
Development and test environments need realistic data to exercise applications properly, but real production data often contains sensitive information (PII, PHI, financial identifiers) that shouldn’t leave the production boundary. Data obfuscation – transforming values so they remain plausible and format-valid but no longer identify real individuals – is the standard approach.
Seven techniques cover most practical scenarios:
(1) Character scrambling – reshuffle characters within each string value so letter frequency and length are preserved but the content is different;
(2) Repeating character masking – replace the middle or end of a value with repeating characters, as credit card receipts show the last four digits;
(3) Numeric variance – add a random percentage variance to each numeric value so distributions are preserved; (4) Nulling – replace sensitive values with NULL where the application can accept it;
(5) Truncation – remove part of the value (last four of a SSN, first three of a zip code);
(6) Encoding – use a mapping table to replace values with codes that preserve uniqueness and referential integrity;
(7) Aggregation – replace per-row detail with group-level summaries.
This article walks through each with T-SQL implementations and discusses when each technique is appropriate, plus briefly covers third-party data-generation tools as an alternative.
Introduction to obfuscation
Halloween is one of my favorite times of the year. On this holiday, the young and young at heart apply make-up, masks, costumes and outfits and wander the streets in search of sweet treats from their neighbors. These costumes are designed to hide the identity of their wearer and grant that person the freedom to shed their everyday demeanor and temporarily adopt the persona of their disguise.
Applying the technique of obfuscation to our sensitive data is somewhat akin to donning a Halloween disguise. By doing so, we mask the underlying data values, hiding their true nature, until the appropriate time to disclose it.
We will explore a handful of obfuscation techniques, which do not require an algorithm, encryption key, decryption key or transformation of data types.
Each of these methods, including character scrambling and masking, numeric variance and nulling, rely on an array of built-in SQL Server system functions that are used for string manipulation.
While these methods of obfuscation will not be used by any federal government to protect nuclear missile launch codes, they can be highly effective when printing documents that contain sensitive data, transferring production data to test environments or presenting data through reporting and warehousing mechanisms.
Development Environment Considerations
Before we proceed with an exploration of obfuscation methods, let’s spend a few moments reviewing a strong candidate for the implementation of the obfuscation methods presented in this article: the development environment.
The database that is utilized for daily business transactions is referred to as the production database. The version of the database that is used to develop and test new functionality is referred to as the development database. These environments are separated so that new development and troubleshooting can occur without having a negative effect on the performance and integrity of the production database.
Any proposed modifications to a production database should be first implemented and tested on a development or test database. In order to ensure the accuracy of this testing, the development database should mimic the production database as closely as possible, in terms of the data it contains and the set of security features it implements.
This means that all of the sensitive data efforts and options noted in this book apply to both environments and that it may be necessary to store sensitive data in both the development and production databases. The difficulty with this is that it is common for developers and testers to be granted elevated permissions within the development database. If the development database contains identical data to that stored in the production database, then these elevated permissions could present a severe and intolerable security risk to the organization and its customers.
In order to mitigate this risk, the Database Administrator responsible for refreshing the contents of the development environment should apply obfuscation methods to hide the actual values that are gleaned from the production environment.
Obfuscation Methods
The word obfuscation is defined by the American Heritage Dictionary as follows:
“To make so confused or opaque as to be difficult to perceive or understand … to render indistinct or dim; darken.”
The word obfuscation, at times, can be used interchangeably with the term obscurity, meaning “the quality or condition of being unknown“. However, there is a subtle difference between the two terms and the former definition is more appropriate since obscurity implies that the hidden condition can be achieved without any additional effort.
Many methods of “disguise”, or obfuscation, are available to the Database Administrator that can contribute a level of control to how sensitive data is stored and disclosed, in both production and development environments. The options that will be discussed in this article are:
- Character Scrambling
- Repeating Character Masking
- Numeric Variance
- Nulling
- Artificial Data Generation
- Truncating
- Encoding
- Aggregating.
Many of these methods rely on SQL Server’s built-in system functions for string manipulation, such as SUBSTRING, REPLACE, and REPLICATE. Appendix A of my book provides a syntax reference for these, and other system functions that are useful in obfuscating sensitive data.
Prior to diving into the details of these obfuscation methods we need to explore the unique value of another system function, called RAND.
The Value of RAND
The RAND system function is not one that directly manipulates values for the benefit of obfuscation, but its ability to produce a reasonably random value makes it a valuable asset when implementing character scrambling or producing a numeric variance.
One special consideration of the RAND system function is that when it is included in a user defined function an error will be returned when the user defined function is created.
|
1 2 |
Msg 443, Level 16, State 1, Procedure SampleUDF, Line 12 Invalid use of a side-effecting operator 'rand' within a function. |
This can be overcome by creating a view that contains the RAND system function and referencing the view in the user defined function. The script in Listing 8-1 will create a view in the HomeLending database that returns a random value, using the RAND system function. Since this view holds no security threat, we will make this available to the Sensitive_high, Sensitive_medium and Sensitive_low database roles with SELECT permissions on this view.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Use HomeLending; GO -- Used to reference RAND with in a function CREATE VIEW dbo.vwRandom AS SELECT RAND() as RandomValue; GO -- Grant permissions to view GRANT SELECT ON dbo.vwRandom TO Sensitive_high, Sensitive_medium, Sensitive_low; GO |
Listing 8-1: Generating random numbers using RAND.
Now, we can obtain a random number in any user defined function with a simple call to our new view. In Listing 8-2, an example is provided that produces a random number between the values of 1 and 100.
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @Rand float; DECLARE @MinVal int; DECLARE @MaxVal int; SET @MinVal = 1;="color:black"> SET @MaxVal = 100;="color:black"> SELECT @Rand = ((@MinVal + 1) - @MaxVal) * RandomValue + @MaxVal FROM dbo.vwRandom GO |
Listing 8-2: Testing the View.
Character Scrambling
Character scrambling is a process by which the characters contained within a given statement are re-ordered in such a way that its original value is obfuscated. For example, the name “Jane Smith” might be scrambled into “nSem Jatih”.
This option does have its vulnerabilities. The process of cracking a scrambled word is often quite straightforward, and indeed is a source of entertainment for many, as evidenced by newspapers, puzzle publications and pre-movie entertainment.
Cracking a scrambled word can be made more challenging by, for example, eliminating any repeating characters and returning only lower case letters. However, not all values will contain repeating values, so this technique may not be sufficient for protecting highly sensitive data.
The Character Scrambling UDF
In the HomeLending database we will create a user defined function called Character_Scramble that performs character scrambling, which is shown in Listing 8-3. It will be referenced as needed in views and stored procedures that are selected to use this method of data obfuscation.
Included in this user defined function is a reference to the vwRandom view that was created in Listing 8-1. In essence, this user defined function will loop through all of the characters of the value that is passed through the @OrigVal argument replacing each character with other randomly selected characters from the same string. For example, the value of “John” may result as “nJho”.
In order for the appropriate users to utilize this user defined function permissions must be assigned. The GRANT EXECUTE command is included in the following script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
Use HomeLending; GO -- Create user defined function CREATE FUNCTION Character_Scramble = ( @OrigVal varchar(max) ) RETURNS varchar(max) WITH ENCRYPTION AS BEGIN -- Variables used DECLARE @NewVal varchar(max); DECLARE @OrigLen int; DECLARE @CurrLen int; DECLARE @LoopCt int; DECLARE @Rand int; -- Set variable default values SET @NewVal = ''; SET @OrigLen = DATALENGTH(@OrigVal); SET @CurrLen = @OrigLen; SET @LoopCt = 1; -- Loop through the characters passed WHILE @LoopCt <= @OrigLen BEGIN -- Current length of possible characters SET @CurrLen = DATALENGTH(@OrigVal); -- Random position of character to use SELECT @Rand = Convert(int,(((1) - @CurrLen) * RandomValue + @CurrLen)) FROM dbo.vwRandom; -- Assembles the value to be returned SET @NewVal = @NewVal + SUBSTRING(@OrigVal,@Rand,1); -- Removes the character from available options SET @OrigVal = Replace(@OrigVal,SUBSTRING(@OrigVal,@Rand,1),''); -- Advance the loop="color:black"> SET @LoopCt = @LoopCt + 1; END -- Returns new value Return LOWER(@NewVal); END GO -- Grant permissions to user defined function GRANT EXECUTE ON dbo.Character_Scramble TO Sensitive_high, Sensitive_medium, Sensitive_low; GO |
Listing 8-3: The character scrambling UDF.
This user defined function takes advantage of system functions such as DATALENGTH which provides the length of a value, SUBSTRING which is used to obtain a portion of a value, REPLACE which replaces a value with another value and LOWER which returns the value in lowercase characters. All are valuable to string manipulation.
This UDF will be referenced in any views and stored procedures that are selected to use this method of data obfuscation, an example of which we’ll see in the next section.
Repeating Character Masking
Over recent years the information that is presented on a credit card receipt has changed. In the past, it was not uncommon to find the entire primary account number printed upon the receipt. Today, this number still appears on credit card receipts; but only a few of the last numbers appear in plain text with the remainder of the numbers being replaced with a series of “x” or “*” characters. This is called a repeating character mask.
This approach provides a level of protection for sensitive data, rendering it useless for transactional purposes, while providing enough information, the number’s last four digits, to identify the card on which the transaction was made.
In the HomeLending database, we will create a user defined function called Character_Mask, as shown in Listing 8-4, which performs repeating character masking, which again can be referenced as needed in views and stored procedures that are selected to use this method of data obfuscation.
This user defined function will modify the value that is passed through the @OrigVal argument and replace all of the characters with the character passed through the @MaskChar argument. The @InPlain argument defines the number of characters that will remain in plain text after this user defined function is executed. For example, the value of “Samsonite” may result in “xxxxxxite”.
In order for the appropriate users to utilize this user defined function permissions must be assigned. The GRANT EXECUTE command is included in the script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
Use HomeLending; GO -- Create user defined function CREATE FUNCTION Character_Mask ( @OrigVal varchar(max), @InPlain int, @MaskChar char(1) ) RETURNS varchar(max) WITH ENCRYPTION AS BEGIN -- Variables used DECLARE @PlainVal varchar(max); DECLARE @MaskVal varchar(max); DECLARE @MaskLen int; -- Captures the portion of @OrigVal that remains in plain text SET @PlainVal = RIGHT(@OrigVal,@InPlain); -- Defines the length of the repeating value for the mask SET @MaskLen = (DATALENGTH(@OrigVal) - @InPlain); -- Captures the mask value SET @MaskVal = REPLICATE(@MaskChar, @MaskLen); -- Returns the masked value Return @MaskVal + @PlainVal; END GO -- Grant permissions to user defined function GRANT EXECUTE ON dbo.Character_Mask TO Sensitive_high, Sensitive_medium, Sensitive_low; GO |
Listing 8-4: The Character_Mask UDF.
This user defined function takes advantage of system functions such as DATALENGTH, which provides the length of a value, and REPLICATE which is used to repeat a given character for a defined number of iterations. Both of these are valuable to string manipulation.
To illustrate the use of this, and our previous Character_Scramble user defined function, to present data in a masked format to the user, we will create a view in the HomeLending database, called vwLoanBorrowers, for the members of the Sensitive_high and Sensitive_medium database roles.
This view, shown in Listing 8-5, will present to the lender case numbers, using the Character_Mask user defined function, and the borrower names using the Character_Scramble user defined function.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Use HomeLending; GO CREATE VIEW dbo.vwLoanBorrowers AS SELECT dbo.Character_Mask(ln.Lender_Case_Number,4,'X') AS Lender_Case_Number, dbo.Character_Scramble(bn.Borrower_FName + ' ' + bn.Borrower_LName) AS Borrower_Name FROM dbo.Loan ln INNER JOIN dbo.Loan_Borrowers lb ON ln.Loan_ID = lb.Loan_ID AND lb.Borrower_Type_ID = 1 -- Primary Borrowers Only INNER JOIN dbo.Borrower_Name bn ON lb.Borrower_ID = bn.Borrower_ID; GO -- Grant permissions to view GRANT SELECT ON dbo.vwLoanBorrowers TO Sensitive_high, Sensitive_medium; GO |
Listing 8-5: The vwLoanBorrowers View.
The vwLoanBorrowers view, without the use of the masking user defined functions, would have returned the data set shown in Table 8-1.
| Lender Case Number | Borrower Name |
| 9646384387HSW | Damion Booker |
| 8054957254EZE | Danny White |
Table 8-1: The non-obfuscated result set.
However, with the user defined functions in place the masked data set shown in Table 8-2 is returned:
| Lender Case Number | Borrower Name |
| XXXXXXXXX7HSW | o akdenbimr |
| XXXXXXXXX4EZE | ni ahtydwe |
Table 8-2: The results returned after character masking and scrambling.
Numeric Variance
Numeric variance is a process in which the numeric values that are stored within a development database can be changed, within a defined range, so as not to reflect their actual values within the production database. By defining a percentage of variance, say within 10% of the original value, the values remain realistic for development and testing purposes. The inclusion of a randomizer to the percentage that is applied to each row will prevent the disclosure of the actual value, through identification of its pattern.
In the HomeLending database, we will create a user defined function called Numeric_Variance that increases or decreases the value of the value passed to it by some defined percent of variance, also passed as a parameter to the function. For example, if we want the value to change within 10% of its current value we would pass the value of 10 in the @ValPercent argument.
A randomizer is added through the use of the vwRandom view that we created earlier in this article. This will vary the percent variance on a per execution basis. For example, the first execution may change the original value by 2%, while the second execution may change it by 6%.
The script to create this Numeric_Variance function, which can be referenced as needed in other views and stored procedures, is shown in Listing 8-6.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
USE HomeLending; GO -- Create user defined function CREATE FUNCTION Numeric_Variance ( @OrigVal float, @VarPercent numeric(5,2) ) RETURNS float WITH ENCRYPTION AS BEGIN -- Variable used DECLARE @Rand int; -- Random position of character to use SELECT @Rand = Convert(int,((((0-@VarPercent)+1) - @VarPercent) * RandomValue + @VarPercent)) FROM dbo.vwRandom; RETURN @OrigVal + CONVERT(INT,((@OrigVal*@Rand)/100)); END GO -- Grant permissions to user defined function GRANT EXECUTE ON dbo.Numeric_Variance TO Sensitive_high, Sensitive_medium, Sensitive_low; GO |
Listing 8-6: The Numeric_Variance UDF.
To employ this method of masking in a development database, simply use an UPDATE statement to change the column’s value to a new value, using our Numeric_Variance function, as shown in Listing 8-7.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE HomeLending; GO -- Variables used DECLARE @Variance numeric(5,2) -- Set variance to 10% SET @Variance = 10 UPDATE dbo.Loan_Term SET Loan_Amount = dbo.Numeric_Variance(Loan_Amount,@Variance) FROM dbo.Loan_Term; GO |
Listing 8-7: Updating a development database to use numeric variance.
Nulling
The process of nulling is the replacement of sensitive data with a NULL value, thus rendering the sensitive data unavailable in the development database. While this certainly protects the sensitive data, since the values are no longer known in the database, it does present issues if there are dependencies upon this data or constraints that do not permit a NULL value. Also, use of nulling can also present difficulties when trying to troubleshoot issues that specifically involve sensitive data.
To employ this method of masking in a development database, simply use an UPDATE statement to set the column’s value to NULL, as shown in Listing 8-8.
<
|
1 2 3 4 5 6 7 8 |
USE HomeLending; GO UPDATE dbo.Borrower_Identification SET Identification_Value = NULL FROM dbo.Borrower_Identification; GO |
Listing 8-8: Nulling a database column.
Truncation
Truncation is a method of protecting sensitive data where a portion of its value is removed. The concept is very similar to the repeating character masking covered earlier except that rather than replacing values with a “mask”, such as an “x” or “*”, truncating simply discards those values. For example, a Social Security Number, “555-86-1234”, that is stored in plain text might be truncated to the value of “1234”.
One way to apply this method is to permanently modify the stored value in the database by executing an UPDATE statement using the LEFT, RIGHT or SUBSTRING system function to define the remaining portion of the value.
For example, the script in Listing 8-9 uses the LEFT function to truncate all but the last four digits from the Identification_Value column.
|
1 2 3 4 5 6 7 8 9 |
USE HomeLending; GO UPDATE dbo.Borrower_Identification SET Identification_Value = LEFT(Identification_Value,4) FROM dbo.Borrower_Identification; GO |
Listing 8-9: Permanently truncating the Identification_Value column.
Alternatively, in order to maintain the original value but perform the truncation for viewing, we can simply reference the column in views and stored procedures that use the LEFT, RIGHT or SUBSTRING system functions to define the remaining portion of the value. For example, Listing 8-10 returns only the last four digits of the values of the Identification_Value column:
|
1 2 3 4 5 6 7 8 |
USE HomeLending; GO SELECT LEFT(Identification_Value,4) AS Identification_Value FROM dbo.Borrower_Identification; GO |
Listing 8-10: Returning a truncated value.
Encoding
Encoding is a technique in which a series of characters is used to represent another value. This technique can be used to camouflage sensitive data, since the code used has no meaning outside the system in which the code is defined.
NOTE:
There are many benefits to encoding, beyond securing sensitive data, such as overcoming language barriers when working in an international environment and providing an expedient means of entering data.
Encoding is a practice that is found in abundance in the health care industry. The World Health Organization maintains the International Classification of Diseases (ICD), which is an industry standard that defines codes that represent diseases and health problems. These codes are used in health records and death certificates. For example, the ICD code for bacterial pneumonia is J15.9.
In the establishment of foreign keys in the HomeLending database we have, at a basic level, implemented encoding. The Loan table, for example, contains two columns that are named Purpose_Type_IDand Mortgage_Type_ID as illustrated in Figure 8-1
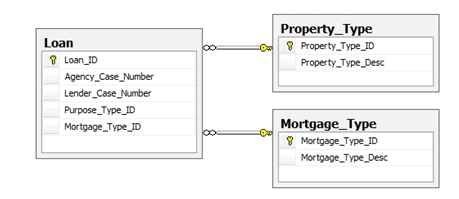
Figure 8-1: Loan table with Foreign Key Relationships
The Purpose_Type_IDand Mortgage_Type_ID columns are foreign keys to the Purpose_Type table and Mortgage_Type table. These tables contain, respectively, the list of potential purposes for a loan and the types of available mortgage, as defined in the Uniform Residential Loan Application, developed by the Federal National Mortgage Association, commonly known as Fannie Mae.
In the Purpose_Type table, we have used a sequence of numbers to indicate these purposes. So, for example, when a new loan record is created, the value of “2” is captured instead of the value “Refinance”.
To further enhance this encoding, we may choose to either utilize a higher starting number in our sequence, such as “5000”, so that the options can be organized into logical groups. For example, we may have various types of refinance options for our borrowers. Through a higher starting number we could use the value range of 5000 through 5100 to represent the available refinance options, while construction loans might be found in the 2000 through 2100 range.
Aggregation
Aggregation is a technique in which identifying details of data are obfuscated through its provision in a summarized format. A few examples of presenting data as an aggregation are as follows:
- As an average: 40% of the loans originated in the
HomeLendingdatabase during the past quarter were refinance loans. - As a calculated sum: $2.5 million in loans were originated in the HomeLending during the past quarter.
- As a geographical statistic: The median home value in the city of Indianapolis, Indiana is $150,000.
Aggregating is a common technique used to populate data warehouses for data analysis. This not only protects the underlying sensitive data, but also reduces the storage requirements for the data.
An advantage of this approach is that the data that is provided to the user is only that which they need for their reporting and analysis requirements, so the potential for the leakage of sensitive data is greatly reduced.
A disadvantage to this approach is that if the aggregations are determined to be inaccurate, the detail data is not available to identify the cause. Another challenge to this approach is that a given aggregation may not meet everyone’s needs, resulting in requests for different views of the same aggregated data, which increases your maintenance footprint.
Within the HomeLending database, aggregation may be beneficial in the collection of the borrower’s liabilities. The current design of the Borrower_Liability table requires the capture of the monthly payment amount and remaining balance. As shown in Figure 8-2, the Borrower_Liability table is related to the Liability_Account table, which reveals the creditor and account number of the liability.
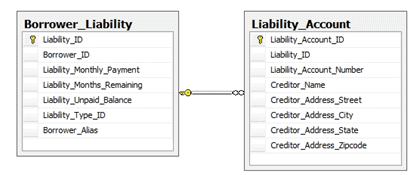
Figure 8-2: The Borrower_Liability and Liability_Account Tables.
An alternate approach would be to dispose of the Liability_Account table and simply capture a single record for the loan application, indicating the sum of their monthly payments and remaining balances for all liabilities, as shown in Figure 8-3.

Figure 8-3: Alternate approach for Borrower_Liability table.
This level of detail would suffice for most users of this database and would protect this sensitive information from being inappropriately disclosed. The Underwriters, who may need access to the detailed liability data for qualification purposes, would refer to the credit report data, which is stored in a separate database, to determine whether or not the borrower can be approved for the loan.
Artificial Data Generation
As an alternative to these obfuscating techniques, you can generate data using third party tools, such as Red Gate’s SQL Data Generator which can produce large volumes of artificial data, based upon regular expressions and pre-defined ranges of values.
This provides protection of sensitive data due to the artificial nature of the data that is generated. In many cases, these third party tools will not execute internal encryption and obfuscation methods. This should not discourage the consideration of artificial data generation. This is noted simply to note that you may need to consider these special methods in a separate process from the general artificial data generation process.
Summary
In this article, we explored some options that are available to protect sensitive data through obfuscation. The system functions that are available in SQL Server provide us with the tools that can be employed in our views, stored procedures and user defined functions to create an effective line of defense.
Once our sensitive data has been secured we will want to identify when an attacker has gained access to our system and is snooping around for sensitive data. In addition, we will want to identify when valid users of our database are taking actions that may be suspicious. This can be done through the auditing feature of SQL Server 2008, and through a practice known as honeycombing.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments