
There are some differences and secrets between the UI of a SQL Endpoint and the UI of a Lakehouse.
I believe the lakehouse UI was changed recently, otherwise you can blame me for being distracted to this level. Let’s analyze the differences and pending points between these UI’s.
SQL Endpoints
When using a SQL Endpoint, we can add multiple lakehouses to the explorer. They are included in the vertical, one above another. This is one of the differences between a SQL Endpoint and the lakehouse.
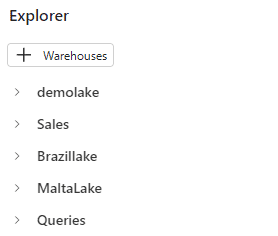
On the top of Explorer, the button is called “+ Warehouses”. This may be a bit confusing because we are working with a lakehouse. The fact is we can add either a lakehouse or data warehouses to the explorer.
Domains and Workspaces
The Microsoft Fabric portal has the domain feature in preview. Domains are a concept from the Data Mesh architecture, but this is a subject for a different and longer article.
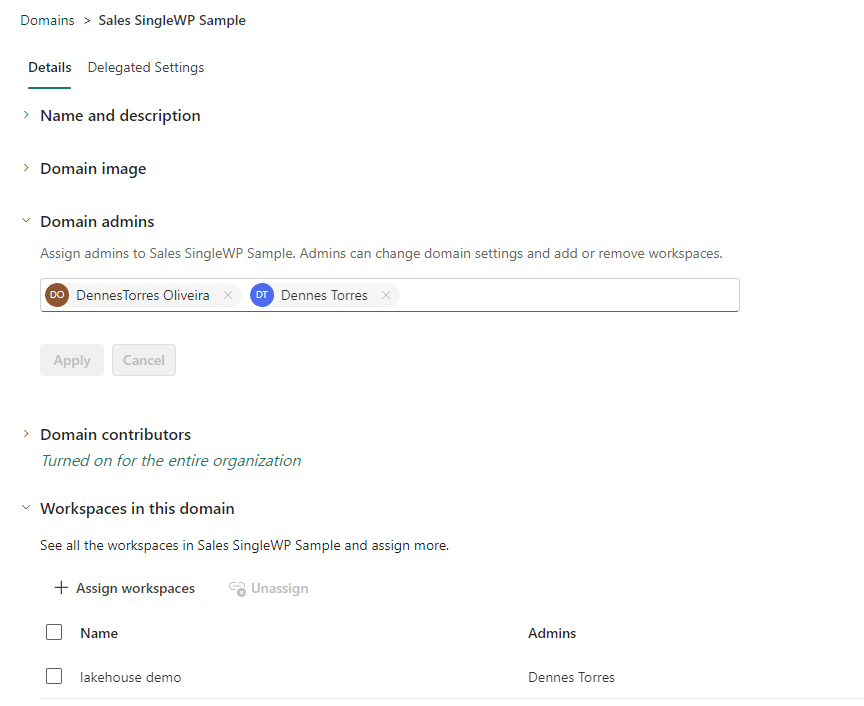
What’s important to understand is that domains allow us to create a set of workspaces and make some limited management tasks to the entire set.
The access to the domains management is done through the Power BI Admin portal.
On the left side of the window, we click on Domains.
In my environment, I already have many domains created.
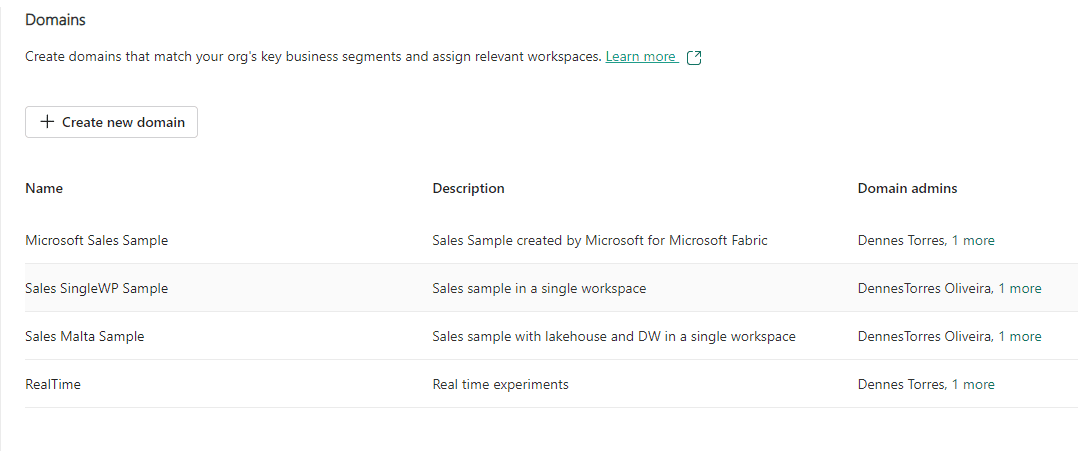
During the preview stage, there are very few configurations we can manage:
- The Domain Admins
- The Domain Contributors
- Workspaces belonging to the domain
- Data certification rules for the domain
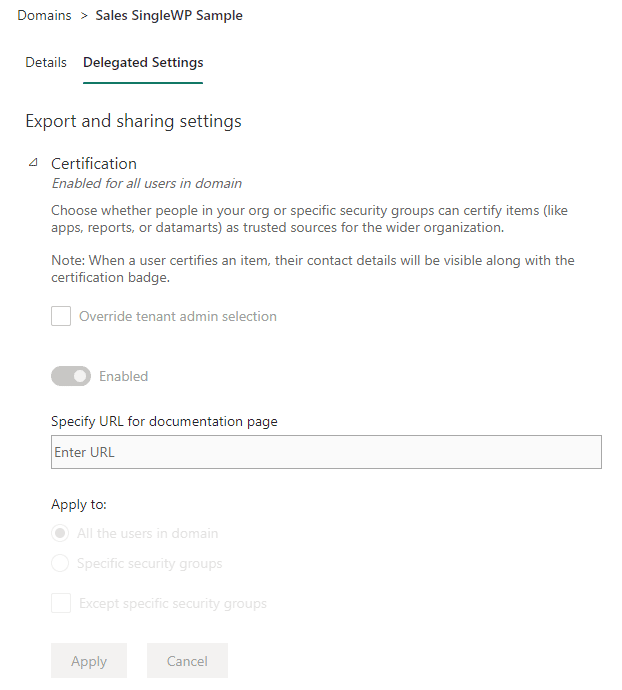
The fact of whether a workspace is linked to a domain or not affects how the SQL Endpoint and Lakehouse window works.
Adding a Storage to the SQL Endpoint
There are some curious behaviors in relation to the SQL Endpoint and the domain management.
If the workspace doesn’t belong to a domain, on the top right of the window we only see a “Filter” dropdown. Using this limited option, we can only add objects, either data warehouse or lakehouses, which are present in the same workspace.

On the other hand, if the workspace belongs to a domain, we can see an additional dropdown intended to include a list of domains.
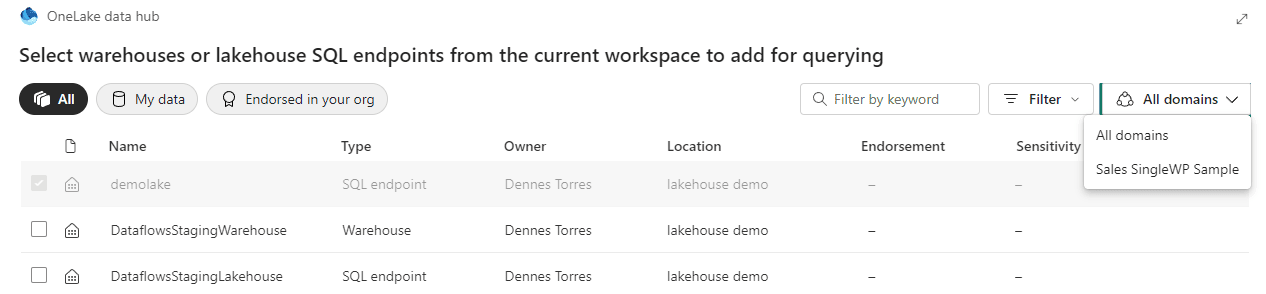
However, this dropdown has some very singular behaviors:
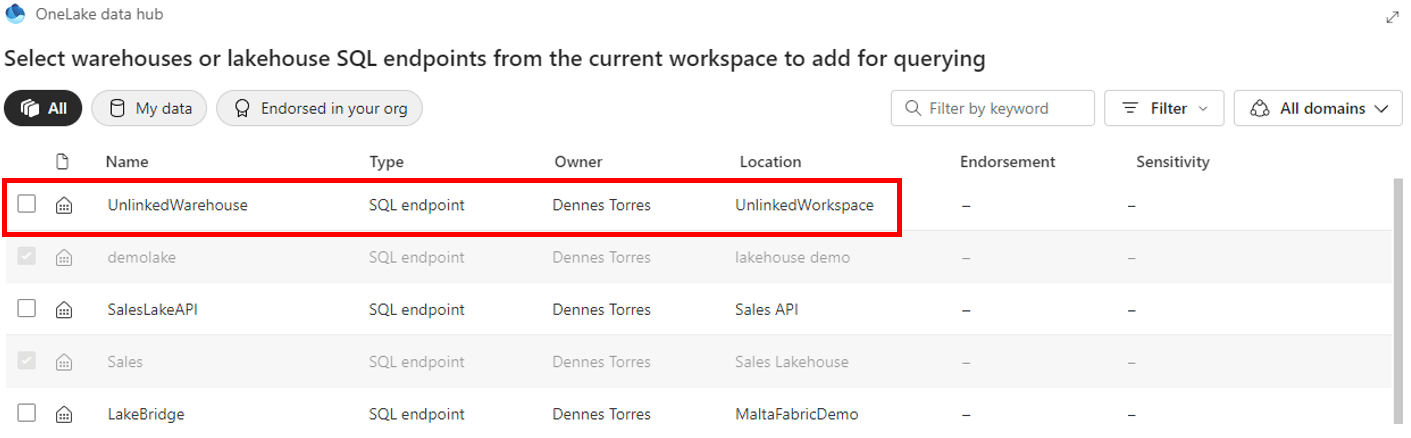
- Only the domain of the current workspace is listed, we can’t see a list of other existing domains.
- The “All Domains” is the default option, but we don’t see objects from all domains by default. We need to change the dropdown to one domain and change back to “All Domains” in order to see all the objects.
- The “All Domains” option includes objects not linked to any domain. The objects not linked to any domain can’t see the other ones, but the other ones can see them.
Queries on the SQL Endpoint
Although we can add objects from different workspaces in the Explorer, we can’t query them. Any attempt to make a cross workspace query will result in an error.
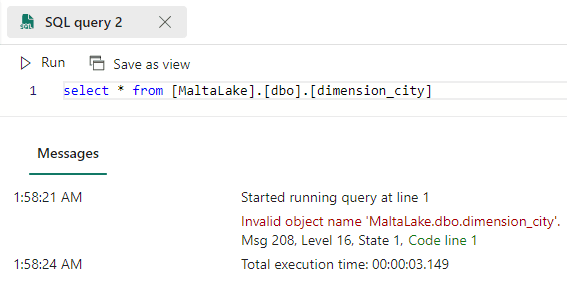
Cross lakehouse work is a long subject for another article. But we can make a conclusion: Either there is some missing feature being produced, or the possibility to add lakehouses to the explorer but not being able to query them is a small method to make cross lakehouse queries easier (but not much).
The lakehouse explorer
We can consider there are two lakehouse explorers:
- One is accessible directly from the lakehouse. On this one, only the lakehouse can be accessible.
- The second one is accessible when we open a notebook. In this one we can add multiple lakehouses.
The window to add a lakehouse to this explorer is very similar to the one explained in relation to the SQL Endpoints but some behaviors are different:
- All the domains are visible in this window, while on the SQL Endpoint only the workspace domain is visible.
- The domain dropdown is available independently if the workspace is linked to a domain or not.
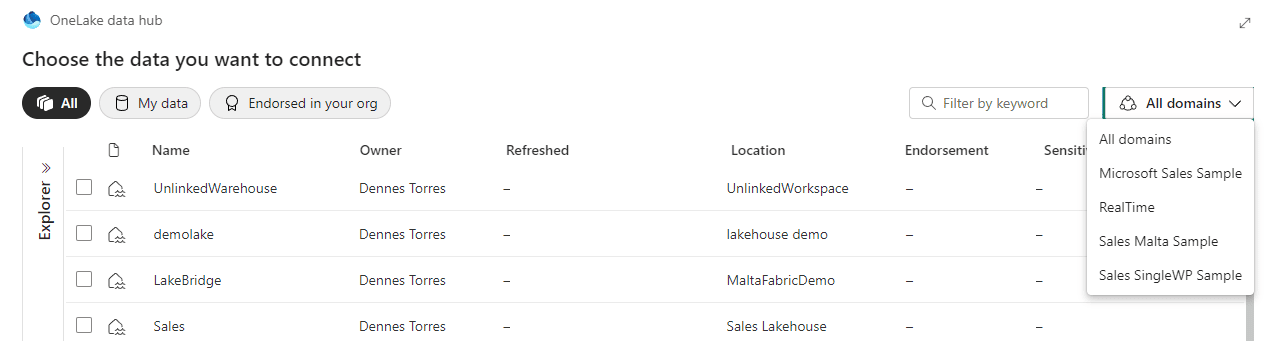
My developer mind keeps wondering why a window which should be the same has different behaviors depending on where it’s called from one place or another, without a clear reason for this. I would love to read your thoughts on the comments.
The default lakehouse
The first lakehouse included becomes the default one for the notebook.
The notebook uses a feature called Live Pool. This means when we run the notebook the spark pool is created automatically for us.
The spark pool creation process includes mounting the default lakehouse as a folder on file system. The path for the default lakehouse will be /lakehouse/default, with the option to access files on /lakehouse/default/files or access tables on /lakehouse/default/tables.
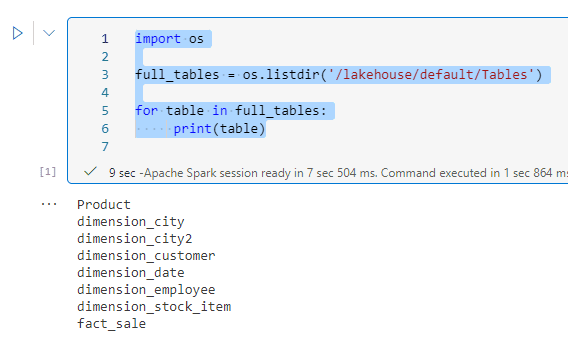
We can use the following code to list the tables from the default lakehouse:
import os full_tables = os.listdir('/lakehouse/default/Tables') for table in full_tables: print(table)
Multiple Lakehouses on the Explorer
When we click on the two arrows icon, we can add new lakehouses to the explorer.
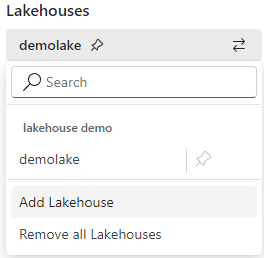
The lakehouses are not included vertically, like on the SQL Endpoint explorer. They are only visible when we click again on the two arrows icon.
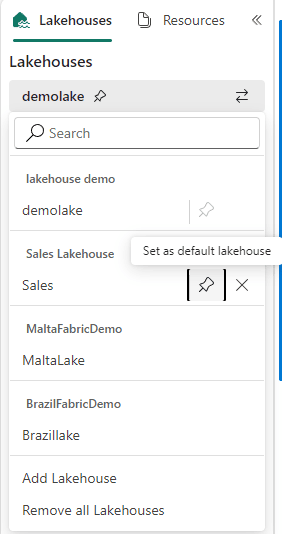
The menu shows which one is the default lakehouse and allows us to change it. Changing the default lakehouse changes the content mounted on the folder on /lakehouse/default.
The Notebook Access to the lakehouse
The notebook has two different ways to access the lakehouse:
- Access the mounted lakehouse using the OS path
- Use Spark.SQL to access the lakehouses contained in the same workspace as the default one
There is no method for the notebook to iterate through the lakehouses added to the explorer. The presence of the lakehouses on the explorer only helps us choose the default lakehouse, nothing else.
This makes me wonder if this is only the starting stage of new features about to be released until the Microsoft Fabric GA version.
Spark.SQL on the notebook
Spark SQL can access different lakehouses, but the ones available to Spark SQL are totally independent of the lakehouses included in the lakehouse explorer.
In summary, Spark.SQL can access all the lakehouses contained in the same workspace as the default lakehouse. It doesn’t matter if they are included in the lakehouse explorer or not.
We can use the following code to list the available lakehouses to spark.sql:
lakehouses = spark.catalog.listDatabases() lakehouse_list = [] for lakehouse in lakehouses: lakehouse_list.append(lakehouse.name) print(lakehouse_list)
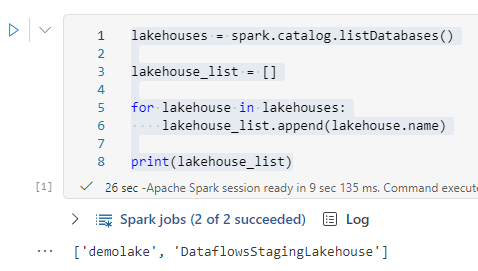
As you may notice in this example, the lakehouses listed are the ones in the same workspace as the default. This includes a lakehouse not in the Explorer and ignores others in it.
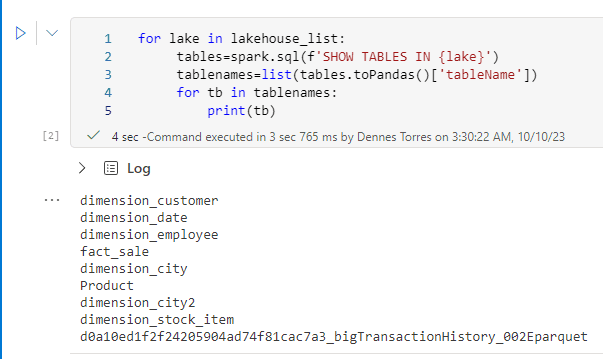
We can go further and use spark sql to list the tables in the lakehouses using the following code:
for lake in lakehouse_list: tables=spark.sql(f'SHOW TABLES IN {lake}') tablenames=list(tables.toPandas()['tableName']) for tb in tablenames: print(tb)
Summary
The UI is full of small tricks and unexpected differences which make us wonder which new features are coming on the GA version to justify these inconsistencies without a clear reason.
Meanwhile, we need to navigate these very small inconsistencies. The better we understand the relation between the lakehouse explorers, OS path and spark SQL, the better we will be able to make a great use of the environment.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments