
You probably have heard that table variables work fine when the table variable only contains a small number of records, but when the table variable contains a large number of records it doesn’t perform all that well. A solution for this problem has been implemented in version 15.x of SQL Server (Azure SQL Database and SQL Server 2019) with the rollout of a feature called Table Variable Deferred Compilation
Table Variable Deferred Compilation is one of many new features to improve performance that was introduced in the Azure SQL Database and SQL Server 2019. This new feature was included in the Intelligent Query Processing (IQP). See Figure 1 for a diagram that shows all the IQP features introduced in Azure SQL Database and SQL Server 2019, as well as features that originally were part of the Adaptive Query Processing feature included in the older generation of Azure SQL Database and SQL Server 2017.
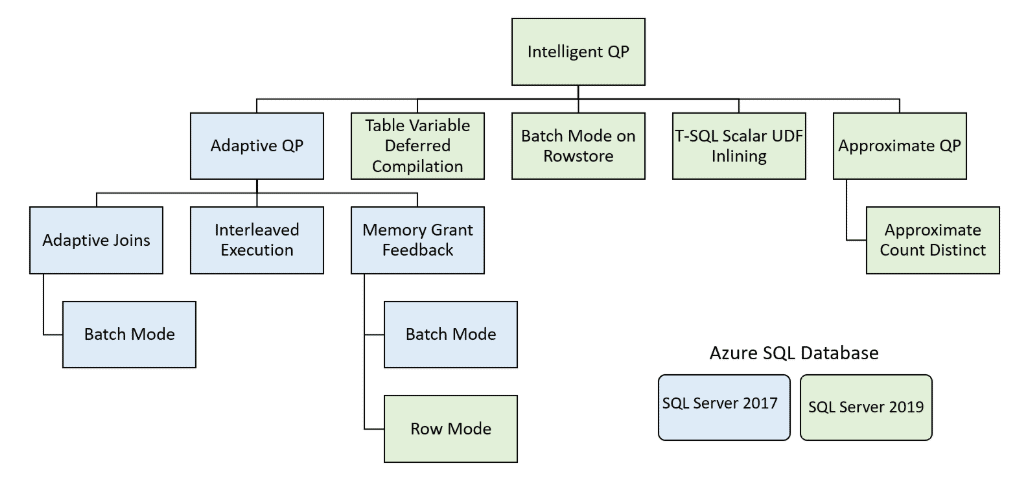
Figure 1: Intelligent Query Processing
In releases of SQL Server prior to 15.x, the database engine used a wrong assumption on the number of rows that were in a table variable. Because of this bad assumption, the execution plan that was generated didn’t work too well when a table variable contained lots of rows. With the introduction of SQL Server 2019, the database engine now defers the compilation of a query that uses a table variable until the table variable is used the first time. By doing this, the database engine can more accurately identify cardinality estimates for table variables. By having more accurate cardinality numbers, queries that have large numbers of rows in a table variable will perform better. Those queries will need to be running against a database with a database compatibility level set to 150 (version 15.x of SQL Server) to take advantage of this feature. To better understand how deferred compilation improves the performance of table variables that contain a large number of rows, I’ll run through an example, but first, I’ll discuss what is the problem with table variables in versions of SQL Server prior to version 15.x.
What is the Problem with Table Variables?
A table variable is defined using a DECLARE statement in a batch or stored procedure. Table variables don’t have distribution statistics and don’t trigger recompiles. Because of this, SQL Server is not able to estimate the number of rows in a table variable like it does for normal tables. When the optimizer compiles code that contains a table variable, prior to 15.x, it assumes a table is empty. This assumption causes the optimizer to compile the query using an expected row count of 1 for the cardinality estimate for a table variable. Because the optimizer only thinks a table variable contains a single row, it picks operators for the execution plan that work well with a small set of records, like the NESTED LOOPS operator for a JOIN operation. The operators that work well on a small number of records do not always scale well when a table variable contains a large number of rows. Microsoft documented this problem and recommends that temp tables might be a better choice than using a table variable that contains more than 100 rows. Additionally, Microsoft even recommends that if you are joining a table variable with other tables that you consider using the query hint RECOMPILE to make sure that table variables get the correct cardinality estimates. Without the proper cardinality estimates queries with large table variables are known to perform poorly.
With the introduction of version 15.x and the Table Variable Deferred Compilation feature, the optimizer delays the compilation of a query that uses a table variable until just before it is used the first time. This allows the optimizer to know the correct cardinality estimates of a table variable. When the optimizer has an accurate cardinality estimate, it has a good chance at picking execution plan operators that perform well for the number of rows in a table variable. In order for the optimizer to defer the compilation, the database must have its compatibility level set to 150. To show how deferred compilation of table variables work, I’ll show an example of this new feature in action.
Table Variable Deferred Compilation in Action
To understand how deferred compilation works, I will run through some sample code that uses a table variable in a JOIN operation. That sample code can be found in Listing 1.
Listing 1: Sample Test Code that uses Table Variable in JOIN operation
|
1 2 3 4 5 6 7 8 |
USE WideWorldImportersDW; GO DECLARE @MyCities TABLE ([City Key] int not null); INSERT INTO @MyCities SELECT [City Key] FROM Dimension.City; SELECT O.[Order Key], TV.[City Key] FROM Fact.[Order] as O INNER JOIN @MyCities as TV ON O.[City Key] = TV.[City Key]; |
As you can see, this code uses the WideWorldImportersDW database, which can be downloaded here. In this script, I first declare my table variable @MyCities and then insert 116,295 rows from the Dimension.City table into the variable. That variable is then used in an INNER JOIN operation with the Fact.[Order] table.
To show the deferred compilation in action, I will need to run the code in Listing 1 twice. The first execution will be run against the WideWorldImportsDW using compatibility code 140, and the second execution will run against this same database using compatibility level 150. The script I will use to compare how table variables work, using the two difference compatibility levels, can be found in Listing 2.
Listing 2: Comparison Test Script
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
USE WideWorldImportersDW; GO -- Turn on time statistics SET STATISTICS TIME ON; GO --------------------------------------------------- -- Test #1 - Using SQL Server 2017 compatibility -- --------------------------------------------------- ALTER DATABASE WideWorldImportersDW SET COMPATIBILITY_LEVEL = 140; GO DECLARE @MyCities TABLE ([City Key] int not null); INSERT INTO @MyCities SELECT [City Key] FROM Dimension.City; SELECT O.[Order Key], TV.[City Key] FROM Fact.[Order] as O JOIN @MyCities as TV ON O.[City Key] = TV.[City Key] --------------------------------------------------- -- Test #2 - Using SQL Server 2019 compatibility -- --------------------------------------------------- ALTER DATABASE WideWorldImportersDW SET COMPATIBILITY_LEVEL = 150; GO USE WideWorldImportersDW; GO DECLARE @MyCities TABLE ([City Key] int not null); INSERT INTO @MyCities SELECT [City Key] FROM Dimension.City SELECT O.[Order Key], TV.[City Key] FROM Fact.[Order] as O JOIN @MyCities as TV ON O.[City Key] = TV.[City Key]; GO |
When I run the code in Listing 2, I run it from a query window in SQL Server Management Studio (SSMS), with the Include Actual Execution Plan query option turned on. The execution plan I get with I run query Test #1 and #2 can be found in Figure 2 and Figure 3, respectfully.
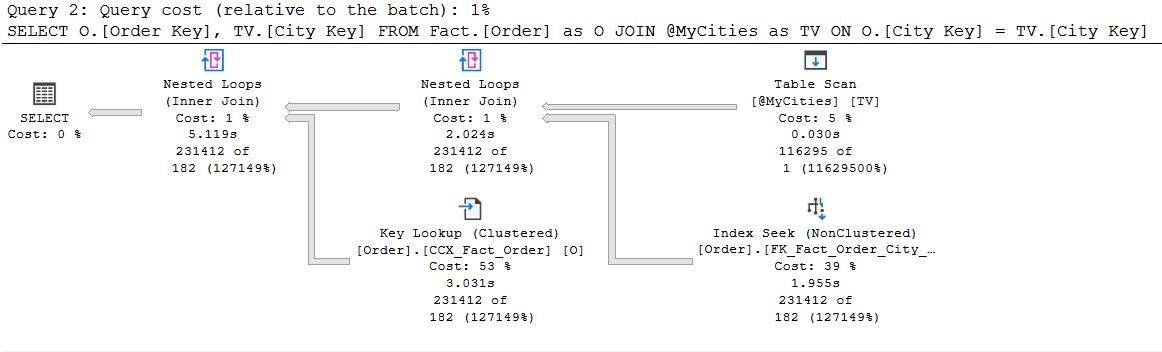
Figure 2: Execution Plan for Test #1 code in Listing 2, using compatibility level 140
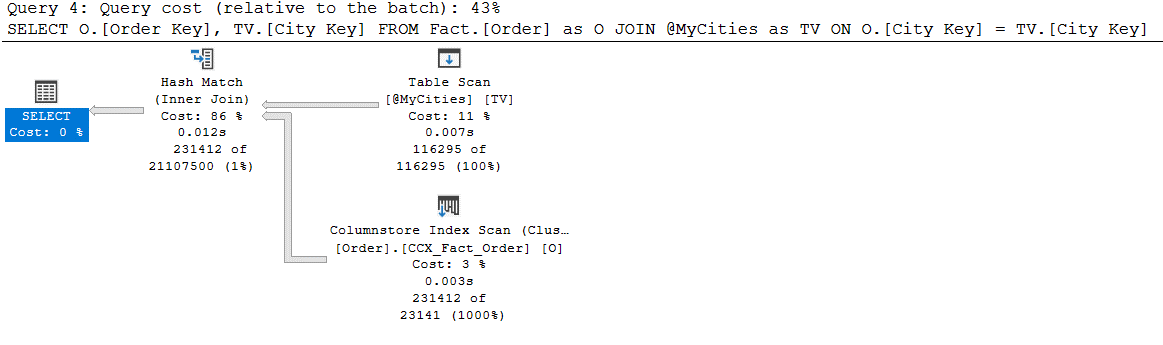
Figure 3: Execution Plan for Test #2 code in Listing 2, using compatibility level 150
If you compare the execution plan between Figure 2 and 3, you will see the execution plans are a little different. When compatibility mode 140 was used, my test query used a NESTED LOOPS operation to join the table variable to the Fact.[Order] table, whereas when using compatibility mode 150, the optimizer picked a HASH MATCH operator for the join operation. This occurred because the Test #1 query uses an estimated row count of 1 for the table variable @MyCities. Whereas the Test #2 query was able to use the deferred table variable compilation feature which allowed the optimizer to use an estimated row count of 116,295 for the table variable. These estimated row count numbers can be verified by looking at the Table Scan operator properties for each execution plan, which are shown in Figure 4 and 5 respectfully.
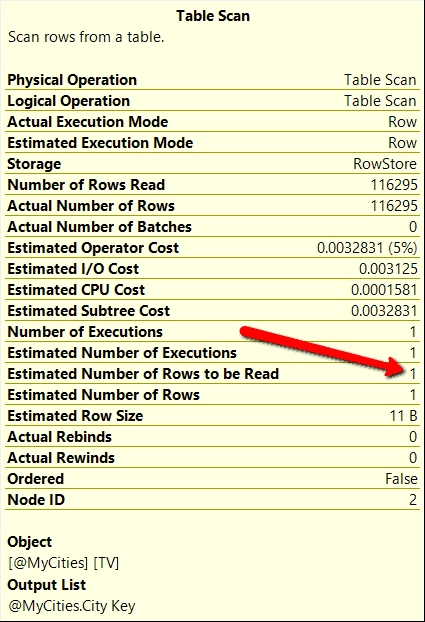
Figure 4: Table Scan properties when Test #1 query ran under compatibility level 140
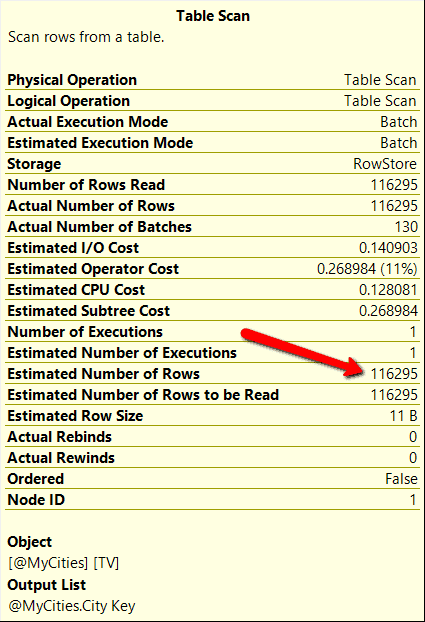
Figure 5: Table Scan properties when Test #2 query ran under compatibility level 150
By reviewing the table scan properties, the optimize used the correct estimated row count when compatibility level 150 was used. Whereas when compatibility level 140 was used, the optimizer estimated a row count of 1. Also note that my query that ran under compatibility level 150 also used BATCH mode for the TABLE SCAN operation, whereas the compatibility mode 140 query ran using ROW mode. You may be asking yourself now, how much faster does running my test code under compatibility level 150 perform over running the test code under the older compatibility level 140.
Comparing Performance between Compatibility Mode 140 and 150
In order to compare the performance of running my test query under both compatibility level, I executed the script in Listing 1 ten different times under each of the two compatibility levels. I then calculated the average CPU and elapsed time for the two different compatibility levels, and finally graphed the average performance number in the graph in Figure 6.
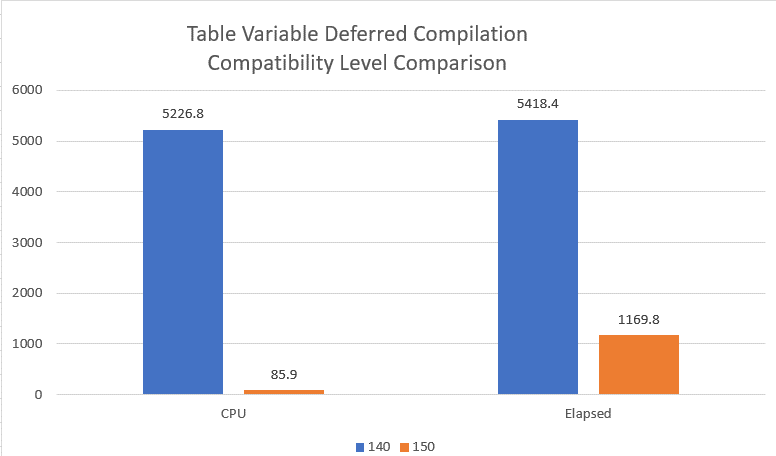
Figure 6: Performance Comparison between Compatibility Mode 140 and 150.
When the test query was run under compatibility mode 150, it used a fraction of the CPU over compatibility level 140. Whereas the Elapsed Time value of the test query that ran under compatibility level 150 ran 4.6 times faster than then using compatibility level 140. This is a significate performance improvement. But since batch mode processing was for the compatibility level 150 test, I can’t assume all this improvement was associated with only the Deferred Table Variable Compilation feature.
In order to remove the batch mode from my performance test, I’m going to run my test query under compatibility mode 150 one more time. But this time my test will run with a query hint to disable the batch mode feature. The script I will use for this additional test can be found in Listing 3.
|
1 2 3 4 5 6 7 8 9 10 |
USE WideWorldImportersDW; GO DECLARE @MyCities TABLE ([City Key] int not null); INSERT INTO @MyCities SELECT [City Key] FROM Dimension.City SELECT O.[Order Key], TV.[City Key] FROM Fact.[Order] as O JOIN @MyCities as TV ON O.[City Key] = TV.[City Key] OPTION(USE HINT('DISALLOW_BATCH_MODE')); GO 10 |
Listing 3: Test #2 query with Batch Mode disabled
The graph in Figure 7 shows the new performance comparison results using deferred compilation and row mode features when my test ran under compatibility level 150.
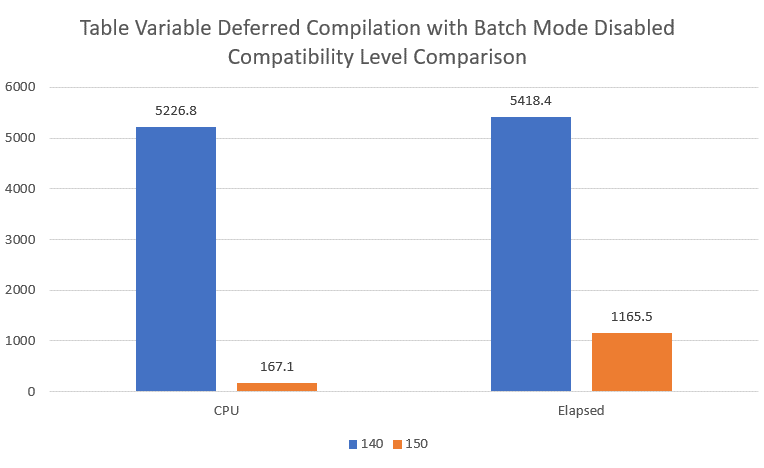
Figure 7: Table Variable Deferred Compilation Comparison with Batch Mode disabled
With the Batch Mode feature disabled, my CPU went up significantly from my previous test when batch mode was enabled. But the Elapsed Time was only slightly different. Deferred Compilation seems to provide significate performance improvements, by delaying the compilation of a query until the table variable is used the first time. I have to wonder if the deferred compilation feature will improve the cardinality estimate issue caused by parameter sniffing with a parameterized query.
Does Deferred Compilation Help with Parameter Sniffing?
Parameter sniffing has been known to cause performance issues when a compiled execute plan is executed multiple times using different parameter values. But does the deferred table variable compilation feature in 15.x solve this parameter sniffing issue? To determine whether or not it does, let me create a stored procedure name GetOrders, to test this out. That stored procedure CREATE statement can be found in Listing 4.
Listing 4: Code to test out parameter sniffing
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE WideWorldImportersDW; GO CREATE OR ALTER PROC GetOrders(@CityKey int) AS DECLARE @MyCities TABLE ([City Key] int not null); INSERT INTO @MyCities SELECT [City Key] FROM Dimension.City WHERE [City Key] < @CityKey; SELECT * FROM Fact.[Order] as O INNER JOIN @MyCities as TV ON O.[City Key] = TV.[City Key] GO |
The number of rows returned by the stored procedure in Listing 4 is controlled by the value passed in the parameter @MyCities. To test if the deferred compilation feature solves the parameter sniffing issue, I will run the code in Listing 5.
Listing 5: Code to see if deferred compilation resolves parameter sniffing issue
|
1 2 3 4 5 6 7 8 |
USE WideWorldImportersDW; GO SET STATISTICS IO ON; DBCC FREEPROCCACHE; -- First Test EXEC GetOrders @CityKey = 10; --Second Test EXEC GetOrders @CityKey = 231412; |
The code in Listing 5 first runs the test stored procedure using a value of 10 for the parameter. The second execution uses the value 231412 for the parameter. These two different parameters will cause the store procedure to process drastically different numbers of rows. After I run the code in Listing 5, I will explore the execution plan for each execution of the stored procedure. I will look at the properties of the TABLE SCAN operation to see what the optimizer thinks are the estimated and actual rows count for the table variables for each execution. The table scan properties for each execution can be found in Figure 8 and 9 respectfully.
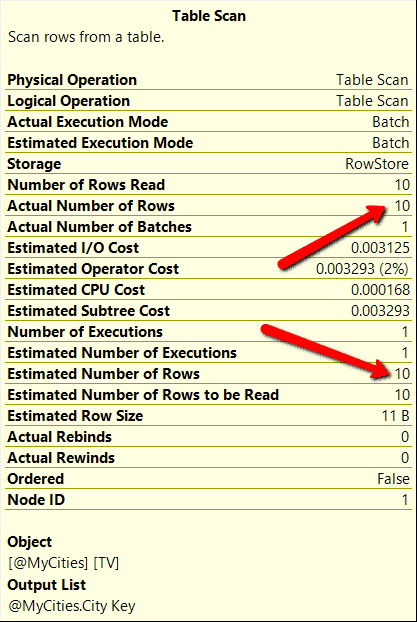
Figure 8: Table Scan Statistics for the first execution of the test stored procedure
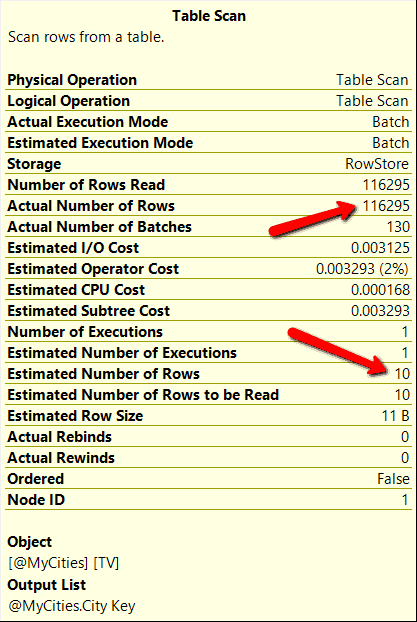
Figure 9: Table Scan Statistics for the second execution of the test stored procedure
Both executions got the same number of estimated rows counts but got considerably different actual row counts. This means that the deferred table compilation feature of version 15.x doesn’t resolve the parameter sniffing problem of a stored procedure.
What Editions Supports the Deferred Compilations for Table Variables?
Like many cool new features that have come out with each new release of SQL Server in the past, they are first introduced in Enterprise edition only, and then over time, they might become available in other editions. You will be happy to know that the Deferred Compilation for Table Variables feature doesn’t follow this typical pattern. As of the RTM release of SQL Server 2019, the deferred compilation feature is available in all editions of SQL Server, as documented here.
Improve Performance of Code using Table Variables without Changing Any Code
TSQL code that contains a table variable has been known not to perform well when the variable contains lots of rows. This is because the code that declares the table valuable is compiled before the table has been populated with any rows of data. Well, that has all changed when TSQL code is executed in SQL Server 2019 or Azure SQL DB when your database is running under compatibility level 150. When using a database that is in compatibility level 150, the optimizer defers the compilation of code using a table variable until the first time the table variable is used in a query. By deferring the compilation, SQL Server can obtain a more accurate estimate of the number of rows in the table variable. When the optimizer has better cardinality estimates for a table variable, the optimizer can pick more appropriate operators for the execution plan, which leads to better performance. Therefore, if you have found code where table variables don’t scale well when they contain a lot of rows, then possibly version 15.x of SQL Server might help. By running TSQL code under compatibility level 150, you can improve the performance of code using table variables without changing any code.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments