
When a set of time intervals can overlap – user login sessions, vehicle dispatch events, hotel room occupancy, assembly-line uptime – finding the gaps of inactivity between them requires packing the overlapping intervals into their continuous-range equivalents first, then computing the gaps between those packed ranges.
This article walks through the problem (overlapping user login intervals) and the solution in two stages: (1) pack the overlapping intervals using a classic interval-packing technique; (2) convert the packed intervals to their complement (the gaps).
The article includes complete T-SQL code for each stage, a performance test harness for SQL Server 2008+, and scalability results across dataset sizes. The same technique applies to fleet management, factory-floor reporting, hotel occupancy analysis, and any problem where ‘when is everything idle’ is the question.
When building a web site that requires login access it is normal practice, and even a statutory requirement in some places, that you keep a record of user logins. This log can be invaluable for high-usage web sites in order to identify periods when the web site is infrequently used, so that a suitable time for maintenance such as operating system patching can be scheduled.
Since you have no control over when authorized users log into your web sites, you’ll always have periods when more than one are logged in at the same time. Login and logout times will be staggered, and so the intervals when users are logged in will be overlapping. Today we’ll ultimately be showing you how to find the gaps of inactivity, but to do so we will also show you a neat way to identify those periods where there is activity.
Although this may seem like a slightly contrived problem, there are plenty of times that you are faced with the sort of reporting where special SQL techniques are required. For example:
- If you have a fleet of vehicles where events represent departure and return, you may wish to ask during what periods are at least one of my vehicles out and when are they all not being used?
- In a manufacturing plant with multiple assembly lines where events are line starts and line stops, you can find out during what periods at least one line is in use or the periods when all lines are idle.
- By adding a bit of PARTITIONing to these queries, you can handle the case of a hotel that has multiple types of rooms. Then you can ask the questions, during what times is at least one room of a type occupied or when are all rooms of a particular type unoccupied.
New features in SQL 2012 have been developed to make short work of some of these gaps problems, so we will need SQL 2012 to run many of the examples, specifically those that relate to data clean-up. These solutions are not limited to login/logout intervals; actually any defined interval between specific events will do.
The accompanying resource file: Sample Queries (2012).sql contains all of the sample queries shown in the following sections. All SQL resource files are appended with either (2008) or (2012) to indicate which version of SQL they can be run in.
Problem Setup and Explanation
First we’ll create a table with some basic set-up data that represents three user logins. The login periods will overlap and contain a gap to illustrate the essentials of what we are trying to do.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
IF OBJECT_ID('tempdb.dbo.#Events', 'U') IS NOT NULL DROP TABLE #Events; CREATE TABLE #Events ( ID BIGINT IDENTITY PRIMARY KEY ,UserID INT ,EventTime DATETIME ,[Event] TINYINT -- 0=Login, 1=Logout ); INSERT INTO #Events SELECT 1, '2013-09-01 15:33', 0 UNION ALL SELECT 2, '2013-09-01 16:15', 0 UNION ALL SELECT 2, '2013-09-01 17:00', 1 UNION ALL SELECT 3, '2013-09-01 17:10', 0 UNION ALL SELECT 1, '2013-09-01 18:20', 1 UNION ALL SELECT 3, '2013-09-01 19:10', 1 UNION ALL SELECT 1, '2013-09-02 11:05', 0 UNION ALL SELECT 1, '2013-09-02 11:45', 1; SELECT * FROM #Events ORDER BY UserID, EventTime; |
The raw sample data displayed by the final SELECT are as follows:
|
1 2 3 4 5 6 7 8 9 |
ID UserID EventTime Event 1 1 2013-09-01 15:33:00.000 0 5 1 2013-09-01 18:20:00.000 1 7 1 2013-09-02 11:05:00.000 0 8 1 2013-09-02 11:45:00.000 1 2 2 2013-09-01 16:15:00.000 0 3 2 2013-09-01 17:00:00.000 1 4 3 2013-09-01 17:10:00.000 0 6 3 2013-09-01 19:10:00.000 1 |
We can see that logins ([Event]=0) and logouts ([Event]=1) are evenly matched, meaning the logout time was recorded for each login. Let’s take a look graphically at these four events.
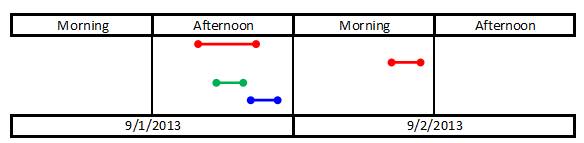
Each login ID is represented by a different color. You can see that there are overlaps between the grouping of logins on the afternoon of 01 Sep and the single login by UserID=1 on 02 Sep. From the data, we ultimately seek to expose the gap between the logout of UserID=3 (blue) and the second login of UserID=1 (2013-09-01 19:10 to 2013-09-02 11:05).
Pairing of Different, Sequential Events
The following solutions assume that concurrent logins by a single account are not allowed. When your login/logout events are equally paired, i.e., there are no missing logout endpoints, a solution such as I’ll be describing will group these events so that your query can place start/end times of the events on a single row.
Sample Query #1: How to Pair up Logins with Logouts
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT UserID, LoginTime=MIN(EventTime), LogoutTime=MAX(EventTime) FROM ( -- Construct a row number (rn) that is 1, 1, 2, 2, 3, 3, ... for each row SELECT UserID, EventTime ,rn=(ROW_NUMBER() OVER (PARTITION BY UserID ORDER BY EventTime)-1)/2 FROM #Events ) a -- When we group by rn we have paired sessions GROUP BY UserID, rn ORDER BY UserID, LoginTime; |
Results from Sample Query #1:
|
1 2 3 4 5 |
UserID LoginTime LogoutTime 1 2013-09-01 15:33:00.000 2013-09-01 18:20:00.000 1 2013-09-02 11:05:00.000 2013-09-02 11:45:00.000 2 2013-09-01 16:15:00.000 2013-09-01 17:00:00.000 3 2013-09-01 17:10:00.000 2013-09-01 19:10:00.000 |
Note how, in the derived table, we’ve created a grouping column as (ROW_NUMBER()+1)/2, which is a well-known trick for pairing consecutive rows. Here are the results in rn for the first four rows:
|
1 2 3 4 5 |
1. (1+1)/2 = 1 2. (2+1)/2 = 1 (integer division truncates the result) 3. (3+1)/2 = 2 4. (4+1)/2 = 2 (integer division truncates the result) 5. ... |
Many times, usually due to incomplete implementation, web sites will not record or generate a logout event. This clutters the data with spurious, unpaired logins. Let’s add a couple of these to our data.
|
1 2 3 4 5 |
INSERT INTO #Events SELECT 1, '2013-09-01 18:00', 0 UNION ALL SELECT 2, '2013-09-01 18:01', 0; SELECT * FROM #Events ORDER BY UserID, EventTime; |
The sample data now appears as follows, where IDs 1 and 10 represent a login that is not paired with a corresponding logout event.
|
1 2 3 4 5 6 7 8 9 10 11 |
ID UserID EventTime Event 1 1 2013-09-01 15:33:00.000 0 9 1 2013-09-01 18:00:00.000 0 5 1 2013-09-01 18:20:00.000 1 7 1 2013-09-02 11:05:00.000 0 8 1 2013-09-02 11:45:00.000 1 2 2 2013-09-01 16:15:00.000 0 3 2 2013-09-01 17:00:00.000 1 10 2 2013-09-01 18:01:00.000 0 4 3 2013-09-01 17:10:00.000 0 6 3 2013-09-01 19:10:00.000 1 |
In order to pair logins with logouts in this case a different approach is required. Note the use of OUTER APPLY (rather than a CROSS APPLY) is required to bring into the results set the final, unpaired login for UserID=2.
Sample Query #2: Pairing Logins with no Corresponding Logout
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT UserID, LoginTime=a.EventTime, LogoutTime=b.EventTime FROM #Events a -- Use an OUTER APPLY to retain outer query rows when inner query returns NULL OUTER APPLY ( -- find the first of any events for this user after the login. If a logout -- then use its EventTime. If a login return NULL -- For logout events (Event=1) pick up the EventTime as the time of logout SELECT TOP 1 EventTime=CASE WHEN [Event] = 1 THEN EventTime END FROM #Events b WHERE a.UserID = b.UserID AND b.EventTime > a.EventTime ORDER BY b.EventTime ) b -- Filter on only login events WHERE [Event] = 0 ORDER BY UserID, LoginTime; |
Since the execution plan of this query shows two Clustered Index Scans, compared to the execution plan of the first showing a single Clustered Index Scan, we’d expect the second query to be a bit slower than the first. So this data clean-up comes at a cost.
Results from Sample Query #2:
|
1 2 3 4 5 6 7 |
UserID LoginTime LogoutTime 1 2013-09-01 15:33:00.000 NULL 1 2013-09-01 18:00:00.000 2013-09-01 18:20:00.000 1 2013-09-02 11:05:00.000 2013-09-02 11:45:00.000 2 2013-09-01 16:15:00.000 2013-09-01 17:00:00.000 2 2013-09-01 18:01:00.000 NULL 3 2013-09-01 17:10:00.000 2013-09-01 19:10:00.000 |
Unfortunately, further testing of this pairing method using a large row set identified that it is quite slow. To find a better alternative, we’ll turn to the new LEAD analytic function in SQL 2012. You’ll find that the following query returns the exact same row set as the prior, but ultimately performs much better (in fact it takes about 10% of the time to run).
Sample Query #3: Using LEAD to Improve Performance (where some logins have no logout)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT UserID, LoginTime, LogoutTime FROM ( SELECT ID, UserID ,LoginTime=CASE WHEN [Event] = 0 THEN EventTime END ,LogoutTime=CASE -- If the next Event by EventTime is a logout WHEN LEAD([Event], 1) OVER (PARTITION BY UserID ORDER BY EventTime) = 1 -- Then we pick up the corresponding EventTime THEN LEAD(EventTime, 1) OVER (PARTITION BY UserID ORDER BY EventTime) -- Otherwise logout time will be set to NULL END ,[Event] FROM #Events ) b -- Filter only on login events WHERE [Event] = 0 ORDER BY UserID, LoginTime; |
It is quite easy to eliminate the rows with missing LogoutTimes in either of the above queries by adding a check for NULL LogoutTime to the WHERE clause.
It would also be possible to implement other business rules for cases where no logout time is recorded for a login event, for example:
- Use the average duration of that user’s logins to predict an approximate LogoutTime.
- Assume the user is still logged in, so substitute GETDATE() for the LogoutTime.
We will leave these as exercises for the interested reader.
Packing the Overlapping Login Intervals
Sometime back, a good friend of mine pointed me to an article that describes a way to pack overlapping intervals. That article is called Packing Intervals and it is by none other than SQL MVP and all-around guru, Mr. Itzik Ben-Gan. When I first read that article, I was impressed by the elegantly simple explanation for how this highly imaginative query works, so I won’t try to inadequately reproduce it here. What I can tell you is that it took me all of about three milliseconds (coincidentally the resolution of the SQL DATETIME data type) to realize that this was something I needed to retain in my tool box. Let’s look at how we would apply this technique to our sample data, by first putting our Example Query #3 (eliminating the spurious logins) into a Common Table Expression and then applying the Packing Intervals technique.
Sample Query #4: Pack the Overlapping Intervals down to non-overlapping Events
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
WITH GroupedLogins AS ( -- Essentially the same as Sample Query #3 except a different filter SELECT UserID, LoginTime, LogoutTime FROM ( SELECT ID, UserID ,LoginTime=CASE WHEN [Event] = 0 THEN EventTime END ,LogoutTime=CASE -- If the next Event by EventTime is a logout WHEN LEAD([Event], 1) OVER (PARTITION BY UserID ORDER BY EventTime) = 1 -- Then we pick up the corresponding EventTime THEN LEAD(EventTime, 1) OVER (PARTITION BY UserID ORDER BY EventTime) -- Otherwise logout time will be set to NULL END ,[Event] FROM #Events ) a -- Filter only on login events that are not "open" (no logout) WHERE [Event] = 0 AND LogoutTime IS NOT NULL ), C1 AS ( -- Since the CTE above produces rows with a start and end date, we'll first unpivot -- those using CROSS APPLY VALUES and assign a type to each. The columns e and s will -- either be NULL (s NULL for an end date, e NULL for a start date) or row numbers -- sequenced by the time. UserID has been eliminated because we're looking for overlapping -- intervals across all users. SELECT ts, [Type] ,e=CASE [Type] WHEN 1 THEN NULL ELSE ROW_NUMBER() OVER (PARTITION BY [Type] ORDER BY LogoutTime) END ,s=CASE [Type] WHEN -1 THEN NULL ELSE ROW_NUMBER() OVER (PARTITION BY [Type] ORDER BY LoginTime) END FROM GroupedLogins CROSS APPLY (VALUES (1, LoginTime), (-1, LogoutTime)) a([Type], ts) ), C2 AS ( -- Add a row number ordered as shown SELECT C1.*, se=ROW_NUMBER() OVER (ORDER BY ts, [Type] DESC) FROM C1 ), C3 AS ( -- Create a grpnm that pairs the rows SELECT ts, grpnm=FLOOR((ROW_NUMBER() OVER (ORDER BY ts)-1) / 2 + 1) FROM C2 -- This filter is the magic that eliminates the overlaps WHERE COALESCE(s-(se-s)-1, (se-e)-e) = 0 ), C4 AS ( -- Grouping by grpnm restores the records to only non-overlapped intervals SELECT StartDate=MIN(ts), EndDate=MAX(ts) FROM C3 GROUP BY grpnm ) SELECT * FROM C4 ORDER BY StartDate; |
It is instructive to see how each successive CTE (ignoring the first because we’ve already seen what it does) returns a row set that brings us closer to our target of non-overlapping intervals. Rather than being repetitive, I’ll refer you to the comments at each step (above).
Results from C1:
|
1 2 3 4 5 6 7 8 9 |
ts Type e s 2013-09-01 17:00:00.000 -1 1 NULL 2013-09-01 19:10:00.000 -1 3 NULL 2013-09-01 18:20:00.000 -1 2 NULL 2013-09-02 11:45:00.000 -1 4 NULL 2013-09-01 16:15:00.000 1 NULL 1 2013-09-01 17:10:00.000 1 NULL 2 2013-09-01 18:00:00.000 1 NULL 3 2013-09-02 11:05:00.000 1 NULL 4 |
Results from C2:
|
1 2 3 4 5 6 7 8 9 |
ts Type e s se 2013-09-01 16:15:00.000 1 NULL 1 1 2013-09-01 17:00:00.000 -1 1 NULL 2 2013-09-01 17:10:00.000 1 NULL 2 3 2013-09-01 18:00:00.000 1 NULL 3 4 2013-09-01 18:20:00.000 -1 2 NULL 5 2013-09-01 19:10:00.000 -1 3 NULL 6 2013-09-02 11:05:00.000 1 NULL 4 7 2013-09-02 11:45:00.000 -1 4 NULL 8 |
Results from C3:
|
1 2 3 4 5 6 7 |
ts grpnm 2013-09-01 16:15:00.000 1 2013-09-01 17:00:00.000 1 2013-09-01 17:10:00.000 2 2013-09-01 19:10:00.000 2 2013-09-02 11:05:00.000 3 2013-09-02 11:45:00.000 3 |
The results produced by this fascinating method are shown below.
Final Results from Sample Query #4:
|
1 2 3 4 |
StartDate EndDate 2013-09-01 16:15:00.000 2013-09-01 17:00:00.000 2013-09-01 17:10:00.000 2013-09-01 19:10:00.000 2013-09-02 11:05:00.000 2013-09-02 11:45:00.000 |
If we return to look at Sample Query Results #2, we find that these represent the packed intervals across all of the UserIDs. You can also think of these as “islands” of time where users are logged into our system.
Before we move on to finding the gaps in these islands, let’s take a closer look at what’s happening in CTEs GroupedLogins and C1. The only reason we have GroupedLogins to begin with is to remove the spurious logins. Looking at the work being done by C1, it is ungrouping that which we just grouped. This leads us to believe that if the spurious logins were not present it might be possible to simplify the query, so let’s try to do this after first deleting the two rows we added to our original sample data.
Sample Query #5: Simplify the Packing Method by using our logins/logouts directly
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
DELETE FROM #Events WHERE ID IN (9,10); WITH C1 AS ( -- It is no longer necessary to CROSS APPLY VALUES to UNPIVOT. The columns e and s will -- either be NULL (s NULL for an end date, e NULL for a start date) or row numbers -- sequenced by the time. UserID has been eliminated because we're looking for overlapping -- intervals across all users. Now we're using the native event type [Event] instead of -- creating one during the UNPIVOT. SELECT EventTime, [Event] ,e=CASE [Event] WHEN 0 THEN NULL ELSE ROW_NUMBER() OVER (PARTITION BY [Event] ORDER BY EventTime) END ,s=CASE [Event] WHEN 1 THEN NULL ELSE ROW_NUMBER() OVER (PARTITION BY [Event] ORDER BY EventTime) END FROM #Events ), C2 AS ( -- Add a row number ordered as shown SELECT C1.*, se=ROW_NUMBER() OVER (ORDER BY EventTime, [Event] DESC) FROM C1 ), C3 AS ( -- Create a grpnm that pairs the rows SELECT EventTime, grpnm=FLOOR((ROW_NUMBER() OVER (ORDER BY EventTime)-1) / 2 + 1) FROM C2 -- This filter is the magic that eliminates the overlaps WHERE COALESCE(s-(se-s)-1, (se-e)-e) = 0 ), C4 AS ( -- Grouping by grpnm restores the records to only non-overlapped intervals SELECT StartDate=MIN(EventTime), EndDate=MAX(EventTime) FROM C3 GROUP BY grpnm ) SELECT * FROM C4 ORDER BY StartDate; Here we have used the native event type, instead of constructing one using CROSS APPLY VALUES as Mr. Ben-Gan did in his original C1 CTE. The results from this query are shown below. |
Results from Sample Query #5:
|
1 2 3 |
StartDate EndDate 2013-09-01 15:33:00.000 2013-09-01 19:10:00.000 2013-09-02 11:05:00.000 2013-09-02 11:45:00.000 |
These correspond to the packed intervals in our original data, including the depiction in our diagram. Note that it is slightly different than the packed results we got from Sample Query #4, because the “spurious logins” that we removed resulted in slightly different overlapping intervals.
Converting Packed Intervals to the Corresponding Gaps
Once we have our packed intervals (“islands”) it is simple enough to add just a little bit of code to convert these into gaps. We draw upon a previous Simple Talk article called The SQL of Gaps and Islands in Sequence Numbers and look for the CROSS APPLY VALUES method to convert islands to gaps. We will add this technique to Sample Query #5 to get to:
Sample Query #6: Convert Packed Intervals into Gaps Between them
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
WITH C1 AS ( -- The columns e and s will either be NULL (s NULL for an end date, e NULL for a start date) -- or row numbers sequenced by the time. UserID has been eliminated because we're looking -- for overlapping intervals across all users. Now we're using the native event type [Event] -- instead of creating one during the UNPIVOT. SELECT EventTime, [Event] ,e=CASE [Event] WHEN 0 THEN NULL ELSE ROW_NUMBER() OVER (PARTITION BY [Event] ORDER BY EventTime) END ,s=CASE [Event] WHEN 1 THEN NULL ELSE ROW_NUMBER() OVER (PARTITION BY [Event] ORDER BY EventTime) END FROM #Events ), C2 AS ( -- Add a row number ordered as shown SELECT C1.*, se=ROW_NUMBER() OVER (ORDER BY EventTime, [Event] DESC) FROM C1 ), C3 AS ( -- Create a grpnm that pairs the rows SELECT EventTime, grpnm=FLOOR((ROW_NUMBER() OVER (ORDER BY EventTime)-1) / 2 + 1) FROM C2 -- This filter is the magic that eliminates the overlaps WHERE COALESCE(s-(se-s)-1, (se-e)-e) = 0 ), C4 AS ( -- Grouping by grpnm restores the records to only non-overlapped intervals SELECT StartDate=MIN(EventTime), EndDate=MAX(EventTime) FROM C3 GROUP BY grpnm ) -- CROSS APPLY VALUES to convert islands to gaps SELECT StartTime=MIN(EventTime), EndTime=MAX(EventTime) FROM ( SELECT EventTime ,rn=ROW_NUMBER() OVER (ORDER BY EventTime)/2 FROM C4 a CROSS APPLY (VALUES (StartDate), (EndDate)) b(EventTime) ) a GROUP BY rn HAVING COUNT(*) = 2 ORDER BY StartTime; Comparing the results of this query with the Results from Sample Query #5, we can see by inspection that the row returned is the gap between the two islands. |
Results from Sample Query #6:
|
1 2 |
StartTime EndTime 2013-09-01 19:10:00.000 2013-09-02 11:05:00.000 |
Obviously, if we needed to handle spurious logins, the little bit of code we added after C4 could be applied just as easily to Sample Query #4.
Building a Test Harness
Now that we have a way to calculate gaps between overlapping intervals, we want to make sure that the code we’ve built will scale to large row sets in a reasonable fashion. To do this, we must build a test harness with a realistic number of rows.
We can simulate the duration of a login by starting the login at a particular time of day and then assume that the user was logged in for a random period of time. In SQL, we can generate uniform random numbers like this:
|
1 |
SELECT 10+ABS(CHECKSUM(NEWID()))%120 |
This will generate a uniformly-distributed random integer between 10 and 130, which could for example represent the minutes the user was logged in. But we’re going to have a little fun and say that our logins are not based on a uniform distribution, rather the time logged in will behave more like a normal distribution where the mean is 240 seconds and the standard deviation is 60 seconds. To do this, we need a way to generate normally distributed random numbers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE FUNCTION dbo.RN_NORMAL ( @Mean FLOAT ,@StDev FLOAT ,@URN1 FLOAT ,@URN2 FLOAT ) RETURNS FLOAT WITH SCHEMABINDING AS BEGIN -- Based on the Box-Muller Transform RETURN (@StDev * SQRT(-2 * LOG(@URN1))*COS(2*ACOS(-1.)*@URN2)) + @Mean END |
The function presented above does this. Generating Non-uniform Random Numbers with SQL has an empirical proof that it does, and you will also find several other random number generators for other distributions contained therein. To use this function, you must pass it two uniform random numbers on the interval 0 to 1.
The test data (1,000,000 rows) can be generated based on 500 days and 1000 UserIds as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
DECLARE @StartDate DATETIME = '2005-01-01' -- 500 days x 1000 users x 2 endpoints = 1,000,000 rows ,@UserIDs INT = 1000 ,@Days INT = 500 ,@MeanLoginSeconds INT = 240 ,@StdDevLoginSeconds INT = 60; WITH Tally (n) AS ( SELECT TOP ( SELECT CASE WHEN @UserIDs > @Days THEN @UserIDs ELSE @Days END ) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM sys.all_columns a CROSS JOIN sys.all_columns b ) INSERT INTO #Events SELECT UserID=f.n, EventTime, [Event] -- Create 2 uniform random numbers FROM (SELECT RAND(CHECKSUM(NEWID()))) a(URN1) CROSS APPLY (SELECT RAND(CHECKSUM(NEWID()))) b(URN2) -- Create 1 Normally-distributed random number from the 2 URNs using the -- using the Box-Muller transform function CROSS APPLY ( SELECT dbo.RN_NORMAL(@MeanLoginSeconds, @StdDevLoginSeconds, URN1, URN2) ) c(NRN) -- Use our Tally table to generate the required number of @Days then convert to a date CROSS APPLY (SELECT n FROM Tally WHERE n BETWEEN 1 AND @Days) d CROSS APPLY (SELECT DATEADD(day, d.n-1, @StartDate)) e([Date]) -- Use our Tally table to generate the required number of @users and logins/logouts CROSS APPLY (SELECT n FROM Tally WHERE n BETWEEN 1 AND @UserIDs) f CROSS APPLY (SELECT DATEADD(second, ABS(CHECKSUM(NEWID()))%84000, e.[Date])) g(LoginStart) CROSS APPLY ( VALUES (0, LoginStart),(1, DATEADD(second, NRN, LoginStart)) ) h([Event], EventTime); |
Each UserID logs in once per day. Rows resulting from the query can be increased in increments of 1,000,000 rows by changing @Days to 1000, 1500 and 2000. Using Sample Query #6 with the above table generates about 30,000 packed intervals and consequently nearly the same number of gaps (actually exactly one less). This can be demonstrated by running the SQL code stored in the resource file: Check Test Harness (2008).sql.
Since each of our queries is built upon a series of steps, we’ll break each step down and get timings on each. Two additional test harness SQL files are provided:
Test Harness 1 (2008).sql– tests 2 queries which are like Sample Query #5 plus the additional code to convert those islands to gaps (Sample Query #6).Test Harness 2 (2012).sql– tests 3 queries which are like Sample Query #3 (removing the logins with missing logouts), Sample Query #4 (to calculate the packed intervals) and finally with the additional code to convert those islands into gaps.
The DELETE statement below appears in Test Harness 2 (2012).sql to remove a few logout events.
|
1 2 3 4 5 6 7 8 |
WITH Logouts AS ( SELECT *, rn=ROW_NUMBER() OVER (ORDER BY EventTime) FROM #Events WHERE [Event] = 1 ) DELETE FROM Logouts WHERE rn % 300 = 2; |
This deletes about 1,667 logout rows out of 1,000,000 (about 0.17%).
Performance Results
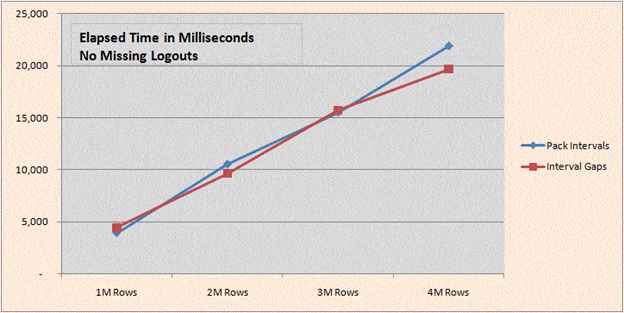
Using Test Harness 1 (2008).sql (run in SQL 2008) we can demonstrate that the additional time for CPU and Elapsed run times when adding the CROSS APPLY VALUES Islands to Gaps method to the interval packing is nearly insignificant. Together the solutions both scale quite linearly and are fairly reasonable when there are no missing logouts.
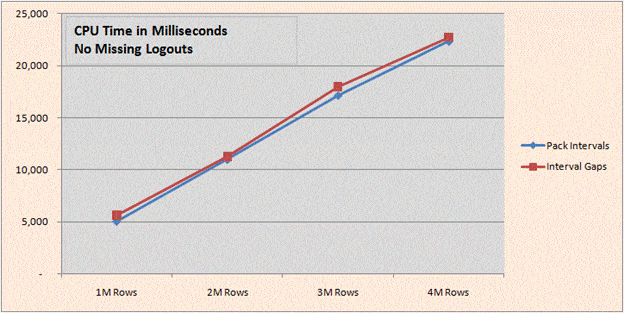
The result below at 4M rows for elapsed time (Interval Gaps less than Pack Intervals) can only be explained by an increasing amount of parallelism introduced by SQL Server into the query.
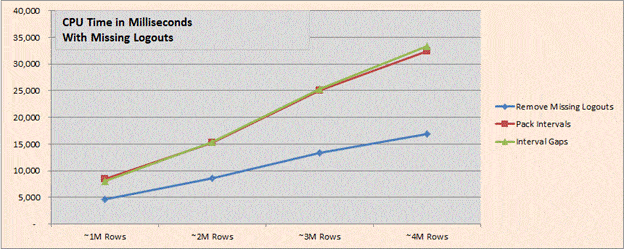
We see a similar story when reviewing the results when there are missing logouts (using Test Harness 2 (2012).sql (run in SQL 2012). Simply needing to remove the missing logouts takes slightly more than 50% of the CPU, but when we layer calculating the gaps on top of the packing algorithm, that additional work is quite minimal.
Elapsed times tell a similar story except that the amount of time for removing the open-ended logins does not comprise nearly as large a percentage of the overall time. Nonetheless, both interval packing and calculating the gaps between them scales quite linearly.
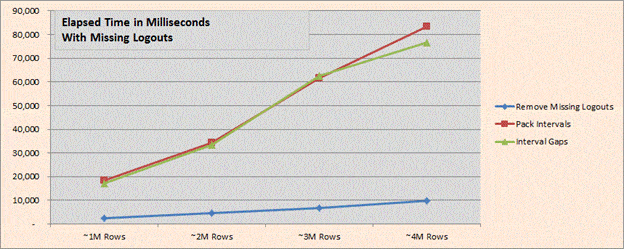
Note that test results for the cases of no vs. missing logouts were run on different machines due to the need for SQL 2012 for the latter, so the CPU/Elapsed times recorded may not be comparable in terms of raw magnitude. Test machines:
- No Missing Logouts: Windows 7 Professional and SQL 2008 R2 (both 64 bit), Dell Inspiron laptop w-Intel Core i5-2430M @ 2.4 GHz, 8GB RAM
- Missing Logouts: Windows 7 Enterprise and SQL 2012 (both 64 bit), Lenovo laptop w-Intel Core i5-3230M @ 2.60 GHz, 12GB RAM
Conclusion
The important concepts we have demonstrated in this article are:
- Combining rows where login and logout events are paired.
- A fast solution using the SQL 2012 analytic function LEAD for combining rows where login and logout events are paired, but some of the logout events are missing.
- The excellent solution proposed by SQL MVP Itzik Ben-Gan for packing intervals, with modifications to support both of the above cases.
- Using the CROSS APPLY VALUES approach to convert islands (packed intervals) to gaps (the periods of no login activity).
- Finally, and very importantly, that these solutions seem linearly scalable to multi-million row sets.
Further Reading
Dealing with event intervals is a fascinating and challenging problem in SQL. If you are interested in pursuing this further, I strongly recommend that you take a look at some of the links below. They provide even more advanced, high-performing techniques for dealing with time intervals.
- Packing Intervals by Itzik Ben-Gan
- Interval Queries in SQL Server by Itzik Ben-Gan
- Intervals and Counts, Part 1 by Itzik Ben-Gan
- Intervals and Counts, Part 2 by Itzik Ben-Gan
- Intervals and Counts, Part 3 by Itzik Ben-Gan
- A Static Relational Interval Tree by Laurent Martin
- Advanced interval queries with the Static Relational Interval Tree by Laurent Martin
- Using the Static Relational Interval Tree with time intervals by Laurent Martin
Thank you for your attention and we hope you found the information in this article interesting and ultimately useful.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments