
The transaction log is a file that each SQL Server database has. It can be thought of as a journal of update activity that has occurred to a database. The transaction log is used to maintain the integrity of the database. The information stored about a transaction can be used to roll it back if, for some reason, it is not successfully committed or a system failure occurs. In this article, I will cover the architecture of the transaction log.
ACID principle
The transaction log is used to maintain the integrity of the database. When transactions are performed against a database, they need to be written completely and accurately to the data files of a SQL Server database. If they are not completed 100% successfully, then the complete transaction would need to be rolled back to make sure the data in the database only contains complete transactions.
When a transaction is not written correctly or completely, the database might contain incorrect data and/or incomplete information. There are a number of different situations where a transaction might not be written correctly to the data file. Below are a few of the reasons why data in a database might be inaccurate and not complete:
- Data entered into the system is inaccurate or doesn’t follow data integrity rules.
- The database engine crashes during a critical moment before all updates have been committed to disk in the DATA files.
- A disk system fails, causing only partial information for a transaction to be written to disk.
SQL Server maintains the integrity of the database by following what is known as the ACID principle. The term ACID is just an acronym that stands for Atomicity, Consistency, Isolation, and Durability. These four properties work together to maintain the consistency and integrity of a relational database.
Atomicity
The atomicity property means that a complete transaction will be written to disk, or none of the transaction will be written. It’s the “All or Nothing” approach. A simple example of how atomicity works is in how a bank processes transferring money when a written check is processed. The process of cashing a check requires both a debit and a credit transaction. The debit transaction removes the funds from the checking account on which the check is associated. The credit transaction deposits funds into an account to which the check was written. In order to maintain atomicity, both the credit and debit transaction needs to completed successfully. If either the credit or debit transaction fails for some reason, then the atomicity property ensures that neither transaction is processed. When only part of the transaction is performed, a rollback of all the transactions associated with the check cashing process is performed to maintain atomicity.
Consistency
Consistency property ensures that all data written to the database in a transaction enforces all constraints, triggers, and other database or application rules. If any part of the transaction doesn’t successfully update the database, then the data in the database would not follow the consistency rules, and the transaction would need to be aborted and rolled back to ensure consistency in the data within the database.
The check-cashing process requires both a debit and a credit transaction to occur to be successful. If only the “debit” process of the check cashing process occurs, then only 50% of the transactions would have been completed. Without the credit transaction being processed, all the rules for the check process would not have completed successfully, and the “debit” transaction would need to be backed out to make sure the data in the database didn’t contain incomplete information. The consistency property would ensure that all parts of a transaction are completed successfully, and, if not, partially completed transactions would be rolled back.
Isolation
The isolation property has to do with isolating uncommitted data modification in one transaction from being read or updated by another transaction. The isolation property ensures that a new transaction doesn’t read or update data from a transaction that has not yet been committed.
In the check cashing processing example, the isolation principle makes sure a second banking transaction doesn’t try to access the account in the middle of a check cashing transaction before the transaction has completed successfully. Imagine the financial implications if the funds associated with the check cashing process could be withdrawn prior to the successful completion of a check-cashing process. This might cause an overdraft situation if the check cashing process was rolled back.
SQL Server has several different isolation levels, some that allow more or less isolation than others. To understand more about the different SQL Server isolation levels, you can read this Microsoft documentation.
Durability
The durability property means that the data changes will be permanently made to the database when a transaction has been committed. Having durability means that changes will not disappear should the system crash after the transaction has been successfully committed. By having durability, SQL Server ensures that once the “debit” and the “credit” transaction of the check cashing example have been completed and committed, the changes will stick around, even if the database engine should crash. Without durability, changes might disappear if the system crashes, which would not be a good thing. By using the ACID principles and the information stored in the transaction log the database engine is able to maintain the integrity of information in SQL Server databases.
Transaction log architecture
The transaction log is a sequential file that holds transactions while they are being processed. The architecture of the transaction log has both a logical and physical architecture. The logical architecture described how the transaction works from a logical standpoint. The physical architecture shows how the transaction log is physically implemented and managed by the database engine.
Logical architecture
Logically, the transaction log can be thought of as a sequential file that contains a series of log records that record the different kinds of modifications performed to the database. Each time the database is changed, one or more log records are written to the logical end of the transaction log. The records written either describe the logical operation performed or contain the before and after images of the actual data changes. The before images are copies of the data in the database before it was changed. The after images are the images of the data after the database was modified. The logical operation and the before and after images are not only used to update the database but also to back out a transaction and/or recover the database in the event of a system crash.
Each log record written is identified by a log sequence number (LSN). The LSN identifies the order in which the log records are written to the log. Meaning a log record with an LSN value of 1 would have been written to the log prior to a log record that has an LSN value of 2.
Each of the LSNs associated with a transaction and could be active or inactive. An active LSN is associated with a transaction that has not been committed, whereas an inactive LSN is associated with a transaction that has been committed. The oldest LSN (lowest LSN number) that is active is known as the minimum recovery log sequence number or MinLSN. Figure 1 is a logical representation of the transaction log, where the LSN’s in yellow are the active LSN’s.

Figure 1: Logical Architecture
Physical architecture
Physically the transaction log is made up of one or more transaction log files. The log file is broken up into chunks known as virtual log files (VLF’s). A transaction log might have a few or many VLFs, depending on how big the transaction log is and its growth over time. Each time the transaction log needs to grow, additional VLF’s are created and added to the chain of VLFs. The amount of disk space added to the transaction log for each growth event will determine the number of new VLF’s created.
The transaction log can be considered a circular file, made up by chaining VLF’s together from one VLF to the next. Transaction log records are written from beginning to end, and then wrap back around and start writing at the beginning. The diagram in Figure 2 shows a transaction log with 4 different VLF files, which logically are chained together in a circular fashion. The red dashed line represents how the transaction log records are written from the first VLF to the last and circles back and starts writing at the first VLF again.

Figure 2: Circular log file
The beginning of the circular log file could be any one of the VLFs in the transaction log. When SQL Server hits the end of the sequential log file as it is writing transaction log records, it will circle around and start writing log records at the beginning of the sequential log file, as long as the end of the log file never reaches the logical beginning of the log file, as shown in Figure 3.Figure 2: Circular log file.
If the end of the log file ever reaches the beginning of the log file, then SQL Server will stop writing to the database until some transaction log file records are removed by truncating the log or the physical file is expanded. If all of the VLF’s are active when the end of the log meets the beginning, then the transaction log file will be expanded, and more VLF’s will be created. If some VLF’s are inactive when the end of the log meets the beginning, then the database engine will truncate the log to empty out inactive VLF’s to free up more space for writing transaction log records. Emptying out inactive VLF’s are done automatically when a database is in simple recovery mode, but requires a transaction log back when databases are in full or bulk-logged recovery mode.
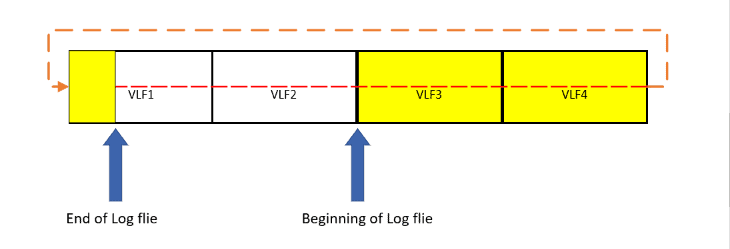
Figure 3; Partially filled transaction log
Log truncation
The log file must be periodically truncated to keep it from filling up. The log truncation process empties VLF files that contain only log records that have already been committed. This emptying out process starts from the VLF at the beginning of the log file until it reaches the VLF that contains the minimum recovery log sequence number (MinLSN). MinLSN is the oldest log record that is needed to successfully rollback the oldest uncommitted transaction. Before the log can be truncated, a checkpoint command needs to be performed. Figure 4 shows how full VLF’s are emptied during the truncation process, and the beginning of the log is reset when VLF’s are cleaned out. Figure 4 shows that the log file starts at VLF3, and the MinLSN is contained in VLF4 prior to the log truncation. When the truncation process occurs, it empties the VLFs that only hold committed log records between the beginning of the log file and the VLF that contains the MinLSN. In my example, VLF3 was emptied, and the beginning of the log file was repositioned at the beginning of VLF4.
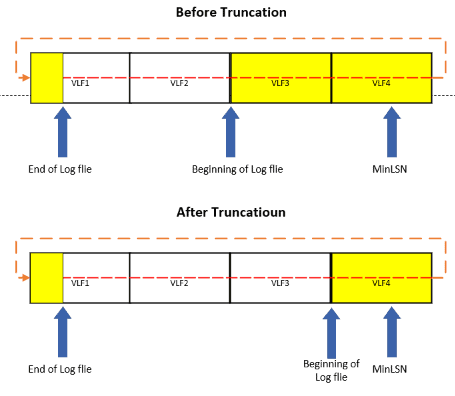
Figure 4: Truncating Transaction Log
The log will be truncated automatically after the following events:
- After a checkpoint when the database is running under simple recovery model.
- After a log back up if full or bulk-logged recovery models are used, provided a checkpoint has been performed since the previous backup (more information about recovery models can be found in my August 2020 article).
What performs a checkpoint?
Changes to the database are first written in-memory to the buffer cache, and for performance reasons, are only committed to disk when a checkpoint operation occurs. When a page has been updated in memory and hasn’t yet been written to disk, it is known as a dirty page. When a checkpoint occurs, dirty pages that only contain committed transactions are written to disk.
Checkpoints can be written automatically, manually, indirectly or internally. Checkpoints are issued automatically when the database engine estimates it has enough transactions that can be written to disk, based on the “Recovery Time Interval” configuration setting. They can also be performed manually by issuing a CHECKPOINT command. If you are running on SQL Server 2012 or higher, indirect checkpoints can be issued. Indirect checkpoints are written based on the number of dirty pages in the log that can be written to disk in a specific period of time, controlled by the “target recovery time” database setting. This setting identifies an upper bound for how long SQL Server should take to recover a database. Checkpoints can be written internally when specific server events occur. The events that cause internal checkpoints are below, as noted in the Microsoft Database Checkpoints:
- Database files have been added or removed by using
ALTER DATABASE. - A database backup is taken.
- A database snapshot is created, whether explicitly or internally for
DBCC CHECKDB. - An activity requiring a database shutdown is performed. For example,
AUTO_CLOSEisONand the last user connection to the database is closed, or a database option change is made that requires a restart of the database. - An instance of SQL Server is stopped by stopping the SQL Server (MSSQLSERVER) service. This action causes a checkpoint in each database in the instance of SQL Server.
- Bringing a SQL Server failover cluster instance (FCI) offline.
SQL Server transaction log architecture
The transaction log is a journal of update activity for a database. SQL Server holds this database update information until they are permanently committed and written to disk. The log is also used to back out incorrect or uncompleted transactions due to application or system issues. It also can be used to roll forward the database to a point-in-time should a recovery be needed. If the transaction log is not managed, it will fill up. To keep the transaction log from filling up, checkpoints and transaction log backups need to be taken periodically. As a DBA, you need to understand the architecture of the transaction log, how to manage the size and growth of the log, and periodically take transaction log backups of databases that are not in simple recovery mode.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments