-
Remove the
DATEarithmetic, because when generating multi-million row test harnesses it is difficult to generate that many unique months, so the[Date]table column has been revised to be aBIGINTdata type.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
SET NOCOUNT ON; CREATE TABLE #RollingTotalsExample ( -- [Date] DATE PRIMARY KEY -- Change data type of [Date] to BIGINT [Date] BIGINT PRIMARY KEY ,[Value] INT ); WITH Tally (n) AS ( SELECT TOP 1000000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM sys.all_columns a CROSS JOIN sys.all_columns b ) INSERT INTO #RollingTotalsExample SELECT n, 1+ABS(CHECKSUM(NEWID()))%1000 FROM Tally; PRINT 'Number of test rows: ' + CAST(@@ROWCOUNT AS VARCHAR(12)); PRINT 'Solution #1 - Tally Table'; SET STATISTICS TIME ON; -- Rolling twelve month totals using a Tally table WITH Tally (n) AS ( SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 ) SELECT GroupingDate ,Value=MAX(CASE n WHEN 0 THEN a.Value END) ,Rolling12Months=CASE WHEN ROW_NUMBER() OVER (ORDER BY GroupingDate) < 12 THEN NULL ELSE SUM(Value) END INTO #Results_Soln1 FROM #RollingTotalsExample a CROSS APPLY Tally b CROSS APPLY ( -- Remove the DATE arithmetic SELECT GroupingDate=[Date] + n -- DATEADD(month, n, [Date]) ) c GROUP BY GroupingDate HAVING GroupingDate <= MAX([Date]) ORDER BY GroupingDate; SET STATISTICS TIME OFF; PRINT 'Solution #2 - INNER JOIN' + CHAR(10); SET STATISTICS TIME ON; -- Rolling twelve month total by using INNER JOIN SELECT a.[Date] ,Value=MAX(CASE WHEN a.[Date] = b.[Date] THEN a.Value END) ,Rolling12Months=CASE WHEN ROW_NUMBER() OVER (ORDER BY a.[Date]) < 12 THEN NULL ELSE SUM(b.Value) END INTO #Results_Soln2 FROM #RollingTotalsExample a -- Remove the DATE arithmetic --JOIN #RollingTotalsExample b ON b.[Date] BETWEEN DATEADD(month, -11, a.[Date]) AND a.[Date] JOIN #RollingTotalsExample b ON b.[Date] BETWEEN a.[Date]-11 AND a.[Date] GROUP BY a.[Date]; SET STATISTICS TIME OFF; GO DROP TABLE #RollingTotalsExample; DROP TABLE #Results_Soln1; DROP TABLE #Results_Soln2; |
When we run our test harness at 1,000,000 rows, we get the following raw results, which would seem to eliminate Solutions #1 and #7 as contenders for the top prize in elapsed execution time. You may want to also run this once at 4,000,000 rows (excluding solutions #1 and #7) to give SQL a chance to “learn” a “good” execution plan, prior to attempting to recreate the test results we’ll show in a moment.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
Number of test rows: 1000000 Solution #1 - Tally Table SQL Server Execution Times: CPU time = 63039 ms, elapsed time = 188357 ms. Solution #2 - INNER JOIN SQL Server Execution Times: CPU time = 9251 ms, elapsed time = 8003 ms. Solution #3 - CROSS APPLY TOP SQL Server Execution Times: CPU time = 5397 ms, elapsed time = 5421 ms. Solution #4 - Correlated Sub-query SQL Server Execution Times: CPU time = 5382 ms, elapsed time = 5410 ms. Solution #5 - Quirky Update SQL Server Execution Times: CPU time = 2792 ms, elapsed time = 2871 ms. Solution #6 - SQL 2012 Window Frame SQL Server Execution Times: CPU time = 4041 ms, elapsed time = 4073 ms. Solution #7 - SQL 2012 Multiple LAGs SQL Server Execution Times: CPU time = 33275 ms, elapsed time = 33480 ms. |
For the remaining solutions (#2 – #6), we have graphed the CPU and Elapsed time results from 1M though 4M rows.
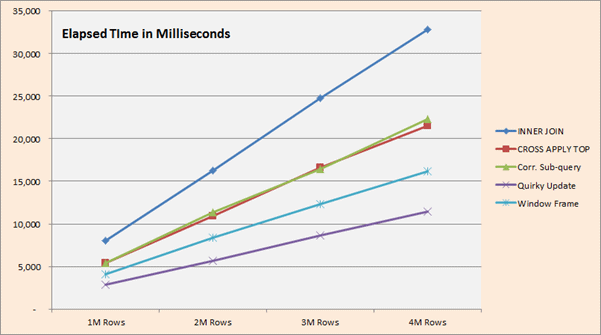
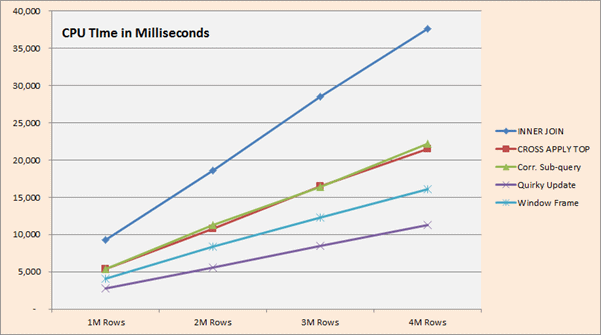
Interpreting the Results
Elapsed and CPU times seem to be consistent across the different methods with respect to their ordering. All appear to scale in a linear fashion.
The Quirky Update, assuming you can understand it and all of its associated rules, seems to be the fastest available solution to solving this problem, even considering the new features available in SQL 2012.
In SQL 2012, the window frame approach is certainly neat, compact and elegant, but slightly trails the Quirky Update solution across the rows we tested. These test results seem to conform to an earlier test on Running Totals in SQL “Denali” CTP3 by Microsoft Certified Master Wayne Sheffield in his blog.
If you’re stuck with an earlier version of SQL (2005 or 2008), and for some reason you can’t abide using a Quirky Update (e.g., if you don’t trust this undocumented behavior), the fastest solutions available to you are either the CROSS APPLY TOP or using a correlated sub-query, as both of those seemed to be in a close tie across the board.
It seems that the “traditional” INNER JOIN is something to be avoided. It will probably only get worse if you need to do date arithmetic within the JOIN’s ON clause. Likewise, using either a Tally Table or multiple LAGs (SQL 2012) certainly was not the way to go.
We did not explore CURSOR-based solutions, but you can back track to the article referenced on running totals to get an idea of how they might perform in this case. I’ve also seen some solutions that employ a recursive Common Table Expression (rCTE), but I most certainly wouldn’t bet on their performance compared to the QU or window frame solutions.
There are many ways to calculate values within a rolling window in SQL and there are some clear performance winners among them. We hope you found this guide to the available methods interesting and informative.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments