
Finally, mirroring is available for Fabric! You can mirror an Azure SQL to Fabric. It works for CosmoDB and Snowflake as well, but in this article, I will focus on Azure SQL. It is 100%, no, but it is definitely a feature that is really great even now.
Before getting into a step-by-step of the process, let’s understand the basics.
Why Mirror a Database
You need to read data from production to build a single source of truth. If you create pipelines reading directly from production, you will create additional load over the production environment. The mirror allows you to do much of the production reporting from the mirror, leaving the production environment to serve other users. Keep in mind, production report, but not analytics report.
Mirroring a production database to Fabric is one method to ensure the load over production will be as low as possible and the data will be transferred fabric to complete the transformations from this point.
Only this? What about avoiding pipeline creation? Not really, you still need to create pipelines, as I will explain ahead.
Where your data will be stored
If I tell you OneLake, you might want to slap me. Of course it’s on OneLake, you know that! But where? A Data Warehouse? A Lakehouse? Where?
Microsoft created a special type of object for this: The Mirrored Database. In the same way as the other data objects, this object also has two associated objects: A SQL Endpoint and a Semantic Model.
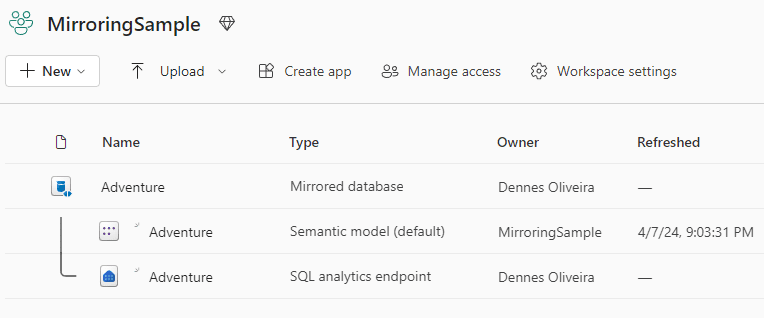
We can use the SQL Endpoint to query the mirrored data, in the same way we would do with a Data Warehouse or Lakehouse.
Of course we can use the Semantic Model to build reports, but let’s talk later if this is a good idea or not.
What to do and not to do with a mirrored database
Mirroring a database is like creating a landing zone in your Data Intelligence environment. While it is similar, it is a bit different from that: a landing zone keeps the data ingested, the mirrored database doesn’t. When a record is updated or deleted in production the same will happen with the mirror.
The mirrored model contains all the common mistakes of production modelling which makes it not good for analytical reporting. Usually, it will not be good to hold history and may not be representing the facts in a business point of view.
What you should NOT do: Use the mirrored model directly to build analytical reports and dashboards. The quality of this data would be low, the amount of history would be questionable, you would not have a single source of truth.
However, keep in mind I wrote analytical reports. Production reports, which may be paginated reports, can be built over the Mirrored Database, because it has the same data as production. In this way, you remove from production the production reporting workload. But only production reporting, not analytical reporting.

Image created using Microsoft Designer Image Creator
For the analytical reporting, you need to transform the mirrored model in a data intelligence model, prepared to hold the complete history of the data and provide it according to the business meaning.
In this way, the mirroring feature doesn’t save you from building pipelines to transform the data, only move the entire workload of these pipeline to inside Fabric and OneLake.
If you are concerned about duplicating the data in the OneLake, it’s not really a duplication due to the needed transformations you will make. You can use shortcuts to handle the few exceptions which may not need transformations. Yes, the mirrored database supports shortcuts from lakehouses.
Requirements For Mirroring
This is the list of what works and doesn’t work with mirroring in Fabric. The list which you will skim and not really understand until, exactly like me, you get error messages about all these problems, one by one.
- It doesn’t support on premises servers and data gateway
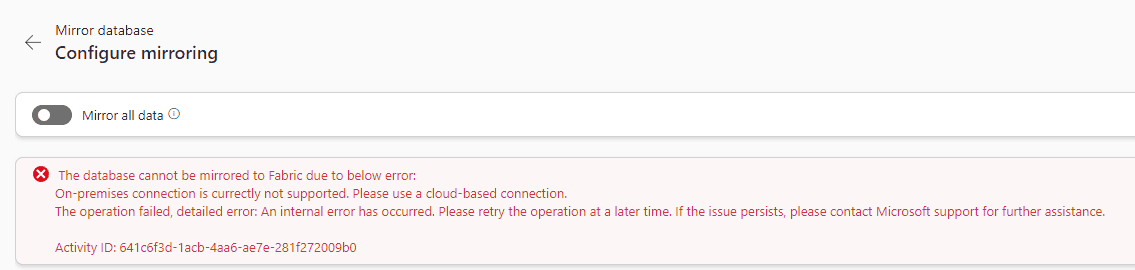
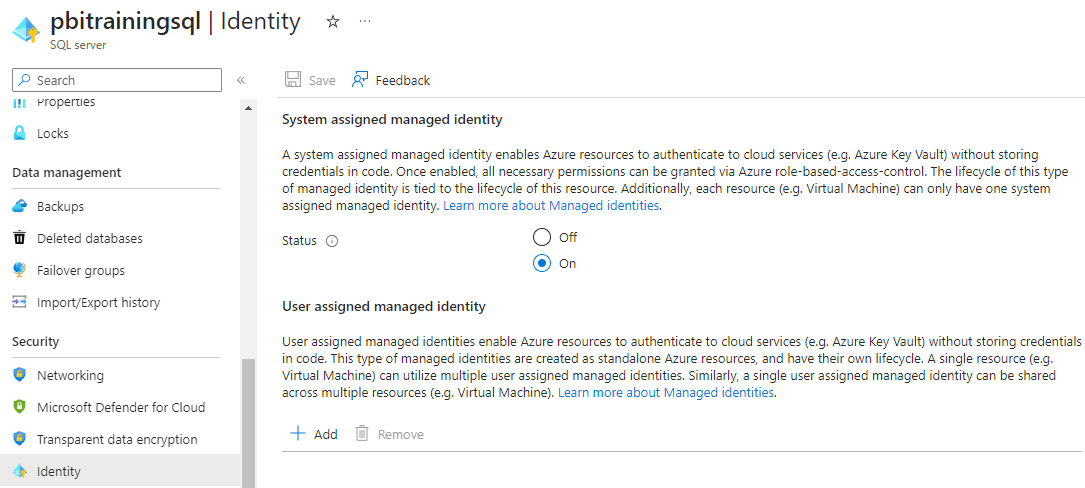
- The Azure SQL Server needs to have an identity, at least a System Managed identity

- On the server, Identity blade, you only need to enable the System Managed Identity.
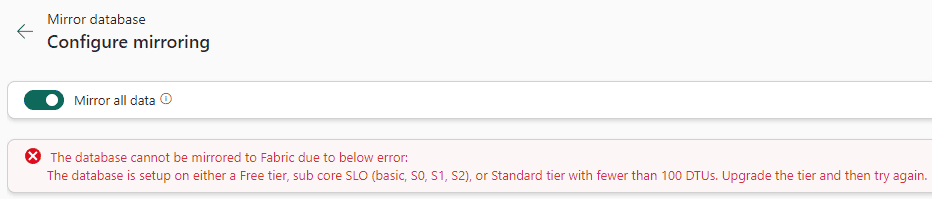
- The database needs to be at least on level S3 or above. CDC (Change Data Capture) and other features related to change capture are only available from S3 and above. It’s the first level to have a dedicated vCore.
- The database needs to be on the same Tenant as the Fabric workspace
- Fields using UDTs (User Defined Type) can’t be mirrored
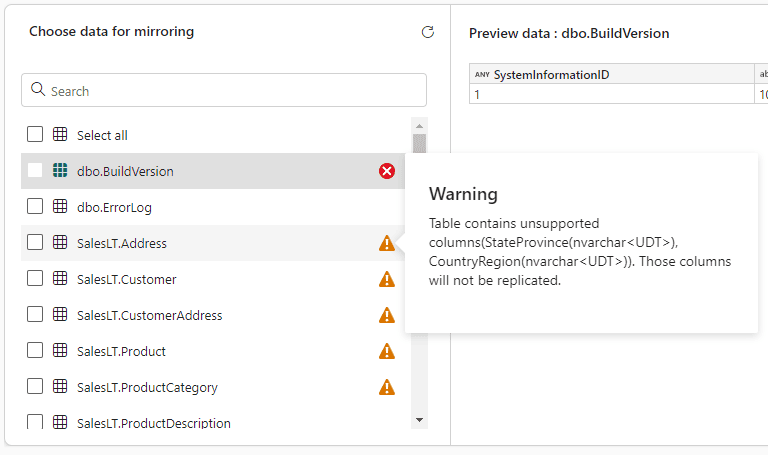
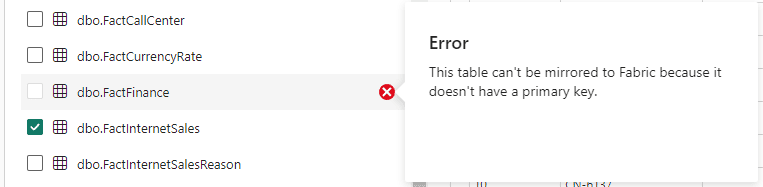
This one is trouble , because the sample database, AdventureWorksLT, which is so easy to create in Azure SQL, is not supported for mirroring to Fabric - Tables without primary keys can’t be mirrored
Preparing the Walkthrough
You need a database installed in Azure SQL with some tables which fit the requirements in order to test this feature.
I suggest one of these options:
- You can create the AdventureWorksLT and use the Make_Big_Adventure script to create to big tables. I adapted this script for the AdventureWorksLT and provided a copy on https://github.com/DennesTorres/BigAdventureAndQSHints The usual tables from AdventureWorksLT will not work for mirroring, but the new ones created by this script will.
- You can install one sample database (https://learn.microsoft.com/en-us/sql/samples/sql-samples-where-are?view=sql-server-ver16) in your local SQL Server and use Azure Data Studio to migrate it to Azure SQL. https://learn.microsoft.com/en-us/azure/dms/tutorial-sql-server-azure-sql-database-offline?tabs=azure-data-studio
Starting the Walkthrough
1) Create a workspace called MirroringSample
2) Create a lakehouse called BronzeLake
The lakehouse is not required for the mirror, but we will use this for an experiment. If you need more information about creating a lakehouse, check this link: https://www.red-gate.com/simple-talk/cloud/azure/microsoft-fabric-lakehouse-and-data-factory-in-power-bi-environment/
3) Change the Experience to Data Warehouse

Mirroring is included in the Data Warehouse experience.
4) Click the button Mirrored Azure SQL Database
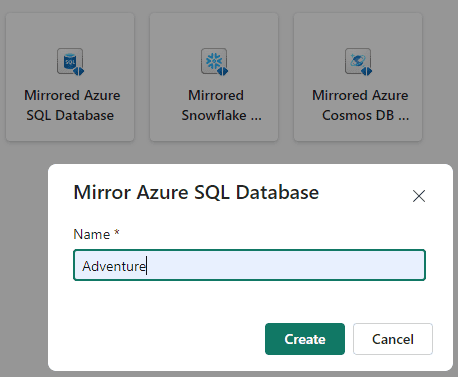
5) On the Mirror Azure SQL Database window, type the name Adventure:
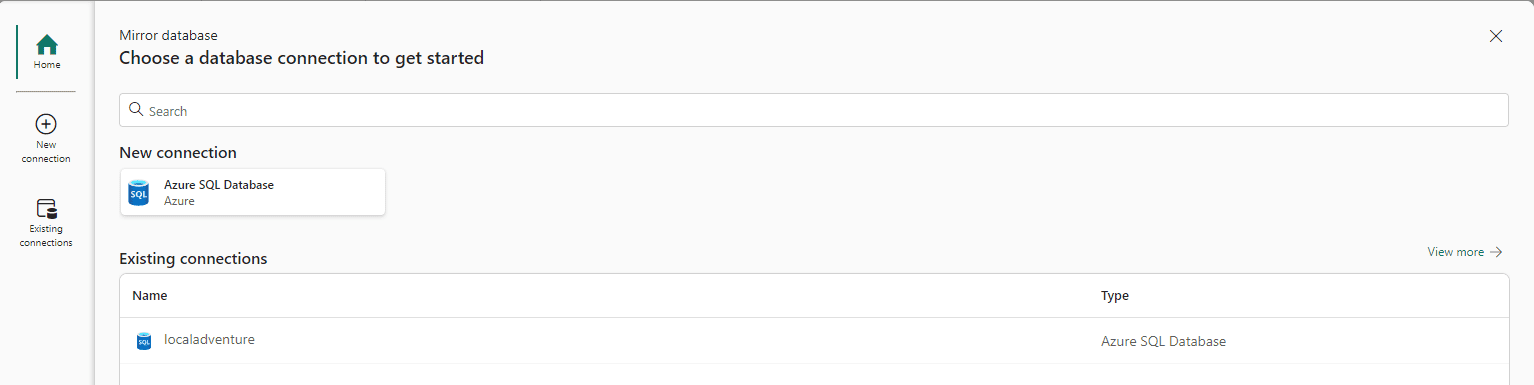
6) On the Mirror Database window, under New Connection, click Azure SQL Database
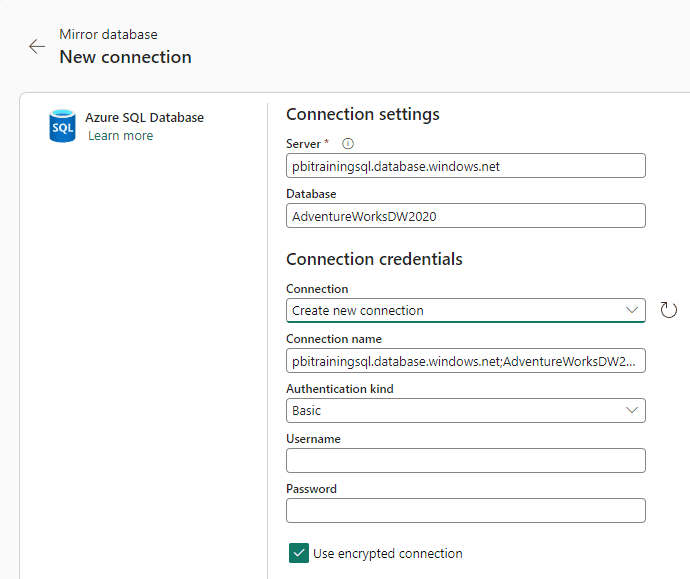
7) On the New Connection window, Server textbox, type the address of the Azure SQL Database
8) On the Database textbox, type the name of the database.
9) On the Connection Name textbox, you can customize the name of the connection:
Mirroring Security
Before we continue with the walkthrough, we need to discuss security for a moment. The security of the mirroring solution involves two important considerations: Authentication and Network Access.
Authentication
There are 3 types of authentications supported:
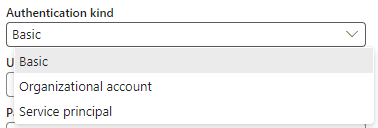
Basic Authentication
SQL authentication with a user and password. Is the least secure one, and should only rarely be used, when you don’t have the others available.

Organizational Account
This is the easiest way to implement, but it has many problems. Let’s say this implementation option has two levels of laziness. The consequence of the implementation depends on the level of laziness.
Laziness level 1: Use your own Azure Entra user account for the authentication. In this scenario, the implementation is tied with your account. What happens when your password changes? When you leave the company?
Laziness level 2: Create a custom account to be used only by this service. This helps, but the account would still be subject to all protection policies on Azure Entra. This can create problems for the implementation. The password policies and others working over the account may stop the service out of the blue. The solution architect would need to exclude this account from all policy applications for this to work, and it would be subject to mistakes.
Correct Method: Use a Service Principal
Service Principal
This is the safest option, but the most complex to implement. It requires an App Registration on Entra Id. The App Registration provides a client Id and key which allow it to be configured in services like the mirroring in Power BI.
The App Registration is not subject to the same policies as a regular user.

Check details about App Registration
Network Access
Fabric and Azure can be on a single Tenant, but they are on different networks. If we try a direct access from Fabric to Azure, the following will happen:
- The connection may pass through public internet.
- The connection will be subject to the firewall of the Azure object
We need a good method to make the connection work in a safe way.
The Wrong and lazy way
Azure SQL has a firewall control. In order to allow Fabric to bypass the Firewall, we should enable the option “Allow Azure Services and resources to access this server”.

The problem with this option is that we are basically disabling one layer of security for any attempt of connection coming from Azure Services or Power BI.
I explain on this video why this is a bad idea and some other concepts of Azure SQL Security.
Using a Private Endpoint
Private endpoints are a recent new feature in Microsoft Fabric. We can create a private endpoint to bring an Azure Resource to inside a virtual managed network in Fabric.
In this way, the connection would stay completely private and secure.
I recorded a video about how to use Fabric Private Endpoint
The Future: Workspace Identities and Trusted Workspace Access
Workspace Identities and Trusted workspaces is a new feature to allow a secure connection from Fabric to Azure.
At this moment these features only allow the connection to storage accounts, but soon it will be possible to use these features to connect to other resources, such as Azure SQL.
Read more about Workspace Identities
Read more about Trusted Workspaces
Continuing the Walkthrough
Now that you know the security issues involved with the connection and are ready to configure the authentication to Azure SQL, let’s continue the walkthrough.
We will start back, using the choices made about the authentication and network access method.
10) After configuring the authentication, click the Connect button on the lower right side of the window.
11) Disable the option Mirror All Data
You can mirror all the data if you would like, but to choose only some tables, you need to disable this option.
12) Select the tables to mirror. In my example, I will select DimProduct, DimCustomer and FactInternetSales
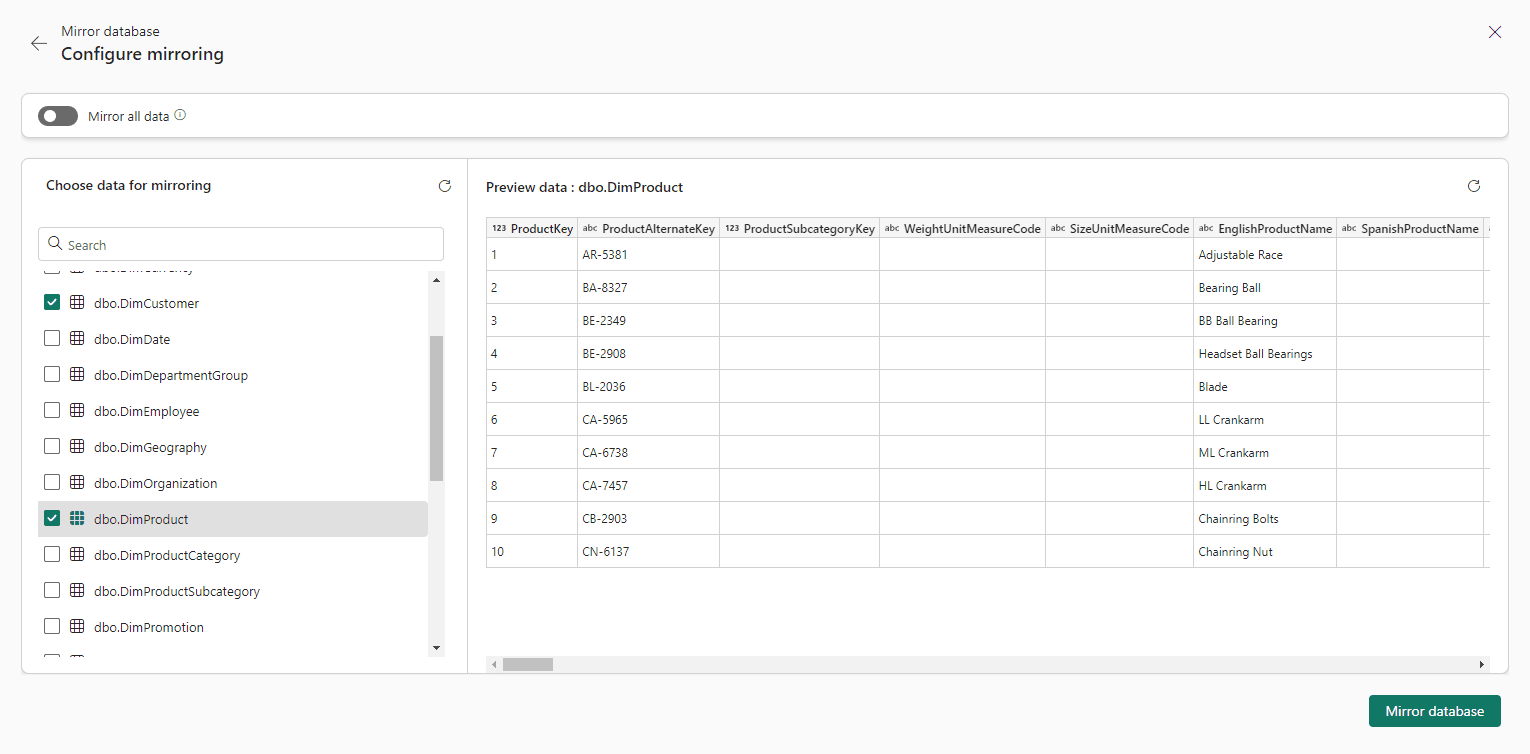
13) Click the Mirror Database button.
14) On the top of the window, click the Monitor Replication button
There is another button with the same purpose on the centre of the replication object window as well.
15) On the monitoring mirrored database window, the Total replicated rows will be empty until all rows are replicated.
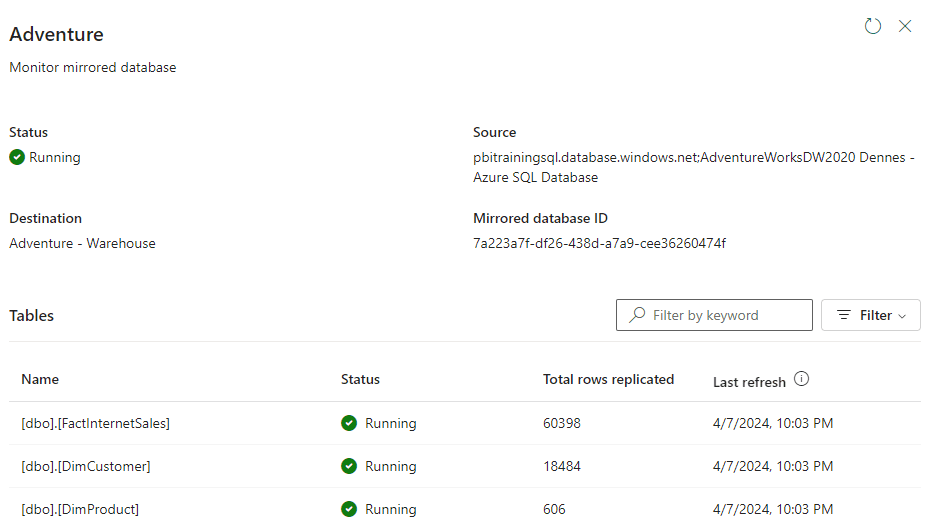
16) Close the monitoring window.
17) Click the settings button on the top of the window.
18) Click the SQL Endpoint tab.
This illustrates the presence of a SQL Endpoint and the address to connect to it from SSMS.
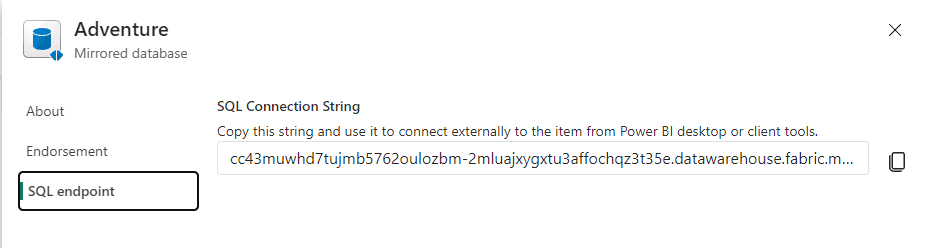
19) Close the settings window.
20) On the left bar, close the Adventure object
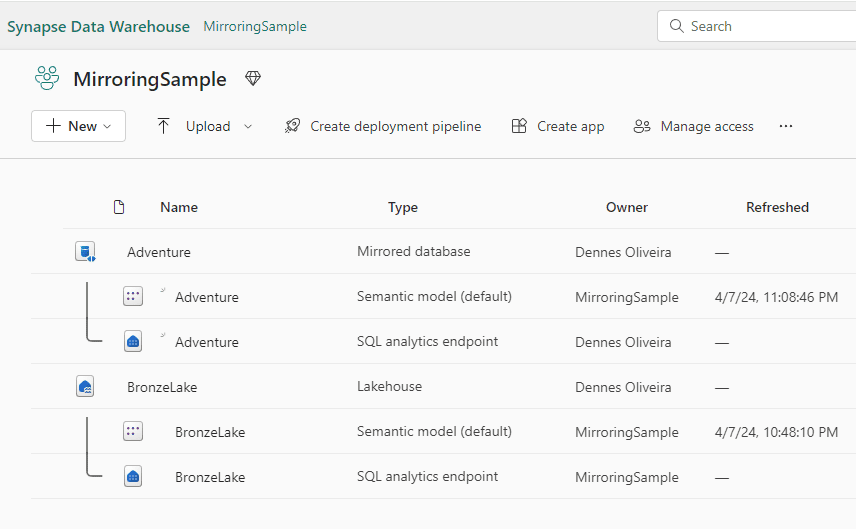
This is how the workspace should be at this point:
Testing the Mirroring
Let’s confirm the mirroring is working and continuously updating Fabric with new information from Azure SQL
21) Open the Adventure SQL Endpoint
The names of the mirrored tables are creating concatenating the schema of the tables with the name. For example, dbo.DimCustomer will become dbo.dbo_DimCustomer
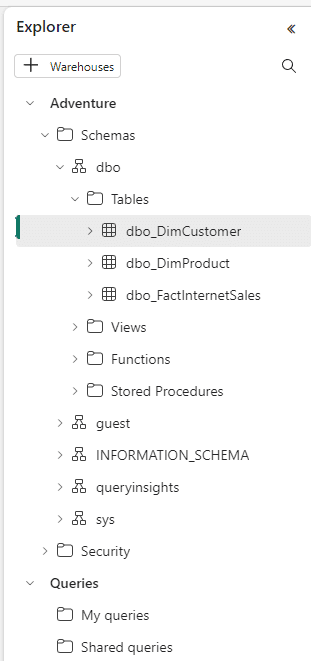
22) Click on the New Query button
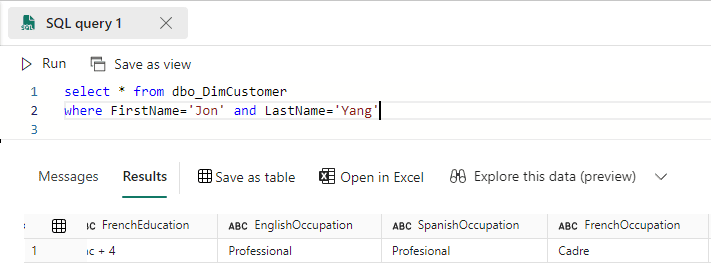
23) Execute the following query:
select * from dbo_DimCustomer
where FirstName='Jon' and LastName='Yang'
24) Open SSMS
25) Connect to your Azure SQL
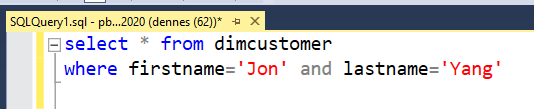
26) Update the EnglishOccupation field of the same record

27) Query this row to confirm it’s updated
You should get the following output:

28) On the SQL Endpoint, query the same record
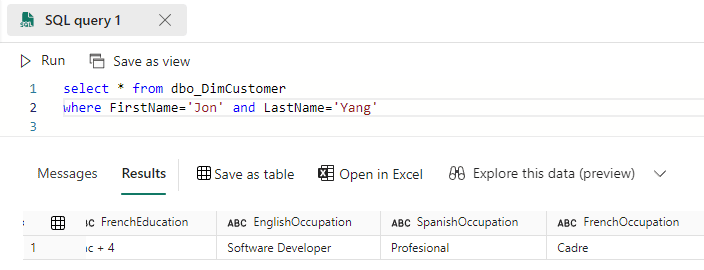
In this way, we could see the mirroring in action, synchronizing updates between Azure SQL and Fabric
29) Close the SQL Endpoint
Creating a Shortcut
As mentioned before, you will need to create pipelines to transform the mirrored data from the production model to a Data Intelligence model.
However, it’s possible some secondary tables may not need transformation. In this case, the possibility to create a shortcut will avoid data duplication in OneLake
30) Open the BronzeLake lakehouse
31) Right click the Tables folder
32) Click New Shortcut menu item
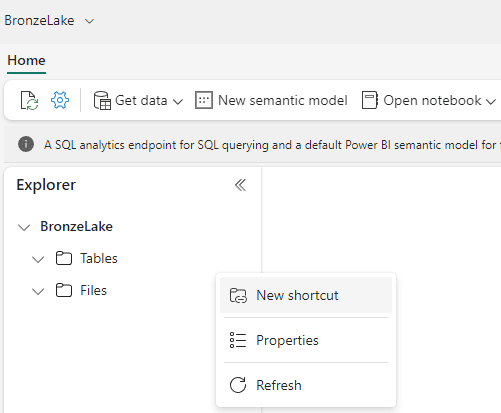
- On the Select a data source type window, select Adventure
This illustrates the Mirrored Database can be used as source for shortcuts
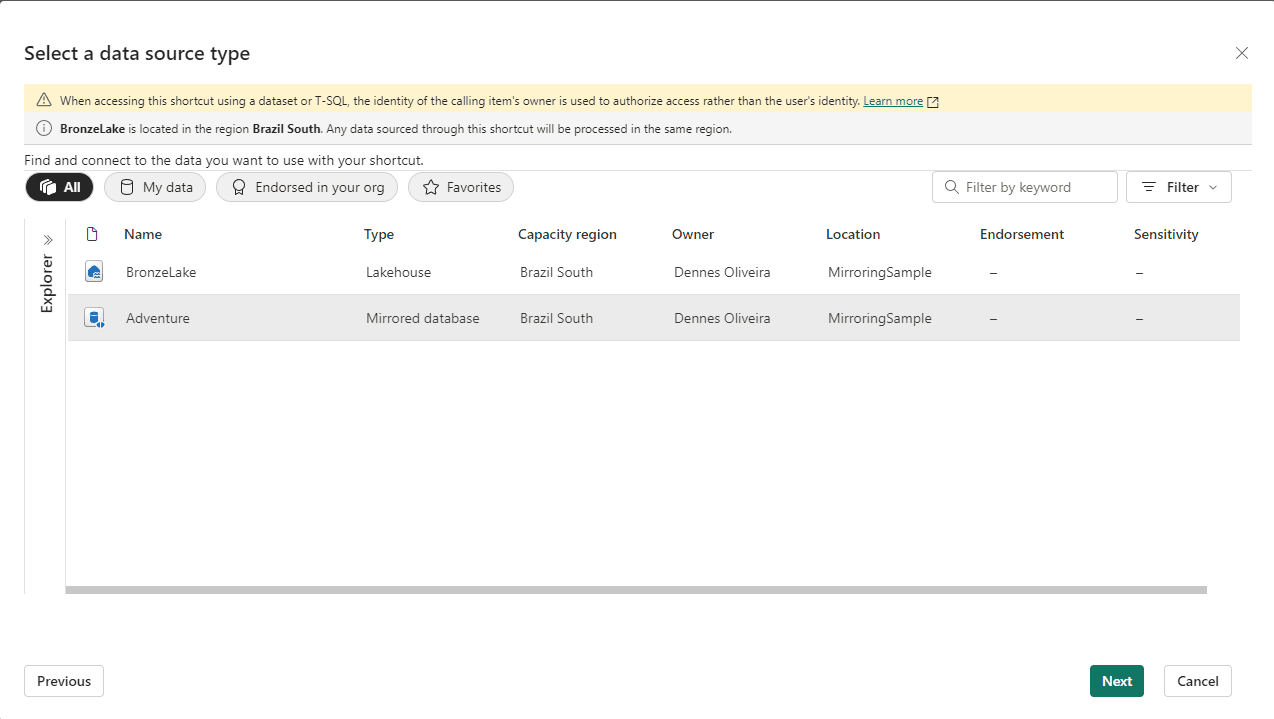
34) Click Next button
35) On the New Shortcut window, select the table dbo_DimCustomer
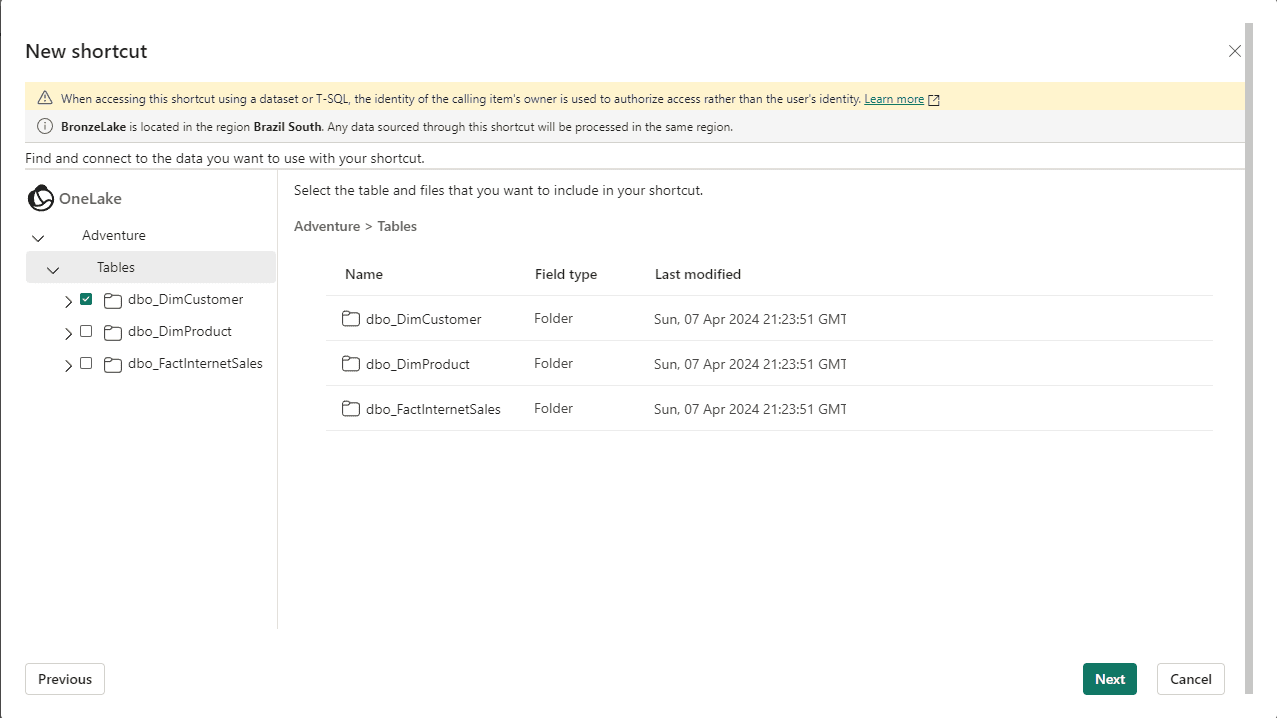
36) Click Next button
37) Click the Create button

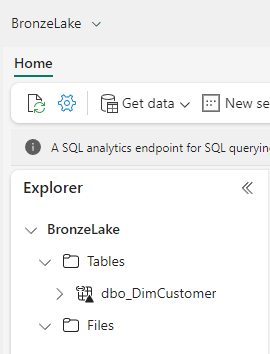
Summary
The mirroring feature can be very useful if used correctly, but still has a long way to go. You can also check Kevin Chant article about mirroring with CosmoDB
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments