
Roughly four years ago, my team implemented, and began using rigorously, a harness of automated tests from our database code. With the help of Alex Styler, I wrote a series of articles explaining, from a developer’s perspective, how we unit test databases, and in particular stored procedures. In these articles, we provided a working framework for testing (i.e. the implementation of all the modules we used), but we did not spend much time explaining why we made certain choices regarding test implementation, tools and language.
Four years later, this article attempts to describe our automated testing from a team leader’s perspective, highlighting which problems show up as we keep changing our system, and as the size of our code base grows. It also revisits some of the choices we made and, with the benefit of hindsight, assesses how they worked out.
The benefits and costs of automated database testing
Creating and maintaining a harness of automated tests is never cheap: it takes time and effort to create the tests and additional time and effort to adjust them in response to changes in our systems.
Given this investment, we expect the following payoff: testing a code change, and making sure nothing else was broken as a result of the change, becomes extremely fast and reliable. In Agile environments, where change is frequent and the team expects a rapid response to these changes, it is particularly important to have efficient and comprehensive test harnesses.
Even under the best circumstances, a useful test harness requires a lot of effort to create and maintain and, unfortunately, it is particularly challenging to unit test T-SQL modules because:
- Any testing that involves databases is slow, compared to testing with mocks. Typically it is much faster to develop mock objects than to set up proper test data, and the tests running off mocks usually complete much faster too.
- T-SQL lacks the tools and IDEs that make development and automated testing relatively easy in modern object-oriented languages such as Java, C++, and C#
This means that automated tests for T-SQL modules require extra care, in order to get them right, and if we do not do it right, our test harness may be prohibitively slow to run, or very brittle and expensive to modify. In either case, we might end up spending too much on the test harness, and eventually decide that it simply not worth the pain.
Despite all this, our experience over four years of unit testing stored procedures has proved to us that it is possible to have a test harness that manages to inform us if our T-SQL modules are broken, run in reasonable time, and can be maintained with reasonable effort. More to the point, it is also quite feasible to start adding tests to a system which does not have any, and reap the benefit of such tests, in a reasonably short time.
Lessons Learned
The goal here is to describe the main lessons we’ve learned from our database testing in a way that will enable someone joining a new project which doesn’t currently use automated testing, to start adding useful tests quickly, and in places where they are most needed.
A brief note on nomenclature
Strictly speaking, not all the tests we discuss in the article are unit tests. Some might be better described as regression tests, others integration tests. The emphasis of this article is simply on developing useful tests that run automatically and involve database objects.
Trivial modules usually don’t need tests
All tests in our system must have a reason to exist; the effort required to create and maintain a test should be justified by the payoff we expect to get from it. In other words, when we break a module that is covered by a test, the test must help us determine, quickly, exactly what is broken. In most cases, tests covering very simple modules do not fare well against these criteria. Consider, for example, the trivial stored procedure shown in Listing 1.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE PROCEDURE dbo.SelectCountry @CountryCode VARCHAR(3) AS BEGIN ; SET NOCOUNT ON ; SELECT CountryCode , [Description] FROM dbo.Countries WHERE CountryCode = @CountryCode ; RETURN @@ERROR ; END ; |
Listing 1: A trivial stored procedure
With or without a test, changing this procedure would be very easy and the additional time effort that will be required to maintain the test as well as the code is probably wasted. Explicitly testing such trivial modules rarely makes sense (except in articles and books, where all examples must be short!)
Complex modules and queries, in contrast, require more effort to maintain, and benefit more from automated testing because they:
- Need more frequent performance tuning; we often completely rewrite a slow query, improving its performance while keeping its functionality intact
- Are more likely to have bugs, and when we fix those bugs we need to make sure that we haven’t introduce new ones
- Are more difficult to change if the requirements have changed
- Need better documentation, and a well written set of unit tests works very well in this regard, since they demonstrate how to run a module and show the expected results.
So, if our system does not have any tests at all, we should definitely start by first developing tests for the more-complex modules.
Integration tests are vital
Suppose that we have a complex ETL process, developed a while ago, and we need to change it. The transformation phase of this process is far from trivial, so it takes considerable time to understand what it is doing. Regardless of the quality and quantity of documentation, it really helps when we can run a few working examples. Also, of course, we need to make sure that our change to the ETL process doesn’t break anything. More specifically, it really helps if we can do the following:
- Set up a sandbox database, and pre-load some test data into it
- Get the source data for the ETL
- Run the ETL
- Make sure the results are exactly as expected.
Note that the process described above would definitely not be a unit test, because it involves multiple modules, possibly developed in more than one language. Yet it would be highly useful, and we do want to have such tests. This ETL process is just one example; there are typically many situations when we want to run automated tests that involve both client-side code and the database.
Add tests gradually
In reality, we have too many other demands on our time to concentrate exclusively on developing a test harness for more than a few hours or days. Instead, we typically have to include work on tests in our already busy schedule, gradually improving our test coverage.
In order to be able to add tests gradually and easily, we need a sound testing framework. However, setting up the framework is somewhat involved, and must be done before we can run our first test. To run automated tests, we need the ability to:
- Create a database and populate it with test data;
- Run tests and determine if they succeeded.
Let us discuss in more detail our initial, up-front investment, setting up the framework.
Requirements for the test databases
First of all, every developer needs his or her own test database in order to avoid interfering with each other’s activities. Overall, it is simpler and cheaper to let everyone create and drop their own sandboxes, as needed. We’ve found it most convenient for each member of our team to just run SQL Server Developer’s Edition right on their workstation. This allows each developer to work off different Git branches, and possibly different versions of database schema, and to use different test data, if needed.
Secondly, we need a simple and rock-solid way to create a sandbox database from scripts, and data that is version control friendly. Text files, such as SQL scripts and .csv files, are version control friendly; they allow us to see history of changes, and that is essential when we are determining what went wrong.
On the other hand, binary files such as backups and detached files, do not easily allow us to analyze a history of changes. As such, we don’t use them as the primary way, or the only way, to create a sandbox database.
Finally, since we are going to concentrate on covering only the more-complex modules, and are going to add test coverage incrementally, we do not have to have the full database schema in source control before we roll out our first test. Instead, we can concentrate on one schema or one domain area. For example, we can concentrate on Sales schema for now, and not script out into version control any objects from Marketing schema, unless they are referred to by objects in Sales schema.
Once each developer has a sandbox database, it is time to start using it, and to start benefiting from the time and effort invested in creating it, even if the sandbox database is not quite complete, as yet. We can begin covering with tests all the new complex modules in Sales schema, as well as covering existing modules as we need to change them for whatever reason.
Adding the first tests: Clarifying the requirements
Developing tests should begin with clarifying the requirements. At the risk of stating the obvious: as we develop tests for a module, we have to make sure that it is doing the right thing.
Incomplete, incorrect, and ambiguous communication between customers and developers, resulting in incomplete or incorrect requirements, is a serious problem that frequently slows down software development. Improving communication is especially important in Agile teams, where speed of development is essential. Lots of research and innovation is going on in this area and one article in particular that’s worth reading is Introducing Behavior Driven Development, by Dan North, which offers a way to dramatically improve our communication, guarantee that our documentation is always up-to-date, and involve our customers in creating a meaningful test harness.
Fortunately, in database programming we can have executable requirements without having to develop a language for that purpose. Let’s consider a specific T-SQL example of executable requirements. Suppose that we need to implement a stored procedure dbo.SelectCustomersByName, and the requirements are as follows: “the user should always provide last name. First name is optional. The module must return all matching rows.“
Clearly the requirements are incomplete, and as we develop the module, we need answers to the following questions:
- If first name is not provided, should we match on last name only?
- How do we order the result set?
- What should we do if first name is supplied as zero-length string (which is different from
NULL)?
I might be missing a few questions, but I’m sure you get my point.
Instead of communicating via e-mail, updating some document, or modifying a ticket, all of which are time-consuming, we can just translate the requirements into straightforward stored procedure calls, as demonstrated in Listing 2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- if first name is not provided, return all matches on last name, -- ordered by first name and ID EXEC dbo.SelectCustomersByName @LastName = 'Yang' ; GO -- if first name is a zero-length string, silently convert it to NULL -- return all matches on last name, ordered by first name and ID EXEC dbo.SelectCustomersByName @LastName = 'Brown', @FirstName = '' ; GO -- if there are multiple matches, rows must be ordered by ID EXEC dbo.SelectCustomersByName @LastName = 'Brown', @FirstName = 'Jessica' ; GO |
Listing 2: Executable acceptance criteria
When we have set up enough test data and have some implementation, we can just create the sandbox database, run the script, and show the script and its output to our customers. If there is any misunderstanding, we can quickly fix the code and/or add more test cases. This approach works especially well when we work right next to our customers; collocation is quite common in Agile environments.
The script works very wells as means of communication between customers and developers. Even better, we can incorporate this script directly into our test harness, so that it also serves us as an automated test. All we need to do is generate the expected output in XML format, as we shall discuss soon, and we are all set. Whenever we need to run our test harness, it will automatically create an empty database, set up test data off scripts loaded from version control, execute the requirements, and match actual results against expected ones, which are also loaded from version control.
So, one and the same T-SQL script serves several purposes: it provides clear and precise requirements, forms part of our automated test harness and offers practical and easy to use documentation in the form of working examples.
Traditional documentation can easily get out of sync with the actual system, and that may become a serious problem. If, however, requirements take the form of working examples, executed against a test database, they must be in sync with current state of our system; otherwise our tests would fail.
Matching actual test results against expected
At this point, let’s assume that we have clear and complete requirements in the form of a commented T-SQL script, and the output of the script looks correct. However, to have a complete automated test, we need to match its output against expected results every time we run it. We’ve certainly learned a few lessons here, over the past four years.
Everything must be verified in all cases
When we explicitly test a stored procedure that returns result sets, we should always verify the structure of the result sets, as well as all values in all returned rows, match the expected results. If a column name or type changes, this may break some other code. Our tests are more useful if they detect all potentially-breaking changes.
Some database testing frameworks allow us to choose whether or not we want to verify the structure of the result sets. There might be cases when we do not want to detect such breaking changes, but so far I have not encountered a single such case in my practice. So, in order to keep things simple, and to avoid wasting time making the same choice over and over again, our framework simply does not allow such a choice. Instead, our framework always verifies that the structure of results sets is as expected.
When a test fails, it must provide full details
All too many automated tests fail too early, without outputting the full details of what exactly went wrong. As a result, we end up spending more time than necessary determining what exactly is broken. Let us consider, for example, the typical xUnit-type code snippet in Listing 3.
|
1 2 3 4 |
Assert.AreEqual(1.23, actualResults.Rows[0].Columns[0]); Assert.AreEqual(new DATETIME(2011, 11, 5), actualResults.Rows[0].Columns[1]); //snip Assert.AreEqual(1.25, actualResults.Rows[3].Columns[5]); |
Listing 3: A typical x-unit-style test
If there is any discrepancy between actual and expected results, this test will surely indicate failure, which is good. The problem, however, is that after the first failure no more checks are executed, so we do not get very much information about why the test failed. Suppose, for instance, that the very first assertion failed. Is the first row missing altogether from the result set? Have the rows returned in the wrong order? Is this the only wrong value in the whole result set? We do not know, and we have to spend extra effort to understand what exactly is going on.
If a test fails, usually we want to know exactly what went wrong right away, and in full detail, so automating this very common task to the fullest make a lot of practical sense. Just verifying the row count of the result set is not good enough; it would detect only one of the previous three problems. Another popular approach, checksum verification, would detect all three problems but when such a test fails, we still do not know exactly what went wrong.
In our framework, we store the expected and actual results as text (XML) files, so we can use any diff tool, such as TortoiseMerge, to see all the differences. If, for instance, the first row is missing, we can see this right away, as shown in Figure 1.
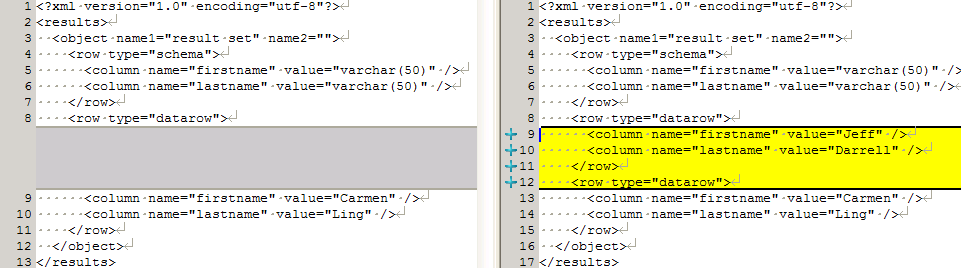
Figure 1: A missing row in the actual results (click to enlarge)
Similarly, it is obvious from Figure 2 that only the first value in the first column does not match.
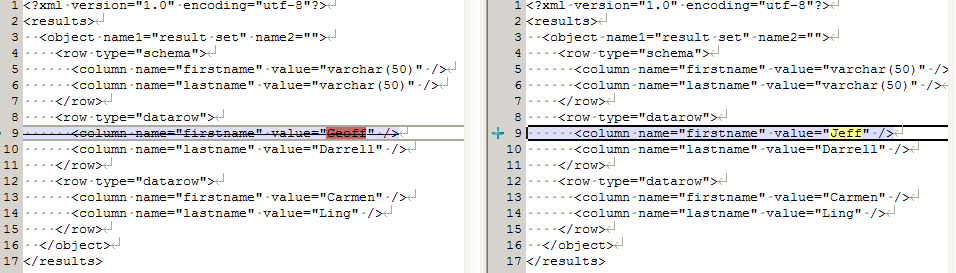
Figure 2: Only one non-matching row
If the rows return in the wrong order, it is just as easy to spot, as shown in Figure 3.
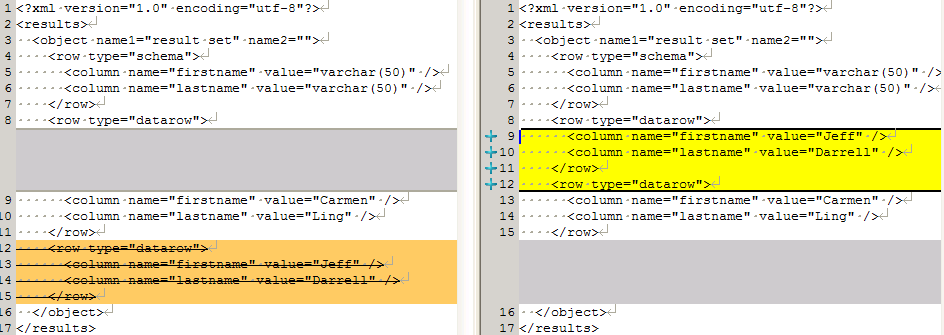
Figure 3: Rows returned in the wrong order
This test output gives us the whole picture, whenever our test detects a discrepancy. Note that the XML files shown in the output are, by design, version-control friendly; they use line breaks and indentations so that they show only one property (or one column, or one field) per line. As such, we can easily see all the differences without having to scroll left and right, even on a smallish laptop screen. Little things like this can boost productivity.
Expected results should be generated and stored separately
The reason is simple: this approach speeds up both creating and, in particular, maintaining these tests. For example, suppose that we need to unit test a procedure dbo.SelectCustomersByZipCode; we’ve set up test data, and have issued the following stored procedure call from SSMS:
|
1 |
EXEC dbo.SelectCustomersByZipCode @ZipCode = '60540' ; |
Our testing framework will do the rest for us; it will execute this script and store its output in in an XML file, as shown in Figure 4.
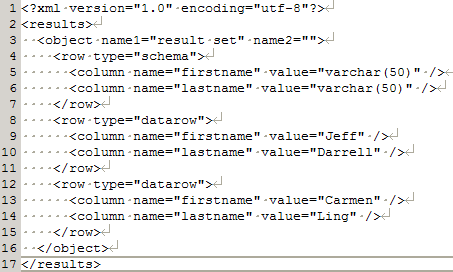
Figure 4: XML output from a test
However, at some later date, we add a new column, MiddleName, to our dbo.Customers table and need to expose this new column in many of our stored procedures. This is one of those cases when making a change itself is easy, but fixing the tests broken by the change may take much more time.
Instead, we can just make the change and rerun the tests in a mode that overwrites expected results whenever there is a mismatch, as shown in Figure 5.
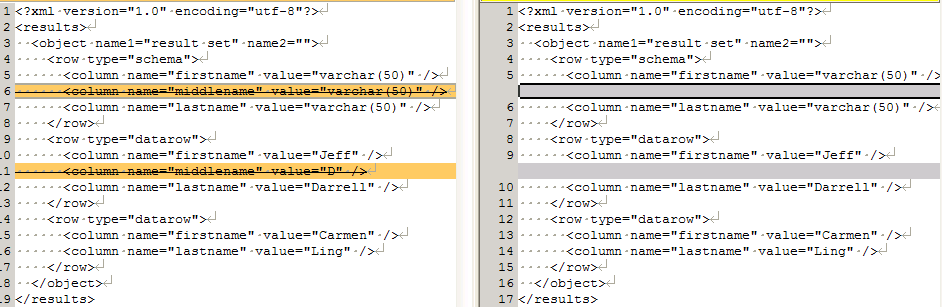
Figure 5: New column added
We must still verify all the changes we commit to version control, and this takes some time; there is no way around it. However, we have fixed all those broken tests at once, and with very little effort. We did not have to fix tests one by one, neither manually nor via wizards, which would have been very boring, repetitive, and time consuming.
As we have seen, keeping expected results separate from the tests can dramatically speed up maintenance, because it allows us to automate a lot of tedious work.
Developing tests defensively
As we are developing tests, we need to do it defensively, just as when we are developing any other code, otherwise we can make a change that renders our test useless, and not notice it.
Suppose, for example, that we are testing a stored procedure which returns all the events that occurred within a range of time, including the beginning of the range, and excluding its end, as shown in Listing 4.
|
1 2 3 4 5 6 7 8 9 10 |
-- test data EXEC dbo.SaveEvent @EventTime = '20111228 09:30:00', @Description = 'Range starts, must be returned' ; EXEC dbo.SaveEvent @EventTime = '20111228 09:35:00', @Description = 'Inside the range, must be returned' ; -- this row is exactly on end of range, must not be returned EXEC dbo.SaveEvent @EventTime = '20111229 09:40:00', @Description = 'Range ends, must NOT be returned' ; EXEC dbo.GetEventsForDateRange @EventTimeFrom = '20111228 09:30:00', @EventTimeTo = '20111228 09:40:00' ; |
Listing 4: A faulty unit test
In this test we are selecting all events that occurred on or after 9:30 AM and before 9:40 AM on December 28th, 2011.This test is supposed to return the two first rows out of three, and it does exactly that. However, the test is not completely correct: the third event occurs one day later that the range submitted to dbo.GetEventsForDateRange ends on December 29th instead of December 28th.
We tried to do it right, testing the edge case when an event occurs exactly when a range ends, and we even managed to document our intent in a clear comment, but we have still ended up with a mistake in our test, of which we are not aware.
All this effort spent on good comments has failed to prevent us from a mistake. This is a good demonstration of that fact that comments, however useful they can be, are frequently not good enough, and that we can do better. Let me demonstrate how we could avoid such a mistake.
In our test, when we execute dbo.GetEventsForDateRange, we are assuming that there is an event occurring exactly when our range ends. Instead of just commenting this assumption, we can enforce it in several ways. If we are setting up test data for this one test, we can enforce the assumption as shown in Listing 5.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @EndRange DATETIME ; SET @EndRange = '20111228 09:40:00' ; -- test data EXEC dbo.SaveEvent @EventTime = '20111228 09:30:00', @Description = 'Range starts, must be returned' ; EXEC dbo.SaveEvent @EventTime = '20111228 09:35:00', @Description = 'Inside the range, must be returned' ; EXEC dbo.SaveEvent @EventTime = @EndRange, @Description = 'Range ends, must NOT be returned' ; EXEC dbo.GetEventsForDateRange @EventTimeFrom = '20111228 09:30:00', @EventTimeTo = @EndRange ; |
Listing 5: The fixed test
If we are running multiple tests off the same test data, which is created in another script, we may add one more test to ensure that our assumption is correct, as shown in Listing 6.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- test data is set up in another script DECLARE @EndRange DATETIME , @EndRangePlusMinute DATETIME ; SET @EndRange = '20111228 09:40:00' ; SET @EndRangePlusMinute = DATEADD(MINUTE, 1, @EndRange) ; -- must return exactly one row EXEC dbo.GetEventsForDateRange @EventTimeFrom = @EndRange, @EventTimeTo = @EndRangePlusMinute ; -- the row from the test above -- must not be returned in this test EXEC dbo.GetEventsForDateRange @EventTimeFrom = '20111228 09:30:00', @EventTimeTo = @EndRange ; |
Listing 6: Adding another test to enforce an assumption
As we have seen, a few simple changes can correct our test harness and make it more robust.
Implementing the testing framework
This section describes the choices we’ve made with regard to tools and techniques, and how we’ve adapted them, as necessary, to help us survive frequent changes, while maintaining high quality in our system.
Choosing an existing testing tool vs. implementing our own
As Agile developers, we spend a lot of time every day working with our automated tests, so getting them right is essential; inefficiencies that could be easily tolerated in less dynamic environments get in our way all-too-often in Agile development. Such inefficiencies are like a small piece of rock in our shoe; the pain can be tolerated if we are going to walk a dog around the block, but it can cause a serious problem if we are running a marathon.
In our environment, we knew developing and maintaining unit tests was going to be a marathon, not a short jaunt round the block, so our stance was that the tools should do exactly what we want without unnecessary complications, and absolutely without any bugs.
When we started this project, in 2007, we could find no ready-made tools that would allow us to test database modules in the way we wanted. Rather than try to adapt to the limitations of these tools, in our testing, we made the decision to “reinvent the wheel” and develop our own testing tool.
Four years later, I can state confidently that this decision paid off very well for us. We concentrated on the tasks that we perform many times every day, and we ended up with a library that automated only the most important tasks but automated them really well. The relative lack of “features” meant that we could deliver a very robust solution; we encountered no bugs during four years of intensive use, and we fully trust our tool.
As Agile developers, we need to be able to refactor with confidence, and our simple and convenient tool allowed us to maintain very good test coverage quite easily. The time and effort invested in developing a simple and robust in-house tool paid off many times over.
Choosing the testing language
We chose to implement our testing solution in C#, because the team felt unanimously that C# development is more efficient than T-SQL development. As a result, we are using C# code to test T-SQL, and so technically our tests are not unit tests, but are integration tests.
However, doing most of the heavy lifting in C# also proved to be the right choice; it allowed us to implement testing logic only once and reuse it thousands of times. Also in my experience we could easier accomplish good performance with C#. More to the point, certain things are just not possible in T-SQL at all. For example, if a stored procedure returns multiple result sets, to my best knowledge there is no way to capture them all in T-SQL.
We absolutely did not want to restrict ourselves to stored procedures that return only one result set, so any methodology using T-SQL to test T-SQL was out of the question for us.
Conclusion
A harness of automated tests is more useful if we spend less time creating and maintaining it, and more time using it. Over four years of testing database code, we’ve learned that we should:
- Gradually add test coverage to our existing systems
- Use our tests as means of precise communication with the customers
- Verify everything, so that no breaking change goes unnoticed
- In case of failure provide complete information on what went wrong
- Generate expected results and store them separately
As our test harness gets bigger, we should expect some growing pains. They are quite real and need to be dealt with, but they are beyond the scope of this article. Before spending time and effort on improving our test harness, we need to know that it is actually worth it, which is the whole point of this article.
Happy programming and automated testing!
I would like to thank Dan North for reviewing the article.
The ‘Close Your Loopholes’ series of articles on Unit Testing TSQL code.
| Close These Loopholes in Your Database Testing | Alex starts of a series of articles on ‘Unit Testing’ your database development work. He starts off by describing five simple rules that make all the difference. ( 31 Jul 2007 ) |
| Close those Loopholes – Testing Stored Procedures | Alex and Alex give some examples of unit testing stored procedures. ( 20 Aug 2007 ) by Alex Kuznetsov and Alex Styler |
| Close These Loopholes – Testing Database Modifications | Alex K and Alex S give some examples of unit testing Database Modifications ( 02 Sep 2007 ) by Alex Kuznetsov and Alex Styler |
| Close Those Loopholes: Stress-Test those Stored Procedures | You can write a stored procedure that tests perfectly in your regression tests. You will hand it to the tester in the smug certainty that it is perfectly bug-free. Dream on, for without stress-testing you could easily let some of the most unpleasant bugs through. Alex showing how to catch those subtle problems. ( 03 Feb 2008 ) |
| Close these Loopholes – Reproduce Database Errors | Here, Alex shows how you can test the way that your application handles database-related errors such as constraint-violations or deadlocks. With a properly-constructed test-harness you can ensure that the end-user need never sees the apparent gobbledegook of database system error messages, and that they are properly and robustly handled by the application. ( 23 May 2008 ) |
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments