
Over time data in SQL Server tables needs to be modified. There are two major different aspects of modifying data: updating and deleting. In my last article “Updating SQL Server Data” I discussed using the UPDATE statement to change data in existing rows of a SQL Server table. In this article I will be demonstrating how to use the DELETE statement to remove rows from a SQL Server Table.
Syntax of the Basic DELETE statement
Deleting data seems like a simple concept so you would think the syntax for a DELETE statement would be super simple. In some respects that is true, but there are many ways and aspects of how the DELETE statement can be used. In this article I will be discussing only the basic DELETE statement.
The syntax for basic DELETE statement can be found in Figure 1:
| DELETE
[ TOP (<expression>) [ PERCENT ] ] [ FROM ] <object> [ WHERE <search_condition>] |
Figure 1: Basic syntax of the DELETE statement
Where:
expression– Identifies the number or percentage of rows to be delete. When only theTOPkeyword is identified the expression identifies the number of rows to be deleted. It the keywordPERCENTis also included then the expression identifies the percentage of rows to be delete.object– Identifies the table or view from which rows will be deleted.search_condition– Identifies the criteria for which a row must meet in order to be deleted. Thesearch_conditionis optional. When it is excluded from aDELETEstatement, then all the rows in the object will be deleted.
For the complete syntax of the DELETE statement refer to the Microsoft Documentation which can be found here.
To better understand the syntax of the simple DELETE statement and how to use it, several examples are provided below. But before these examples can be run a couple sample tables need to be created.
Sample Data
Listing 1 contains a script to create two sample tables in the tempdb database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
USE tempdb; GO CREATE TABLE dbo.LoginTracking ( ID INT IDENTITY(1,1), LoginName varchar(100), LoginDataTime datetime, LogoffDateTime datetime); GO INSERT INTO dbo.LoginTracking VALUES ('Scott','2022-07-11 08:41:31','2022-07-11 11:45:50'), ('Sally','2022-07-11 08:55:27','2022-07-11 11:59:59'), ('Dick','2022-07-11 09:05:17','2022-07-11 16:15:37'), ('Dick','2022-07-12 08:05:11','2022-07-12 15:50:31'), ('Scott','2022-07-12 08:12:27','2022-07-12 16:11:22'), ('Sally','2022-07-12 09:20:06','2022-07-12 16:45:11'), ('Dick','2022-07-13 08:10:13','2022-07-13 15:59:45'), ('Scott','2022-07-13 08:12:37','2022-07-13 16:21:38'), ('Sally','2022-07-13 09:07:05','2022-07-13 16:55:17'); GO CREATE TABLE dbo.LoginsToRemove( LoginName varchar(100)); GO INSERT INTO dbo.LoginsToRemove VALUES ('Sally'); GO |
Listing 1: Script to create sample tables.
The first table created in Listing 1 is the dbo.LoginTracking table. This table is the table from which rows will be deleted. The second table created is dbo.LoginsToRemoved. This table is a staging table that contains a single column named LoginName. This table will be used to show how to delete rows using rows in another table.
If you would like to follow along and run the code in this article you can use Listing 1 to create the two sample tables in the tempdb database on your instance of SQL Server.
Deleting a Single Row
To delete a single row, the DELETE command needs to identify the specific row that needs to be deleted. This is done by including a WHERE constraint. The WHERE constraint needs to uniquely identify the specific row to delete. The code in Listing 2 will delete the LoginTracking record that have a LoginName “Scott” and an ID value of 1.
|
1 2 3 4 5 6 |
USE tempDB; GO DELETE FROM dbo.LoginTracking WHERE LoginName = 'Scott' and ID = 1; GO |
Listing 2: Deleting a single row
In the LoginTracking table there are multiple rows that have a LoginName of “Scott”. Therefore the ID column value of “1” was also included in the search_condition to uniquely identify which single row was to be deleted.
Only the ID column alone could have been used to identify the single record to be deleted. However, in many cases having extra filter conditions can be useful. For example, if the row where ID = 1 has a different LoginName, it would not be deleted.
Note: When you are expecting a certain number of rows to be deleted, it is a good idea to check the value in @@ROWCOUNT to make sure.
Deleting Multiple Rows
A single DELETE statement can also be used to delete multiple rows. To delete multiple rows the WHERE clause needs to identify each row in the table or view that needs to be deleted. The code in Listing 3 identifies two LoginTracking rows to delete by identifying the ID column values for the rows to be deleted.
|
1 2 3 4 5 6 |
USE tempDB; GO DELETE FROM dbo.LoginTracking WHERE ID = 2 or ID=3; GO |
Listing 3: Deleting multiple rows with a single DELETE statement
By specify a WHERE clause, that identifies multiple rows the code in Listing 2 will delete multiple rows in the LoginTracking table when this code is executed.
Using the TOP Clause to Delete Rows of Data
When the TOP clause is included with a DELETE statement, it identifies the number of random rows that will be deleted from the table or view being referenced. There are two different formats for using the TOP clause. (1) identifies the number of rows to be delete.
The code in Listing 4 shows how to use the TOP clause to delete one random row from the LoginTracking table.
|
1 2 3 4 5 |
USE tempdb; GO DELETE TOP(1) FROM dbo.LoginTracking; GO |
Listing 4: Deleting one row using the TOP clause
The reason the top clause deletes random row is because SQL Server does not guarantee the order rows will be returned, without an ORDER clause.
If you need to delete rows in a specific order, it is best to use a subquery that uses TOP and an order by, as shown in Listing 5.
|
1 2 3 4 5 6 7 |
USE tempdb; GO DELETE TOP (2) FROM dbo.LoginTracking WHERE ID IN (SELECT TOP(2) ID FROM dbo.LoginTracking ORDER BY ID DESC); GO |
Listing 5: Deleting the last 2 rows based in ID
Executing the code in Listing 5 deletes the last two rows in the LoginTracking table, based on the descending order of the ID column. The code accomplished this by using a subquery in the WHERE constraint. The subquery uses the TOP clause to identify the two ID values that will be deleted based on descending sort order. This list of ID values is then used as the WHERE filter condition to identify the two rows to be delete.
Note: in this case, the TOP (2) in the DELETE is technically redundant. But if the ID column didn’t contain unique values, and the TOP clause would need to be included to make sure only two rows would have been deleted,.
The TOP clause in the prior two examples identified a specific number of rows to be deleted. The TOP clause also supports identifying a percentage of rows to delete. Before showing an example of deleting a percentage of rows using the TOP clause let’s first review the details of the rows still in the LoginTracking table, by running the code in the Listing 6.
|
1 2 3 4 |
USE tempdb; GO SELECT * FROM dbo.LoginTracking; |
Listing 6: Displaying the rows currently in the dbo.LoginTracking table
When the code in Listing 6 is run the results in Report 1 are displayed.
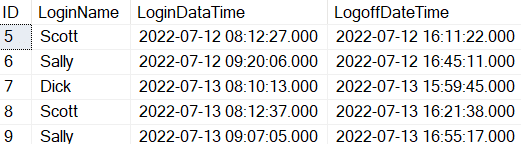
Report 1: Current rows in the LoginTracking table.
Currently there are 5 rows in the LoginTracking table.
To delete a percentage of the rows in a table the TOP clause is use along with the PERCENT keyword. The expression provided provide with the TOP clause identifies the percentage of rows to delete. The code in Listing 7 specifies 41 percent of the rows in the LoginTracking table should be deleted.
|
1 2 3 4 5 6 |
USE tempdb; GO DELETE TOP(41) PERCENT FROM dbo.LoginTracking; GO SELECT * FROM dbo.LoginTracking; GO |
Listing 7: Deleting 41 percent of the rows using the TOP clause.
When Listing 4 is executed the output in Report 2 is displayed.

Report 2: Number left in LoginTracking after the code in Listing 7 was run
By reviewing Report 2 and comparing it with Report 1 results, you can see 3 rows were deleted, which means 60 percent of the rows were deleted. Why 60 percent? The reason 60 percent of the rows were deleted is because SQL Server needs to delete a percentage of rows that equates to a whole number. Since 41 percent of 5 rows would have been 2.05 of the rows in the LoginTracking tracking table, SQL server rounded the row count up to 3. 3 equates to 60 percent of the rows when it performed the DELETE statement.
Using a Table to Identify the Row to Delete
There are times when you might need to identify rows to delete based on a table. To show how to delete rows based on rows in a table, the LoginsToRemove table was created in Listing 1. The LoginsToRemove table could be considered a staging table, which identifies the logins that need to be deleted. The code in Listing 8 uses this table to delete rows from the LoginTracking table.
|
1 2 3 4 5 6 7 |
USE tempdb; GO DELETE FROM dbo.LoginTracking FROM dbo.LoginTracking JOIN dbo.LoginsToRemove ON LoginTracking.LoginName = LoginsToRemove.LoginName GO |
Listing 8: Using a table to identify rows to be deleted from a table
The code in Listing 8 joined the LoginsToRemove table with the LoginTracking table on the LoginName column from each table. This join operation only finds those rows in the LoginTracking table which have a matching LoginName in the LoginsToRemove table. In this example all the records that had “Sally” as a LoginName got deleted from the LoginTracking table.
Deleting all Rows from a Table
The DELETE statement can be used to remove all the rows in a table. To accomplish this a DELETE Statement without a WHERE constraint can be executed, as in Listing 9.
|
1 2 3 4 5 |
USE tempdb; GO DELETE FROM dbo.LoginTracking; GO |
Listing 9: Deleting all the rows in a table.
Even though the DELETE statement can delete all the rows in a table, as done in Listing 9, this is not the most efficient way to delete all the rows in a table. The DELETE statement performs a row-by-row operation to delete all the rows. Every time a row is deleted information needs to be written to the transaction log file, based on the database recovery model option. If there are a lot of rows in a table, it could take a long time and use a lot of resources to delete all the rows using a DELETE operation.
An alternative method to remove all rows in a table
A more efficient, though more limited method to delete all rows is to use the TRUNCATE TABLE statement as shown in Listing 10.
|
1 2 3 4 5 |
USE tempDB; GO TRUNCATE TABLE dbo.LoginTracking; GO |
Listing 10: Deleting all the rows in a table using a TRUNCATE TABLE statement
When a TRUNCATE TABLE statement is used, less information is logged to the transaction log file, as well as has some other significate differences. One of those differences is when a DELETE statement is used, if all the rows are deleted from a physical DATA page the page is left empty in the database, which wastes valuable disk space. Additionally, a TRUNCATE TABLE option requires less locks to remove all the rows.
Another important difference is how these two different delete methods affect the identity column’s seed value. When a TRUNCATE TABLE statement is executed the seed value for the identity column is set back to the seed value of the table. Whereas the DELETE statement retains the last identity column value inserted. This means when a new row is inserted, after all the rows were deleted, using a DELETE statement, that the next identify value will not start at the seed value for the table. Instead, the new row’s identity value will be the determined based off the last identity value inserted, and the increment value for the identity column. These differences need to be kept in mind when deleting rows using the DELETE statement during testing cycles.
There are two major limitations to consider. First, the table being truncated cannot be referenced in a FOREIGN KEY constraint. The second is security. To be able to execute a DELETE statement that references a table, you need DELETE permissions. To execute TRUNCATE TABLE you need ALTER TABLE rights, which gives the user the ability to change the table’s structure. For more details on TRUNCATE TABLE, check the Microsoft documentation here.
Deleting data using a view
Deleting from a view is the same as deleting from a table, with one caveat. The delete can only affect one table. This essentially means that the FROM clause of the view can only reference one table to be the target of a DELETE statement. You could have conditions (like subqueries) that reference other objects, but no joins. For example, in listing 11, consider the two view objects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE VIEW dbo.v_LoginTracking AS SELECT ID, LoginName, LoginDataTime, LogoffDateTime FROM dbo.LoginTracking; GO CREATE VIEW dbo.v_LoginTracking2 AS SELECT LoginTracking.ID, LoginTracking.LoginName, LoginTracking.LoginDataTime, LoginTracking.LogoffDateTime FROM dbo.LoginTracking JOIN dbo.LoginsToRemove ON LoginTracking.LoginName = LoginsToRemove.LoginName GO |
Listing 11: View objects to demonstrate how deleting from a view works
Executing a DELETE statement in the first view: dbo.v_LoginTracking, will work. But attempt to delete rows using the second view: dbo.v_LoginTracking, and you will get the following error.
View or function 'dbo.v_LoginTracking2' is not updatable because the modification affects multiple base tables.
Deleting Rows from a SQL Server table
The DELETE statement is used to delete rows in a SQL Server table or view. By using the DELETE statement, you can delete one or more rows from an object. If all the rows in a table need to be deleted, a DELETE statement is less efficient then using the TRUNCATE TABLE statement, but has fewer limitations and doesn’t reset the identity value information.
Knowing how to use the basic DELETE statement, and when not to use it is important concept for every TSQL programmer to understand.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments