
First of all, a warning:
Much of what you will see here is ‘undocumented’. That means we can discuss it, but you can’t trust that this will not change in a service pack or a new product release. Also you will not be able to call Microsoft support for help or advice on the topic, or if you get an error when using the following techniques. Use with precaution and with extra attention.
Introduction
A very common problem relating to distribution statistics is associated with what we call “ascending value columns” in a table. This generally happens when a large table has ascending values and the most recent rows are the ones most commonly being accessed. When data values in a column ascend, most new insertions are beyond the range covered by the distribution statistics. This can lead to poorly performing plans since they inaccurately predict from the statistics that filters selecting recent data would exclude the entire relation.
As we already know, a column which belongs to a statistic has to get to a threshold quantity of modifications after the previous update in order to trigger the auto-updated statistics, and for certain cases, this threshold is too high. In other words, a column table requires too many modifications before the distribution statistics are rebuilt.
This delay in auto-updating a statistic can be a problem for queries that are querying the newest data in the table. That is very likely to happen when we are using date or identity columns. As you know, the use of an outdated statistic can be very bad for performance because SQL Server will not be able to estimate precisely the number of rows a table will return, and is likely to use a poor execution plan.
To simulate this problem I’ll start by creating a table called Pedidos (which means Orders in Portuguese) and I’ll make the identity column a primary key.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
USE Tempdb GO SET NOCOUNT ON; GO IF OBJECT_ID('Pedidos') IS NOT NULL DROP TABLE [Pedidos] GO CREATE TABLE [dbo].[Pedidos] ( [ID_Pedido] [int] IDENTITY(1, 1) NOT NULL, [ID_Cliente] [int] NOT NULL, [Data_Pedido] Date NOT NULL, [Valor] [numeric](18, 2) NOT NULL, CONSTRAINT [xpk_Pedidos] PRIMARY KEY CLUSTERED(ID_Pedido) ) GO CREATE INDEX ix_Data_Pedido ON Pedidos(Data_Pedido) GO INSERT INTO Pedidos (ID_Cliente, Data_Pedido, Valor) SELECT ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), '18000101', ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))) GO -- Inserting 50000 rows in the table INSERT INTO Pedidos WITH(TABLOCK) (ID_Cliente, Data_Pedido, Valor) SELECT ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), (SELECT DATEADD(d, 1, MAX(Data_Pedido)) FROM Pedidos), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))) GO 50000 SELECT * FROM Pedidos GO |
Here is what the data looks like:

As you can see the orders are added sequentially and that’s what usually happens with this sort of table. The date_order (column data_pedido) is the date of the order.
Now let’s suppose a query that is searching for the orders of the day will look like the following:
|
1 2 3 4 5 |
SET STATISTICS IO ON SELECT * FROM Pedidos WHERE Data_Pedido >= Convert(date, GetDate()) OPTION (RECOMPILE) SET STATISTICS IO OFF |
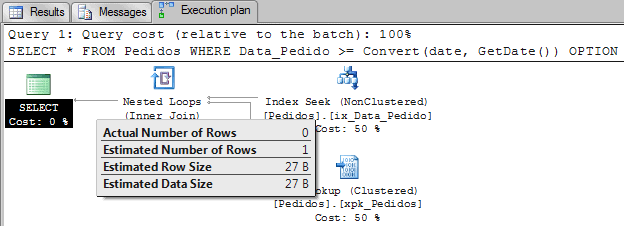
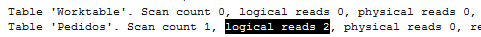
In the beginning of the day SQL Server can estimate that 0 (even it shows 1 on the plan, it is estimating 0) rows will be returned. But what will happen in the end of the day when thousands of orders were inserted?
It’s likely that an execution plan using the Key Lookup will not be a good option since the lookup operation will demand a lot of pages to be read.
Let’s simulate the problem by inserting 5001 new orders in the table. Because this is below the autoupdate threshold it will not trigger the auto-updated statistics.
|
1 2 3 4 5 6 7 8 9 10 |
INSERT INTO Pedidos WITH(TABLOCK) (ID_Cliente, Data_Pedido, Valor) SELECT ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), GetDate(), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))) GO INSERT INTO Pedidos (ID_Cliente, Data_Pedido, Valor) VALUES (ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), (SELECT DateAdd(d, 1, MAX(Data_Pedido)) FROM Pedidos), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5)))) GO 5000 |
Now the table has lots of new orders, and each order was inserted in ascending order. That means the column Data_Pedido is increasing.
Let’s run the same query and check how many pages SQL Server has to read to execute this plan.
|
1 2 3 4 5 6 |
SET STATISTICS IO ON SELECT * FROM Pedidos WHERE Data_Pedido >= Convert(date, GetDate()) OPTION (RECOMPILE) SET STATISTICS IO OFF GO |
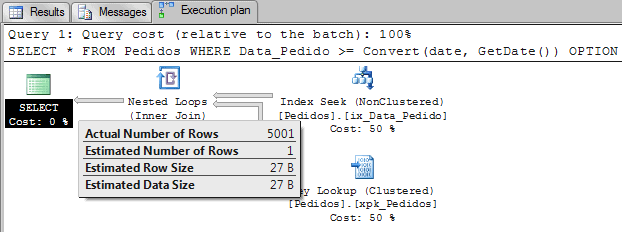
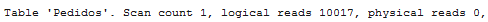
Note: Notice that I’m using the hint RECOMPILE to avoid query plan reuse. Also the auto create and auto update statistics are enabled on the tempdb database.
We can see here that the estimation of how many rows will be returned is very wrong. The 5001 insertions were not enough to trigger the auto-updated statistics, and the query optimizer still thinks that the table has no orders greater than GetDate().
What if we force a scan on the base table?
|
1 2 3 4 5 |
SET STATISTICS IO ON SELECT * FROM Pedidos WITH(FORCESCAN, INDEX(0)) WHERE Data_Pedido >= Convert(date, GetDate()) OPTION (RECOMPILE) SET STATISTICS IO OFF |
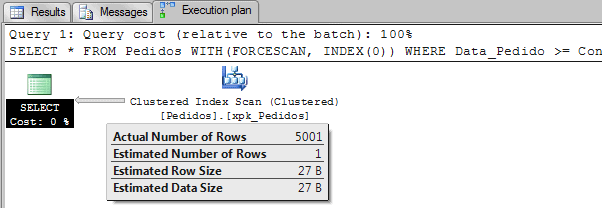

Note: The hint FORCESCAN is new on SQL Server 2008 R2 SP1. You can read more this hint http://technet.microsoft.com/en-us/library/ms187373.aspx.
As we can see, a scan on the clustered index requires much fewer page-reads, 200 pages on clustered index versus 10017 on the non-clustered one, plus the lookup on the clustered index.
The estimate is still wrong because the statistics are outdated and therefore don’t represent the reality of what is in the table.
Branding
SQL Server can detect when the leading column of a statistics object is ascending and can mark or “brand” it as ascending. A statistics object that belongs to an ascending column is branded as “ascending” after three updates on the statistics. It’s necessary to update it with ascending column values so that when the third update occurs, SQL Server brands the statistics object as ascending.
It’s possible to check the statistics’ brand using the trace flag 2388, when turned on it changes the result of the DBCC SHOW_STATISTICS, and then we can see a column called “Leading column type” with the brand of the column.
For instance:
|
1 2 3 4 5 6 7 8 9 |
-- Enable trace flag 2388 DBCC TRACEON(2388) GO -- Look at the branding DBCC SHOW_STATISTICS (Pedidos, [ix_Data_Pedido]) GO -- Disable trace flag 2388 DBCC TRACEOFF(2388) GO |

As we can see, the column now is “Unknown”. Let’s insert 10 rows with ascending orders and update the statistics to see what will happen.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- Insert 10 rows INSERT INTO Pedidos (ID_Cliente, Data_Pedido, Valor) VALUES (ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), (SELECT DateAdd(d, 1, MAX(Data_Pedido)) FROM Pedidos), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5)))) GO 10 -- Update statistics UPDATE STATISTICS Pedidos [ix_Data_Pedido] WITH FULLSCAN GO DBCC TRACEON(2388) DBCC SHOW_STATISTICS (Pedidos, [ix_Data_Pedido]) DBCC TRACEOFF(2388) |

As I said before, the statistics have to be updated three times to be branded as ascending, so let’s do it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- Insert 10 rows INSERT INTO Pedidos (ID_Cliente, Data_Pedido, Valor) VALUES (ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), (SELECT DateAdd(d, 1, MAX(Data_Pedido)) FROM Pedidos), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5)))) GO 10 -- Update statistics UPDATE STATISTICS Pedidos [ix_Data_Pedido] WITH FULLSCAN GO -- Insert 10 rows INSERT INTO Pedidos (ID_Cliente, Data_Pedido, Valor) VALUES (ABS(CONVERT(Int, (CheckSUM(NEWID()) / 10000000))), (SELECT DateAdd(d, 1, MAX(Data_Pedido)) FROM Pedidos), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5)))) GO 10 -- Update statistics UPDATE STATISTICS Pedidos [ix_Data_Pedido] WITH FULLSCAN GO DBCC TRACEON(2388) DBCC SHOW_STATISTICS (Pedidos, [ix_Data_Pedido]) DBCC TRACEOFF(2388) |

Trace Flags 2389 and 2390
By default, the query optimizer keeps the information about the branding of statistics, but doesn’t make use of it. The optimizer won’t choose a different plan based on whether the column is ascending or not. To change this, you need to use the trace flags 2389 or 2390.
When the trace flag 2389 is enabled, the statistics are ascending and you have a covered index on the ascending leading key of the statistic, then the query optimizer will query the table to compute the highest value of the column. This value is then used in the estimation of how many rows will be returned for the predicate.
The trace flag 2390 works similarly to flag 2389, the main difference being that, with this flag set, the query optimizer doesn’t care if the column was branded as ascending or not. In other words, even if the column is marked as “Unknown” it will query the table to find the highest value.
To see this in practice we’ll use an undocumented query hint called QUERYTRACEON. With this query hint we can enable a trace flag in a statement scope.
Here we have a command that is using the trace flags 2389 and 2390:
|
1 2 3 4 5 6 |
SET STATISTICS IO ON SELECT * FROM Pedidos WHERE Data_Pedido >= Convert(date, GetDate()) OPTION(QUERYTRACEON 2389, QUERYTRACEON 2390, RECOMPILE) SET STATISTICS IO OFF GO |
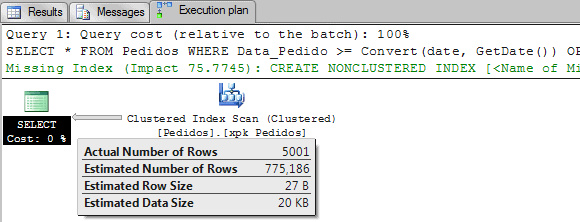
SQL Server, we can see, now has a new estimation and it was enough to avoid the bad plan that was using the key lookup.
Note: Internally QUERYTRACEON will run DBCC TRACEON command and you’ll need a sysadmin privilege to run this hint. A good alternative is to use a stored procedure and run it as an administrator user.
Note: There is another brand for a statistics object called “Stationary”. The query optimizer will not trigger the query on the table to compute the value if the brand is stationary. In other words, the data in the leading column(s) is not ascending.
Conclusion
Remember that this is just an alternative way to fix a problem that is seen with large tables with ascending columns. The best option is to update your statistics periodically. In this case, it’s just a matter of creating a job to update the statistics more frequently for the tables with ascending columns up to several times a day, there is no fixed number of updates per day here, you’ll need to figure out which is the appropriate number of updates necessary for your scenario. You also have query hints, plan guides and other alternatives to fix this problem.
Here are some questions I asked myself when I first read about these trace flags.
Are trace flags always good?
Probably not, you have to find the scenario where to test them, and test, test, test.
Will SQL Server always query the table to find the highest value on in the column?
Not always. It depends on the predicate and how you are querying the table.
Can I use the trace flag 2389 alone?
Yes, but it will work only for columns branded as ascending.
Can I use the trace flag 2390 alone?
You can, but it doesn’t make sense to do so because it will stop working when the column turns out to be ascending.
As with everything, you need to test it before you use it and it always depends on the scenario. It’s also worth mentioning that this method is not supported; so don’t call Microsoft if you have any doubts about this, or me either, come to think of it.
That’s all folks, see you.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments