
Memory-optimized tables (In-Memory OLTP) in SQL Server store data in both active memory and on disk simultaneously. They eliminate traditional lock-and-latch contention by using optimistic concurrency with row versioning, making them significantly faster for high-throughput OLTP workloads.
Available since SQL Server 2014, you can create them with the MEMORY_OPTIMIZED = ON option and choose between SCHEMA_AND_DATA durability (persisted to disk) or SCHEMA_ONLY (data lost on restart, useful for session state or caching). This guide covers how to create, configure, and query memory-optimized tables with practical examples.
Introduction
Sometimes when I try to learn about a concept my brain blocks out everything about it. Talking about anything that uses the In-Memory concept tends to do this to me on occasion. It’s important to note that In-Memory is a marketing term for a series of features in SQL Server that have common behaviors but are not inherently related. In this article, I am going to explain some In-Memory concepts as it relates to SQL Server starting with a dive into Memory Optimized Tables or In-Memory OLTP. I’ve already written about Columnstore which has vastly different use cases compared to In-Memory OLTP, and you can find those here. Columnstore is a perfect example of an In-Memory concept that took me some time to wrap my head around.
What are Memory Optimized Tables?
A Memory Optimized Table, starting in SQL Server 2014, is simply a table that has two copies, one in active memory and one durable on disk whether that includes data or just Schema Only, which I will explain later. Since memory is flushed upon restart of SQL Services, SQL Server keeps a physical copy of the table that is recoverable. Even though there are two copies of the table, the memory copy is completely transparent and hidden to you.
Read also:
Temporary tables in SQL Server
CHAR vs VARCHAR for memory-optimized columns
AI embeddings in SQL Server 2025
What is the Added Benefit for Using These In-Memory Tables?
That’s always something I ask when looking at SQL Server options or features. For in-memory tables, it’s the way SQL Server handles the latches and locks. According to Microsoft, the engine uses an optimistic approach for this, meaning it does not place locks or latches on any version of updated rows of data, which is very different than normal tables. It’s this mechanism that reduces contention and allows the transactions to process exponentially faster. Instead of locks, In-Memory uses Row Versions, keeping the original row until after the transaction is committed. Much like Read Committed Snapshot Isolation (RCSI), this allows other transactions to read the original row, while updating the new row version. The In-Memory structured version is pageless and optimized for speed inside active memory, giving a significant performance impact depending on workloads.
SQL Server also changes its logging for these tables. Instead of fully logging, this duality of both on disk and in memory versions (row versions) of the table allows less to be logged. SQL Server can use the before and after versions to gain information it would normally acquire from a log file. In SQL Server 2019, the same concept applies to the new Accelerated Data Recovery (ADR) approach to logging and recovery.
Finally, another added benefit is the DURABILITY option shown in the example in the section on creating the tables. The use of SCHEMA_ONLY can be a great way to get around the use of #TEMP tables and add a more efficient way to process temporary data especially with larger tables. You can read more on that here.
Things to Consider
Now this all sounds great, so you would think everyone would add this to all their tables, however, like all SQL Server options this is not meant for all environments. There are things you need to consider before implementing In Memory Tables. First and foremost, take into account the amount of memory and the configuration of that memory before considering this. You MUST have that set up correctly in SQL Server as well adjust for the increased use of memory which may mean adding more memory to your server before starting. Secondly, know that, like Columnstore indexes, these tables are not applicable for everything. These table are optimized for high volume WRITEs, not a data warehouse which is mostly for reads for example. Lastly for a full list of unsupported features and syntax to consider be sure to check out the documentation below are just a few.
Features not supported for in memory tables to keep in mind.
- Replication
- Mirroring
- Linked Servers
- Bulk Logging
- DDL Triggers
- Minimal Logging
- Change Data Capture
- Data Compression
T-SQL not supported
- Foreign Keys (Can only reference other Memory Optimized Table PKs)
- ALTER TABLE
- CREATE INDEX
- TRUNCATE TABLE
- DBCC CHECKTABLE
- DBCC CHECKDB
Creating a Memory Optimized Table
The key to having a table “In-Memory” is the use of the key word “MEMORY-OPTIMIZED” on the create statement when you first create the table. Note there is no ability to ALTER a table to make an existing one memory optimized; you will need to recreate the table and load the data in order to take advantage of this option on an existing table. There are just a couple more settings you need to have configured to make this work as you can see from below.
The first step is to make sure you are on compatibility level >=130. Run this query to find out the current compatibility level:
|
1 2 3 |
SELECT d.compatibility_level FROM sys.databases as d WHERE d.name = Db_Name(); |
If the database is at a lower level, you will need to change it.
|
1 2 |
ALTER DATABASE AdventureWorks2016CTP3 SET COMPATIBILITY_LEVEL = 130; |
Next you must alter your database in order to take advantage of In-Memory OLTP by enabling the MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT setting.
|
1 2 |
ALTER DATABASE AdventureWorks2016CTP3 SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; |
Lastly, your database will need to have a memory optimized file group added.
|
1 2 |
ALTER DATABASE AdventureWorks2016CTP3 ADD FILEGROUP AdventureWorks2016CTP3_mod CONTAINS MEMORY_OPTIMIZED_DATA; |
Note that a database may have just one memory optimized file group, and the AdventureWorks2016CTP3 database has one already, so you may see an error when running that statement.
The below command creates the file into the new filegroup.
|
1 2 3 4 |
ALTER DATABASE AdventureWorks2016CTP3 ADD FILE (name='AdventureWorks2016CTP3_mod1', filename='c:\data\AdventureWorks2016CTP3) TO FILEGROUP AdventureWorks2016CTP3_mod |
Now create a table
|
1 2 3 4 5 6 7 8 9 10 11 |
USE AdventureWorks2016CTP3 CREATE TABLE dbo.InMemoryExample ( OrderID INTEGER NOT NULL IDENTITY PRIMARY KEY NONCLUSTERED, ItemNumber INTEGER NOT NULL, OrderDate DATETIME NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); |
Table properties show Memory Optimized = TRUE and Durability = SchemaAndData once the table is created which makes it very simple to verify what the table is doing.
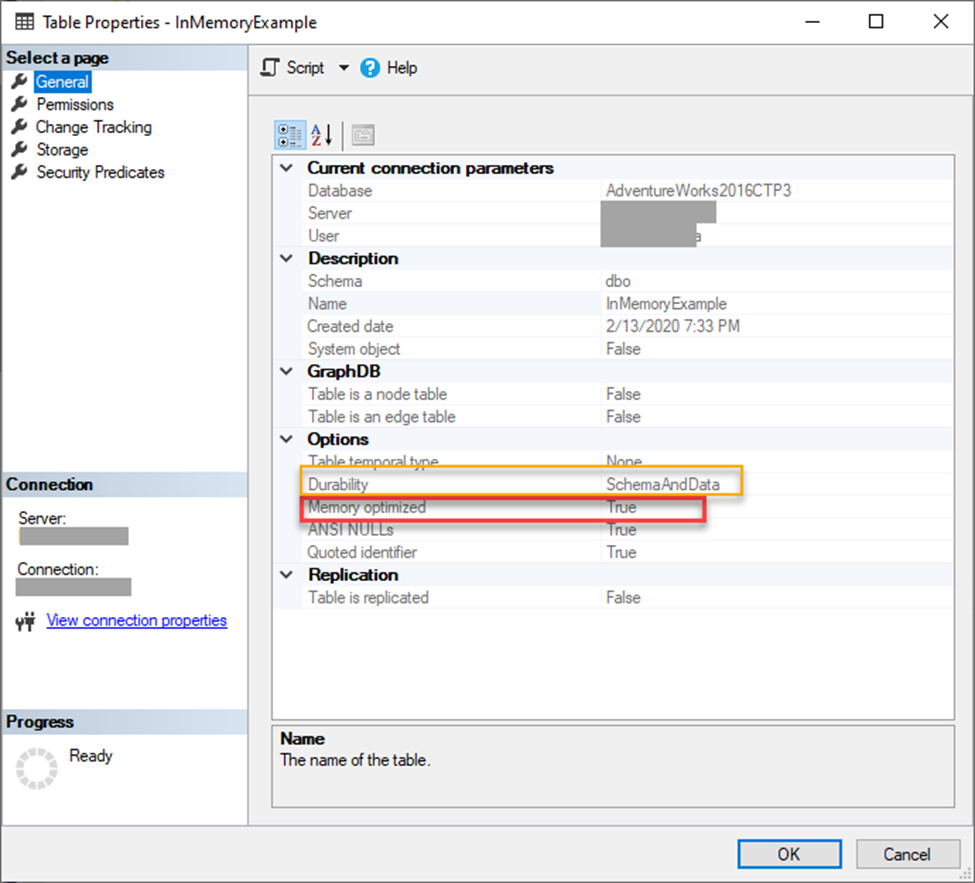
Inserting and selecting against the table is syntactically the same as any other regular table, however, internally it is far different. Above and beyond the table creation, its structured behavior is basically the same in these actions including adding or removing a column. Now one caveat to these tables is that you cannot CREATE or DROP an Index the same way. You must use ADD/DROP Index to accomplish this, and, believe me, I tried. Indexing these tables is covered later in the article.
Remember the DURABILITY option I briefly mentioned before? This is important. The example above has it set to SCHEMA_AND_DATA which means, upon database going offline, both the schema and data are preserved on disk. If you choose SCHEMA_ONLY, this means that only the structure will be preserved, and data will be deleted. This is very important to note as it can introduce data loss when used incorrectly.
As you can see, In-Memory tables are not as complicated as my brain wanted to make them. It’s a relatively simple concept that just incorporates row versioning and two copies of the table. Once you pull the concept apart into its parts, it really makes it easier to understand.
Which Tables Do I Put In-Memory?
Determining which tables could benefit from being In-Memory is made easy by using a tool called Memory Optimization Advisor (MOA). This a is a tool built into SQL Server Management Studio (SSMS) that will inform you of which tables could benefit using In-Memory OLTP capabilities, and which may have non supported features. Once identified, MOA will help you to migrate that table and data to be optimized.
To see how it works, I’ll walk you through using it on a table I use for demonstrations in AdventureWorks2016CTP3. Since this is a smaller table and doesn’t incur a ton writes it is not a good use case, however, for simplicity I am using it for this demo.
To get started, right-click on the Sales.OrderTracking table and select Memory Optimization Advisor.
This brings up the wizard. Click Next to continue.
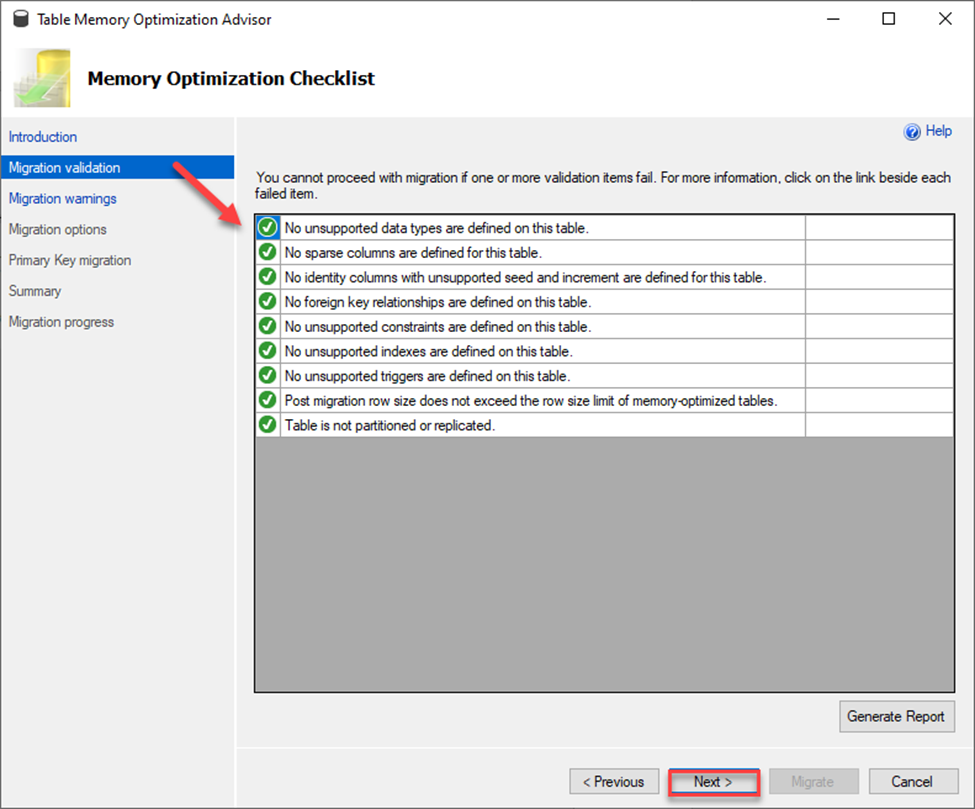
Next it will validate if your table is able to be migrated. It looks for things like unsupported data types, sparse columns, seeded columns, foreign keys, constraints and replication just to name a few. If any item fails, you must make changes and/or remove those features in order to move the table to a memory optimized table.
Next it will go over some warnings. These items, unlike the ones in the validation screen, won’t stop the migration process but can cause behavior of that option to fail or act abnormally so be aware of this. Microsoft goes a step further here and provides links to more information so that you can make an informed decision as whether or not to move forward with the migration.
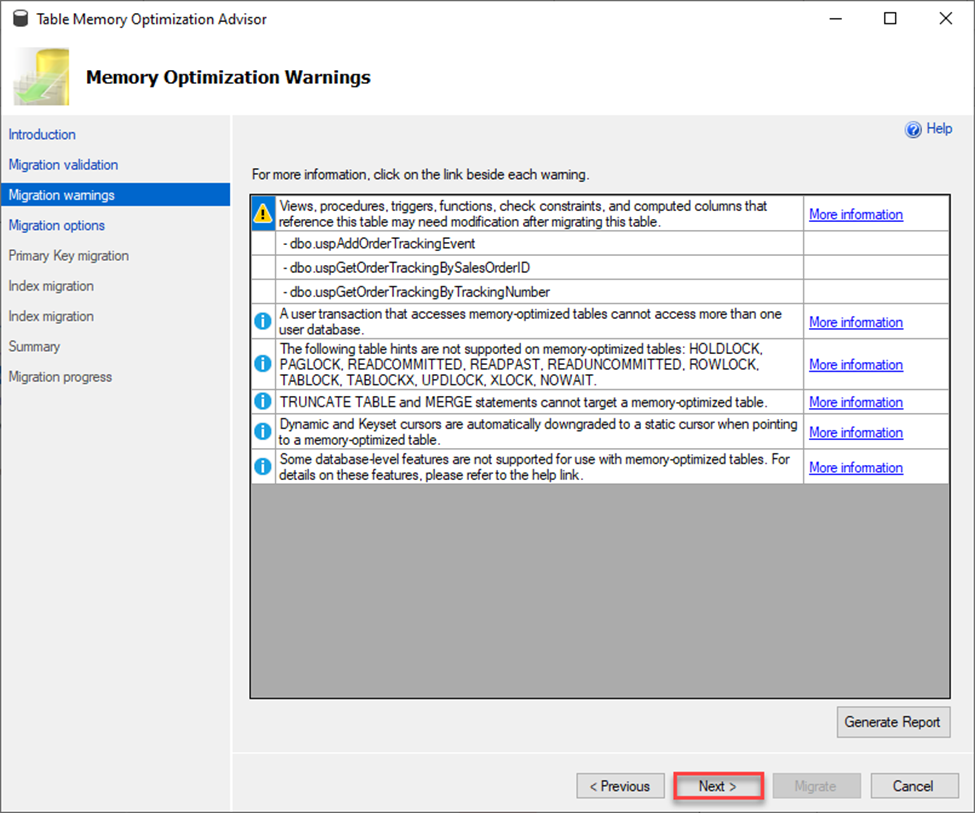
The next screen below is very important as it lets you choose options for your migration to a memory optimized table. I want to point out a few things in this next screen shot.
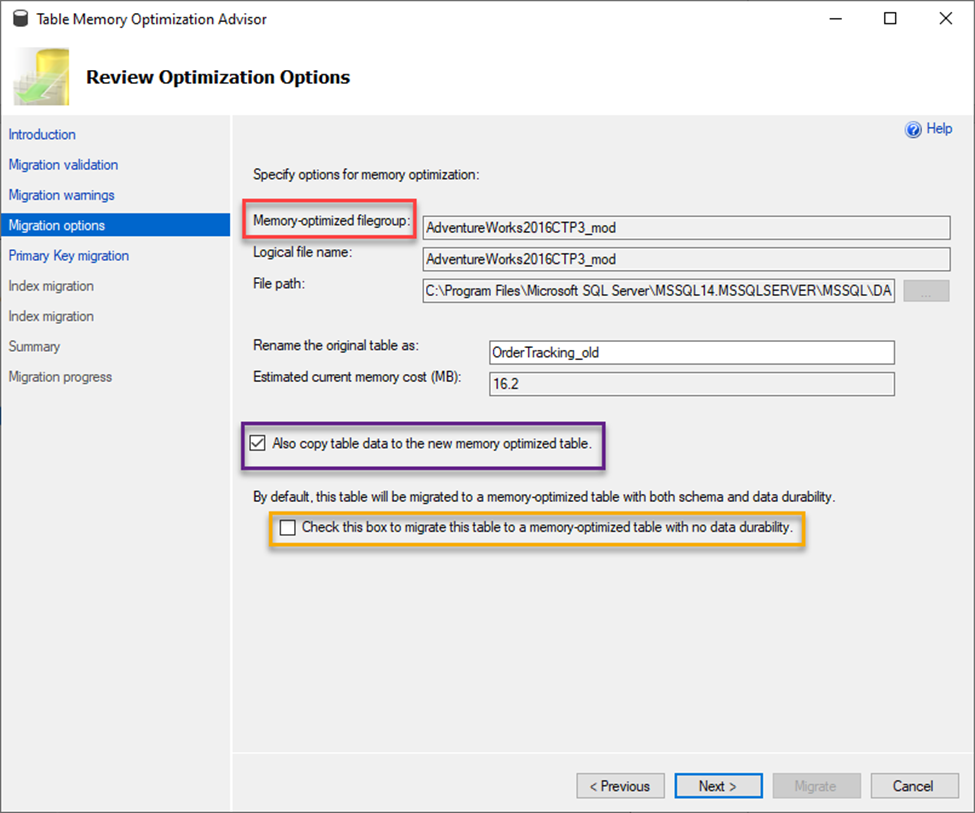
First, in the RED box, you will find requirement for a file group name. A memory optimized table must have a special file group when migrating. This is a requirement to allow you to rename the original table and keep it in place thus avoiding naming conflicts. You will note also in this screen that you can choose what to rename the original table.
Next in the PURPLE box, you will see the option to check to also have the data moved to the new table. If you do not check this option, your table will be created with no rows and you will have to manually move your data.
Next in the YELLOW box is the create table option that is equivalent to DURABILITY= SCHEMA_ONLY or SCHEMA_AND_DATA that I mentioned earlier in the article. If you do check this box, then you will not have any durability, and your data will disappear due to things like a restart of SQL Services or reboots (this may be what you want if you are using this table as though it was a TEMP TABLE and the data is not needed). Be very aware of these options because, by default, this is not checked. If you are not sure which option to choose, don’t check the box. That will ensure the data is durable. Click Next.
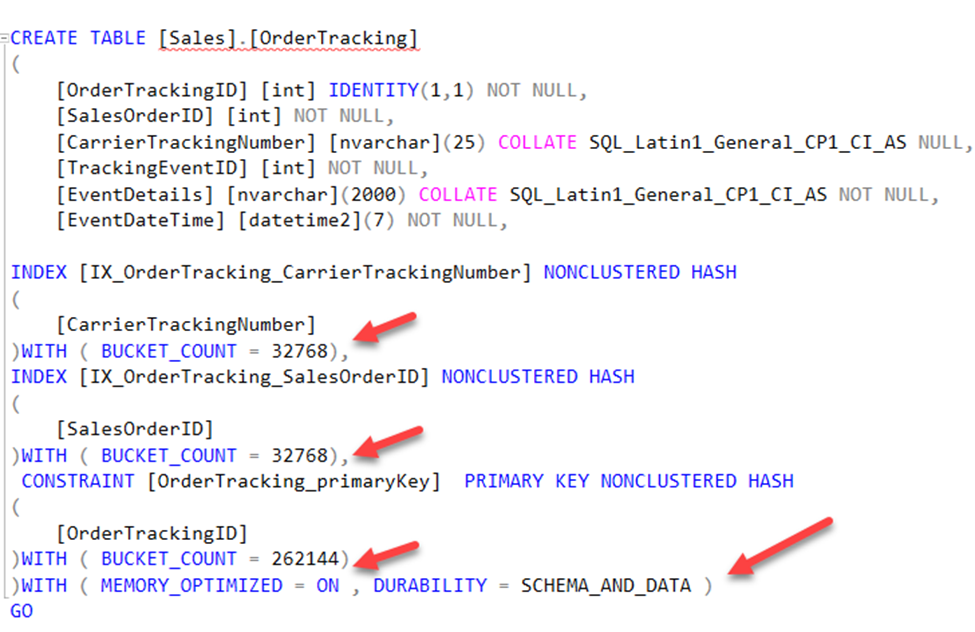
Remember that this is making a copy of your table for migration so the new optimized table cannot have the same primary key name. This next screen assists with renaming that key as well as setting up your index and bucket counts. I’ll explain bucket counts more below.
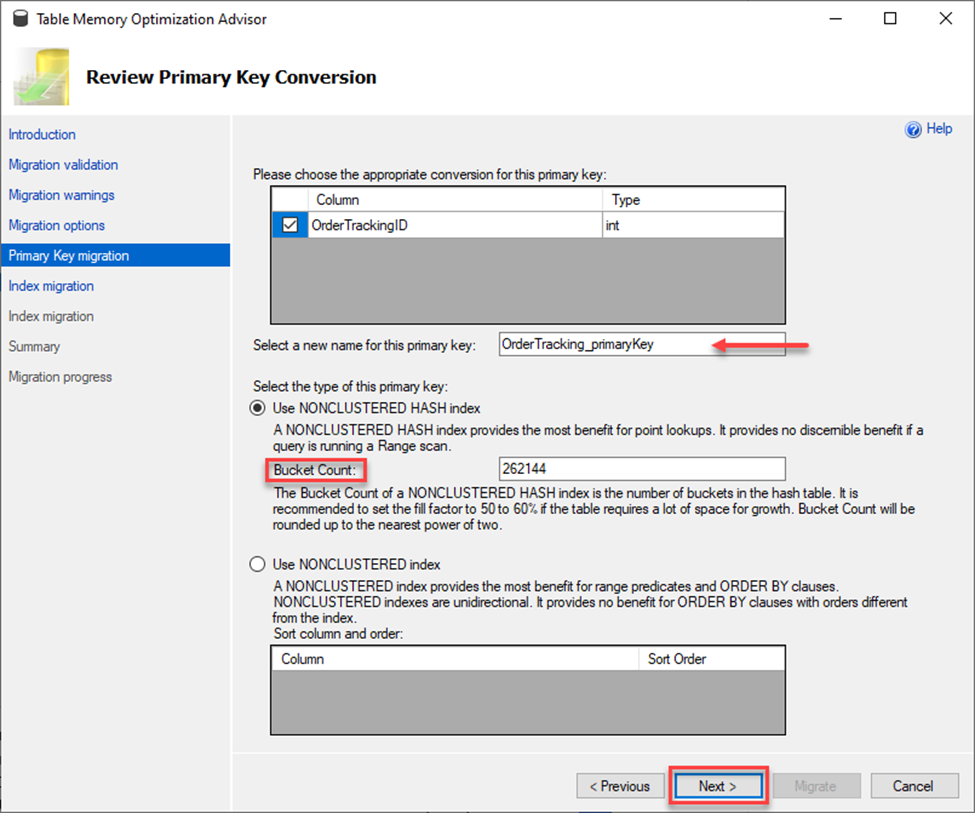
Note in the screen above it provides you a space to rename your primary key and create a new index. As you know, a primary key is an index so you must set that up. You have two options for the second index. You can use a NONCLUSTERED INDEX which is great for tables with many range queries and needing a sort order or you can use a NONCLUSTERED HASH index which is better for those direct lookups. If you choose the latter, you also need to provide a value for the Bucket Count. Bucket count can dramatically impact the performance of the table, and you should read the documentation on how to properly set this value. In the case above, I am leaving it to the pre-populated value and choosing Next.
This table has existing indexes, so the next step is to run through the setup up of those for conversion. If you do not have any existing indexes this part is bypassed.
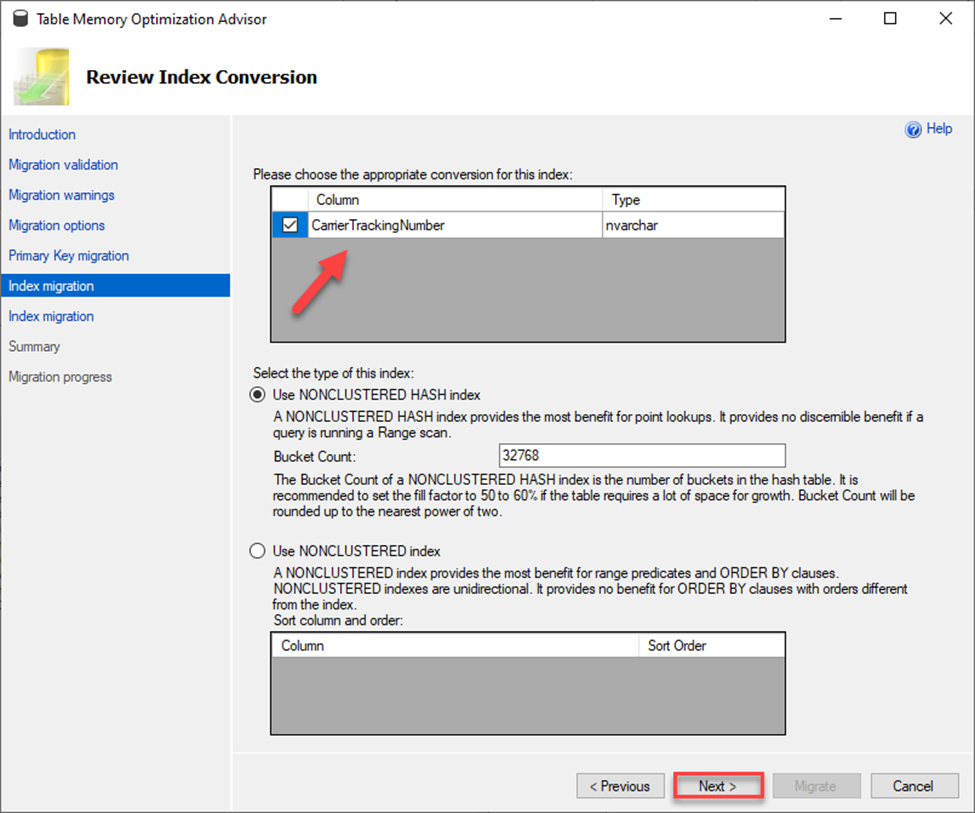
Note the two index migration options on the left. This means there are two indexes to migrate.
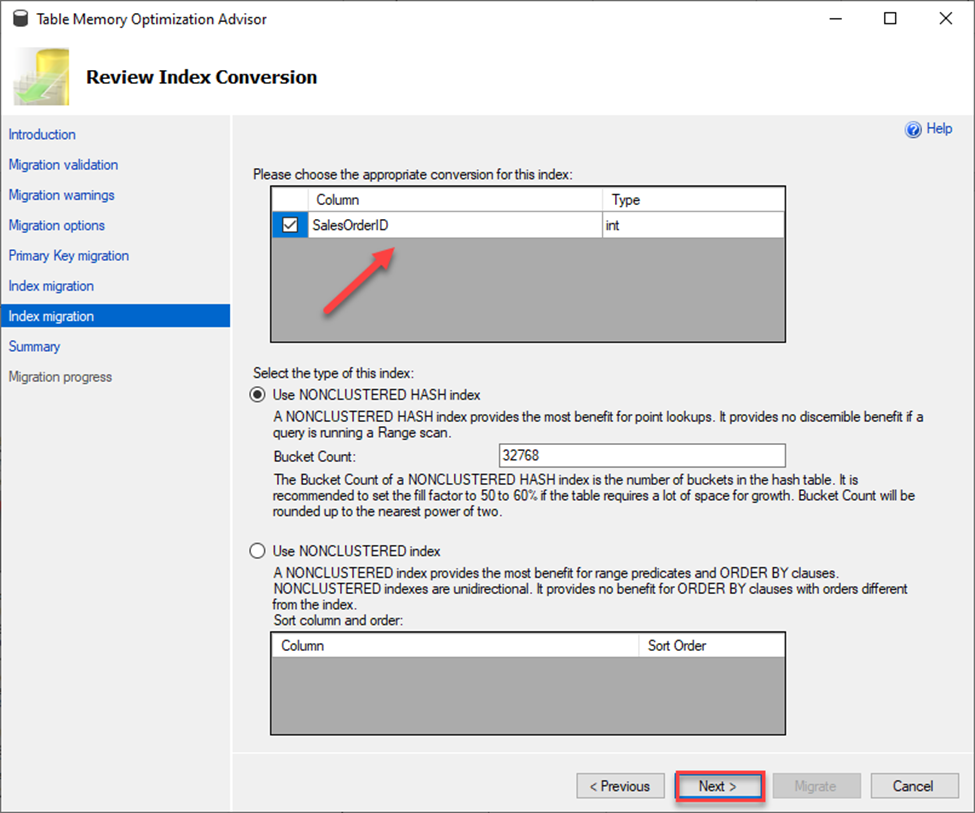
The next screen to come up is just a summary of all the migration options chosen in the setup. By choosing to migrate, you will migrate your table and its data to be an In-Memory optimized table so proceed with caution. This maybe a good time to hit the Script button and script this out for later use. Keep in mind that I already have a memory optimized file group for this database so one is not created for me. If one didn’t already exist, you would see its creation in Summary screen.
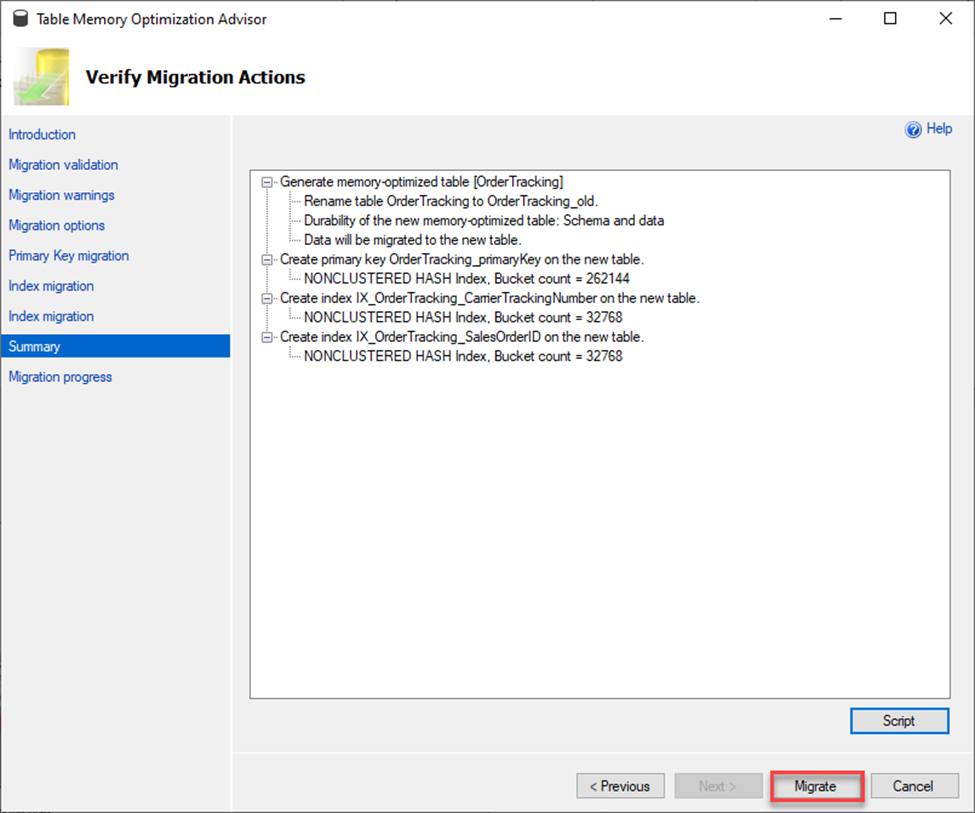
As shown below, the migration was successful. A new table was created while the old table was renamed, and the data was copied over.
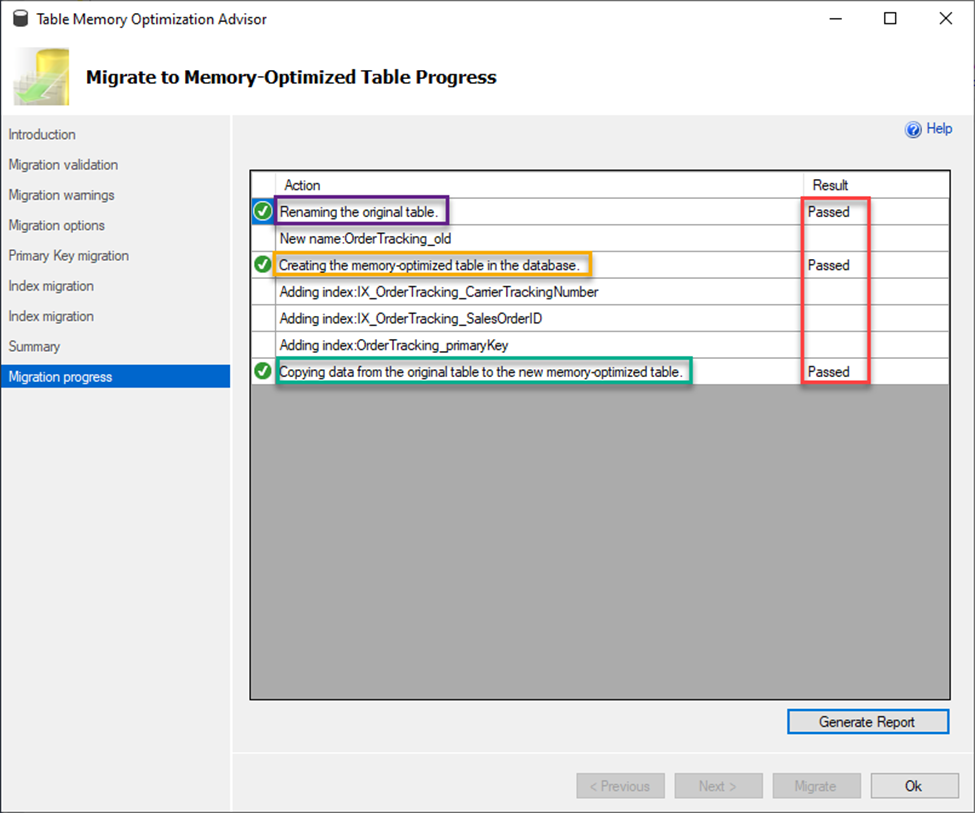
Here are the results.
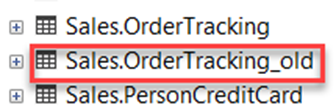
If I script out the new table now you will see that it notates it is a memory optimized table and has appropriate bucket counts. Also note I DID NOT check the box that would have made my table SCHEMA_ONLY durable and you see that reflected with the DURABILTIY = SCHEMA_AND_DATA below.
As you can see the Memory Optimization Advisor makes it simple to identify and migrate tables to In-Memory Optimized Tables. I highly advise testing this process before trying to convert any tables in your databases. Not all workloads are viable candidates for this feature, so be sure to do your due diligence before implementation. When you are ready to implement, this tool can help make that process a lot easier for you.
Now that I have explained about In-Memory Tables and Migrating to In-Memory tables, the next step is looking at indexes and how they are created and how they work within those tables. As you can imagine indexes, called memory optimized indexes are different for these types of tables, so take a look at just how different that are from regular tables.
Before diving into this subject, it is VERY important to note the biggest differences.
First, if you are running SQL Server 2014, memory optimized indexes MUST be created when the table is created or migrated. You cannot add indexes to an existing table without dropping and recreating the table. After 2016, you now have the option, and this limitation has been removed.
Secondly, prior to 2017 you could only have eight indexes per table including your primary key. Remember that every table must have a primary key to enforce a secondary copy for a minimum of schema durability. This means you can only really add seven additional indexes so be sure to understand your workloads and plan indexing accordingly. Per Microsoft, starting with SQL Server 2017 (14.x) and in Azure SQL Database, there is no longer a limit on the number of indexes specific to memory-optimized tables and table types.
Third, Memory Optimized Indexes only exist in memory, they are not persisted to disk, and are not logged in the transaction logs. Therefore, this means they are also recreated upon database startup and do incur a performance hit as they are rebuilt.
Next, there is no such thing as key lookups against an In-Memory table, as all indexes are by nature a covering index. The index uses a pointer to the actual rows to get the needed fields instead of using a primary key like physical tables do. Therefore, these are much more efficient in returning the proper data.
Lastly, there also is no such thing as fragmentation for these indexes, since these are not read from disk. Unlike on disk indexes, these do not have a fixed page length. On disk indexes use physical page structures within the B-Tree, determining how much of the page should be filled is what the Fill Factor does. Since this is not a requirement, fragmentation does not exist.
Ok now that you made it through all of that, look at the types of indexes you can create and gain an understanding of what they are and how they are created.
Nonclustered HASH Indexes
This index is used to access the In-Memory version of the table, called a Hash. These are great for predicates that are singleton lookups and not ranges of values. These are optimized for seeks of equality values. For example, WHERE Name = ‘Joe’. Something to keep in mind when determining what to include in your indexes is this: if your query has two or more fields as your predicate and your index only consists of one of those fields, you will get a scan. It will not seek on that one field that was included. Understanding your workloads and indexing on the appropriate fields (or a combination thereof) is important. Given that this In-Memory OLTP is mainly focused on heavy insert/update workloads, and less so reading, this should be less of a concern.
These types of indexes are highly optimized and do not work very well if there are a lot of duplicate values in an index, the more unique your values better the index performance gains you will get. It is always important to know your data.
When it comes to these indexes, knowing your memory consumption plays a part. The hash index type is fixed length and consumes a fixed amount of memory determined upon creation. The amount of memory is determined by the Bucket Count value. It is extremely important to make sure this value is as accurate as possible. Right sizing this number can make or break your performance. Too low of a number, according to Microsoft, “can significantly impact workload performance and recovery time of a database.” Meanwhile, you can learn more about hash indexes at docs.microsoft.
Using T-SQL (both methods give the same result)
Example One (Note the index comes after the table fields)
|
1 2 3 4 5 6 |
CREATE TABLE [Sales] ([ProductKey] INT NOT NULL, [OrderDateKey] [int] NOT NULL, INDEX IDX_ProductKey HASH ([ProductKey]) WITH (BUCKET_COUNT = 100)) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) |
Example Two (Note the index comes after the field)
|
1 2 3 4 5 |
CREATE TABLE [Sales] ([ProductKey] INT NOT NULL INDEX IDX_ProductKey HASH WITH (BUCKET_COUNT = 100), [OrderDateKey] [int] NOT NULL) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) |
Nonclustered Indexes
Nonclustered indexes are also used to access the In-Memory version of the table however, these are optimized for range values such as less than and equal to, inequality predicates and sorts orders. Examples are WHERE DATE between ‘20190101’ and ‘20191231’ and WHERE DATE <> ‘20191231’. These indexes do not require a bucket count or fixed memory amount. The memory consumed by these indexes are determined by the actual row counts and size of the indexed key columns which makes it a simpler to create.
Moreover, in contrast to hash indexes which need all fields required for your predicate to be part of your index to get a seek, these do not. If your predicates have more than one field and your index has that one of those as its leading index key value, then you can still attain a seek.
Using T-SQL (both methods give the same result)
Example One (Note the index comes after the table fields)
|
1 2 3 4 5 |
CREATE TABLE [Sales] ([ProductKey] INT NOT NULL, [OrderDateKey] [int] NOT NULL, INDEX IDX_ProductKey ([ProductKey])) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) |
Example Two (Note the index comes after the field)
|
1 2 3 4 |
CREATE TABLE [Sales] ([ProductKey] INT NOT NULL INDEX IDX_ProductKey, [OrderDateKey] [int] NOT NULL) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) |
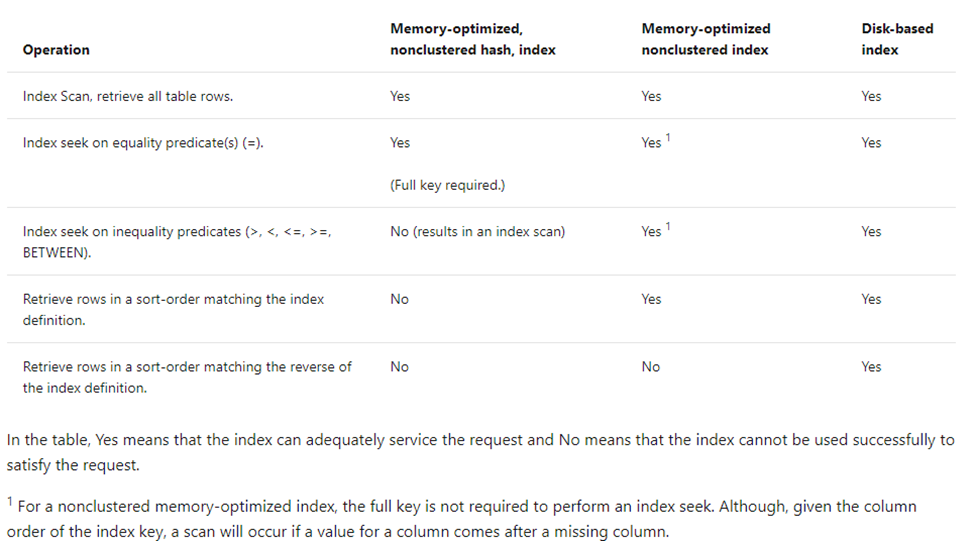
Determining which index type to use can be tricky but Microsoft has provided a great guide in the below chart.
Conclusion
As you can see there some key differences to how In- Memory table indexes, memory optimized indexes, work compared to the normal disk indexes. Like with any other table design it is important to consider your index needs before you embark on creating or migrating to memory optimized tables. You’ll be happy you did.
Fast, reliable and consistent SQL Server development…
FAQs: Memory-optimized tables in SQL Server
1. What is the difference between durable and schema-only memory-optimized tables in SQL Server?
A durable memory-optimized table (DURABILITY = SCHEMA_AND_DATA) persists both the table structure and its data to disk, so data survives a SQL Server restart. A schema-only table (DURABILITY = SCHEMA_ONLY) persists only the table definition – all data is lost on restart. Schema-only tables are ideal for temporary session state, ETL staging, or caching scenarios where data is transient and can be regenerated.
2. How do you create a memory-optimized table in SQL Server?
First, add a MEMORY_OPTIMIZED_DATA filegroup to your database. Then use CREATE TABLE with the MEMORY_OPTIMIZED = ON option and specify the DURABILITY setting. The table must have a primary key – nonclustered hash indexes or nonclustered range indexes are supported. You’ll also need to set the database compatibility level to at least 130.
3. When should you use memory-optimized tables instead of regular tables in SQL Server?
Use memory-optimized tables when your workload suffers from latch contention, lock waits, or tempdb bottlenecks on high-throughput OLTP operations. They’re particularly effective for session-state management, shopping carts, real-time IoT ingestion, and any scenario with heavy concurrent inserts/updates. They’re not ideal for analytical queries on large datasets – columnstore indexes are better suited for that pattern.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments