
A migration script is a T-SQL script that alters a database rather than recreating it. Unlike a build script (which creates a database from scratch) or an automated synchronisation tool (which compares source and target schemas and generates a diff), a migration script is written by hand to handle changes that schema comparison tools cannot infer – primarily table renames, column splits or merges, data type changes with data migration, and bulk data movements. Every migration script should include a guard clause that checks whether the script needs to run before making any changes.
This article explains when to write migration scripts, provides T-SQL guard clause templates for common precondition checks, and includes complete example scripts for the most common manual migration tasks.

DevOps, Continuous Delivery & Database Lifecycle Management
Automated Deployment
What is a Migration Script?
Whereas a build script creates a database, a migration script, or ‘change’ script, alters a database. It is called a migration script because it changes all or part of a database from one version to another. It ‘migrates’ it between versions. This alteration can be as simple as adding or removing a column to a table, or a complex refactoring task such as splitting tables or changing column properties in a way that could affect the data it stores.
For every likely migration path between database versions, we need to store in version control the migration scripts that describe precisely those steps required to perform the change and, if necessary, moving data around and transforming it in the process
Migration scripts are of two types:
- Automated Migration Script – this is a script generated by a synchronization tool such as SQL Compare and normally checked, and perhaps altered, by a developer or DBA.
- Manual Migration Script – this is a script written by a database programmer. Sometimes it is impossible for a tool to create a migration script that will preserve the data in the correct place. Although it knows what the ‘before’ and ‘after’ versions of the database look like, there is sometimes ambiguity regarding the correct transition path. The classic example is that of renaming a table from A to B. We know it’s the same table with a different name, but a tool would likely perform the transition by dropping A, and any data it contains, and creating B. Of course, there are other, more subtle examples where there is not enough evidence in the source and target databases for the tool to be certain of where the data should go without human intervention.
Migration scripts can be forward or “up” migrations that go to a newer version of a database, or backward, or “down” migrations to fall back to a previous version of a database. Any manual migration script is generally used to move between consecutive versions of a database.
A migration script must be idempotent, in that it will have no additional effect if run more than once on the same database. It isn’t wise to change a script once it has been run successfully, and the same set of migration scripts should be run in every server environment where the deployment is taking place.
With this discipline in place, we have a much greater chance of error-free deployments. To bring a database up-to-date, for example, all that is necessary is to run in the correct order the “up” migration scripts that will transform the target database from its current version to the latest version in source control. A ‘build script’ is then merely a special case of a migration script that migrates the database from nowhere to the first version.
It is a good precaution to write integration tests to check that the migration scripts have worked, and it is also essential to be able to roll back to a known version if an error occurs during the build process.
Why some refactoring tasks can’t be automated
Although a synchronization tool can describe most migrations, there are some database changes that can’t be inferred by comparing the beginning and end states of the database, because the tool has insufficient information to know how to migrate the existing data.
Let’s consider a few examples.
Table renaming
A table named People in one database might be named Customers in another. Although they’re the same table and contain the same data, it is impossible to tell whether the two are the same table with any certainty. In assessing the differences between the databases, any automated process will interpret them as two different tables. The People table only exists in the target database, and the Customers table only exists in the source database, and an automatically-generated comparison script would drop the People table and create a new, empty table named Customers. When the script is run, the data in the People table is lost. To get around a great deal of work, it is better to replace this with a manual migration script that does the rename using sp_rename.
Splitting or merging columns
When we split a column, an automated migration script would likely create two or more new columns and drop the original column. Likewise, a column merge would create a new column and drop the original columns.
In either case, any data in the dropped column(s) will be lost.
Instead, we can create a manual migration script to create the new column(s), run custom SQL to move the data, and then drop the original column(s).
Changing the data type or size of a column
When we change a column’s data type (for example, from INT to SMALLINT), data may be truncated during deployment if the new data type doesn’t accommodate some of the rows. Similarly, changes to the size of some columns can result in truncation; for example, VARCHAR(50) to VARCHAR(20). We can create a manual migration script to modify rows appropriately that would otherwise be truncated.
Dealing with large data movements
Regardless of how we generate the migration script, we may not be able to run it “as is” on a large database, especially one that is in production use.
An ALTER statement on a heavily used OLTP table that is being actively updated can have serious repercussions. Any operation, for example, that acquires a schema-modification lock will prevent user access to the table or its metadata during the modification. Alterations to a table are fully logged and so I/O-intensive. If they require table locks, then all other active users of the table will be forced to wait.
Operations such as dropping a column, or adding a NOT NULL column with a default value, can take a long time to complete and will generate many log records.
Just as we might break into smaller batches INSERT, UPDATE, or DELETE statements against large active tables, that affect many rows, so large-scale data migrations in such circumstances are best done incrementally in discrete batches. However this doesn’t apply to metadata. An individual column insertion is a single operation and can’t be broken down and so, to avoid taking the database offline, would require a series of steps involving the creation of a new table, population with data, and a subsequent rename, or ideally a synonym change. This process is usually done with indirection using changes of Synonyms because of their late-binding, or with partition-switching (Enterprise Edition only).
Writing Migration Scripts
Every migration script needs a way to check the preconditions in the environment in which it will run to make sure the script has the right and that it is idempotent, meaning that running it repeatedly will have no further effect. For this purpose, we include in every script a guard clause that will, for example, check to see whether the migration task has already been accomplished before continuing to run it.
We might also write a clause that checks whether the migration script is valid for the version of the target database. For example, if we know that a migration script is intended for version 1.5, we can have the script start by interrogating the current version number of the target database, and aborting if it isn’t “1.5”.
Unfortunately, there is no standard way of attaching a version to a SQL Server Database. The obvious place to store the current version is in the extended properties of the database, but these are not implemented in Windows Azure SQL Database (formerly SQL Azure, SQL Server Data Services, and later SQL Services). Therefore, it is probably safest to store them in a special-purpose table-valued function or view in the target database if your database has to be portable to Azure SQL.
The following sections review some typical IF EXISTS-style guard clauses.
Guard Clauses
Every migration script should include a guard clause that will stop the migration script making changes if it doesn’t need to be run. It is dangerous to assume that a script will only be run in the right preconditions. If you don’t include a guard clause, the migration script might fail or create unexpected changes in the database.
Guard clauses are standard practice for SQL Server scripting. When, for example, developing a stored procedure, one can use CREATE PROCEDURE if the procedure doesn’t exist, or the ALTER PROCEDURE if it does. The former will fail with an error if it already exists, and the latter will fail if it doesn’t. To prevent errors, a guard clause is generally inserted to delete the procedure first if it exists. After that, it is safe to use CREATE PROCEDURE. Since SQL Server 2008, it has been possible to do it a more elegant way that preserves existing permissions on the procedure, having the guard clause run SET NOEXEC ON if the procedure already exists, which then parses, but does not execute the CREATE statement that creates a blank procedure. This avoids deleting an object in a running system, and preserves all the object’s existing attributes when making a change to it. It also gets round the problem of doing a conditional ‘CREATE’ when it must be at the start of a batch. see Listing 1 in ‘Automating SQL Server Database Deployments: Scripting Details’.
In other circumstances, a guard clause can be used to abort a script if it determines that it has already been run, or to perform different logic depending on the database context in which the script is being run. In the following examples, print statements are used to show where the SQL Statements would be.
To check that a table exists
|
1 2 3 4 5 6 7 8 |
-- does a particular table exist IF EXISTS ( SELECT 1 FROM information_schema.Tables WHERE table_schema = 'MySchema' AND TABLE_NAME = 'MyTableName' ) PRINT 'the table exists' ELSE PRINT 'The table isn''t there' |
To check that a function exists
|
1 2 3 4 5 6 7 8 9 |
-- does a particular function exist IF EXISTS ( SELECT 1 FROM information_schema.Routines WHERE ROUTINE_NAME = 'MyFunctionName' AND ROUTINE_TYPE = 'FUNCTION' AND ROUTINE_SCHEMA = 'MySchema' ) PRINT 'the function exists' ELSE PRINT 'The function isn''t there' |
To check that a procedure exists
|
1 2 3 4 5 6 7 8 9 |
-- does a particular procedure exist IF EXISTS ( SELECT 1 FROM information_schema.Routines WHERE ROUTINE_NAME = 'MyProcedureName' AND ROUTINE_TYPE = 'PROCEDURE' AND ROUTINE_SCHEMA = 'MySchema' ) PRINT 'the procedure exists' ELSE PRINT 'The procedure isn''t there' |
To check that a particular column exists in a table exists
|
1 2 3 4 5 6 7 8 9 |
-- does a particular column exist in a table IF EXISTS ( SELECT 1 FROM information_schema.COLUMNS WHERE table_schema = 'MySchema' AND TABLE_NAME = 'MyTableName' AND column_Name = 'MyColumnName' ) PRINT 'the colmun exists' ELSE PRINT 'The column isn''t there' |
To check whether a column has any sort of constraint
|
1 2 3 4 5 6 7 8 |
IF EXISTS ( SELECT 1 FROM information_schema.CONSTRAINT_column_USAGE WHERE table_schema = 'MySchema' AND TABLE_NAME = 'MyTableName' AND column_Name = 'MyColumnName' ) PRINT 'there is a constraint on the column' ELSE PRINT 'no constraint' |
To check that a column has a check constraint
|
1 2 3 4 5 6 7 8 9 |
IF EXISTS ( SELECT 1 FROM information_schema.CONSTRAINT_column_USAGE CCU INNER JOIN information_schema.CHECK_CONSTRAINTS CC ON CC.constraint_name = CCU.constraint_NAME WHERE table_schema = 'MySchema' AND TABLE_NAME = 'MyTableNames' AND column_Name = 'MyColumnName' ) PRINT 'there is a check constraint on the column' ELSE PRINT 'no check constraint' |
To check that a column has a foreign key constraint
|
1 2 3 4 5 6 7 8 9 10 |
--is there a foreign key constraint on the column IF EXISTS ( SELECT 1 FROM information_schema.CONSTRAINT_column_USAGE CCU INNER JOIN information_schema.REFERENTIAL_CONSTRAINTS CC ON CC.constraint_name = CCU.constraint_NAME WHERE table_schema = 'MySchema' AND TABLE_NAME = 'MyTableName' AND column_Name = 'MyColumnName' ) PRINT 'there is a referential constraint on the column' ELSE PRINT 'no referential constraint' |
To check that a column participates in a primary key
|
1 2 3 4 5 6 7 8 9 10 11 |
--is the column (part of ) a primary key? IF EXISTS ( SELECT 1 FROM information_schema.CONSTRAINT_column_USAGE CCU INNER JOIN information_schema.TABLE_CONSTRAINTS CC ON CC.constraint_name = CCU.constraint_NAME WHERE CCU.table_schema = 'MySchema' AND CCU.TABLE_NAME = 'MyTableName' AND column_Name = 'MyColumnName' AND constraint_Type = 'PRIMARY KEY' ) PRINT 'the column is involved in a primary key' ELSE PRINT 'not involved in a primary key' |
Examples of migration scripts
The following section provides typical examples of manual migration scripts for various common database refactoring tasks.
Updating a Stored Procedure
This technique preserves permissions on a routine (procedure or function) whilst doing the update. (SQL 2008 or above only)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
-- does a particular procedure exist IF EXISTS ( SELECT 1 FROM information_schema.Routines WHERE ROUTINE_NAME = 'MyProcedureName'--name of procedire AND ROUTINE_TYPE = 'PROCEDURE'--for a function --'FUNCTION' AND ROUTINE_SCHEMA = 'DBO' ) SET NOEXEC ON GO PRINT 'MyProcedureName: creating a stub' go -- if the routine exists this stub creation stem is parsed but not executed CREATE PROCEDURE MyProcedureName AS Select 'created, but not implemented yet.'--just anything will do GO -- the following section will be always executed SET NOEXEC OFF PRINT 'MyProcedureName: Updating routine code...' GO ALTER PROCEDURE MyProcedureName -- here are all the parameters if needed AS -- here will be all your code Select 'MyProcedureName ... running ...'--just for now! --- go PRINT 'MyProcedureName Routine code updated.' go |
Renaming a table
This migration renames the Person table to Customer. The script includes a guard clause to check that the table Person exists in the database. If the table doesn’t exist, no changes are made.
|
1 2 3 4 5 6 7 8 9 |
--Rename table [dbo].Person to [dbo].Customer IF NOT EXISTS ( SELECT 1 FROM [information_schema].[Tables] WHERE table_schema = 'dbo' AND TABLE_NAME = 'Person' ) PRINT 'Object ''[dbo].[Person]'' could not be found - skipping migration.'; ELSE EXEC sp_rename '[dbo].[Person]', 'Customer' |
Updating a column definition
This migration updates the column definition in the table Widgets with a default value for existing rows before adding a NOT NULL constraint. It includes a guard clause to check that the Widgets table contains a Description column. If the column doesn’t exist, no changes are made.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
--first check that there is a [Description] column IF NOT EXISTS ( SELECT * FROM sys.columns WHERE name LIKE 'description' AND OBJECT_NAME(object_ID) = 'Widgets' AND OBJECT_SCHEMA_NAME(object_ID) = 'dbo' ) BEGIN PRINT 'Column [Description] in [dbo].[Widgets] could not be found - skipping migration.'; RETURN --None of the statements in a batch --following the RETURN statement are executed. END --check to see if the column has already been made NOT NULL IF NOT EXISTS ( SELECT * FROM sys.columns WHERE name LIKE 'description' AND OBJECT_NAME(object_ID) = 'Widgets' AND OBJECT_SCHEMA_NAME(object_ID) = 'dbo' AND is_nullable = 1 ) BEGIN PRINT 'Column [Description] in [dbo].[Widgets] is already not nullable.'; RETURN --None of the statements in a batch --following the RETURN statement are executed. END --we can't do the change if there are any dependencies. --There would be an error IF EXISTS ( SELECT * FROM sys.sql_dependencies WHERE class IN ( 0, 1 ) AND referenced_major_id = OBJECT_ID('widgets') AND COL_NAME( referenced_major_id, referenced_minor_id) = 'Description' ) BEGIN PRINT 'Column [Description] couldn''t be altered because it is being referenced.'; RETURN --None of the statements in a batch --following the RETURN statement are executed. END UPDATE widgets SET Description = 'unknown' WHERE description IS NULL IF NOT EXISTS ( SELECT * FROM sys.columns c INNER JOIN sys.default_constraints d ON c.default_object_id = d.object_id WHERE OBJECT_NAME(c.object_ID) = 'Widgets' AND c.name = 'description' AND OBJECT_SCHEMA_NAME(c.object_ID) = 'dbo' ) ALTER TABLE [dbo].[Widgets] ADD CONSTRAINT WidgetDefault DEFAULT 'unknown' FOR Description; ALTER TABLE [dbo].[Widgets] ALTER COLUMN description VARCHAR(50) NOT NULL |
Splitting a column
In this example, The Customer table has a column Address with the postcode embedded, which means that reports that determine regions based on postcode are difficult.
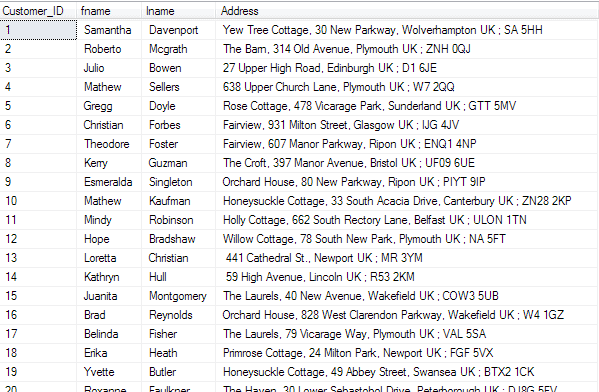
Figure 1: An Address column with embedded postcodes
The manual migration script splits Address into the columns StreetAddress and PostCode, and updates existing rows. Fortunately, the extraction of the postcode is relatively easy since it is separated from the address by a semicolon character ‘;’
The script includes a guard clause to check that the Customer table contains an Address column. If the column doesn’t exist, then no changes are made. If the column does exist, the guard clause checks that the StreetAddress and PostCode columns also exist. If they don’t exist, the script creates the columns before updating the rows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
IF NOT EXISTS ( SELECT * FROM sys.columns WHERE name LIKE 'address' AND OBJECT_NAME(object_ID) = 'customer' AND OBJECT_SCHEMA_NAME(object_ID) = 'dbo' ) BEGIN PRINT 'Column ''address'' in dbo.customer could not be found - skipping migration.'; RETURN --None of the statements in a batch following the RETURN statement are executed. END PRINT N'Address exists' IF NOT EXISTS ( SELECT * FROM sys.columns WHERE name LIKE 'StreetAddress' AND OBJECT_NAME(object_ID) = 'customer' AND OBJECT_SCHEMA_NAME(object_ID) = 'dbo' ) BEGIN PRINT N'Creating StreetAddress' ALTER TABLE [Customer] ADD StreetAddress VARCHAR(100) END ELSE PRINT 'The StreetAddress column already exists' IF NOT EXISTS ( SELECT * FROM sys.columns WHERE name LIKE 'Postcode' AND OBJECT_NAME(object_ID) = 'customer' AND OBJECT_SCHEMA_NAME(object_ID) = 'dbo' ) BEGIN PRINT N'Creating Postcode' ALTER TABLE [Customer] ADD Postcode VARCHAR(20) END ELSE PRINT 'The postcode column already exists' IF EXISTS ( SELECT 1 FROM dbo.customer WHERE streetaddress IS NULL ) EXECUTE sp_executeSQL N' --Split data into columns StreetAddress and PostCode UPDATE customer SET StreetAddress=SUBSTRING(ADDRESS, 0, CHARINDEX('';'', ADDRESS)) UPDATE customer SET Postcode=SUBSTRING(ADDRESS,CHARINDEX('';'', ADDRESS)+1, LEN(Address) )' ELSE PRINT 'this operation has already been completed' |
This would have the following affect when run:
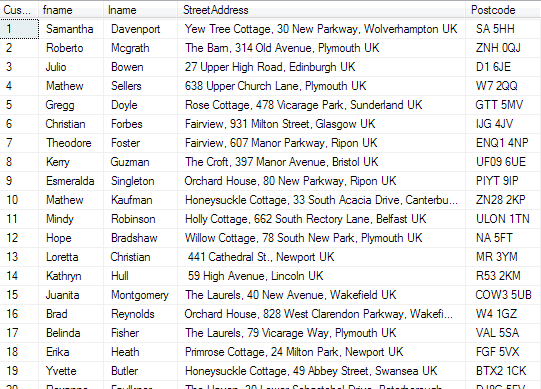
Figure 2: The refactored Customer table
It it was inadvertently run again, the output would be …
|
1 2 3 4 |
Address exists The StreetAddress column already exists The postcode column already exists This operation has already been completed |
Moving Data
In this example, a table, PersonData, has two email columns in it, to try to accommodate the fact that some customers have two email addresses. It needs to be normalized, of course.
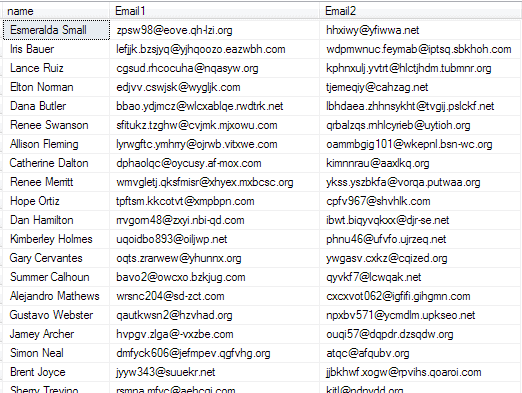
Figure 3: The PersonData table has two email columns
The migration script moves data from the table PersonData to the tables Person and Email. It includes a guard clause to check that the table PersonData exists in the database. If the table doesn’t exist, no changes are made. If the table exists, the guard clause checks that the Person and Email tables exist. If they don’t exist, the script creates the tables before updating the rows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
IF NOT EXISTS ( SELECT 1 FROM Information_Schema.Tables WHERE table_schema = 'dbo' AND TABLE_NAME = 'PersonData' ) BEGIN PRINT 'Table [dbo].[PersonData] could not be found - skipping migration.'; RETURN; END -- Create [dbo].Person if it doesn't exist at the time of deployment IF NOT EXISTS ( SELECT 1 FROM Information_Schema.Tables WHERE table_schema = 'dbo' AND TABLE_NAME = 'Person' ) BEGIN CREATE TABLE Person ( ID INT IDENTITY(1, 1) NOT NULL , NAME NVARCHAR(200) , CONSTRAINT PK_ID PRIMARY KEY ( ID ) ); END -- Create [dbo].Email if it doesn't exist IF NOT EXISTS ( SELECT 1 FROM Information_Schema.Tables WHERE table_schema = 'dbo' AND TABLE_NAME = 'Email' ) BEGIN CREATE TABLE Email ( PersonID INT , Email NVARCHAR(200) CONSTRAINT FK_Person_ID FOREIGN KEY ( PersonID ) REFERENCES Person ( ID ) ); END --Move data from [dbo].PersonData into [dbo].Person SET IDENTITY_INSERT [dbo].Person ON INSERT INTO [dbo].Person ( ID , Name ) SELECT ID , NAME FROM dbo.PersonData SET IDENTITY_INSERT [dbo].Person OFF -- Move data from [dbo].[PersonData] to [dbo].Email INSERT INTO dbo.Email ( PersonID , Email ) SELECT ID , Email1 FROM dbo.PersonData WHERE Email1 IS NOT NULL UNION SELECT ID , Email2 FROM dbo.PersonData WHERE Email2 IS NOT NULL |
Here is the resulting table filled with the email addresses:
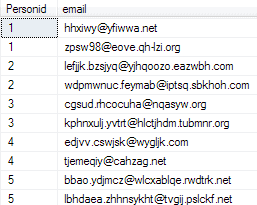
Figure 4: The refactored PersonData table
Table refactoring
Imagine that we have inherited a database that hasn’t been properly normalized and needs refactoring. Data for customers is held in table named PersonData, which also contains all their contact details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE dbo.PersonData ( ID INT IDENTITY(1, 1) , NAME NVARCHAR(200) NOT NULL , Email1 NVARCHAR(200) NULL , Email2 NVARCHAR(200) NULL , Phone1 NVARCHAR(100) NULL , Phone2 NVARCHAR(100) NULL , Street1 NVARCHAR(200) NULL , City1 NVARCHAR(200) NULL , StateProvince1 NVARCHAR(50) NULL , PostalCode1 NVARCHAR(50) NULL , Street2 NVARCHAR(200) NULL , City2 NVARCHAR(200) NULL , StateProvince2 NVARCHAR(50) NULL , PostalCode2 NVARCHAR(50) NULL , CONSTRAINT PK_PersonDataID PRIMARY KEY ( ID ) ); |
To normalize the table, we’ll break it into different tables in a new schema named Contacts:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
IF SCHEMA_ID('contacts') IS NULL EXEC sp_executeSQL N'CREATE SCHEMA Contacts' IF OBJECT_ID('Contacts.Person', 'U') IS NULL CREATE TABLE Contacts.Person ( ID INT IDENTITY PRIMARY KEY , NAME NVARCHAR(200) NOT NULL, ); IF OBJECT_ID('Contacts.Email', 'U') IS NULL CREATE TABLE Contacts.Email ( EmailID INT IDENTITY PRIMARY KEY , PersonID INT NOT NULL REFERENCES Contacts.Person , Email NVARCHAR(200) NOT NULL ); IF OBJECT_ID('Contacts.Phone', 'U') IS NULL CREATE TABLE Contacts.Phone ( PhoneID INT IDENTITY PRIMARY KEY , PersonID INT NOT NULL REFERENCES Contacts.Person , Phone NVARCHAR(100) NOT NULL ); IF OBJECT_ID('Contacts.PostAddress', 'U') IS NULL CREATE TABLE Contacts.PostAddress ( PostAddressID INT IDENTITY PRIMARY KEY , PersonID INT NOT NULL REFERENCES Contacts.Person , Street NVARCHAR(200) NULL , City NVARCHAR(200) NULL , StateProvince NVARCHAR(50) NULL , PostalCode NVARCHAR(50) NULL ); IF NOT EXISTS ( SELECT 1 FROM Contacts.Person ) BEGIN SET IDENTITY_INSERT Contacts.Person ON INSERT INTO Contacts.Person ( ID , Name ) SELECT ID , NAME FROM dbo.PersonData SET IDENTITY_INSERT [Contacts].Person OFF END |
We now want to migrate Email1 and Email2 from PersonData into Contacts.Email, creating two separate rows for a person having both Email1 and Email2. Similarly, we migrate the phone and address details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
--Move data from dbo.PersonData into [Contacts].Email IF NOT EXISTS ( SELECT 1 FROM Contacts.Email ) INSERT INTO Contacts.Email ( PersonID , Email ) SELECT ID , Email1 FROM dbo.PersonData WHERE Email1 IS NOT NULL UNION SELECT ID , Email2 FROM dbo.PersonData WHERE Email2 IS NOT NULL -- To migrate Phone1 and Phone2 from dbo.PersonData into [Contacts].Phone: -- Move data from dbo.PersonData into [Contacts].Phone IF NOT EXISTS ( SELECT 1 FROM Contacts.Phone ) INSERT INTO Contacts.Phone ( PersonID , Phone ) SELECT ID , Phone1 FROM dbo.PersonData WHERE Phone1 IS NOT NULL UNION SELECT ID , Phone2 FROM dbo.PersonData WHERE Phone2 IS NOT NULL -- To migrate address details from dbo.PersonData to [Contacts].PostAddress: --Move data from dbo.PersonData into [Contacts].PostAddress IF NOT EXISTS ( SELECT 1 FROM Contacts.PostAddress ) INSERT INTO Contacts.PostAddress ( PersonID , Street , City , StateProvince , PostalCode ) SELECT ID , Street1 , City1 , StateProvince1 , PostalCode1 FROM dbo.PersonData UNION SELECT ID , Street2 , City2 , StateProvince2 , PostalCode2 FROM dbo.PersonData |
After running the migration script, we can drop the original PersonData table as a separate commit.
Conclusions
Although much of the chore of synchronizing databases for a deployment can be done using a tool such as SQL Compare, there are times when a step has to be done by hand, either because it is a large table, or it isn’t unambiguously obvious how the existing data should be placed in the target revision of the database, in such a way as to be sure of preserving it.
For the automated deployment of databases, hand-crafted SQL migration scripts will occasionally have a place, and will be stored in version control to run before any automated process for deploying changes to the database. They should be written so that, if it is run at the wrong time, or run repeatedly, it will have no effect. Guard Clauses are a good way of ensuring that Murphy’s law will have no consequences.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
FAQs: Using Migration Scripts in Database Deployments
1. What is a database migration script?
A database migration (or change) script is a T-SQL script that alters an existing database – adding columns, renaming tables, migrating data, or modifying constraints – as opposed to a build script that creates a database from scratch. Migration scripts are needed when a schema comparison tool cannot infer the intended change from comparing two database states (for example, a table rename could be interpreted as ‘drop old table + create new table’, losing all data). For these cases, a human-written migration script that explicitly specifies the operation is required.
2. What is a guard clause in a SQL Server migration script?
A guard clause is a precondition check at the top of a migration script that prevents it from running if the expected preconditions are not met – for example, checking that the table being renamed actually exists before renaming it. Guard clauses prevent the script from applying changes it has already applied (idempotency), from failing with an ambiguous error on a database in a different state, and from running in the wrong environment. A typical guard clause uses IF EXISTS / IF NOT EXISTS to check for the presence or absence of a database object before the migration code executes.
3. What database changes require a manual migration script?
Table renames (a tool cannot tell if the new table is the same as the old one, or a new table), column splits (splitting one column into two new columns with data migration logic), column merges (the reverse), data type changes that require custom conversion logic (e.g., VARCHAR to INT with validation), and bulk data migrations between tables. Schema comparison tools can generate scripts for simple operations like adding a column or changing a default, but any operation that requires business logic to preserve or transform data needs a manual migration script.
4. How do I deploy a migration script across multiple SQL Server instances?
Use SQL Server Management Studio’s Central Management Server feature to run the migration script across all registered servers in a group simultaneously, or use PowerShell with the SqlServer module to iterate over a server list and call Invoke-Sqlcmd for each. For automated deployments in CI/CD pipelines, tools like Redgate SQL Change Automation, Flyway, or Liquibase apply migration scripts in version order against target environments, ensuring scripts run exactly once per database.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments