
This article shows how to export SQL Server query results and configuration data as YAML documents using PowerShell and SQL Server Management Objects (SMO). YAML is well-suited to hierarchical document content – human-readable, diff-friendly, and deeply nestable – which makes it practical for configuration snapshots, query-result capture with embedded sub-structures (XML columns, spatial types), and source-control-friendly object inventories.
Table of contents
Before we get started…
DBAs are often faced with having to create, maintain or inspect documents that contain hierarchical data and information. Sometimes, hierarchical information has even been shoehorned into a table or two, but at other times it happens for no better reason than the culture behind SMO and SSMS. SMO is resolute in recording SQL Server’s information an object-oriented hierarchical way, even though it is, within any relational database, entirely based on relational tabular data and Metadata. Codd insists on it.
The grey-muzzle DBA will, of course, have secure tricks for saving the more familiar tabular information, all the way from CSV to SQLite. Most of us, however, scratch our heads when faced with XML or JSON. The former is mark-up, tricky to inspect and over-ambitious in scope; the second is a subset of JavaScript, and inadequate for specifying data types in sufficient detail. My well-thumbed copy of ‘XML in a Nutshell’ runs to 680 pages. YAML is more intuitive to use, though: Although it is a superset of JSON, you can jettison those brackets and use an intuitive style that has been used for representing hierarchical information since before computers. A good YAML Deserializer will deal with JSON as well as YAML and output JSON dialect if you choose.
Yes, YAML is equally readable and updateable by either machines or humans. YAML has been slow to gain traction because it has never had a human-oriented textbook or adequate training materials. The extremely clever people who devised it weren’t natural communicators.
In celebration of the introduction of PSYaml, I want to demonstrate how you’d use YAML with PowerShell for recording server information or recording results that are easy to read into applications. (.NET developers will find it even easier because they can use Antoine Aubry’s excellent YamlDotNet library directly). We’ll start simply.
Following Along
To follow along, you’ll need my PSYaml module. I’ve tried to make it self-installing and you’ll see it described here.
Getting Query Results from a Server in a Hierarchical Way
Simple queries with metadata
Let’s start with a simple PowerShell function that executes a query that returns a result. It not only records the data in a way that makes it easy to inspect, but also records when and where you executed the query and lists the table columns you’d need to store the data.
|
1 2 3 4 |
ConvertTo-YAML ( Get-QueryResult 'Select top 2 * from person.address' ` 'YourInstance' ` 'Adventureworks2014') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
--- Query: 'Select top 2 * from person.address' Database: 'Adventureworks2014' Instance: ‘MyBigFatServer’ Schema: - 'AddressID int IDENTITY' - 'AddressLine1 nvarchar (60) ' - 'AddressLine2 nvarchar (60) NULL' - 'City nvarchar (30) ' - 'StateProvinceID int ' - 'PostalCode nvarchar (15) ' - 'SpatialLocation AdventureWorks2014.sys.geography NULL' - 'rowguid uniqueidentifier ' - 'ModifiedDate datetime ' Date: 2016-09-30T11:59:58 Data: - - 1 - '1970 Napa Ct.' - null - 'Bothell' - 79 - '98011' - IsNull: 'False' Lat: '47.7869921906598' Long: '-122.164644615406' M: 'Null' STSrid: '4326' Z: 'Null' - '9aadcb0d-36cf-483f-84d8-585c2d4ec6e9' - 2007-12-04T00:00:00 - - 2 - '9833 Mt. Dias Blv.' - null - 'Bothell' - 79 - '98011' - IsNull: 'False' Lat: '47.6867097047995' Long: '-122.250185528911' M: 'Null' STSrid: '4326' Z: 'Null' - '32a54b9e-e034-4bfb-b573-a71cde60d8c0' - 2008-11-30T00:00:00 |
The indentation represents the nesting level. The number of spaces used at any level isn’t significant as long as the left margin lines up. The ‘-‘ sign within the left margin means that your data is a list item. Most collections of data are list items or key:value pairs. The latter are represented by the key being followed by a colon’:’ followed by a value.
You’ll notice that we are mixing up lists and ordered hash tables. In YAML, you can represent collections of data as:
- maps, which are unordered set of key: value pairs without duplicates.
- omaps (ordered maps) that are ordered sequences of key: value pairs without duplicates.
- pairs: which are ordered sequence of key: value pairs allowing duplicates.
- sets which are unordered set of non-equal values.
- seqs (Sequences) consisting of a sequence of arbitrary values.
Generally, our data consists of structures of omaps and seqs. JSON has unordered sets of name/value pairs without duplicates (maps) and arrays, which are ordered collections of values, equivalent to a seq. The YAML documentation and reference card will show how to represent the other types.
We’re giving you the SQL column names at the top of the list and then providing each row as an ordered list. This is a compact way of storing longer results.
One problem with this rendering is that it is done in a style that is economical on space. Because I know the column headings, I’m doing each row as a simple list, as if it were CSV. You might something that is easier to read.
If I do this
|
1 2 3 4 |
ConvertTo-YAML ( Get-QueryResult 'Select top 2 * from person.address' ` 'MyBigFatServer' ` 'Adventureworks2014' doAsList $false ) |
Then I get each row looking like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- AddressID: 2 AddressLine1: '9833 Mt. Dias Blv.' AddressLine2: null City: 'Bothell' StateProvinceID: 79 PostalCode: '98011' SpatialLocation: IsNull: 'False' Lat: '47.6867097047995' Long: '-122.250185528911' M: 'Null' STSrid: '4326' Z: 'Null' rowguid: '32a54b9e-e034-4bfb-b573-a71cde60d8c0' ModifiedDate: 2008-11-30T00:00:00 |
Whichever way you do it, you’ll notice in the full listing that the columns in the ‘schema’ section at the top get a datatype as well as the column name. Here is the extract.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--- Query: 'Select top 2 * from person.address' Database: 'Adventureworks2014' Instance: 'MyBigFatServer' Schema: - 'AddressID int IDENTITY' - 'AddressLine1 nvarchar (60) ' - 'AddressLine2 nvarchar (60) NULL' - 'City nvarchar (30) ' - 'StateProvinceID int ' - 'PostalCode nvarchar (15) ' - 'SpatialLocation AdventureWorks2014.sys.geography NULL' - 'rowguid uniqueidentifier ' - 'ModifiedDate datetime ' |
That suits me fine. With any structured document you can add all sorts of detail that are impossible with a tabular representation such as CSV. We tend to get around this with comments or descriptive filenames when there is no other way, but that boxes you in when you are doing automation work, so it is definitely a bonus to have this feature.
YAML isn’t alone in giving you this luxury. You can, of course use JSON or XML, Python or PowerShell. Here we’ll show JSON. Here is just one record.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
{ "Query": "Select top 2 * from person.address", "Database": "Adventureworks2014", "Instance": ‘MyBigFatServer’, "Schema": [ "AddressID int IDENTITY", "AddressLine1 nvarchar (60) ", "AddressLine2 nvarchar (60) NULL", "City nvarchar (30) ", "StateProvinceID int ", "PostalCode nvarchar (15) ", "SpatialLocation AdventureWorks2014.sys.geography NULL", "rowguid uniqueidentifier ", "ModifiedDate datetime " ], "Date": "2016-09-30T11:59:58", "Data": [ 1, "1970 Napa Ct.", "", "Bothell", 79, 98011, { "IsNull": false, "Lat": 47.7869921906598, "Long": -122.164644615406, "M": "Null", "STSrid": 4326, "Z": "Null" }, "9aadcb0d-36cf-483f-84d8-585c2d4ec6e9", "2007-12-04T00:00:00" ] } |
This can, incidentally, be deserialized successfully with ConvertFrom-YAML, so you get the choice of either style.
Fast, reliable and consistent SQL Server development…
Queries that return XML columns
You’ll notice that .NET’s provider split your SpatialLocation up into its components. With ConvertTo-YAML, we can do the same for XML columns too if you want.
|
1 2 3 4 |
ConvertTo-YAML ( Get-QueryResult 'Select top 1 * from [HumanResources].[JobCandidate] ' ` 'YourInstance' ` 'Adventureworks2014' ) |
Yes, you don’t see the XML, but a proper hierarchical rendering of the data. This is because the YAML converter is set to unwrap XMLDocuments as if they were objects. You can change that behaviour, of course if you wish to preserve the XML document. (I only show a bit of this YAML document)
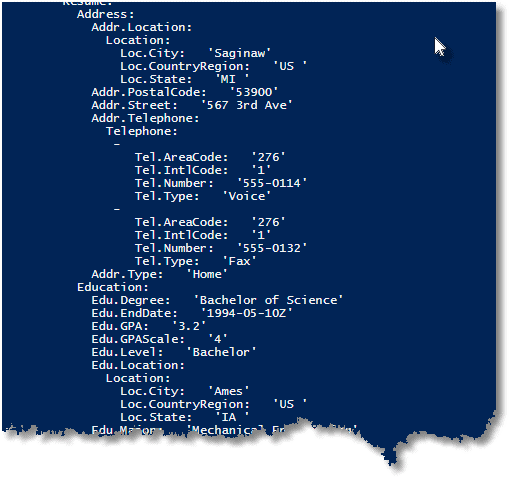
If you are still wondering why anyone would find this useful, try running the same queries in SSMS just to see how informative the result pane is in comparison.
So, what does the query plan look like in YAML? Well, it isn’t exactly pretty, but it is a lot easier to scan by eye.
Just a sample here, of course. You’ll have to try it out to see more.
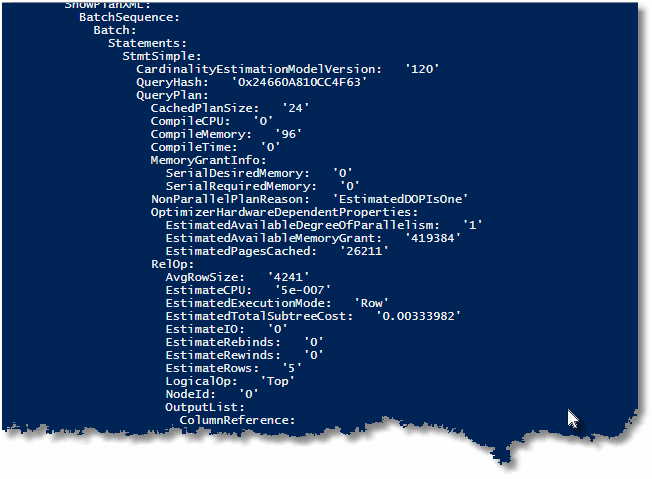
Here is the PowerShell code to get the top five slow-running queries from which I took that excerpt, and produce a YAML document from them, including the SQL and the execution plan.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
ConvertTo-YAML ( Get-QueryResult @" SELECT st.text, qp.query_plan FROM ( SELECT TOP 3 dm_exec_query_stats.sql_handle, dm_exec_query_stats.plan_handle FROM sys.dm_exec_query_stats WHERE ( dm_exec_query_stats.max_worker_time > 300 OR dm_exec_query_stats.max_elapsed_time > 300 ) ORDER BY dm_exec_query_stats.total_worker_time DESC ) AS qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp; "@ 'YourInstance' ` 'Adventureworks2014' ) |
Normally, you’d want to do a xpath query to just get the nodes you really want because there is a lot of clutter in an XML query plan.
You can, of course, easily create an XML hierarchical result that was created with the FOR XML PATH syntax. The only stricture is that you must supply a ROOT. You must also coerce it into an XML datatype as it is otherwise sent as ntext and can’t easily be recognised as XML.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
ConvertTo-YAML -verbose ( Get-QueryResult @" SELECT CONVERT( XML,(SELECT emp.NationalIDNumber AS [Employee/@ID], per.FirstName AS [Employee/Name/First], per.MiddleName AS [Employee/Name/Middle], per.LastName AS [Employee/Name/Surname], COALESCE(per.Title+ ' ','')+per.FirstName+' '+COALESCE(per.MiddleName+ ' ','') + per.LastName+ COALESCE(' '+per.Suffix,'') AS [Employee/Name/Full], emp.BirthDate AS [Employee/Personal/DOB], emp.Gender AS [Employee/Personal/Gender], emp.MaritalStatus AS [Employee/Personal/Married], emp.JobTitle AS [Employee/CurrentYear/Job_Title], emp.VacationHours AS [Employee/CurrentYear/Vacation_hours], emp.SickLeaveHours AS [Employee/CurrentYear/SickLeave_Hours], emp.CurrentFlag AS [Employee/CurrentYear/Current] FROM HumanResources.Employee emp INNER JOIN Person.Person per ON emp.BusinessEntityID = per.BusinessEntityID WHERE emp.BusinessEntityID IN ( 4,18,115) FOR XML PATH,ROOT('EmployeeList'), ELEMENTS XSINIL)) AS Top_Employees; "@ 'MyBigFatInstance' ` 'Adventureworks2014' ) |
Which gives.. (just an extract again )
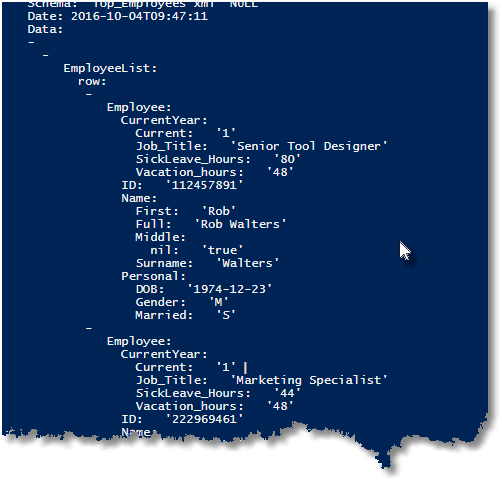
The function that gave these results, Get-QueryResults, is this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
function Get-QueryResult {<# .SYNOPSIS Returns a powershell object that records the date it was executed, on what instance and database. It also records the nature of each column returned in SQL .DESCRIPTION This is designed to be used in conjunction with ConvertTo-YAML or ConvertTo-XML to save a query in such a way that the rows can be read and there is a full record of where and when the expression was executed. Don't try to use this for large queries where you should be using BCP. This is intended for reports and diagnostic queries that need to be saved to file or inspected. .EXAMPLE ConvertTo-YAML ( Get-QueryResult 'Select top 5 * from person.address' ` 'YourInstance' ` 'Adventureworks') ConvertTo-YAML ( Get-QueryResult 'Select top 2 * from person.address' ` 'YourInstance' ` 'Adventureworks2014' doAsList $false ) .PARAMETER SQL The SQL Expression that you want scripted out .PARAMETER Sourceinstance The SQL Server instance you want to use .PARAMETER Sourcedatabase The source database (master if you don't care) .PARAMETER Credentials internal use only. required for formatting #> [CmdletBinding()] param ( |
[parameter(Position = 0, Mandatory = $true, ValueFromPipeline = $true)]
[string]$sql, #the valid SQL Expression that you want to execute
[parameter(Position = 1, Mandatory = $true, ValueFromPipeline = $false)]
[string]$Sourceinstance, #the full name of the instance
[parameter(Position = 2, Mandatory = $false, ValueFromPipeline = $false)]
[string]$Sourcedatabase = ‘master’, # e.g. Adventureworks
[parameter(Position = 3, Mandatory = $false, ValueFromPipeline = $false)]
[string]$Credentials = ‘integrated security=True’,
[parameter(Position = 4, Mandatory = $false, ValueFromPipeline = $false)]
[int]$doAsList = $true ) $Credentials = ‘integrated security=True’ #uid and password if SQL Server $SourceConnectionString = “Data Source=$Sourceinstance;Initial Catalog=$Sourcedatabase;$credentials” $sourceConnection = New-Object System.Data.SqlClient.SQLConnection($SourceConnectionString) $sourceConnection.open() $commandSourceData = New-Object system.Data.SqlClient.SqlCommand($sql, $sourceConnection) $reader = $commandSourceData.ExecuteReader() $Counter = $Reader.FieldCount $schemaTable = $reader.GetSchemaTable(); $ResultSchema = $schemaTable.Rows | foreach-object { “$($_.ColumnName) $($_.DataTypeName) $( if ($_.DataTypeName -in (‘char’, ‘varchar’, ‘nchar’, ‘nvarchar’)) { if ($_.IsLong -eq $true) { ‘(MAX)’ } else { ‘(‘ + $_.ColumnSize + ‘)’ } } elseif ($_.DataTypeName -in (‘decimal’, ‘numeric’)) { ‘(‘ + $_.NumericPrecision + ‘, ‘ + $_.NumericScale + ‘)’ } ) $( if ($_.IsIdentity -eq $true) { ‘IDENTITY’ } else { ” } )$( if ($_.AllowDBNull -eq $true) { ‘NULL’ })” } $Rows = @() #the array of arrays that will store our result while ($Reader.Read()) # read the next row until done { if ($doAsList -eq $true) { $tuple = @() #do this row-by-row for ($i = 0; $i -lt $Counter; $i++) #for each column { write-verbose $schemaTable.Rows[$i].DataTypeName if ($Reader.IsDBNull($i) -eq $true) { $tuple += $null } elseif ($Reader.GetFieldType($i).Name -eq ‘DateTime’) { $tuple += $Reader.GetDateTime($i) } elseif ($schemaTable.Rows[$i].DataTypeName -eq ‘xml’) { $tuple += [xml]$Reader.GetValue($i) } elseif ($Reader.GetFieldType($i).Name -eq ‘Byte[]’) { $tuple += ,$Reader.GetValue($i) } else { $tuple += $Reader.GetValue($i) }; } $rows += ,$tuple } else { $tuple = [ordered]@{ } #do this row-by-row for ($i = 0; $i -lt $Counter; $i++) #for each column { $tuple.”$($Reader.GetName($i))” = &{ if ($Reader.GetFieldType($i).Name -eq ‘DateTime’) {$Reader.GetDateTime($i)} elseif ($schemaTable.Rows[$i].DataTypeName -eq ‘xml’) {[xml]$Reader.GetValue($i)} elseif ($Reader.IsDBNull($i) -eq $true) {$null} elseif ($Reader.GetFieldType($i).Name -eq ‘Byte[]’) {$Reader.GetValue($i) } else { $Reader.GetValue($i) } }; } $rows += $tuple } } [ordered]@{ Query = $sql; Database = $Sourcedatabase; Instance = $SourceInstance; Schema = $ResultSchema; Date = Get-date; Data = $rows; } }
Using SMO
Saving Endpoint Configuration Settings
Let’s now go to a slightly different task, recording configuration data. Endpoints, for example, can cause a problem, especially if you have a fairly subtle setting to outwit intruders. You need to record your settings in your CMS so you can reconstitute them on another server. We’ll start by getting hold of SMOs Server object, also known as
Microsoft.SqlServer.Management.SMO.server
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Import-Module sqlps -DisableNameChecking #load the SQLPS functionality for getting the registered servers import-module psyaml $ServerName = 'andrewctest.testnet.red-gate.com\sql2008' $Credentials = 'integrated security=True' $SMO = 'Microsoft.SqlServer.Management.SMO' # to shorten some of the devotions to libraries $Conn = 'Microsoft.SqlServer.Management.Common.ServerConnection' $SQLConn = 'System.Data.SqlClient.SqlConnection' $connectionString = "Data Source=$serverName;$credentials;pooling=False;multipleactiveresultsets=False;packet size=4096" #this might need to be changed under some circumstances try #making the connection { $srv = new-object "$Smo.Server"(new-object $Conn(new-object $sqlConn($connectionString))) } catch #if it isn't going to happen { "Could not connect to SQL Server instance '$servername': $($error[0].ToString() + $error[0].InvocationInfo.PositionMessage). The script is aborted" exit - 1 # return -1 if there is an error otherwise 0 } # |
Then we’ll get the endpoint information, but also use the opportunity to add the essential details about the server and the date the record was made. No need to worry about what extra information you record in the YAML document. If it is useful, add it because it doesn’t affect the ease with which we can import the settings as an object if we wish to transfer these settings to a different server.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$EndPointFacts = @{ #create the hash table that will contain the settings Server = $srv.Name; Date = Get-date; What = 'List of configuration settings'; } # and now we simply walk through the endpoints, adding the permissions as a hash table # and inserting the whole lot into our holding hash table $EndPointFacts.settings = $srv.Endpoints | Select Name, Protocol.Http.SslPort, Owner, EndpointState, EndpointType, Protocol, ProtocolType, Payload, @{Name = "Permissions"; Expression = {$_.EnumObjectPermissions() }} ConvertTo-YAML $EndPointFacts |
This will give you something like this (I’ve only included only a couple of endpoints)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
--- Date: 2016-09-30T14:58:23 Server: WhateverYourServerIs' What: 'List of configuration settings' settings: - Name: 'Dedicated Admin Connection' Protocol.Http.SslPort: null Owner: 'sa' EndpointState: 'Started' EndpointType: 'TSql' Protocol: Http: '[Dedicated Admin Connection]' Tcp: '[Dedicated Admin Connection]' ProtocolType: 'Tcp' Payload: DatabaseMirroring: '[Dedicated Admin Connection]' ServiceBroker: '[Dedicated Admin Connection]' Soap: '[Dedicated Admin Connection]' Permissions: null - Name: 'TSQL Default TCP' Protocol.Http.SslPort: null Owner: 'sa' EndpointState: 'Started' EndpointType: 'TSql' Protocol: Http: '[TSQL Default TCP]' Tcp: '[TSQL Default TCP]' ProtocolType: 'Tcp' Payload: DatabaseMirroring: '[TSQL Default TCP]' ServiceBroker: '[TSQL Default TCP]' Soap: '[TSQL Default TCP]' Permissions: ColumnName: null Grantee: 'public' GranteeType: 'ServerRole' Grantor: 'sa' GrantorType: 'Login' ObjectClass: 'Endpoint' ObjectID: '4' ObjectName: 'TSQL Default TCP' ObjectSchema: null PermissionState: 'Grant' PermissionType: 'CONNECT' |
I won’t go into the nuts and bolts of how you save this to a file. If you’re unsure, I’ll show how in the next illustration.
Without sliding too far off-topic, you can store this endpoint configuration in source control and use it in a PowerShell script for building your server to host a database application. After all, endpoint settings are as much part of a database as any other aspect of access control.
Saving and Comparing Configuration Settings
Perhaps you just want to have your basic configuration settings written out in your CMS. (we will be using the same server object $srv in this code)
|
1 2 3 4 5 6 7 8 9 |
$settings=@{} $srv.Configuration.properties|foreach{ $settings.Add(($_.displayName), ($_.Runvalue))} $EnPointFacts = @{ Server = $srv.Name; Date = Get-date; What = 'List of configuration settings'; settings=$settings } ConvertTo-YAML $EnPointFacts >"$env:TEMP\ConfigSettings_$($srv.InstanceName)_$(Get-Date -format ddMMMyy).YAML" |
This will give you a simple list of your configuration data that can subsequently be saved or read from disk into a PowerShell object for analysis.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
--- Date: 2016-09-30T14:43:59 Server: 'andrewctest.testnet.red-gate.com\sql2008' What: 'List of configuration settings' settings: Ad Hoc Distributed Queries: 1 server trigger recursion: 1 set working set size: 0 query governor cost limit: 0 access check cache quota: 0 PH timeout (s): 60 Agent XPs: 1 lightweight pooling: 0 locks: 0 nested triggers: 1 ft crawl bandwidth (max): 100 access check cache bucket count: 0 xp_cmdshell: 1 ft notify bandwidth (min): 0 Database Mail XPs: 0 awe enabled: 0 affinity I/O mask: 0 recovery interval (min): 0 show advanced options: 1 fill factor (%): 0 media retention: 0 min memory per query (KB): 1024 common criteria compliance enabled: 0 clr enabled: 1 SMO and DMO XPs: 1 remote login timeout (s): 20 cross db ownership chaining: 0 ft crawl bandwidth (min): 0 in-doubt xact resolution: 0 scan for startup procs: 0 user options: 0 max worker threads: 0 precompute rank: 0 open objects: 0 SQL Mail XPs: 0 cursor threshold: -1 remote admin connections: 0 two digit year cutoff: 2049 backup compression default: 0 c2 audit mode: 0 blocked process threshold (s): 0 optimize for ad hoc workloads: 0 user connections: 0 transform noise words: 0 priority boost: 0 remote query timeout (s): 600 filestream access level: 0 default trace enabled: 1 max degree of parallelism: 0 ft notify bandwidth (max): 100 disallow results from triggers: 0 index create memory (KB): 0 affinity mask: 0 remote access: 1 default full-text language: 1033 query wait (s): -1 max full-text crawl range: 4 network packet size (B): 4096 EKM provider enabled: 0 allow updates: 0 min server memory (MB): 8 max text repl size (B): 65536 Ole Automation Procedures: 1 cost threshold for parallelism: 5 Replication XPs: 0 default language: 0 remote proc trans: 0 max server memory (MB): 2147483647 |
What use is this? Well, in this case, I’ve saved the information in a temporary location and I’ve saved it for a few days. I’ve then changed a setting. Can I find when I changed it? Well, yes.
|
1 2 |
Compare-Object $(Get-Content "$env:TEMP\ConfigSettings_SQL2008_27Sep16.YAML") ` $(Get-Content "$env:TEMP\ConfigSettings_SQL2008_29Sep16.YAML") |
|
1 2 3 4 5 6 |
InputObject SideIndicator ----------- ------------- Date: 2016-09-29T16:01:25 => Ole Automation Procedures: 0 => Date: 2016-09-27T16:09:58 <= Ole Automation Procedures: 1 |
Or you can let your source control system do the work for you, in which you’d definitely want to remove the date!
Now you have these on file you can access single settings from PowerShell. These get the setting for the cost threshold for parallelism for 27th September and checks the date on the file!
|
1 2 3 |
$content = ConvertFrom-YAML ([IO.File]::ReadAllText("$env:TEMP\ConfigSettings_SQL2008_27Sep16.YAML")) $content.settings.'cost threshold for parallelism' $content.Date |
|
1 2 3 |
5 27 September 2016 16:09:58 |
Getting the Quantities of each Object in Each Database.
So what about something a bit more spectacular? A stock-take of your database objects? Here is some simple code for getting the number of each type of database object from all the databases on a server. Once again, we’ll leave out the obvious details of creating and connecting the SMO server object and cut to the essential details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
#firstly we find out the number of system views, tables and functions there are $SystemViews = $srv.databases['model'].Views.Count $SystemSchemas = $srv.databases['model'].Schemas.Count $SystemStoredProcedures = $srv.databases['model'].StoredProcedures.Count $SystemFunctions = $srv.databases['model'].UserDefinedFunctions.Count #now we create an empty array and then stock it with the number of each #type of object #We will start with a record of the number of system views and functions #that are exposed via the sys and Information_schema schemas in each database $Sizing = @( [ordered]@{ Database = 'System/Model'; 'no. of Schemas' = $SystemSchemas; 'no. of Stored Procedures' = $SystemStoredProcedures; 'no. of Functions' = $SystemFunctions; 'no. of Views' = $SystemViews; } ) #now we add in all the system and user databases. $Sizing += $srv.databases | foreach{ [ordered]@{ Database = $_.Name; 'Object-count' = [ordered]@{ "no. of Rules" = $_.Rules.Count; "no. of Schemas" = $_.Schemas.Count - $SystemSchemas; "no. of Sequences" = $_.Sequences.Count; "no. of StoredProcedures" = $_.StoredProcedures.Count - $SystemStoredProcedures; "no. of Synonyms" = $_.Synonyms.Count; "no. of Tables" = $_.Tables.Count; "no. of Triggers" = $_.Triggers.Count; "no. of UserDefinedAggregates" = $_.UserDefinedAggregates.Count; "no. of UserDefinedDataTypes" = $_.UserDefinedDataTypes.Count; "no. of UserDefinedFunctions" = $_.UserDefinedFunctions.Count - $SystemFunctions; "no. of UserDefinedTableTypes" = $_.UserDefinedTableTypes.Count; "no. of UserDefinedTypes" = $_.UserDefinedTypes.Count; "no. of Users" = $_.Users.Count; "no. of Views" = $_.Views.Count - $SystemViews; "no. of XmlSchemaCollections" = $_.XmlSchemaCollections.Count } } } ConvertTo-YAML $Sizing |
So, on a nice clean instance, we get
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
--- - Database: 'System/Model' no. of Schemas: 13 no. of Stored Procedures: 1393 no. of Functions: 118 no. of Views: 480 - Database: 'AdventureWorks2014' Object-count: no. of Rules: 0 no. of Schemas: 5 no. of Sequences: 0 no. of StoredProcedures: 11 no. of Synonyms: 0 no. of Tables: 71 no. of Triggers: 1 no. of UserDefinedAggregates: 0 no. of UserDefinedDataTypes: 6 no. of UserDefinedFunctions: 11 no. of UserDefinedTableTypes: 0 no. of UserDefinedTypes: 0 no. of Users: 4 no. of Views: 20 no. of XmlSchemaCollections: 6 - Database: 'model' Object-count: no. of Rules: 0 no. of Schemas: 0 no. of Sequences: 0 no. of StoredProcedures: 0 no. of Synonyms: 0 no. of Tables: 1 no. of Triggers: 0 no. of UserDefinedAggregates: 0 no. of UserDefinedDataTypes: 0 no. of UserDefinedFunctions: 0 no. of UserDefinedTableTypes: 0 no. of UserDefinedTypes: 0 no. of Users: 4 no. of Views: 0 no. of XmlSchemaCollections: 0 - Database: 'msdb' Object-count: no. of Rules: 0 no. of Schemas: 10 no. of Sequences: 0 no. of StoredProcedures: 475 no. of Synonyms: 10 no. of Tables: 144 no. of Triggers: 0 no. of UserDefinedAggregates: 0 no. of UserDefinedDataTypes: 0 no. of UserDefinedFunctions: 58 no. of UserDefinedTableTypes: 1 no. of UserDefinedTypes: 0 no. of Users: 7 no. of Views: 78 no. of XmlSchemaCollections: 4 - Database: 'tempdb' Object-count: no. of Rules: 0 no. of Schemas: 0 no. of Sequences: 0 no. of StoredProcedures: 0 no. of Synonyms: 0 no. of Tables: 1 no. of Triggers: 0 no. of UserDefinedAggregates: 0 no. of UserDefinedDataTypes: 0 no. of UserDefinedFunctions: 0 no. of UserDefinedTableTypes: 0 no. of UserDefinedTypes: 0 no. of Users: 4 no. of Views: 0 no. of XmlSchemaCollections: 0 - Database: 'WideWorldImporters' Object-count: no. of Rules: 0 no. of Schemas: 10 no. of Sequences: 26 no. of StoredProcedures: 42 no. of Synonyms: 0 no. of Tables: 48 no. of Triggers: 0 no. of UserDefinedAggregates: 0 no. of UserDefinedDataTypes: 0 no. of UserDefinedFunctions: 2 no. of UserDefinedTableTypes: 4 no. of UserDefinedTypes: 0 no. of Users: 4 no. of Views: 3 no. of XmlSchemaCollections: 0 |
We can, of course read this YAML into PowerShell and find out, for example, the total number of database objects, and the maximum number in any database
|
1 2 3 4 5 6 7 |
Foreach-Object { ConvertFrom-YAML $OurYAMLfile } | foreach{ $_.GetEnumerator() } | #for every database Where-Object Name -eq 'Object-count' | foreach { $_.Value } | foreach{ $_.GetEnumerator() | Select-object @{ Name = "Object"; Expression = { $_.Name } }, @{ Name = "HowMany"; Expression = { $_.Value } } } | Measure-Object HowMany -sum -max |Select Sum, Maximum, Count |
..to give…
|
1 2 3 |
Sum Maximum Count --- ------- ----- 3075 1393 79 |
Conclusion
As far as I’m aware, YAML is the only format or language of data documents that is designed for both machines and humans. It is for XML what Markdown is for HTML. As data professionals, we can no longer avoid representing hierarchical information, and YAML is a good compromise. Already PostgreSQL is using YAML for EXPLAIN plans. It is great for headers of function and procedure scripts. You can pack a lot of information into an extended property as well!
References
Accelerate and simplify database development with Redgate
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments