
- What’s the difference between statistics on a table and statistics on an index?
- How can the Query Optimizer work out how many rows will be returned from looking at the statistics?
- When data changes, SQL Server will automatically maintain the statistics on indexes that I explicitly create, if that setting is enabled. Does it also maintain the statistics automatically created on columns?
- Where are the statistics actually stored? Do they take up much space? Can I save space by only having the essential ones?
- How do I know when stats were last updated?
- How reliable is the automated update of statistics in SQL Server?
- Are there any scripts or tools that will help me maintain statistics?
- Do we update statistics before or after we rebuild/reorganize indexes?
- Is using UPDATE STATISTICS WITH FULL SCAN the same as the statistics update that happens during an index rebuild?
- How do you determine when you need to manually update statistics?
- How often should I run a manual update of my statistics?
- Is there a way to change the sample rate for particular tables in SQL Server?
- Can you create a set of statistics in SQL Server like you do in Oracle?
- Can you have statistics on a View?
- Are statistics created on temporary tables?
- How does partitioning affect the statistics created by SQL Server?
- What kind of statistics are provided for SQL Server through a linked server?
- Can statistics be imported/exported?
Try as I might, I find it hard to over-emphasize the importance of statistics to SQL Server. Bad or missing statistics leads to poor choices by the optimizer: The result is horrific performance. Recently, for example, I watched a query go from taking hours to taking seconds just because we got a good set of statistics on the data. The topic of statistics and their maintenance is not straightforward. Lots of questions occur to people when I’m doing a presentation about statistics, and some get asked in front of the rest of the audience. Then there are other questions that get asked later on, in conversation. Here are some of those other questions….
1. What’s the difference between statistics on a table and statistics on an index?
There is no essential difference between the statistics on an index and the statistics on a table. They’re created at different points and, unless you’re creating the statistics manually yourself, they’re created slightly differently. The statistics on an index are created with the index. So, for an index created on pre-existing data, you’ll get a full scan against that data as part of the task of creating the index which is also then used to create the statistics for the index. The automatically-created statistics on columns are also usually created against existing data when the column is referenced in one of the filtering statements (such as WHERE or JOIN .. ON). But these are created using sampled data, not a full scan. Other than the source and type of creation, these two types of statistics are largely the same.
2. How can the Query Optimizer work out how many rows will be returned from looking at the statistics?
This is the purpose of the histogram within the statistics. Here’s an example histogram from the Person.Address table in AdventureWorks2012:
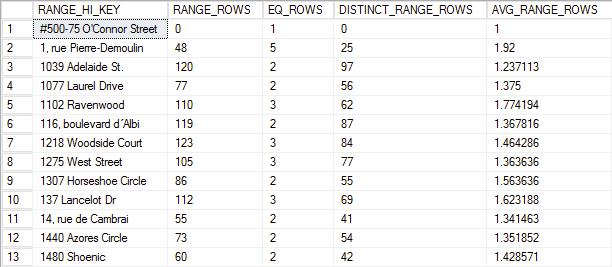
If I were doing a search for the address ‘1313 Mockingbird Lane’ then the query optimizer is going to look at the histogram to determine two things:
- Is it possible that this set of statistics contains this value
- If it does contain the value, how many likely rows will be returned
The RANGE_HI_KEY column shows the top of a set of data within the histogram, so a search for ‘1313’ would place it within the step represented by row ten which has a RANGE_HI_KEY value of ‘137 Lancelot Dr.’ So the first question is answered. The optimizer will then look at the AVG_RANGE_ROWS to determine the average number of rows that match any given value within the step. So in this case, the optimizer will assume that there are 1.623188 rows returned for the value. But, these are all estimates. In reality, the database doesn’t contain the value ‘1313 Mockingbird Lane
3. When data changes, SQL Server will automatically maintain the statistics on indexes that I explicitly create, if that setting is enabled. Does it also maintain the statistics automatically created on columns?
As data changes in your tables, the statistics – all the statistics – will be updated based on the following formula:
- When a table with no rows gets a row
- When 500 rows are changed to a table that is less than 500 rows
- When 20% + 500 are changed in a table greater than 500 rows
By ‘change’ we mean if a row is inserted, updated or deleted. So, yes, even the automatically-created statistics get updated and maintained as the data changes.
4. Where are the statistics actually stored? Do they take up much space? Can I save space by only having the essential ones?
The statistics themselves are stored within your database in a series of internal tables that include sysindexes. You can view some of the information about them using the system views sys.stats and sys.indexes, but the most detail is gleaned using a function, DBCC SHOW_STATISTICS. The statistics themselves take very little space. The header is a single row of information. The density is a set of rows with only three columns, equal in the number of rows to the number of columns defining the key columns of the statistic. Then you have the histogram. The histogram is up to 200 rows and never exceeds that amount. This means statistics do not require much room at all. While you can save a little bit of space by removing unneeded statistics, the space savings are too small to ever be worthwhile .
5. How do I know when stats were last updated?
You can look at the header using DBCC SHOW_STATISTICS. This contains a bunch of general information about the statistics in question. This example is from the Person.Address table:

As you can see, the last time the statistics were updated was January 4, 2013 at 7:01AM.
6. How reliable is the automated update of statistics in SQL Server?
You’d have to define what you mean by reliable. They are very reliable. They’re also sampled and automated to update on the criteria that we outlined in the first question. If the data in your system is fairly well distributed, as is usually the case, then the sampled statistics will work well for you. By ‘well distributed’ I mean that you’ll get a consistent view of all the available data by pulling just a sample of the data. Most systems, most of the time, will have reasonably well distributed data. But, almost every system I’ve worked with has exceptions. There always seems to be that one rogue table or that one index that’s got a very weird distribution of data, or gets updated very frequently, but not frequently enough to trigger an automatic update of the statistics. In this situation, the statistics can get stale or be inaccurate. But the problem isn’t the automated process. It’s that this data is skewed. These are the situations where you’ll need to manually take control of your statistics. This should be an exceptional event in most systems.
7. Are there any scripts or tools that will help me maintain statistics?
SQL Server provides two basic commands to help you to maintain your statistics, sp_updatestats and UPDATE STATISTICS. Sp_updatestats will look at all the statistics within a database to see if any rows have been modified in the table that the statistics support. If one or more rows have been modified, then you’ll get a sampled update of the statistics. UPDATE STATISTICS will update the statistics in the way that you specify, against the object that you specify; whether it is a table, an index, or a specific set of statistics.
8. Do we update statistics before or after we rebuild/reorganize indexes?
Just remember that, when you create an index, part of the task of creating that index is to create the statistics using a full scan of the data. Since a rebuild of an index is effectively a ‘drop and recreate’ of the index, the statistics are also recreated. I’ve frequently seen maintenance scripts that rebuild indexes and then update statistics using sp_updatestats. This basically replaces a good set of statistics based on a full scan with a less-accurate set of statistics based on random sampling. So if you are rebuilding indexes, I would not recommend updating the statistics since this is extra work for a less effective statistic.
Now when you reorganize an index, no modifications of any kind are made to the statistics. So if you’ve had enough modifications to the data that you feel you should also update the statistics, go ahead and do it for indexes that you’ve reorganized because you won’t be hurting any other work.
If you absolutely must update the statistics and rebuild the indexes and you’re not going to try to tightly control exactly which indexes and tables you do this on, then the best practice would be to update the statistics first and then rebuild the indexes second.
9. Is using UPDATE STATISTICS WITH FULL SCAN the same as the statistics update that happens during an index rebuild?
Yes. The keyword and tricky phrase that you have to look at is WITH FULL SCAN. That indicates that the full data set is used to create/update the statistics. Since rebuilding an index is, to a degree, almost the same as recreating the index, you’re getting a full scan of the data set to put the index back together. This full scan also updates the statistics. If you run UPDATE STATISTICS WITH FULL SCAN, once again, it’s looking at all the data.
10. How do you determine when you need to manually update statistics?
This is one of the hardest questions about statistics to answer, because there is no hard-and-fast formula. The short answer is that you need to determine whether the statistics accurately enough represent the distribution of the data, and update them if it doesn’t. You need to update your statistics manually when the automatic processes are either not occurring frequently enough to provide you with a good set of statistics or because the sampled nature of the automatic updates is causing your statistics to be inaccurate. The only way to know whether you need to do these things is to track the behavior of queries within your system in order to spot when the optimizer starts making bad choices. This is probably because the statistics are not reflecting the data in a way that leads to good execution plans. It’s very easy to say, but a lot of work to do.
11. How often should I run a manual update of my statistics?
The answer to that depends on many circumstances. I’ve worked on systems that never needed any manual intervention on the statistics at all. At other times I’ve experienced a problem where we were running a manual update of the statistics every two minutes (that was a horrifically broken database and indexing design, not a pattern to be emulated). More usually, you’ll be dealing with a table that gets lots of inserts, maybe with an index on a datetime column, or an identity column, so that the data is outside the range of the statistics, but, there’s not enough activity to cause the automatic update to fire. Then, you’ll need to manually update statistics on a scheduled basis.
But how often? Often enough. You’ll need to determine that period based on your system and your circumstances. There’s not a formula I can provide that will precisely tell you when to run a manual update on your statistics. Further, I can’t tell you how to sample your statistics either. You may be experiencing random sampling that is perfect , or you may need some more specified degree of sampling right up to a full scan. You’ll need to experiment to understand what the right answer is in your circumstances.
12. Is there a way to change the sample rate for particular tables in SQL Server?
You can define how statistics sample the table when you create them or update them. You can specify either the number of rows to be sampled or the percentage of the table to be sampled. You can even specify that 0 percent or 0 rows be sampled. This will update your statistics, but with no actual statistics data. It’s probably a dangerous choice. If you use sp_update stats or UPDATE STATISTICS you can specify, by using the RESAMPLE command, the sample rate that you specified when you created the statistics should then be reused. If you controlled the sample rate directly, the next time you use RESAMPLE, that sample rate will be used again. This includes statistics created on columns and on indexes.
One point worth noting is that the automatic update of statistics will be a sampled update. If you have a very specific need for a particular sample rate on statistics and there’s a good chance that the automatic maintenance could tax your system too much, you might consider turning off the automatic update for that table or set of statistics. You can do this by specifying NORECOMPUTE option when you either UPDATE or CREATE STATISTICS. You have to use the STATISTICS_NORECOMPUTE option when you create an index. You can specify NORECOMPUTE with a manual update of the statistics. But, if you do this, and the data is changing, you need to plan for manual updates to those statistics.
13. Can you create a set of statistics in SQL Server like you do in Oracle?
Oracle allows you to create custom statistics all the way down to creating your own histogram. SQL Server doesn’t give you that much control. However, you can create something in SQL Server that doesn’t exist in Oracle; filtered statistics. These are extremely useful when dealing with partitioned data or data that is wildly skewed due to wide ranging data or lots of nulls. Using AdventureWorks2012 as an example, I could create a set of statistics on multiple columns such as TaxAmt and CurrencyRateID in order to have a denser, more unique, value for the statistics than would be created by the optimizer on each of the columns separately. The code to do that looks like this:
|
1 2 3 4 |
CREATE STATISTICS TaxAmtFiltered ON Sales.SalesOrderHeader (TaxAmt,CurrencyRateID) WHERE TaxAmt > 1000 AND CurrencyRateID IS NOT NULL WITH FULLSCAN; |
This may help the optimizer to make better choices when creating the execution plan, but you’ll need to test it in any given setting.
14. Can you have statistics on a View?
No, and yes. No, your basic view is nothing but a query. That query doesn’t have statistics. It’s the same as a SELECT query inside a stored procedure or a batch statement. But, you can create a construct called an indexed view, or materialized view, which is a clustered index based on the query that defines the view. That’s an index, so it gets statistics just like any other index. Further, if you run queries that reference the columns in a filtering clause in the new clustered index, statistics can be created on those columns. While this is, strictly speaking, not the same as statistics on a view, it’s as close as you can get within SQL Server.
15. Are statistics created on temporary tables?
Yes. The major difference between a table variable and a temporary table is that a temporary table has statistics. The rules for the creation and maintenance of these statistics are exactly the same as for a regular table within SQL Server. So if you reference a column in a temporary table in a filtering command in T-SQL such as WHERE or JOIN, then a set of statistics will get created. Unfortunately, the creation of the statistics causes a statement recompile. This is a potential disadvantage of temporary tables: For small statements this is a cheap operation. For larger queries this can be very expensive. That’s a reason why you have to be careful about how you work with your temporary tables.
16. How does partitioning affect the statistics created by SQL Server?
Partitioning within SQL Server is defined through the creation of a clustered index. This clustered index has a full set of statistics based on all the data in the partition. If we’re talking about very large partitions and very large amounts of data, then there’s a good chance that the set of statistics may not be terribly accurate for the queries within your system. Oh, it will help you determine which partition to use very accurately, but within the partition you may still be seeing scans where a seek is possible. In order to help the optimizer, it’s a very good idea to create a set of manual statistics on each partition. This ensures that the data distribution of the partition is available to the optimizer to help it with making a good choice of query plan when executing your queries. For some additional details, read this overview from the SQL Server Customer Advisory Team (SQLCAT).
17. What kind of statistics are provided for SQL Server through a linked server?
None. The data on a linked server will have whatever statistics are provided by the database you’re connecting to through the linked server, on that server, but it won’t pass any statistics back to your system. If you need statistics on the data in the linked server then you’ll need to load that data into a table or temporary table (not a table variable) and create indexes and/or statistics on that table.
18. Can statistics be imported/exported?
Yes. If you look at the “Generate and Publish Scripts” wizard for a database it is possible to set up a situation where you not only script out the database, but the statistics that define that database as well. Within SQL Server Management Studio (SSMS), right click on the database in question and select “Tasks” from the context menu and then “Generate Scripts” from the sub-menu. This will launch the wizard. You can choose the objects you’re interested in and then click Next until you get to the “Set Scripting Options” step. Here, you want to click the ‘Advanced‘ button. Scroll down and you’ll find the option “Script Statistics.” You can select to script out just the base statistics or include the histogram as you can see selected below.
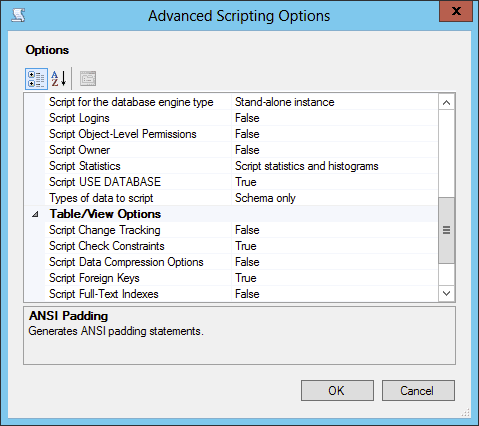
You can then output the scripts. All the objects you selected are then generated out to a script which you can use to create a new database. If you take a look at the script, you can see one of two commands, either an UPDATE STATISTICS command for objects like indexes where a set of statistics are automatically created, or CREATE STATISTICS for sets of statistics that you created manually or were created automatically for you by SQL Server. Each of these has an additional option defined WITH STATS_STREAM and then a binary value:

While SQL Server can generate this binary information, you can’t. If you look for the documentation for STATS_STREAM you won’t find it. Obviously, you can use this feature since it’s supplied by Microsoft. You can even generate your own STATS_STREAM value by using DBCC SHOW_STATISTICS WITH STATS_STREAM. But the documentation there reminds us: Not supported. Future compatibility is not guaranteed. So exercise caution when using this.
Conclusion
Dealing with statistics is definitely one of the more frustrating tasks of maintaining your SQL Server instances: However, as you can see, you have quite a large number of options which will enable you to get your statistics optimized on your server. Just remember that just as your data is not always generic, there is no generic solution for the maintenance of statistics. You’ll need to conform the solution you use to the data and the queries that are running on your system.





Load comments