
How does SSD work and what are its physical limitations?
Solid state storage that is based on flash memory is a fairly new technology. It has only been around for some 15-20 years whereas SSDs based on RAM or NOR storage have been around longer, since 1979.
In this article I will look at a type of Solid State storage called flash memory, also called NAND. It is known as ‘flash’ because one of the inventors, while testing the electrons discharge from the cells of the media exclaimed “This looks like a camera flash”.
Solid State Disks (SSDs) have several components: they have their own processor, they have their own cache, and they contain several NAND chips.
The NAND chip has multiple cells which can contain a charge of electrons. The charge of electrons serves as a bit data storage, i.e. when the cell is charged the value is 0, and when it is empty the value is 1.
As we can imagine, the first most obvious limitation of this structure would be the finite number of program-erase cycles. Every time the cell is charged and discharged, it gets closer to being unable to hold a charge. Once this happens, the entire sector fails.
There are very few producers of NAND chips in the world. Keep in mind that NAND chip producer does not mean storage media producer. In reality, the NAND chips are bought by Solid State Disk manufacturers, which use the NAND chip manufacturer’s interface specifications to write software that controls the NAND chip within the product.
It is the software which controls how many times a cell is charged and discharged and it is responsible for wear leveling. In other words, it is the software provided by the SSD vendors which makes the difference between the SSD products.
Wear leveling is a technique which prolongs the life of the NAND chips by ‘shuffling’ data around so all cells in the NAND chip get used equally. In theory this prolongs the life of the SSDs, but there is yet another limitation of the SSDs which makes the technology rather controversial when it is used with highly transactional database systems. The limitation is related to the smallest write / erase unit in the SSDs, and I will explain more about this later in the article.
The contemporary SSDs use MLC (multi-layer chips). Multi-layer chips were used to achieve greater capacity for the same area of a NAND chip. The manufacturers introduced a multi-threshold for the charge of a single cell. Even though this technique increases capacity, it also decreases the lifecycles of the chips exponentially. There are double-bit and triple-bit chips; so with a single-layer chip we can have 16GB disk space and it will have better durability than 32GB chip (a multi-layer chip) and 64GB chip (which uses triple-bit multi-layer) will be even less durable.
So, in order to keep the high capacity and still have some decent reliability, SSD vendors use cache memory. This means that data is stored first in cache (the drive write cache) and kept there as long as possible.
But this, of course, creates reliability problems – especially with SQL Server data. The main concern here is for the atomicity and consistency of the data.
The guidelines for using write-caching with SQL Server are not clear-cut, and they really depend on the hardware and whether it is battery-backed or not.
One thing is certain, however – SSDs are much more complex in software terms than an HDD and this means that there is so much more that could potentially go wrong with them during a power failure. SSDs have a lot more housekeeping functions; they have a lot more elements to power and much more to consider when the power supply becomes unreliable.
Once again, this varies from vendor to vendor.
How do HDDs and SSDs compare?
NAND device layout:
Each NAND device has:
- Gates – they are responsible for conducting, keeping and releasing the electrical charge of the cells (this very reason makes them vulnerable to ‘wear and tear’ over time)
- Cell – a container of electrical charge which indicates bit value(s); it can be single bit in SLC or it can contain multiple levels of charge and indicate several bits in MLC
- Byte – one byte is comprised of 8 bits / cells
- Sector – a sector is either 512+16 or 2048+64 bytes (or even higher), which is equal to 1 page (this varies from vendor to vendor)
- Block – is a grouping of sectors (16/32/64 sectors depending on SLC / MLC); the smallest erase unit is a block.
The smallest writeable unit in a SSD is a sector. The smallest erase unit is a block.
Side-by-side comparison between SSD and HDD:
The sector in HDD is 512 bytes; the SSD sector may vary from 512, 2k, 4k, 8k.
The SSDs block size depends on the manufacturer and whether it is 16, 32 or 64 sectors.
So the smallest erase unit will be equal to the block size multiplied by sector size. – i.e. if we deal with 64 sectors per block and we have 2048 bytes per sector, if we wanted to delete the data, we would need to charge an area of 128k. (This means that depending on the manufacturer, certain drives will wear off faster than others, since they have different block sizes; furthermore, in order to do an update of a single bit, the entire block has to be written someplace else and the old block has to be charged with electrons, which again means extra wearing off the drive.)
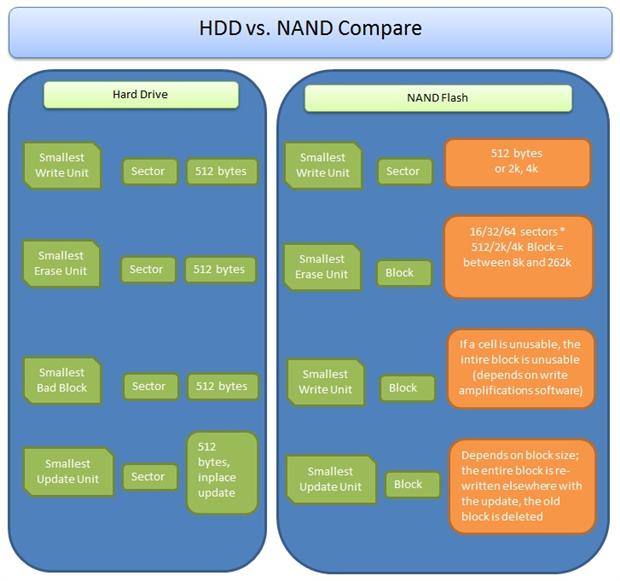
In HDDs – 512 bytes is the smallest write unit and also the smallest bad block. In SSDs it is a bit different, because it depends on the size of the sector.
The smallest erase unit is 512 bytes for HDD.
The smallest Bad block for HDD is 1 sector – 512 bytes, but for SSD is 1 block. If any cell is bad, the entire block is marked as bad. This depends on software, if it can reuse the cells (this is also called ‘write amplifications’), but generally up to the 3rd generation of SSDs, it will mark the entire block bad.
The main difference between the Writes / Updates in SSD and HDD is that when you use HDD you can modify a sector and store the data exactly where it initially was. You can change a sector. When you make a change to data on an SSD, on the other hand, the device already has a charge for the current data and so it has to write the change somewhere else and then remove the old data. Then the old space will be given to the garbage collector and the old data will be erased. This means that the cells will have extra wear.
The significance of this is that the more free space there is, the faster big changes of data will be performed. I would be very curious to test the performance of bulk updates on SSDs when the drive capacity is almost full. If every block has to be moved in order to write the update, then it will be very interesting to measure the performance and wear-and-tear of the drive during this process.
What does the use of SSDs mean for database performance
- Does fragmentation matter?
There is a widely spread myth that fragmentation does not matter in the case of SSDs because the access to all cells is equally fast.
Even though this statement is partially true, there are more factors to account for, aside from the read latency. In short, the fragmentation of table indexes causes more reads than for indexes which are not fragmented, and also the fragmentation diminishes the available disk capacity.
For a detailed test case I recommend reading Jonathan Kehayias’ blog post: http://www.sqlskills.com/blogs/jonathan/post/does-index-fragmentation-matter-with-ssde28099s.aspx.
- Do we get different speeds for different data access patterns (sequential read, write, random read write)?
Of course even for SSDs there are differences between sequential / random reads and writes (the sector and block sizes matter as well as the Queue Depth settings).
The SSDs reads outperform the HDDs, but the performance of the SSDs significantly diminishes in the case of writes and, specifically, updates.
- How do we lose capacity and gain speed?
Fragmentation and wear cause lower capacity, but we have faster speed than spindle disk.
As I mentioned above, fragmentation means more IOPS to read the same amount of data and also means that less cells are available for use, i.e. the larger the fragmentation, less of the drive’s capacity can be used.
Also, frequent updates increase the ‘wear-and-tear’ of the drive, which means that as cells get exhausted and become unusable, the drive loses capacity.
- Does the use of write caching in SSDs help to minimize the wear?
As mentioned above, the write caching is a double-edged sword: it minimizes the wearing of the drive, but it might be vulnerable to power failure unless a serious consideration is given to battery backups and disaster recovery procedures.
- When we gain faster data access, does this mean that we can process it? (CPU and memory are still limited).
It is true that SSDs bring great benefit to our database systems by providing faster data access and by diminishing the latencies to minimum. But the question still remains, how much data can the other components handle?
If we have unlimited access to data, then we actually need to have unlimited access to RAM and to CPU to process the data further.
- What data is most suitable for SSDs, what workloads are NOT suitable for SSDs?
I have mentioned the allocation units for SSDs and for HDDs and it is clear that the more data updates we have, the greater performance problem it becomes for the SSDs. This is because when data is updated on an SSD, the entire block has to be moved to a new block together with the update and then the old block has to be erased. This wears the drive significantly, and slows down performance.
SSDs are great for static data, however. If the data is mostly read and not changed so often, then the SSDs are the best way to go.
- Can we recover data after a failure?
A significant difference between SSDs and HDDs is that, when HDD fails, there are many ways to extract most of the data. Depending on what is damaged, a replacement of the head may help, or maybe just some of the platters can be recovered and so on.
In the case of SSDs, it is almost impossible to extract any data if the drive stops working. Because of the complex algorithms used for wear leveling and because of the specifics of the NAND technology, it is almost impossible to recover data once the SSD fails in service.
- Energy use
The best state for the SSD is to be in use. When the SSD is powered up, it has the best chance of keeping its data intact – it maintains the data in a consistent state.
If an SSD drive is not powered up for a significant period of time (the shelf life of data on SSD is about 7 years) then some data loss is to be expected.
The bottom line:
When deciding whether to use SSDs or HDDs there are several areas to be considered:
- Talk to your SSD vendor about their life cycle guarantee. How many life cycles do they estimate per cell?
- Keep in mind that the bigger the capacity, the more layers are used for the cells, which decreases the wear and the reliability of the drive dramatically.
- Consider what kind of workload will be placed on the SSD. It is great to use them for data which does not change often, despite the read disturb (the way the cells are read over and over may cause the change in value of the adjacent cells after some 100 thousand reads)
- Your database programming techniques have to be adjusted; for example, if TEMPDB is placed on SSDs , the use of temporary objects has to be very cautious.
- Data fragmentation has a new meaning with SSDs. While fragmentation is not good news with HDDs because of the data access latency, it is also not good news with SSDs due to the loss of capacity and the extra wear of the cells when de-fragmenting. With SSDs we have a choice, either less capacity or extra wear.
- Data recovery strategy – when a HDD fails, there is still a chance of recovering some of the data, depending on what failed. With SSDs it is almost impossible to ‘scrape’ any data. This also means that with SSDs, if one NAND chip fails then the entire SSD fails.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments